帮我写一下renderJson方法
时间: 2024-01-25 21:04:30 浏览: 12
好的,以下是一个简单的 renderJson 方法的实现,用于将 JSON 数据渲染到 HTTP 响应中:
```java
public void renderJson(Object data) throws IOException {
HttpServletResponse response = getResponse();
response.setContentType("application/json;charset=utf-8");
PrintWriter out = response.getWriter();
out.print(JSON.toJSONString(data));
out.flush();
out.close();
}
```
在方法中,首先获取 HttpServletResponse 对象,设置响应类型为 JSON。然后将数据对象转换为 JSON 字符串,并将其输出到响应的输出流中,最后关闭输出流。注意,此方法需要处理 IOException 异常。
相关问题
jfinal+vue+el写一个项目demo
好的,下面我将为您提供一个简单的demo示例,使用jfinal+vue+el来实现一个用户管理系统。
1. 准备工作
首先,需要安装Java环境和Maven工具。然后,创建一个Maven项目,并添加以下依赖:
```xml
<dependency>
<groupId>com.jfinal</groupId>
<artifactId>jfinal</artifactId>
<version>4.9.06</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.78</version>
</dependency>
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.26</version>
</dependency>
```
2. 创建数据库表
在MySQL中创建一个名为user的表,包含以下字段:
- id
- username
- password
- nickname
- email
3. 创建后端代码
创建一个UserController类,用于处理用户相关的请求。
```java
public class UserController extends Controller {
public void index() {
render("index.html");
}
public void list() {
int pageNumber = getParaToInt("page");
int pageSize = getParaToInt("limit");
Page<User> userList = User.dao.paginate(pageNumber, pageSize, "select *", "from user");
renderJson(JSON.toJSONString(userList));
}
public void save() {
User user = getModel(User.class, "");
if (user.save()) {
renderJson(JSON.toJSONString(Result.success()));
} else {
renderJson(JSON.toJSONString(Result.failure("保存失败")));
}
}
public void update() {
User user = getModel(User.class, "");
if (user.update()) {
renderJson(JSON.toJSONString(Result.success()));
} else {
renderJson(JSON.toJSONString(Result.failure("更新失败")));
}
}
public void delete() {
Integer id = getParaToInt("id");
if (User.dao.deleteById(id)) {
renderJson(JSON.toJSONString(Result.success()));
} else {
renderJson(JSON.toJSONString(Result.failure("删除失败")));
}
}
}
```
创建一个User类,用于操作数据库。
```java
public class User extends Model<User> {
public static final User dao = new User().dao();
public Integer getId() {
return getInt("id");
}
public void setId(Integer id) {
set("id", id);
}
public String getUsername() {
return getStr("username");
}
public void setUsername(String username) {
set("username", username);
}
public String getPassword() {
return getStr("password");
}
public void setPassword(String password) {
set("password", password);
}
public String getNickname() {
return getStr("nickname");
}
public void setNickname(String nickname) {
set("nickname", nickname);
}
public String getEmail() {
return getStr("email");
}
public void setEmail(String email) {
set("email", email);
}
}
```
4. 创建前端代码
创建一个index.html文件,用于展示用户列表和添加用户。
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>User Management System</title>
<link rel="stylesheet" href="https://cdn.staticfile.org/element-ui/2.15.1/theme-chalk/index.css">
</head>
<body>
<div id="app">
<el-container>
<el-header>
<h1 style="color: white">用户管理系统</h1>
</el-header>
<el-main>
<el-table :data="userList" border style="width: 100%">
<el-table-column label="ID" prop="id"></el-table-column>
<el-table-column label="用户名" prop="username"></el-table-column>
<el-table-column label="昵称" prop="nickname"></el-table-column>
<el-table-column label="邮箱" prop="email"></el-table-column>
<el-table-column label="操作">
<template slot-scope="scope">
<el-button type="primary" @click="editUser(scope.row)">编辑</el-button>
<el-button type="danger" @click="deleteUser(scope.row)">删除</el-button>
</template>
</el-table-column>
</el-table>
<el-pagination :total="total" :page-size="pageSize" :current-page.sync="currentPage" @current-change="getPage"></el-pagination>
<el-form :model="user" ref="userForm" label-width="80px" style="margin-top: 20px;">
<el-form-item label="用户名" prop="username">
<el-input v-model="user.username" placeholder="请输入用户名"></el-input>
</el-form-item>
<el-form-item label="密码" prop="password">
<el-input v-model="user.password" placeholder="请输入密码"></el-input>
</el-form-item>
<el-form-item label="昵称" prop="nickname">
<el-input v-model="user.nickname" placeholder="请输入昵称"></el-input>
</el-form-item>
<el-form-item label="邮箱" prop="email">
<el-input v-model="user.email" placeholder="请输入邮箱"></el-input>
</el-form-item>
<el-form-item>
<el-button type="primary" @click="saveUser">保存</el-button>
<el-button @click="resetForm">重置</el-button>
</el-form-item>
</el-form>
</el-main>
</el-container>
</div>
<script src="https://cdn.staticfile.org/vue/2.6.14/vue.min.js"></script>
<script src="https://cdn.staticfile.org/element-ui/2.15.1/index.js"></script>
<script src="https://cdn.staticfile.org/axios/0.21.1/axios.min.js"></script>
<script type="text/javascript">
new Vue({
el: '#app',
data: {
userList: [],
total: 0,
pageSize: 10,
currentPage: 1,
user: {
username: '',
password: '',
nickname: '',
email: ''
}
},
created: function () {
this.getPage(1);
},
methods: {
getPage: function (page) {
let _this = this;
axios.get('/user/list', {
params: {
page: page,
limit: _this.pageSize
}
}).then(function (response) {
_this.userList = response.data.list;
_this.total = response.data.total;
}).catch(function (error) {
console.log(error);
});
},
editUser: function (row) {
this.user = row;
},
deleteUser: function (row) {
let _this = this;
let id = row.id;
axios.post('/user/delete', {
id: id
}).then(function (response) {
_this.getPage(_this.currentPage);
}).catch(function (error) {
console.log(error);
});
},
saveUser: function () {
let _this = this;
this.$refs.userForm.validate(function (valid) {
if (valid) {
axios.post('/user/save', _this.user).then(function (response) {
_this.getPage(_this.currentPage);
_this.resetForm('userForm');
}).catch(function (error) {
console.log(error);
});
} else {
return false;
}
});
},
resetForm: function (formName) {
this.$refs[formName].resetFields();
this.user = {
username: '',
password: '',
nickname: '',
email: ''
};
}
}
});
</script>
</body>
</html>
```
5. 配置路由
在JFinalConfig类中配置路由。
```java
public class DemoConfig extends JFinalConfig {
@Override
public void configConstant(Constants me) {
me.setDevMode(true);
}
@Override
public void configRoute(Routes me) {
me.add("/user", UserController.class);
}
@Override
public void configPlugin(Plugins me) {
DruidPlugin dp = new DruidPlugin("jdbc:mysql://localhost:3306/demo?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf-8", "root", "123456");
me.add(dp);
ActiveRecordPlugin arp = new ActiveRecordPlugin(dp);
me.add(arp);
arp.addMapping("user", User.class);
}
@Override
public void configInterceptor(Interceptors me) {
}
@Override
public void configHandler(Handlers me) {
}
}
```
6. 运行项目
运行项目,访问http://localhost:8080/user/index即可看到用户管理系统页面。
jfinal返回html源码,jfinal freemarker生成静态html完整例子!支持调用两次render效果,返回json数据。...
好的,针对您的问题,我提供以下代码示例:
1. 返回HTML源码
在JFinal中,我们可以使用render方法来返回HTML源码,示例代码如下:
```
public void index() {
renderHtml("<h1>Hello World!</h1>");
}
```
在上述示例中,我们使用renderHtml方法来返回HTML源码,方法中传入的参数为HTML代码。
2. JFinal Freemarker生成静态HTML完整例子
在JFinal中,我们可以使用Freemarker来生成静态HTML页面,示例代码如下:
```
public void index() {
// 设置模板文件路径
String templatePath = "/WEB-INF/templates/index.ftl";
// 获取数据
String data = "Hello World!";
// 设置输出文件路径
String outputPath = "/WEB-INF/output/index.html";
// 生成静态HTML页面
renderHtml(FreemarkerUtil.render(templatePath, data, outputPath));
}
```
在上述示例中,我们使用了一个名为FreemarkerUtil的工具类,示例代码如下:
```
public class FreemarkerUtil {
/**
* 渲染Freemarker模板
*
* @param templatePath 模板文件路径
* @param data 数据
* @param outputPath 输出文件路径
* @return 生成的HTML源码
*/
public static String render(String templatePath, Object data, String outputPath) {
try {
// 获取模板配置
Configuration config = new Configuration(Configuration.VERSION_2_3_30);
config.setServletContextForTemplateLoading(JFinal.me().getServletContext(), "/");
config.setDefaultEncoding("UTF-8");
// 获取模板
Template template = config.getTemplate(templatePath);
// 渲染模板
StringWriter writer = new StringWriter();
template.process(data, writer);
// 输出到文件
File outputFile = new File(JFinal.me().getServletContext().getRealPath(outputPath));
if (!outputFile.getParentFile().exists()) {
outputFile.getParentFile().mkdirs();
}
Writer fileWriter = new FileWriter(outputFile);
template.process(data, fileWriter);
fileWriter.flush();
fileWriter.close();
// 返回HTML源码
return writer.toString();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
```
在上述示例中,我们首先获取了模板配置并设置了模板文件路径和默认编码,然后获取了模板文件并渲染了数据。接着,我们将生成的HTML源码输出到文件,并返回HTML源码。
3. 支持调用两次render效果,返回JSON数据
在JFinal中,我们可以使用renderJson方法来返回JSON数据,示例代码如下:
```
public void index() {
// 设置模板文件路径
String templatePath = "/WEB-INF/templates/index.ftl";
// 获取数据
String data = "Hello World!";
// 设置输出文件路径
String outputPath = "/WEB-INF/output/index.html";
// 生成静态HTML页面
renderHtml(FreemarkerUtil.render(templatePath, data, outputPath));
// 返回JSON数据
renderJson("{\"status\":\"success\"}");
}
```
在上述示例中,我们首先使用renderHtml方法返回HTML源码,然后使用renderJson方法返回JSON数据。
注意:在JFinal中,只能调用一次render方法来返回响应,如果需要返回多个响应,可以使用renderXXX方法来返回。另外,如果需要在返回JSON数据之前生成静态HTML页面,可以使用renderNull方法来返回空响应。
相关推荐
最新推荐
play framework 框架个人笔记
- Controller类提供多种便利方法,如renderJSON()用于返回JSON,renderBinary()用于返回文件流。 5. **工具包**(play.libs.*) - 提供了一系列辅助库,例如加密、邮件发送、XML/JSON处理等功能。 6. **Play ...
基于springboot大学生智能消费记账系统的设计与实现.docx
基于springboot大学生智能消费记账系统的设计与实现.docx
基于Mnist数据集生成用于(多)目标检测的小型数据集.zip
1 目标检测的定义
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
目标检测任务可分为两个关键的子任务,目标定位和目标分类。首先检测图像中目标的位置(目标定位),然后给出每个目标的具体类别(目标分类)。输出结果是一个边界框(称为Bounding-box,一般形式为(x1,y1,x2,y2),表示框的左上角坐标和右下角坐标),一个置信度分数(Confidence Score),表示边界框中是否包含检测对象的概率和各个类别的概率(首先得到类别概率,经过Softmax可得到类别标签)。
1.1 Two stage方法
目前主流的基于深度学习的目标检测算法主要分为两类:Two stage和One stage。Two stage方法将目标检测过程分为两个阶段。第一个阶段是 Region Proposal 生成阶段,主要用于生成潜在的目标候选框(Bounding-box proposals)。这个阶段通常使用卷积神经网络(CNN)从输入图像中提取特征,然后通过一些技巧(如选择性搜索)来生成候选框。第二个阶段是分类和位置精修阶段,将第一个阶段生成的候选框输入到另一个 CNN 中进行分类,并根据分类结果对候选框的位置进行微调。Two stage 方法的优点是准确度较高,缺点是速度相对较慢。
常见Tow stage目标检测算法有:R-CNN系列、SPPNet等。
1.2 One stage方法
One stage方法直接利用模型提取特征值,并利用这些特征值进行目标的分类和定位,不需要生成Region Proposal。这种方法的优点是速度快,因为省略了Region Proposal生成的过程。One stage方法的缺点是准确度相对较低,因为它没有对潜在的目标进行预先筛选。
常见的One stage目标检测算法有:YOLO系列、SSD系列和RetinaNet等。
2 常见名词解释
2.1 NMS(Non-Maximum Suppression)
目标检测模型一般会给出目标的多个预测边界框,对成百上千的预测边界框都进行调整肯定是不可行的,需要对这些结果先进行一个大体的挑选。NMS称为非极大值抑制,作用是从众多预测边界框中挑选出最具代表性的结果,这样可以加快算法效率,其主要流程如下:
设定一个置信度分数阈值,将置信度分数小于阈值的直接过滤掉
将剩下框的置信度分数从大到小排序,选中值最大的框
遍历其余的框,如果和当前框的重叠面积(IOU)大于设定的阈值(一般为0.7),就将框删除(超过设定阈值,认为两个框的里面的物体属于同一个类别)
从未处理的框中继续选一个置信度分数最大的,重复上述过程,直至所有框处理完毕
2.2 IoU(Intersection over Union)
定义了两个边界框的重叠度,当预测边界框和真实边界框差异很小时,或重叠度很大时,表示模型产生的预测边界框很准确。边界框A、B的IOU计算公式为:
2.3 mAP(mean Average Precision)
mAP即均值平均精度,是评估目标检测模型效果的最重要指标,这个值介于0到1之间,且越大越好。mAP是AP(Average Precision)的平均值,那么首先需要了解AP的概念。想要了解AP的概念,还要首先了解目标检测中Precision和Recall的概念。
首先我们设置置信度阈值(Confidence Threshold)和IoU阈值(一般设置为0.5,也会衡量0.75以及0.9的mAP值):
当一个预测边界框被认为是True Positive(TP)时,需要同时满足下面三个条件:
Confidence Score > Confidence Threshold
预测类别匹配真实值(Ground truth)的类别
预测边界框的IoU大于设定的IoU阈值
不满足条件2或条件3,则认为是False Positive(FP)。当对应同一个真值有多个预测结果时,只有最高置信度分数的预测结果被认为是True Positive,其余被认为是False Positive。
Precision和Recall的概念如下图所示:
Precision表示TP与预测边界框数量的比值
Recall表示TP与真实边界框数量的比值
改变不同的置信度阈值,可以获得多组Precision和Recall,Recall放X轴,Precision放Y轴,可以画出一个Precision-Recall曲线,简称P-R
8051Proteus仿真c源码步进电机C版本
8051Proteus仿真c源码步进电机C版本提取方式是百度网盘分享地址
国内人气最高的Java人工智能算法框架 它可以Maven一键丝滑引入我们的Java项目,无需任何额外的环境配置与依赖,做到开箱即
国内人气最高的Java人工智能算法框架(java版pytorch)。它可以Maven一键丝滑引入我们的Java项目,无需任何额外的环境配置与依赖,做到开箱即用。再者,它既有一些我们已经封装好的图像目标检测及人工智能客服的模块,也提供各种深度学习,机器学习,强化学习,启发式学习,矩阵运算,求导函数,求偏导函数等底层算法工具。
计算机人脸表情动画技术发展综述
"这篇论文是关于计算机人脸表情动画技术的综述,主要探讨了近几十年来该领域的进展,包括基于几何学和基于图像的两种主要方法。作者姚俊峰和陈琪分别来自厦门大学软件学院,他们的研究方向涉及计算机图形学、虚拟现实等。论文深入分析了各种技术的优缺点,并对未来的发展趋势进行了展望。"
计算机人脸表情动画技术是计算机图形学的一个关键分支,其目标是创建逼真的面部表情动态效果。这一技术在电影、游戏、虚拟现实、人机交互等领域有着广泛的应用潜力,因此受到学术界和产业界的广泛关注。
基于几何学的方法主要依赖于对人体面部肌肉运动的精确建模。这种技术通常需要详细的人脸解剖学知识,通过数学模型来模拟肌肉的收缩和舒张,进而驱动3D人脸模型的表情变化。优点在于可以实现高度精确的表情控制,但缺点是建模过程复杂,对初始数据的需求高,且难以适应个体间的面部差异。
另一方面,基于图像的方法则侧重于利用实际的面部图像或视频来生成动画。这种方法通常包括面部特征检测、表情识别和实时追踪等步骤。通过机器学习和图像处理技术,可以从输入的图像中提取面部特征点,然后将这些点的变化映射到3D模型上,以实现表情的动态生成。这种方法更灵活,能较好地处理个体差异,但可能受光照、角度和遮挡等因素影响,导致动画质量不稳定。
论文中还可能详细介绍了各种代表性的算法和技术,如线性形状模型(LBS)、主动形状模型(ASM)、主动外观模型(AAM)以及最近的深度学习方法,如卷积神经网络(CNN)在表情识别和生成上的应用。同时,作者可能也讨论了如何解决实时性和逼真度之间的平衡问题,以及如何提升面部表情的自然过渡和细节表现。
未来,人脸表情动画技术的发展趋势可能包括更加智能的自动化建模工具,更高精度的面部捕捉技术,以及深度学习等人工智能技术在表情生成中的进一步应用。此外,跨学科的合作,如神经科学、心理学与计算机科学的结合,有望推动这一领域取得更大的突破。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
实时处理中的数据流管理:高效流动与网络延迟优化
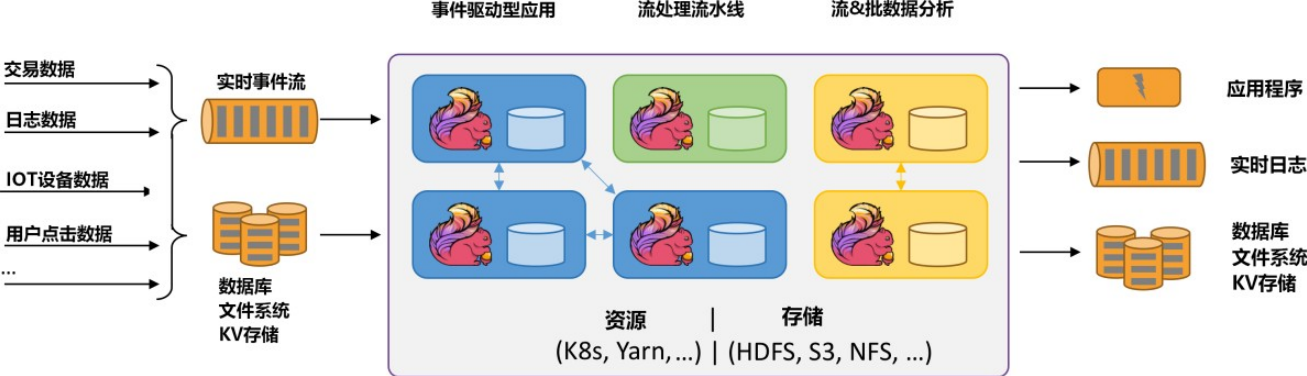
# 1. 数据流管理的理论基础
数据流管理是现代IT系统中处理大量实时数据的核心环节。在本章中,我们将探讨数据流管理的基本概念、重要性以及它如何在企业级应用中发挥作用。我们首先会介绍数据流的定义、它的生命周期以及如何在不同的应用场景中传递信息。接下来,本章会分析数据流管理的不同层面,包括数据的捕获、存储、处理和分析。此外,我们也会讨论数据流的特性,比如它的速度
如何确认skopt库是否已成功安装?
skopt库,全称为Scikit-Optimize,是一个用于贝叶斯优化的库。要确认skopt库是否已成功安装,可以按照以下步骤操作:
1. 打开命令行工具,例如在Windows系统中可以使用CMD或PowerShell,在Unix-like系统中可以使用Terminal。
2. 输入命令 `python -m skopt` 并执行。如果安装成功,该命令将会显示skopt库的版本信息以及一些帮助信息。如果出现 `ModuleNotFoundError` 错误,则表示库未正确安装。
3. 你也可以在Python环境中导入skopt库来测试,运行如下代码:
```python
i
关系数据库的关键字搜索技术综述:模型、架构与未来趋势
本文档深入探讨了"基于关键字的数据库搜索研究综述"这一主题,重点关注于关系数据库领域的关键技术。首先,作者从数据建模的角度出发,概述了关键字搜索在关系数据库中的应用,包括如何设计和构建有效的数据模型,以便更好地支持关键字作为查询条件进行高效检索。这些模型可能涉及索引优化、数据分区和规范化等,以提升查询性能和查询结果的相关性。
在体系结构方面,文章对比了不同的系统架构,如全文搜索引擎与传统的关系型数据库管理系统(RDBMS)的融合,以及基于云计算或分布式计算环境下的关键字搜索解决方案。这些架构的选择和设计对于系统的扩展性、响应时间和查询复杂度有重大影响。
关键算法部分是研究的核心,文章详细分析了诸如倒排索引、布尔逻辑运算、TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)等算法在关键字搜索中的作用。同时,也讨论了近似匹配、模糊查询以及动态调整权重等技术,这些都是为了提高搜索的准确性和用户体验。
然而,论文并未忽视现有技术存在的问题,比如查询效率低下、对自然语言理解的局限、数据隐私保护等。针对这些问题,作者提出了未来研究的方向,包括但不限于改进算法以提升搜索速度,增强对用户查询意图的理解,以及开发更安全的隐私保护策略。
此外,本文还提及了关键词搜索的关键术语,如"top-k查询",这是一种返回最相关结果前k个的查询方式,常用于信息检索和推荐系统中。而"数据库模式"则涵盖了数据结构和组织方式,是实现关键字搜索的基础。
这篇综述论文旨在为研究人员和开发者提供一个全面的视角,以便他们能够理解基于关键字的数据库搜索技术的现状,识别挑战,并推动该领域未来的发展。通过阅读这篇论文,读者可以了解到如何设计更智能、更高效的数据库搜索系统,以满足日益增长的数据处理需求。