实时处理中的数据流管理:高效流动与网络延迟优化


远程debug流程,方便debug
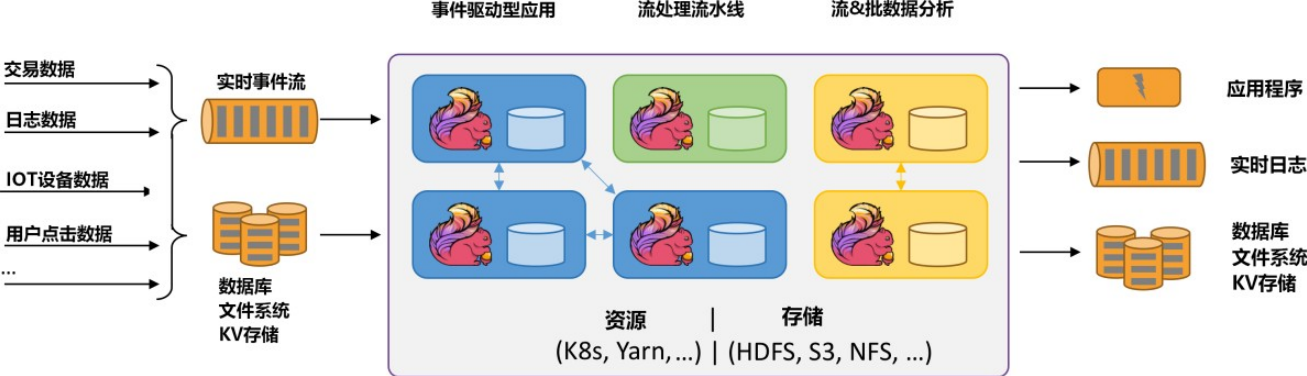
1. 数据流管理的理论基础
数据流管理是现代IT系统中处理大量实时数据的核心环节。在本章中,我们将探讨数据流管理的基本概念、重要性以及它如何在企业级应用中发挥作用。我们首先会介绍数据流的定义、它的生命周期以及如何在不同的应用场景中传递信息。接下来,本章会分析数据流管理的不同层面,包括数据的捕获、存储、处理和分析。此外,我们也会讨论数据流的特性,比如它的速度、大小和多样性,这些因素都会对数据流管理策略产生直接影响。最后,本章将提供一个概览,引导读者理解后续章节中将深入讨论的实时数据流处理技术、网络延迟优化策略以及数据流处理的实践案例。通过对数据流管理理论基础的掌握,读者将对如何有效利用数据流产生更深刻的认识,并为深入学习本教程中的高级主题打下坚实的基础。
2. 实时数据流的处理技术
2.1 数据流模型的构建
2.1.1 数据流图的创建与解析
构建数据流图是理解数据流动和处理过程的首要步骤,它是对系统中数据流动和处理过程的图形化表示。数据流图(DFG)展示了数据从源点出发,经过各个处理节点,最终达到终点的路径。一个基本的数据流图通常包含数据源、数据处理器、数据存储和数据流等元素。
在创建数据流图时,首先需要确定数据流模型的边界,明确哪些组件是外部的,哪些是内部的。接着,识别出系统中的所有数据源和数据接收点,并标注好各种数据流的路径。此外,重要的是确保每个数据处理器的逻辑都得到正确的表示,因为它们定义了数据如何被处理和转换。
下面是一个简化的数据流图创建的代码示例,它使用了假想的系统来展示数据流图的构建过程:
- import matplotlib.pyplot as plt
- # 创建数据源、处理器和目的地
- source = 'Data Source'
- processes = ['Processor A', 'Processor B', 'Processor C']
- sink = 'Data Sink'
- # 构建数据流图
- plt.figure(figsize=(8, 4))
- plt.subplot(1, 3, 1)
- plt.title('Data Flow Graph Creation')
- plt.plot([1, 2], [1, 1], 'k-') # 数据流
- plt.plot(1, 1, 'bo', label=source) # 数据源
- plt.plot(2, 1, 'bs', label=sink) # 数据目的地
- plt.subplot(1, 3, 2)
- plt.plot([1, 2], [1, 1], 'k-')
- plt.plot(1, 1, 'bo', label=processes[0])
- plt.plot(2, 1, 'bs', label=processes[1])
- plt.subplot(1, 3, 3)
- plt.plot([1, 2], [1, 1], 'k-')
- plt.plot(1, 1, 'bo', label=sink)
- plt.plot(2, 1, 'bs', label=processes[2])
- # 添加图例
- for i in range(1, 4):
- plt.subplot(1, 3, i)
- plt.legend()
- plt.show()
这个图示代码利用了matplotlib来生成三个简单的数据流图,分别展示了数据源、处理器和目的地之间以及它们内部的数据流关系。在实际应用中,数据流图会更复杂,包含多个源点、中间处理点和终点,但原理相同。
2.1.2 数据流的分类与特性
数据流可以按照多个维度进行分类,例如,按照数据的产生速度可以分为批处理数据流和实时数据流;按照数据的结构可以分为结构化数据流、半结构化数据流和非结构化数据流。
批处理数据流通常用于离线分析,而实时数据流则是即时处理和分析数据的关键。实时数据流的一个关键特性是低延迟性,这意味着系统能够快速响应数据的产生并进行处理。结构化数据流通常可以通过固定的模式来解析,如CSV或JSON格式的数据,而半结构化和非结构化数据则需要更复杂的解析技术。
数据流的另一个重要特性是持续性,即数据流是持续不断产生的。处理实时数据流需要系统能够稳定地持续接收和处理数据,即使在流量激增的情况下也不会丢失数据。此外,数据流的规模也是其一个特性,随着数据量的不断增长,如何设计可扩展的数据流系统成为了挑战。
2.2 实时数据处理的算法
2.2.1 时间窗口技术
时间窗口是实时数据处理中用于定义一段时间内数据集的概念。根据时间窗口的不同类型,可以将数据流算法分为滑动窗口、跳跃窗口和会话窗口等。
滑动窗口是一种常用的时间窗口技术,它按照固定的时间间隔来定义窗口,并在每个时间点移动窗口以包含最新的数据。这种方法适用于对最近的数据感兴趣的应用场景。
下面展示的是一个滑动窗口算法的伪代码实现:
- # 滑动窗口伪代码示例
- def sliding_window(data_stream, window_size, step):
- """
- data_stream: 数据流
- window_size: 窗口大小
- step: 窗口移动步长
- """
- window_start = 0
- while window_start < len(data_stream):
- window_end = min(window_start + window_size, len(data_stream))
- process(data_stream[window_start:window_end]) # 处理窗口内的数据
- window_start += step # 窗口向前移动
这个伪代码展示了如何处理滑动窗口中的数据流,窗口大小和步长可根据实际需求来定义。滑动窗口算法的实现适用于需要对实时数据流进行快速分析的场景,如股票市场分析、网络流量监控等。
2.2.2 流数据聚合策略
流数据聚合是指对实时数据流进行归纳和汇总,以便更易于管理和分析。常见的聚合策略包括计数、求和、平均值计算以及使用更高级的统计函数。
聚合策略通常结合时间窗口技术一起使用,可以有效地对数据流进行降维处理,减少存储和计算的开销。例如,在分析网络流量时,可能只需要每隔一定时间计算一下通过量的平均值,而不需要保存每个数据点。
下面是一个流数据聚合策略的代码示例,使用Python进行聚合计算:
- import pandas as pd
- # 假设我们有连续的数据点
- data_points = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
- # 将数据点存入时间序列数据结构中
- data_series = pd.Series(data_points)
- # 聚合策略示例:计算滑动窗口内的平均值
- window_size = 3
- averages = data_series.rolling(window=window_size).mean()
- # 打印计算结果
- print(averages)
在这个例子中,使用了Pandas库提供的滚动窗口(rolling window)功能来计算滑动窗口内的平均值。这样的聚合策略大大简化了实时数据流的处理工作。
2.2.3 异常检测与处理
异常检测是实时数据流处理中的重要环节,它可以帮助系统及

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
C语言实用技巧:如何用代码实现先来先服务(FCFS)磁盘调度?(无需等待的秘密)
【伺服驱动器故障速查手册】:15分钟快速诊断与修复指南
【需求捕获与控制】
【Canoco优化秘籍】:高级技巧提升CCA分析效率
【SIP协议深度剖析】:20年技术大佬带你从基础到前沿
Ubuntu系统CloudStack部署速成课:系统优化与性能调整秘籍
深入理解Intouch SCADA系统:掌握与PLC通讯的高级技巧
【Gephi插件生态解析】:扩展功能与定制化分析
提升统计学习效率:ESLII_print12《统计学习的元素》实战策略
【7系列FPGA数据接口高级特性解析】:5个高级功能,让你的设计更上一层楼


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )