以下shell脚本是什么意思,转船python是什么样的。 case ${WORK_ORDER} in FT1|FT2|TSS|ST|ORT) LGetOnlineDiskInfo "accurate.txt" "${ON_LINE_INFO_FILE}" echo "fail" fi ;; *) echo "pass" ;; esac
时间: 2023-07-21 16:08:39 浏览: 44
这是一个 shell 脚本中的 case 语句,根据变量 ${WORK_ORDER} 的值进行不同的处理。如果 ${WORK_ORDER} 的值为 FT1、FT2、TSS、ST 或 ORT,则会调用 LGetOnlineDiskInfo 函数,并将 accurate.txt 和 ${ON_LINE_INFO_FILE} 作为参数传递给该函数。然后输出字符串 "fail"。如果 ${WORK_ORDER} 的值不属于上述几种情况,则直接输出字符串 "pass"。
以下是相应的 Python 代码实现:
```
if WORK_ORDER in ["FT1", "FT2", "TSS", "ST", "ORT"]:
LGetOnlineDiskInfo("accurate.txt", ON_LINE_INFO_FILE)
print("fail")
else:
print("pass")
```
其中,LGetOnlineDiskInfo 函数需要提前定义。
相关问题
给定下列 LL(1)文法,编写递归下降程序,分析表达式 i+i*2 的合法性,并 能显示出分析过程。 E→TE1 E1→+TE1|-TE1|ε T→FT1 T1→*FT1|/FT1|ε F→(E)|i
以下是该 LL(1)文法的递归下降程序(使用 Python 语言实现):
```python
def E():
T()
E1()
def E1():
if lookahead == '+':
match('+')
T()
E1()
elif lookahead == '-':
match('-')
T()
E1()
else:
pass
def T():
F()
T1()
def T1():
if lookahead == '*':
match('*')
F()
T1()
elif lookahead == '/':
match('/')
F()
T1()
else:
pass
def F():
if lookahead == '(':
match('(')
E()
match(')')
elif lookahead == 'i':
match('i')
else:
raise SyntaxError("Invalid token")
def match(token):
global lookahead
if lookahead == token:
lookahead = next_token()
else:
raise SyntaxError("Unexpected token")
def next_token():
global position
if position < len(expression):
token = expression[position]
position += 1
return token
else:
return None
```
假设输入的表达式为 "i+i*2",初始时 `lookahead` 为 "i",`position` 为 0。程序开始执行 `E()`,调用 `T()`,`lookahead` 不是 "*" 或 "/",所以调用 `F()`。`lookahead` 是 "i",匹配成功,调用 `match('i')`,此时 `lookahead` 变为 "+",再调用 `T1()`。`lookahead` 是 "*",匹配成功,调用 `match('*')`,`lookahead` 变为 "2",再调用 `F()`。`lookahead` 是 "2",匹配成功,调用 `match('2')`,`lookahead` 变为 None。此时整个表达式已经被成功分析,程序结束。
分析过程如下:
```
E()
T()
F()
i
T1()
E1()
+
T()
F()
i
T1()
*
F()
2
T1()
```
因此,该表达式是合法的。
用符号表示如下: E→T|E+T|E-T T→F|T*F|T/F F→i|(E) 2、消去上面文法的左递归 E→TE1 E1 →+TE1|-TE1|ε T→FT1 T1→*FT1|/FT1|ε F →i|(E) 3. 按消去左递归的文法,使用Python语言,写出对应的递归下降语法分析器。
以下是Python代码:
```
def match_terminal(expected_token, tokens, index):
if tokens[index] == expected_token:
return index + 1
else:
return -1
def parse_E(tokens, index):
index = parse_T(tokens, index)
if index == -1:
return -1
else:
return parse_E1(tokens, index)
def parse_E1(tokens, index):
next_index = match_terminal('+', tokens, index)
if next_index != -1:
next_index = parse_T(tokens, next_index)
if next_index == -1:
return -1
else:
return parse_E1(tokens, next_index)
else:
next_index = match_terminal('-', tokens, index)
if next_index != -1:
next_index = parse_T(tokens, next_index)
if next_index == -1:
return -1
else:
return parse_E1(tokens, next_index)
else:
return index
def parse_T(tokens, index):
index = parse_F(tokens, index)
if index == -1:
return -1
else:
return parse_T1(tokens, index)
def parse_T1(tokens, index):
next_index = match_terminal('*', tokens, index)
if next_index != -1:
next_index = parse_F(tokens, next_index)
if next_index == -1:
return -1
else:
return parse_T1(tokens, next_index)
else:
next_index = match_terminal('/', tokens, index)
if next_index != -1:
next_index = parse_F(tokens, next_index)
if next_index == -1:
return -1
else:
return parse_T1(tokens, next_index)
else:
return index
def parse_F(tokens, index):
next_index = match_terminal('i', tokens, index)
if next_index != -1:
return next_index
else:
next_index = match_terminal('(', tokens, index)
if next_index != -1:
next_index = parse_E(tokens, next_index)
if next_index == -1:
return -1
else:
return match_terminal(')', tokens, next_index)
else:
return -1
def parse(tokens):
index = parse_E(tokens, 0)
if index != -1 and index == len(tokens):
print("RIGHT, AGAIN! 语法分析完毕!")
else:
print("WRONG! 退出语法分析!")
tokens = ['i', '+', 'i', '*', 'i', '#']
parse(tokens)
```
相关推荐
import requests import re headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'} def baidu(page): num = (page - 1) * 10 url = 'http://www.baidu.com/s?ie=utf-8&medium=0&rtt=1&bsst=1&rsv_dl=news_b_pn&cl=2&wd=meizu&tn=news&rsv_bp=1&rsv_sug3=16&rsv_sug1=6&rsv_sug7=100&oq=&rsv_btype=t&f=8&inputT=5752&rsv_sug4=6599&x_bfe_rqs=032000000000000000004800000000000000000000000008&x_bfe_tjscore=0.080000&tngroupname=organic_news&newVideo=12&goods_entry_switch=1&pn='+ str(num) res = requests.get(url, headers=headers).text baidu(i+1) print("第"+str(i+1)+"页爬取成功") import re p_title = '}">(.*?)
(.*?)<span ' #提取时间 info=re.findall(p_info,res,re.S) print(info) p_href= '<a class="source-link_Ft1ov" href="(.*?)"' #提取网址 href=re.findall(p_href,res,re.S) print(href) p_souce='<span class="c-color-gray" aria-label=".*?">(.*?)</span>' #提取来源 souce=re.findall(p_souce,res,re.S) print(souce) for i in range(len(title)): title[i]=re.sub('<.*?>','',title[i]) #去掉、 print(str(i+1)+"."+title[i]+' ('+info[i]+"-"+souce[i]+')') print(" ",href[i])最新推荐
汽车驱动力与行驶阻力平衡图在Matlab中的程序-新建 Microsoft Word 文档 (2).doc
Ft2=Tq.*ig.*i0.*eT./r; Ft3=Tq.*ig.*i0.*eT./r; Ft4=Tq.*ig.*i0.*eT./r; s=2*pi*r*0.001; Ua1=n./ig./i0.*60.*s; Ua2=n./ig./i0.*60.*s; Ua3=n./ig./i0.*60.*s; Ua4=n./ig./i0.*60.*s; Ff=m*g*f; ua...
汽车理论动力性课后matlab编程题(有源程序和解释)
Ft2=Tq*ig(2)*i0*y/r; Ft3=Tq*ig(3)*i0*y/r; Ft4=Tq*ig(4)*i0*y/r; %计算行驶阻力。 Fz1=m*g*f+2.77*ua1.^2/21.15; Fz2=m*g*f+2.77*ua2.^2/21.15; Fz3=m*g*f+2.77*ua3.^2/21.15; Fz4=m*g*f+2.77*ua4.^2/21.15; %...
java编写的LL(1)文法
LL(1)简单模拟测试 给定某一文法,试构造其简单优先矩阵(或LL(1)矩阵),并编制程序。 给出相应句子的语法分析过程,判其正确性。 例如:给定文法G: E→T E1 ... T→FT1 T1→*F/ε F→id/(E)
高校学生选课系统项目源码资源
项目名称: 高校学生选课系统
内容概要: 高校学生选课系统是为了方便高校学生进行选课管理而设计的系统。该系统提供了学生选课、查看课程信息、管理个人课程表等功能,同时也为教师提供了课程发布和管理功能,以及管理员对整个选课系统的管理功能。
适用人群:
学生: 高校本科生和研究生,用于选课、查看课程信息、管理个人课程表等。
教师: 高校教师,用于发布课程、管理课程信息和学生选课情况等。
管理员: 系统管理员,用于管理整个选课系统,包括用户管理、课程管理、权限管理等。
使用场景及目标:
学生选课场景: 学生登录系统后可以浏览课程列表,根据自己的专业和兴趣选择适合自己的课程,并进行选课操作。系统会实时更新学生的选课信息,并生成个人课程表。
教师发布课程场景: 教师登录系统后可以发布新的课程信息,包括课程名称、课程描述、上课时间、上课地点等。发布后的课程将出现在课程列表中供学生选择。
管理员管理场景: 管理员可以管理系统的用户信息,包括学生、教师和管理员账号的添加、删除和修改;管理课程信息,包括课程的添加、删除和修改;管理系统的权限控制,包括用户权限的分配和管理。
目标:
为高校学生提
TC-125 230V 50HZ 圆锯
TC-125 230V 50HZ 圆锯
RTL8188FU-Linux-v5.7.4.2-36687.20200602.tar(20765).gz
REALTEK 8188FTV 8188eus 8188etv linux驱动程序稳定版本, 支持AP,STA 以及AP+STA 共存模式。 稳定支持linux4.0以上内核。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
:YOLOv1目标检测算法:实时目标检测的先驱,开启计算机视觉新篇章
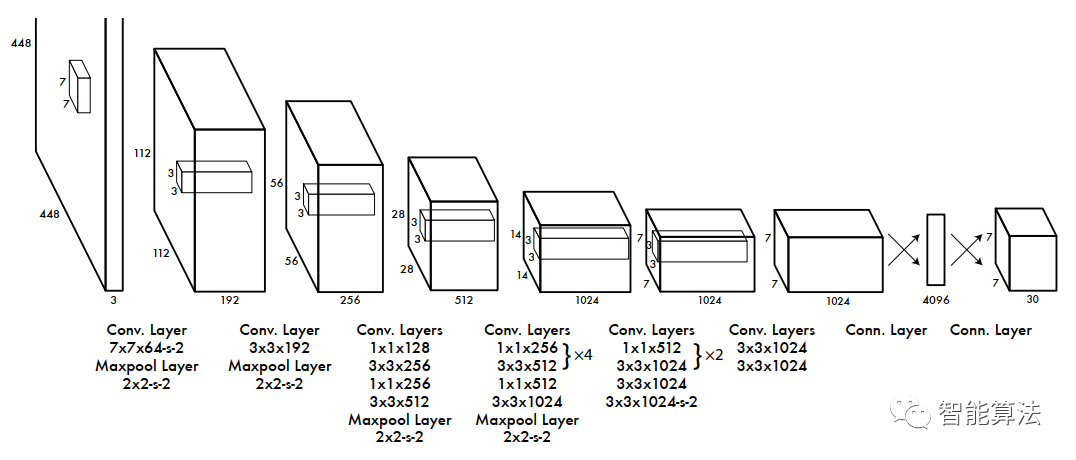
# 1. 目标检测算法概述
目标检测算法是一种计算机视觉技术,用于识别和定位图像或视频中的对象。它在各种应用中至关重要,例如自动驾驶、视频监控和医疗诊断。
目标检测算法通常分为两类:两阶段算法和单阶段算法。两阶段算法,如 R-CNN 和 Fast R-CNN,首先生成候选区域,然后对每个区域进行分类和边界框回归。单阶段算法,如 YOLO 和 SSD,一次性执行检
info-center source defatult
这是一个 Cisco IOS 命令,用于配置 Info Center 默认源。Info Center 是 Cisco 设备的日志记录和报告工具,可以用于收集和查看设备的事件、警报和错误信息。该命令用于配置 Info Center 默认源,即设备的默认日志记录和报告服务器。在命令行界面中输入该命令后,可以使用其他命令来配置默认源的 IP 地址、端口号和协议等参数。
c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
校园超市商品信息管理系统课程设计旨在帮助学生深入理解程序设计的基础知识,同时锻炼他们的实际操作能力。通过设计和实现一个校园超市商品信息管理系统,学生掌握了如何利用计算机科学与技术知识解决实际问题的能力。在课程设计过程中,学生需要对超市商品和销售员的关系进行有效管理,使系统功能更全面、实用,从而提高用户体验和便利性。
学生在课程设计过程中展现了积极的学习态度和纪律,没有缺勤情况,演示过程流畅且作品具有很强的使用价值。设计报告完整详细,展现了对问题的深入思考和解决能力。在答辩环节中,学生能够自信地回答问题,展示出扎实的专业知识和逻辑思维能力。教师对学生的表现予以肯定,认为学生在课程设计中表现出色,值得称赞。
整个课程设计过程包括平时成绩、报告成绩和演示与答辩成绩三个部分,其中平时表现占比20%,报告成绩占比40%,演示与答辩成绩占比40%。通过这三个部分的综合评定,最终为学生总成绩提供参考。总评分以百分制计算,全面评估学生在课程设计中的各项表现,最终为学生提供综合评价和反馈意见。
通过校园超市商品信息管理系统课程设计,学生不仅提升了对程序设计基础知识的理解与应用能力,同时也增强了团队协作和沟通能力。这一过程旨在培养学生综合运用技术解决问题的能力,为其未来的专业发展打下坚实基础。学生在进行校园超市商品信息管理系统课程设计过程中,不仅获得了理论知识的提升,同时也锻炼了实践能力和创新思维,为其未来的职业发展奠定了坚实基础。
校园超市商品信息管理系统课程设计的目的在于促进学生对程序设计基础知识的深入理解与掌握,同时培养学生解决实际问题的能力。通过对系统功能和用户需求的全面考量,学生设计了一个实用、高效的校园超市商品信息管理系统,为用户提供了更便捷、更高效的管理和使用体验。
综上所述,校园超市商品信息管理系统课程设计是一项旨在提升学生综合能力和实践技能的重要教学活动。通过此次设计,学生不仅深化了对程序设计基础知识的理解,还培养了解决实际问题的能力和团队合作精神。这一过程将为学生未来的专业发展提供坚实基础,使其在实际工作中能够胜任更多挑战。