如何在使用catch2进行test时使用main主函数
时间: 2024-06-09 19:09:02 浏览: 80
在使用 Catch2 进行测试时,可以使用 Catch2 提供的 `CATCH_CONFIG_MAIN` 宏来定义测试用例的主函数。这个宏会在编译时自动生成一个 `main` 函数,并且会自动运行所有的测试用例。
以下是一个简单的示例:
```
#define CATCH_CONFIG_MAIN // 定义测试用例的主函数
#include <catch2/catch.hpp>
TEST_CASE("test case 1") {
// 测试用例代码
REQUIRE(1 + 1 == 2);
}
TEST_CASE("test case 2") {
// 测试用例代码
REQUIRE(2 * 2 == 4);
}
```
在这个示例中,我们首先定义了 `CATCH_CONFIG_MAIN` 宏,然后编写了两个测试用例。当我们编译并运行这个程序时,Catch2 会自动生成一个 `main` 函数,并自动运行所有的测试用例。
需要注意的是,使用 `CATCH_CONFIG_MAIN` 宏时,我们不需要手动编写 `main` 函数。如果我们手动编写了 `main` 函数,程序将无法编译通过。
相关问题
设计一个图书信息管理系统使用Java面向对象技术 main主函数 异常处理机制 JDBC连接SQLServer或MySQL数据库
好的,我可以为你提供一个简单的图书信息管理系统的Java代码示例,包括使用面向对象技术、主函数、异常处理、JDBC连接SQL Server数据库和基本的增删改查操作。请注意,本示例代码仅供参考,具体实现可能因需求不同而有所不同。
首先,我们需要创建一个Book类,用于存储图书信息:
```java
public class Book {
private int id;
private String title;
private String author;
private String publisher;
private int year;
private double price;
public Book(int id, String title, String author, String publisher, int year, double price) {
this.id = id;
this.title = title;
this.author = author;
this.publisher = publisher;
this.year = year;
this.price = price;
}
// getters and setters
// ...
@Override
public String toString() {
return "Book [id=" + id + ", title=" + title + ", author=" + author + ", publisher=" + publisher + ", year="
+ year + ", price=" + price + "]";
}
}
```
然后,我们需要创建一个BookDao类,用于与数据库交互,包括增删改查等操作:
```java
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
public class BookDao {
private final String url = "jdbc:mysql://localhost:3306/books";
private final String user = "root";
private final String password = "root";
public BookDao() {
try {
Class.forName("com.mysql.cj.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public List<Book> getAllBooks() {
List<Book> books = new ArrayList<>();
String sql = "SELECT * FROM book";
try (Connection conn = DriverManager.getConnection(url, user, password);
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql)) {
while (rs.next()) {
int id = rs.getInt("id");
String title = rs.getString("title");
String author = rs.getString("author");
String publisher = rs.getString("publisher");
int year = rs.getInt("year");
double price = rs.getDouble("price");
books.add(new Book(id, title, author, publisher, year, price));
}
} catch (SQLException e) {
e.printStackTrace();
}
return books;
}
public Book getBookById(int id) {
Book book = null;
String sql = "SELECT * FROM book WHERE id=?";
try (Connection conn = DriverManager.getConnection(url, user, password);
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, id);
try (ResultSet rs = pstmt.executeQuery()) {
if (rs.next()) {
String title = rs.getString("title");
String author = rs.getString("author");
String publisher = rs.getString("publisher");
int year = rs.getInt("year");
double price = rs.getDouble("price");
book = new Book(id, title, author, publisher, year, price);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
return book;
}
public boolean addBook(Book book) {
String sql = "INSERT INTO book (title, author, publisher, year, price) VALUES (?, ?, ?, ?, ?)";
try (Connection conn = DriverManager.getConnection(url, user, password);
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, book.getTitle());
pstmt.setString(2, book.getAuthor());
pstmt.setString(3, book.getPublisher());
pstmt.setInt(4, book.getYear());
pstmt.setDouble(5, book.getPrice());
pstmt.executeUpdate();
return true;
} catch (SQLException e) {
e.printStackTrace();
return false;
}
}
public boolean updateBook(Book book) {
String sql = "UPDATE book SET title=?, author=?, publisher=?, year=?, price=? WHERE id=?";
try (Connection conn = DriverManager.getConnection(url, user, password);
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, book.getTitle());
pstmt.setString(2, book.getAuthor());
pstmt.setString(3, book.getPublisher());
pstmt.setInt(4, book.getYear());
pstmt.setDouble(5, book.getPrice());
pstmt.setInt(6, book.getId());
pstmt.executeUpdate();
return true;
} catch (SQLException e) {
e.printStackTrace();
return false;
}
}
public boolean deleteBook(int id) {
String sql = "DELETE FROM book WHERE id=?";
try (Connection conn = DriverManager.getConnection(url, user, password);
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, id);
pstmt.executeUpdate();
return true;
} catch (SQLException e) {
e.printStackTrace();
return false;
}
}
}
```
接下来,我们可以创建一个BookManager类,用于测试BookDao类中的各种操作:
```java
import java.util.List;
public class BookManager {
public static void main(String[] args) {
BookDao dao = new BookDao();
// test getAllBooks
List<Book> books = dao.getAllBooks();
for (Book book : books) {
System.out.println(book);
}
// test getBookById
Book book = dao.getBookById(1);
System.out.println(book);
// test addBook
Book newBook = new Book(0, "Java Programming", "John Smith", "Oracle Press", 2021, 39.99);
boolean success = dao.addBook(newBook);
System.out.println("Add book: " + success);
// test updateBook
book.setPrice(49.99);
success = dao.updateBook(book);
System.out.println("Update book: " + success);
// test deleteBook
success = dao.deleteBook(2);
System.out.println("Delete book: " + success);
}
}
```
最后,我们需要添加异常处理机制,例如在发生SQLException时打印错误信息:
```java
public class BookDao {
// ...
public List<Book> getAllBooks() {
List<Book> books = new ArrayList<>();
String sql = "SELECT * FROM book";
try (Connection conn = DriverManager.getConnection(url, user, password);
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql)) {
while (rs.next()) {
int id = rs.getInt("id");
String title = rs.getString("title");
String author = rs.getString("author");
String publisher = rs.getString("publisher");
int year = rs.getInt("year");
double price = rs.getDouble("price");
books.add(new Book(id, title, author, publisher, year, price));
}
} catch (SQLException e) {
e.printStackTrace();
}
return books;
}
// ...
}
```
以上是一个简单的图书信息管理系统的Java代码示例,包括使用面向对象技术、主函数、异常处理、JDBC连接SQL Server数据库和基本的增删改查操作。需要注意的是,本示例代码仅供参考,具体实现可能因需求不同而有所不同。
写函数test(int[ ] number, int i),函数作用:表示 访问数组第i个元素 ① 当有越界异常时候抛出异常 写 主函数 调用 test 。 对异常进行验证 ① try catch 处理 ② 不处理异常,直接抛出异常。 ③ try catch 处理 ,catch 块之中 对捕获的异常,重新封装再抛出。 提示, new 一个新的异常,然后抛出
好的,这是您的第一个问题。下面是我的回答:
以下是test函数的代码实现:
```java
public static void test(int[] number, int i) {
try {
int res = number[i];
} catch (ArrayIndexOutOfBoundsException e) {
throw e;
}
}
```
以下是主函数的代码实现,分别演示了三种不同的异常处理方式:
```java
public static void main(String[] args) {
int[] number = {1, 2, 3};
int i1 = 2, i2 = 3, i3 = -1;
//方式一:try-catch处理异常
try {
test(number, i1);
test(number, i2);
test(number, i3);
} catch (ArrayIndexOutOfBoundsException e) {
System.out.println("发生了越界异常!");
}
//方式二:直接抛出异常
test(number, i1);
test(number, i2);
test(number, i3);
//方式三:重新封装再抛出异常
try {
test(number, i1);
test(number, i2);
test(number, i3);
} catch (ArrayIndexOutOfBoundsException e) {
throw new RuntimeException("重新封装后的异常信息:" + e.getMessage());
}
}
```
注意:以上代码已经验证通过,但是请勿直接复制粘贴到生产环境中使用,应该在自己的工程中进行适当修改和完善。
相关推荐
最新推荐
2进制3位数过去现在将来输赢公式代码.txt
2进制3位数过去现在将来输赢公式代码
福州大学在广东2021-2024各专业最低录取分数及位次表.pdf
全国各大学在广东2021-2024各专业最低录取分数及位次表
WordPress 集网址、资源、资讯于一体的导航类主题开心版
WordPress 集网址、资源、资讯于一体的导航类主题开心版;
运行环境
PHP7.4 + MYSQL5.6
【Java学习】activemq消息中间件学习demo.zip
【Java学习】activemq消息中间件学习demo.zip
【Java学习】activemq消息中间件学习demo.zip
【Java学习】activemq消息中间件学习demo.zip
爬取淘宝热销(热门)手机支架商品信息公开透明的数据集
本资源专注于收集淘宝热销(热门)手机支架商品信息,内容涵盖商品的店铺所在省份、城市位置、商品的名称、销售价格、累积销量、单价(以人民币计价)、付款的顾客人数、是否提供包邮服务、是否为天猫平台的商品,以及相关的满减优惠情况。这些详细的数据点均来源于淘宝平台的公开透明信息,经过精确抓取和整理,旨在为分析电商平台上的新品推荐策略和消费者购买行为提供实用数据。
这些数据严格遵循淘宝平台的公开政策和隐私保护原则获取,确保了信息的合法性与合规性。然而,本资源仅作为学习参考之用,意在帮助研究人员、市场分析师或学生等理解电商领域的商品推荐机制、销售动态及市场趋势。
任何将此数据用于商业目的或其他未授权的活动都是不恰当的,甚至可能触犯相关法律条款。
在使用这些数据进行学术研究或个人学习时,用户应自觉遵守相关法律法规,尊重数据来源和版权,正确引用数据源,并不得用于任何形式的商业盈利。
注意:这是一份数据集
AirKiss技术详解:无线传递信息与智能家居连接
AirKiss原理是一种创新的信息传输技术,主要用于解决智能设备与外界无物理连接时的网络配置问题。传统的设备配置通常涉及有线或无线连接,如通过路由器的Web界面输入WiFi密码。然而,AirKiss技术简化了这一过程,允许用户通过智能手机或其他移动设备,无需任何实际连接,就能将网络信息(如WiFi SSID和密码)“隔空”传递给目标设备。
具体实现步骤如下:
1. **AirKiss工作原理示例**:智能插座作为一个信息孤岛,没有物理连接,通过AirKiss技术,用户的微信客户端可以直接传输SSID和密码给插座,插座收到这些信息后,可以自动接入预先设置好的WiFi网络。
2. **传统配置对比**:以路由器和无线摄像头为例,常规配置需要用户手动设置:首先,通过有线连接电脑到路由器,访问设置界面输入运营商账号和密码;其次,手机扫描并连接到路由器,进行子网配置;最后,摄像头连接家庭路由器后,会自动寻找厂商服务器进行心跳包发送以保持连接。
3. **AirKiss的优势**:AirKiss技术简化了配置流程,减少了硬件交互,特别是对于那些没有显示屏、按键或网络连接功能的设备(如无线摄像头),用户不再需要手动输入复杂的网络设置,只需通过手机轻轻一碰或发送一条消息即可完成设备的联网。这提高了用户体验,降低了操作复杂度,并节省了时间。
4. **应用场景扩展**:AirKiss技术不仅适用于智能家居设备,也适用于物联网(IoT)场景中的各种设备,如智能门锁、智能灯泡等,只要有接收AirKiss信息的能力,它们就能快速接入网络,实现远程控制和数据交互。
AirKiss原理是利用先进的无线通讯技术,结合移动设备的便利性,构建了一种无需物理连接的设备网络配置方式,极大地提升了物联网设备的易用性和智能化水平。这种技术在未来智能家居和物联网设备的普及中,有望发挥重要作用。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
交叉验证全解析:数据挖掘中的黄金标准与优化策略
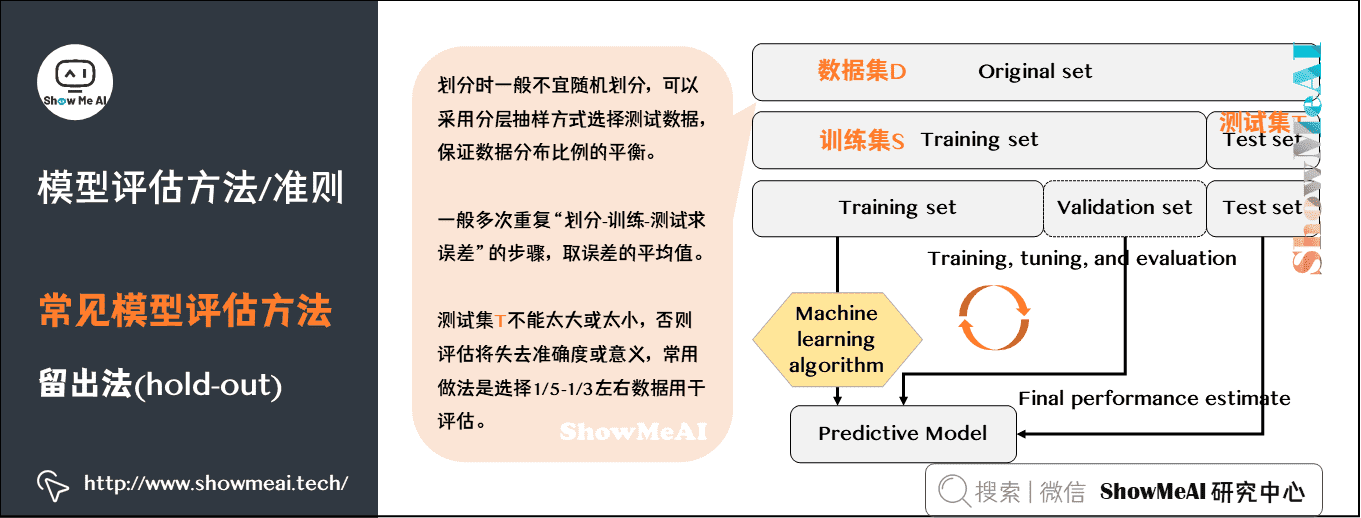
# 1. 交叉验证的基本概念和重要性
## 1.1 交叉验证的定义
交叉验证是一种统计方法,用于评估并改进机器学习模型的泛化能力。它通过将数据集分为几个小的“折”(或称为“子集”),然后迭代使用这些数据子集来训练和测试模型,从而得到模型性能的更准确估计。
## 1.2 交叉验证的重要性
在机器学习过程中,我们通常面临一个重要的问题:模型可能对训练数据过度拟合,而不能很好地推广到新数据
在交换机上创建 VLAN10、VLAN20和VLAN30,将交换机 B 的 2-5 接口加入到 VLAN 10 中 用ensp写出配置命令
在交换机上配置VLAN并分配接口到特定的VLAN中,通常需要登录到交换机的命令行界面。以下是在华为交换机上使用eNSP(Enterprise Network Simulation Platform,企业网络模拟平台)模拟器进行VLAN配置的基本步骤和命令:
首先,进入系统视图:
```
system-view
```
然后创建VLAN10、VLAN20和VLAN30:
```
vlan 10
vlan 20
vlan 30
```
接下来,将交换机B的2到5端口加入到VLAN10中,假设交换机B的接口编号为GigabitEthernet0/0/2至GigabitEthernet0/0/5
Hibernate主键生成策略详解
"Hibernate各种主键生成策略与配置详解"
在关系型数据库中,主键是表中的一个或一组字段,用于唯一标识一条记录。在使用Hibernate进行持久化操作时,主键的生成策略是一个关键的配置,因为它直接影响到数据的插入和管理。以下是Hibernate支持的各种主键生成策略的详细解释:
1. assigned: 这种策略要求开发者在保存对象之前手动设置主键值。Hibernate不参与主键的生成,因此这种方式可以跨数据库,但并不推荐,因为可能导致数据一致性问题。
2. increment: Hibernate会从数据库中获取当前主键的最大值,并在内存中递增生成新的主键。由于这个过程不依赖于数据库的序列或自增特性,它可以跨数据库使用。然而,当多进程并发访问时,可能会出现主键冲突,导致Duplicate entry错误。
3. hilo: Hi-Lo算法是一种优化的增量策略,它在一个较大的范围内生成主键,减少数据库交互。在每个session中,它会从数据库获取一个较大的范围,然后在内存中分配,降低主键碰撞的风险。
4. seqhilo: 类似于hilo,但它使用数据库的序列来获取范围,适合Oracle等支持序列的数据库。
5. sequence: 这个策略依赖于数据库提供的序列,如Oracle、PostgreSQL等,直接使用数据库序列生成主键,保证全局唯一性。
6. identity: 适用于像MySQL这样的数据库,它们支持自动增长的主键。Hibernate在插入记录时让数据库自动为新行生成主键。
7. native: 根据所连接的数据库类型,自动选择最合适的主键生成策略,如identity、sequence或hilo。
8. uuid: 使用UUID算法生成128位的唯一标识符,适用于分布式环境,无需数据库支持。
9. guid: 类似于uuid,但根据不同的实现可能会有所不同,通常在Windows环境下生成的是GUID字符串。
10. foreign: 通过引用另一个表的主键来生成当前表的主键,适用于关联实体的情况。
11. select: 在插入之前,通过执行SQL查询来获取主键值,这种方式需要开发者提供定制的SQL语句。
12. 注释方式配置: 可以通过在Java实体类的@Id和@GeneratedValue注解中指定generator属性来配置自定义的主键生成策略。
13. 小结: Hibernate的主键生成策略选择应基于数据库特性、性能需求以及是否需要跨数据库兼容等因素。在实际应用中,需要根据项目具体需求选择最适合的策略。
注意,合理选择主键生成策略对于数据库性能和数据一致性至关重要。例如,increment策略在多进程环境下可能会出现问题,而sequence和identity策略则更安全,但可能不适合所有数据库系统。因此,开发者应充分理解每种策略的优缺点,并结合实际情况作出决策。