linux读取文件中单词数并做一个词云,将内容分为前中后三部分,分析角色变化
时间: 2024-02-16 16:03:44 浏览: 27
好的,我会尽力回答你的问题。
首先,对于Linux读取文件中单词数并做一个词云的需求,你可以使用以下命令来实现:
```bash
cat file.txt | tr -cs '[:alpha:]' '[\n*]' | sort | uniq -c | sort -nr > word_count.txt
```
其中,`file.txt`是你想要读取的文件名,运行这个命令后,它会将文件中的所有单词都提取出来,并统计每个单词出现的次数,并将结果输出到`word_count.txt`文件中。
接下来,你可以使用诸如WordCloud这样的Python库来生成词云图。你可以使用Python脚本读取`word_count.txt`文件中的数据,并将其传递给WordCloud库,生成词云图。这里提供一个简单的Python脚本示例:
```python
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 读取文件中的数据
with open('word_count.txt', 'r') as f:
data = f.read()
# 生成词云图
wordcloud = WordCloud(width=800, height=800, background_color='white', min_font_size=10).generate(data)
# 显示词云图
plt.figure(figsize=(8, 8), facecolor=None)
plt.imshow(wordcloud)
plt.axis('off')
plt.tight_layout(pad=0)
plt.show()
```
这段代码会生成一个800x800像素的白色背景的词云图,并将其显示出来。你可以根据需要调整参数,生成符合自己需求的词云图。
接下来,对于将内容分为前中后三部分,分析角色变化的需求,你需要根据具体情况进行处理。一般来说,你可以先读取整个文件,然后根据具体情况,将其分为前中后三部分,并对每一部分进行分析。
具体的分析方法取决于你想要分析的内容和角色。你可以使用自然语言处理的方法,对文本进行分词、词性标注、命名实体识别等处理,从而提取出关键信息。你还可以使用情感分析的方法,对文本中的情感进行分析,了解角色的情感变化。总之,具体的分析方法需要结合具体情况进行调整。
希望这些信息能够帮助到你,如果你还有其他问题,可以继续问我。
相关推荐
最新推荐
Shell脚本从文件中逐行读取内容的几种方法实例
今天小编就为大家分享一篇关于Shell脚本从文件中逐行读取内容的几种方法实例,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧
嵌入式系统/ARM技术中的Linux下读取网卡默认MAC地址的方法
在嵌入式linux学习中无可避免也会遇到MAC,本文主要描述了如何通过操作OTP来读取嵌入式linux设备网卡中的MAC地址 1.1 适用范围 这里主要介绍读取网卡MAC地址的方法,适用于EasyARM-i.MX287A...
Java将对象保存到文件中/从文件中读取对象的方法
下面小编就为大家带来一篇Java将对象保存到文件中/从文件中读取对象的方法。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧
python修改linux中文件(文件夹)的权限属性操作
今天生成的对流云团路径图片放在linux下,文件的权限都是rw,没有x,后续的别人的程序调用不了,这里附上对三个属性的简单解释,有不够的欢迎大家补充 Linux的权限不是很细致,只有RWX三种 r(Read,读取):对文件而...
Python实现读取txt文件中的数据并绘制出图形操作示例
主要介绍了Python实现读取txt文件中的数据并绘制出图形操作,涉及Python文件读取、数值运算及基于pylab库的图形绘制相关操作技巧,需要的朋友可以参考下
zigbee-cluster-library-specification
最新的zigbee-cluster-library-specification说明文档。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL数据库性能提升秘籍:揭秘性能下降幕后真凶及解决策略
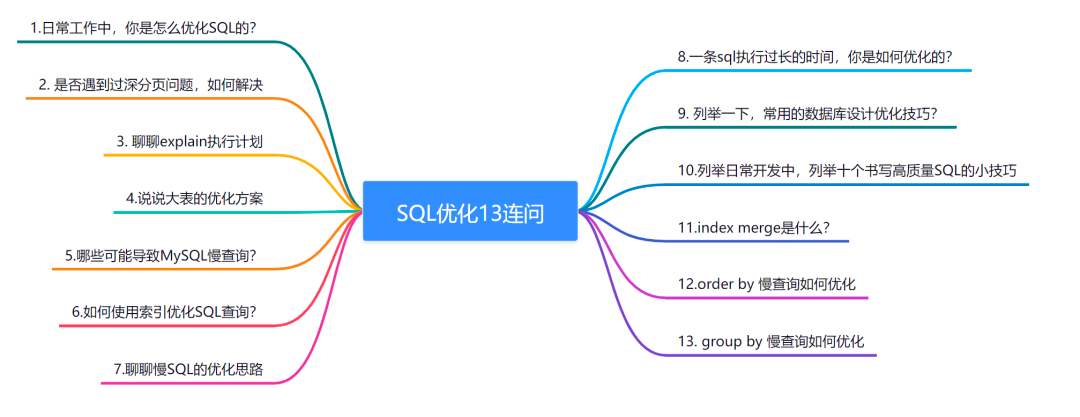
# 1. MySQL数据库性能优化概述**
MySQL数据库性能优化是一项至关重要的任务,可以显著提高应用程序的响应时间和整体用户体验。优化涉及识别和解决影响数据库性能的因素,包括硬件资源瓶颈、软件配置不当和数据库设计缺陷。通过采取适当的优化策略,可以显著提升数据库性能,满足业务需求并提高用户满意度。
# 2. MySQL数据库性能下降的幕后真凶
### 2.1 硬件资源瓶颈
#### 2.1.1 CPU利用率过高
**症状:
如何在unity创建按钮
在 Unity 中创建按钮的步骤如下:
1. 在 Unity 中创建一个 UI Canvas,选择 GameObject -> UI -> Canvas。
2. 在 Canvas 中创建一个按钮,选择 GameObject -> UI -> Button。
3. 在场景视图中调整按钮的位置和大小。
4. 在 Inspector 中设置按钮的文本、颜色、字体等属性。
5. 添加按钮的响应事件,选择按钮,在 Inspector 的 On Click () 中添加相应的方法。
这样就可以创建一个按钮了,你可以在游戏中使用它来触发相应的操作。
JSBSim Reference Manual
JSBSim参考手册,其中包含JSBSim简介,JSBSim配置文件xml的编写语法,编程手册以及一些应用实例等。其中有部分内容还没有写完,估计有生之年很难看到完整版了,但是内容还是很有参考价值的。