Linux环境下使用kibanna导入数据到es中
时间: 2024-02-26 13:52:06 浏览: 35
要在Linux环境下使用Kibana导入数据到Elasticsearch中,需要先确保Elasticsearch和Kibana已经成功安装和启动,并且它们之间的连接已经建立。
接下来,可以按照以下步骤进行数据导入:
1. 在Kibana中打开“Management”页面,然后选择“Index Patterns”。
2. 点击“Create index pattern”按钮,输入要导入的数据的索引名称,并点击“Next step”。
3. 在“Configure settings”页面上,可以选择要在Kibana中显示的字段,并设置时间字段。完成后,点击“Create index pattern”按钮。
4. 在Kibana的左侧导航栏中选择“Discover”页面,并选择刚才创建的索引模式。
5. 点击“Create index pattern”按钮,Kibana将会自动检测到数据,并在页面上显示它们。
6. 在页面上方选择“Import”选项卡,然后选择要导入的数据文件。
7. 设置导入选项,比如索引名称、时间字段等,并点击“Import”按钮。
8. Kibana将会自动将数据导入到Elasticsearch中,并在“Discover”页面上显示它们。
以上就是在Linux环境下使用Kibana导入数据到Elasticsearch的基本步骤。需要注意的是,导入数据的具体步骤可能因为数据格式、数据来源等原因而略有不同。
相关问题
idea中如何将数据库的数据导入到Elasticsearch中
在 IntelliJ IDEA 中将数据库中的数据导入到 Elasticsearch 可以通过以下步骤实现:
1. 首先,你需要在 IDEA 中安装 Elasticsearch 插件。打开 IDEA,点击菜单栏的 File -> Settings,在弹出的窗口中点击左侧的 Plugins,搜索 Elasticsearch 并安装。
2. 接下来,你需要创建一个 Maven 项目,并添加 Elasticsearch 和数据库(比如 MySQL)的依赖。在 pom.xml 文件中添加以下依赖:
```xml
<dependencies>
<!-- Elasticsearch -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.10.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.10.1</version>
</dependency>
<!-- 数据库驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
</dependencies>
```
3. 在 Java 代码中,创建 Elasticsearch 客户端并连接到 Elasticsearch 服务器。然后,创建一个数据库连接,并使用 JDBC 获取数据。将数据转换为 Elasticsearch 文档格式,并使用 Elasticsearch 客户端将文档索引到 Elasticsearch 中。
```java
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import java.sql.*;
public class Main {
public static void main(String[] args) throws Exception {
// 创建 Elasticsearch 客户端
RestHighLevelClient client = new RestHighLevelClient(/* ... */);
// 创建数据库连接
String url = "jdbc:mysql://localhost:3306/mydb";
String user = "root";
String password = "root";
Connection conn = DriverManager.getConnection(url, user, password);
Statement stmt = conn.createStatement();
// 查询数据
ResultSet rs = stmt.executeQuery("SELECT * FROM mytable");
while (rs.next()) {
// 将数据转换为 Elasticsearch 文档格式
String id = rs.getString("id");
String name = rs.getString("name");
String age = rs.getString("age");
String json = String.format("{ \"id\": \"%s\", \"name\": \"%s\", \"age\": \"%s\" }", id, name, age);
// 将文档索引到 Elasticsearch 中
IndexRequest request = new IndexRequest("myindex").id(id).source(json, XContentType.JSON);
client.index(request, RequestOptions.DEFAULT);
}
// 关闭连接和客户端
rs.close();
stmt.close();
conn.close();
client.close();
}
}
```
以上就是在 IDEA 中将数据库的数据导入到 Elasticsearch 的基本步骤。你需要根据自己的实际情况进行修改。
利用java多线程技术导入数据到elasticsearch的方法步骤
利用Java多线程技术导入数据到Elasticsearch的方法步骤如下:
步骤1:引入必要的依赖
首先,需要在项目中引入Elasticsearch的Java客户端依赖,可以通过Maven或Gradle进行引入。
步骤2:创建Elasticsearch客户端
使用Elasticsearch的Java客户端创建与Elasticsearch服务器的连接。可以使用TransportClient或RestClient来进行连接。
步骤3:创建数据导入任务
创建一个数据导入任务类,实现Runnable接口,并重写run()方法。该任务类负责将数据导入到Elasticsearch中。根据需求,可以将数据分批导入,也可以按照一定规则并发导入。
步骤4:创建线程池
创建一个线程池,用于管理多个线程执行数据导入任务。可以使用Java自带的ThreadPoolExecutor类来创建线程池,并根据需求设置线程池的大小、任务队列等相关参数。
步骤5:提交任务到线程池
将数据导入任务提交到线程池中执行。可以使用execute()方法提交任务,也可以使用submit()方法提交任务并获取返回结果。
步骤6:等待任务完成
使用CountDownLatch或其他同步工具等待所有的数据导入任务完成。可以通过调用shutdown()方法关闭线程池,并在主线程中调用awaitTermination()方法等待所有任务执行完成。
步骤7:关闭Elasticsearch客户端
在数据导入完成后,关闭与Elasticsearch服务器的连接,释放资源。
步骤8:处理导入结果
根据需要,可以在任务类中添加相应的处理逻辑,比如统计导入数据的成功和失败数量,打印异常信息等。
总结:
利用Java多线程技术导入数据到Elasticsearch的主要步骤包括引入依赖、创建Elasticsearch客户端、创建数据导入任务、创建线程池、提交任务到线程池、等待任务完成、关闭客户端和处理导入结果。根据具体需求,可以灵活调整以上步骤的顺序和细节。同时,还应注意线程安全和异常处理等问题,以保证数据导入的正确性和可靠性。
相关推荐
最新推荐
特别有用的MySQL数据实时同步到ES轻松配置手册
在当今大数据时代,实时数据同步成为许多企业和组织的关键需求,特别是从关系型数据库如 MySQL 到分布式搜索引擎如 ElasticSearch(ES)的实时同步。本文将详细介绍如何利用灵蜂数据集成软件 BeeDI 实现这一目标。 ...
Python对ElasticSearch获取数据及操作
在本文中,我们将深入探讨如何使用Python与Elasticsearch进行交互,特别是针对数据的获取和操作。首先,我们需要了解Python中的Elasticsearch库,它是连接和操作Elasticsearch的主要工具。在提供的代码示例中,我们...
elasticsearch中term与match的区别讲解
今天小编就为大家分享一篇关于elasticsearch中term与match的区别讲解,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧
SpringBoot中使用Jsoup爬取网站数据的方法
例如,可以使用SpringBoot的其他依赖,如`spring-boot-starter-data-redis`、`spring-boot-starter-data-elasticsearch`,来存储抓取的数据。如果需要展示数据,可以使用`spring-boot-starter-thymeleaf`或`spring-...
java使用es查询的示例代码
Elasticsearch 是用 Java 开发的,并作为 Apache 许可条款下的开放源码发布。 二、 Java 中使用 ES 在 Java 中使用 ES 可以解决查询速度不够快、效率不够高的问题。要使用 ES,首先需要添加 ES 的依赖包,依赖如下...
BSC关键绩效财务与客户指标详解
BSC(Balanced Scorecard,平衡计分卡)是一种战略绩效管理系统,它将企业的绩效评估从传统的财务维度扩展到非财务领域,以提供更全面、深入的业绩衡量。在提供的文档中,BSC绩效考核指标主要分为两大类:财务类和客户类。
1. 财务类指标:
- 部门费用的实际与预算比较:如项目研究开发费用、课题费用、招聘费用、培训费用和新产品研发费用,均通过实际支出与计划预算的百分比来衡量,这反映了部门在成本控制上的效率。
- 经营利润指标:如承保利润、赔付率和理赔统计,这些涉及保险公司的核心盈利能力和风险管理水平。
- 人力成本和保费收益:如人力成本与计划的比例,以及标准保费、附加佣金、续期推动费用等与预算的对比,评估业务运营和盈利能力。
- 财务效率:包括管理费用、销售费用和投资回报率,如净投资收益率、销售目标达成率等,反映公司的财务健康状况和经营效率。
2. 客户类指标:
- 客户满意度:通过包装水平客户满意度调研,了解产品和服务的质量和客户体验。
- 市场表现:通过市场销售月报和市场份额,衡量公司在市场中的竞争地位和销售业绩。
- 服务指标:如新契约标保完成度、续保率和出租率,体现客户服务质量和客户忠诚度。
- 品牌和市场知名度:通过问卷调查、公众媒体反馈和总公司级评价来评估品牌影响力和市场认知度。
BSC绩效考核指标旨在确保企业的战略目标与财务和非财务目标的平衡,通过量化这些关键指标,帮助管理层做出决策,优化资源配置,并驱动组织的整体业绩提升。同时,这份指标汇总文档强调了财务稳健性和客户满意度的重要性,体现了现代企业对多维度绩效管理的重视。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
【实战演练】俄罗斯方块:实现经典的俄罗斯方块游戏,学习方块生成和行消除逻辑。
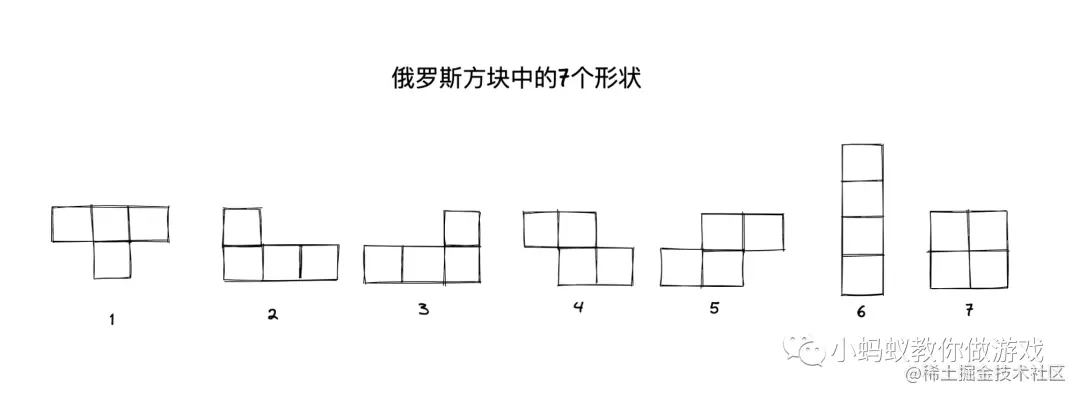
# 1. 俄罗斯方块游戏概述**
俄罗斯方块是一款经典的益智游戏,由阿列克谢·帕基特诺夫于1984年发明。游戏目标是通过控制不断下落的方块,排列成水平线,消除它们并获得分数。俄罗斯方块风靡全球,成为有史以来最受欢迎的视频游戏之一。
# 2.
卷积神经网络实现手势识别程序
卷积神经网络(Convolutional Neural Network, CNN)在手势识别中是一种非常有效的机器学习模型。CNN特别适用于处理图像数据,因为它能够自动提取和学习局部特征,这对于像手势这样的空间模式识别非常重要。以下是使用CNN实现手势识别的基本步骤:
1. **输入数据准备**:首先,你需要收集或获取一组带有标签的手势图像,作为训练和测试数据集。
2. **数据预处理**:对图像进行标准化、裁剪、大小调整等操作,以便于网络输入。
3. **卷积层(Convolutional Layer)**:这是CNN的核心部分,通过一系列可学习的滤波器(卷积核)对输入图像进行卷积,以
绘制企业战略地图:从财务到客户价值的六步法
"BSC资料.pdf"
战略地图是一种战略管理工具,它帮助企业将战略目标可视化,确保所有部门和员工的工作都与公司的整体战略方向保持一致。战略地图的核心内容包括四个相互关联的视角:财务、客户、内部流程和学习与成长。
1. **财务视角**:这是战略地图的最终目标,通常表现为股东价值的提升。例如,股东期望五年后的销售收入达到五亿元,而目前只有一亿元,那么四亿元的差距就是企业的总体目标。
2. **客户视角**:为了实现财务目标,需要明确客户价值主张。企业可以通过提供最低总成本、产品创新、全面解决方案或系统锁定等方式吸引和保留客户,以实现销售额的增长。
3. **内部流程视角**:确定关键流程以支持客户价值主张和财务目标的实现。主要流程可能包括运营管理、客户管理、创新和社会责任等,每个流程都需要有明确的短期、中期和长期目标。
4. **学习与成长视角**:评估和提升企业的人力资本、信息资本和组织资本,确保这些无形资产能够支持内部流程的优化和战略目标的达成。
绘制战略地图的六个步骤:
1. **确定股东价值差距**:识别与股东期望之间的差距。
2. **调整客户价值主张**:分析客户并调整策略以满足他们的需求。
3. **设定价值提升时间表**:规划各阶段的目标以逐步缩小差距。
4. **确定战略主题**:识别关键内部流程并设定目标。
5. **提升战略准备度**:评估并提升无形资产的战略准备度。
6. **制定行动方案**:根据战略地图制定具体行动计划,分配资源和预算。
战略地图的有效性主要取决于两个要素:
1. **KPI的数量及分布比例**:一个有效的战略地图通常包含20个左右的指标,且在四个视角之间有均衡的分布,如财务20%,客户20%,内部流程40%。
2. **KPI的性质比例**:指标应涵盖财务、客户、内部流程和学习与成长等各个方面,以全面反映组织的绩效。
战略地图不仅帮助管理层清晰传达战略意图,也使员工能更好地理解自己的工作如何对公司整体目标产生贡献,从而提高执行力和组织协同性。