``` def make_layers(self): ```
时间: 2024-08-13 07:01:21 浏览: 33
```python
# 定义一个名为make_layers的函数,通常在深度学习模型中用于构建网络结构或堆叠层
def make_layers(self):
```
在这个函数中,`self` 是一个指向类实例的引用,这个方法可能是某个神经网络模型中的内部方法,它会根据模型的设计来创建并返回一系列的网络层(layers)。通过调用这个函数,模型可以动态地构造其架构,适应不同的输入和输出需求。例如,在卷积神经网络(CNN)中,可能会有卷积层、池化层、全连接层等,每个层级的参数可能需要根据训练数据进行调整。
相关问题
帮我为下面的代码加上注释:class SimpleDeepForest: def __init__(self, n_layers): self.n_layers = n_layers self.forest_layers = [] def fit(self, X, y): X_train = X for _ in range(self.n_layers): clf = RandomForestClassifier() clf.fit(X_train, y) self.forest_layers.append(clf) X_train = np.concatenate((X_train, clf.predict_proba(X_train)), axis=1) return self def predict(self, X): X_test = X for i in range(self.n_layers): X_test = np.concatenate((X_test, self.forest_layers[i].predict_proba(X_test)), axis=1) return self.forest_layers[-1].predict(X_test[:, :-2]) # 1. 提取序列特征(如:GC-content、序列长度等) def extract_features(fasta_file): features = [] for record in SeqIO.parse(fasta_file, "fasta"): seq = record.seq gc_content = (seq.count("G") + seq.count("C")) / len(seq) seq_len = len(seq) features.append([gc_content, seq_len]) return np.array(features) # 2. 读取相互作用数据并创建数据集 def create_dataset(rna_features, protein_features, label_file): labels = pd.read_csv(label_file, index_col=0) X = [] y = [] for i in range(labels.shape[0]): for j in range(labels.shape[1]): X.append(np.concatenate([rna_features[i], protein_features[j]])) y.append(labels.iloc[i, j]) return np.array(X), np.array(y) # 3. 调用SimpleDeepForest分类器 def optimize_deepforest(X, y): X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) model = SimpleDeepForest(n_layers=3) model.fit(X_train, y_train) y_pred = model.predict(X_test) print(classification_report(y_test, y_pred)) # 4. 主函数 def main(): rna_fasta = "RNA.fasta" protein_fasta = "pro.fasta" label_file = "label.csv" rna_features = extract_features(rna_fasta) protein_features = extract_features(protein_fasta) X, y = create_dataset(rna_features, protein_features, label_file) optimize_deepforest(X, y) if __name__ == "__main__": main()
# Define a class named 'SimpleDeepForest'
class SimpleDeepForest:
# Initialize the class with 'n_layers' parameter
def __init__(self, n_layers):
self.n_layers = n_layers
self.forest_layers = []
# Define a method named 'fit' to fit the dataset into the classifier
def fit(self, X, y):
X_train = X
# Use the forest classifier to fit the dataset for 'n_layers' times
for _ in range(self.n_layers):
clf = RandomForestClassifier()
clf.fit(X_train, y)
# Append the classifier to the list of forest layers
self.forest_layers.append(clf)
# Concatenate the training data with the predicted probability of the last layer
X_train = np.concatenate((X_train, clf.predict_proba(X_train)), axis=1)
# Return the classifier
return self
# Define a method named 'predict' to make predictions on the test set
def predict(self, X):
X_test = X
# Concatenate the test data with the predicted probability of each layer
for i in range(self.n_layers):
X_test = np.concatenate((X_test, self.forest_layers[i].predict_proba(X_test)), axis=1)
# Return the predictions of the last layer
return self.forest_layers[-1].predict(X_test[:, :-2])
# Define a function named 'extract_features' to extract sequence features
def extract_features(fasta_file):
features = []
# Parse the fasta file to extract sequence features
for record in SeqIO.parse(fasta_file, "fasta"):
seq = record.seq
gc_content = (seq.count("G") + seq.count("C")) / len(seq)
seq_len = len(seq)
features.append([gc_content, seq_len])
# Return the array of features
return np.array(features)
# Define a function named 'create_dataset' to create the dataset
def create_dataset(rna_features, protein_features, label_file):
labels = pd.read_csv(label_file, index_col=0)
X = []
y = []
# Create the dataset by concatenating the RNA and protein features
for i in range(labels.shape[0]):
for j in range(labels.shape[1]):
X.append(np.concatenate([rna_features[i], protein_features[j]]))
y.append(labels.iloc[i, j])
# Return the array of features and the array of labels
return np.array(X), np.array(y)
# Define a function named 'optimize_deepforest' to optimize the deep forest classifier
def optimize_deepforest(X, y):
# Split the dataset into training set and testing set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Create an instance of the SimpleDeepForest classifier with 3 layers
model = SimpleDeepForest(n_layers=3)
# Fit the training set into the classifier
model.fit(X_train, y_train)
# Make predictions on the testing set
y_pred = model.predict(X_test)
# Print the classification report
print(classification_report(y_test, y_pred))
# Define the main function to run the program
def main():
rna_fasta = "RNA.fasta"
protein_fasta = "pro.fasta"
label_file = "label.csv"
# Extract the RNA and protein features
rna_features = extract_features(rna_fasta)
protein_features = extract_features(protein_fasta)
# Create the dataset
X, y = create_dataset(rna_features, protein_features, label_file)
# Optimize the DeepForest classifier
optimize_deepforest(X, y)
# Check if the program is being run as the main program
if __name__ == "__main__":
main()
这段代码怎么拆分成单独的层class resnet50_Decoder(nn.Module): def __init__(self, inplanes, bn_momentum=0.1): super(resnet50_Decoder, self).__init__() self.bn_momentum = bn_momentum self.inplanes = inplanes self.deconv_with_bias = False #----------------------------------------------------------# # 16,16,2048 -> 32,32,256 -> 64,64,128 -> 128,128,64 # 利用ConvTranspose2d进行上采样。 # 每次特征层的宽高变为原来的两倍。 #----------------------------------------------------------# self.deconv_layers = self._make_deconv_layer( num_layers=3, num_filters=[256, 128, 64], num_kernels=[4, 4, 4], ) def _make_deconv_layer(self, num_layers, num_filters, num_kernels): layers = [] for i in range(num_layers): kernel = num_kernels[i] planes = num_filters[i] layers.append( nn.ConvTranspose2d( in_channels=self.inplanes, out_channels=planes, kernel_size=kernel, stride=2, padding=1, output_padding=0, bias=self.deconv_with_bias)) layers.append(nn.BatchNorm2d(planes, momentum=self.bn_momentum)) layers.append(nn.ReLU(inplace=True)) self.inplanes = planes return nn.Sequential(*layers) def forward(self, x): return self.deconv_layers(x)
可以将这段代码拆分成以下两个类:
1. DeconvLayer(nn.Module):此类用于实现ConvTranspose2d、BatchNorm2d和ReLU激活函数的组合,即一层上采样层。其构造函数需要传入in_channels、out_channels、kernel_size、stride、padding、output_padding和bn_momentum等参数。
2. ResNet50Decoder(nn.Module):此类用于实现ResNet50的解码器部分,即利用DeconvLayer对ResNet50的特征图进行上采样,得到最终的输出结果。其构造函数需要传入inplanes和bn_momentum等参数。
以下是代码示例:
```python
class DeconvLayer(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, output_padding, bn_momentum=0.1, bias=False):
super(DeconvLayer, self).__init__()
self.conv_transpose = nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, padding, output_padding, bias=bias)
self.bn = nn.BatchNorm2d(out_channels, momentum=bn_momentum)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv_transpose(x)
x = self.bn(x)
x = self.relu(x)
return x
class ResNet50Decoder(nn.Module):
def __init__(self, inplanes, bn_momentum=0.1):
super(ResNet50Decoder, self).__init__()
self.bn_momentum = bn_momentum
self.inplanes = inplanes
self.deconv_with_bias = False
self.deconv_layers = self._make_deconv_layer(
num_layers=3,
num_filters=[256, 128, 64],
num_kernels=[4, 4, 4],
)
def _make_deconv_layer(self, num_layers, num_filters, num_kernels):
layers = []
for i in range(num_layers):
kernel = num_kernels[i]
planes = num_filters[i]
layers.append(DeconvLayer(
in_channels=self.inplanes,
out_channels=planes,
kernel_size=kernel,
stride=2,
padding=1,
output_padding=0,
bn_momentum=self.bn_momentum,
bias=self.deconv_with_bias
))
self.inplanes = planes
return nn.Sequential(*layers)
def forward(self, x):
return self.deconv_layers(x)
```
相关推荐
最新推荐
基于opencv实现象棋识别及棋谱定位python源码+数据集-人工智能课程设计
基于opencv实现象棋识别及棋谱定位python源码+数据集-人工智能课程设计,含有代码注释,满分课程设计资源,新手也可看懂,期末大作业、课程设计、高分必看,下载下来,简单部署,就可以使用。该项目可以作为课程设计期末大作业使用,该系统功能完善、界面美观、操作简单、功能齐全、管理便捷,具有很高的实际应用价值。
基于opencv实现象棋识别及棋谱定位python源码+数据集-人工智能课程设计,含有代码注释,满分课程设计资源,新手也可看懂,期末大作业、课程设计、高分必看,下载下来,简单部署,就可以使用。该项目可以作为课程设计期末大作业使用,该系统功能完善、界面美观、操作简单、功能齐全、管理便捷,具有很高的实际应用价值。
基于opencv实现象棋识别及棋谱定位python源码+数据集-人工智能课程设计,含有代码注释,满分课程设计资源,新手也可看懂,期末大作业、课程设计、高分必看,下载下来,简单部署,就可以使用。该项目可以作为课程设计期末大作业使用,该系统功能完善、界面美观、操作简单、功能齐全、管理便捷,具有很高的实际应用价值。基于opencv实现象棋识别及棋谱定位python源码+数据集
基于Python实现的Cowrie蜜罐设计源码
该项目为基于Python实现的Cowrie蜜罐设计源码,共计380个文件,涵盖166个Python源代码文件,以及包括RST、SQL、YAML、Markdown等多种类型的配置和文档文件。Cowrie蜜罐是一款用于记录暴力攻击和攻击者执行的SSH及Telnet交互的中等交互式蜜罐。
QT 摄像头获取每一帧图像数据以及opencv获取清晰度
QT 摄像头获取每一帧图像数据以及opencv获取清晰度
基于asp.net的(CS)地震预测系统设计与实现.docx
基于asp.net的(CS)地震预测系统设计与实现.docx
基于Springboot和Mysql的医院药品管理系统代码(程序,中文注释)
医院药品管理系统-医院药品管理系统-医院药品管理系统-医院药品管理系统-医院药品管理系统-医院药品管理系统-医院药品管理系统-医院药品管理系统-医院药品管理系统-医院药品管理系统-医院药品管理系统-医院药品管理系统
1、资源说明:医院药品管理系统源码,本资源内项目代码都经过测试运行成功,功能ok的情况下才上传的。
2、适用人群:计算机相关专业(如计算计、信息安全、大数据、人工智能、通信、物联网、自动化、电子信息等)在校学生、专业老师或者企业员工等学习者,作为参考资料,进行参考学习使用。
3、资源用途:本资源具有较高的学习借鉴价值,可以作为“参考资料”,注意不是“定制需求”,代码只能作为学习参考,不能完全复制照搬。需要有一定的基础,能够看懂代码,能够自行调试代码,能够自行添加功能修改代码。
4. 最新计算机软件毕业设计选题大全(文章底部有博主联系方式):
https://blog.csdn.net/2301_79206800/article/details/135931154
技术栈、环境、工具、软件:
① 系统环境:Windows
② 开发语言:Java
③ 框架:SpringBo
批量文件重命名神器:HaoZipRename使用技巧
资源摘要信息:"超实用的批量文件改名字小工具rename"
在进行文件管理时,经常会遇到需要对大量文件进行重命名的场景,以统一格式或适应特定的需求。此时,批量重命名工具成为了提高工作效率的得力助手。本资源聚焦于介绍一款名为“rename”的批量文件改名工具,它支持增删查改文件名,并能够方便地批量操作,从而极大地简化了文件管理流程。
### 知识点一:批量文件重命名的需求与场景
在日常工作中,无论是出于整理归档的目的还是为了符合特定的命名规则,批量重命名文件都是一个常见的需求。例如:
- 企业或组织中的文件归档,可能需要按照特定的格式命名,以便于管理和检索。
- 在处理下载的多媒体文件时,可能需要根据文件类型、日期或其他属性重新命名。
- 在软件开发过程中,对代码文件或资源文件进行统一的命名规范。
### 知识点二:rename工具的基本功能
rename工具专门设计用来处理文件名的批量修改,其基本功能包括但不限于:
- **批量修改**:一次性对多个文件进行重命名。
- **增删操作**:在文件名中添加或删除特定的文本。
- **查改功能**:查找文件名中的特定文本并将其替换为其他文本。
- **格式统一**:为一系列文件统一命名格式。
### 知识点三:使用rename工具的具体操作
以rename工具进行批量文件重命名通常遵循以下步骤:
1. 选择文件:根据需求选定需要重命名的文件列表。
2. 设定规则:定义重命名的规则,比如在文件名前添加“2023_”,或者将文件名中的“-”替换为“_”。
3. 执行重命名:应用设定的规则,批量修改文件名。
4. 预览与确认:在执行之前,工具通常会提供预览功能,允许用户查看重命名后的文件名,并进行最终确认。
### 知识点四:rename工具的使用场景
rename工具在不同的使用场景下能够发挥不同的作用:
- **IT行业**:对于软件开发者或系统管理员来说,批量重命名能够快速调整代码库中文件的命名结构,或者修改服务器上的文件名。
- **媒体制作**:视频编辑和摄影师经常需要批量重命名图片和视频文件,以便更好地进行分类和检索。
- **教育与学术**:教授和研究人员可能需要批量重命名大量的文档和资料,以符合学术规范或方便资料共享。
### 知识点五:rename工具的高级特性
除了基本的批量重命名功能,一些高级的rename工具可能还具备以下特性:
- **正则表达式支持**:利用正则表达式可以进行复杂的查找和替换操作。
- **模式匹配**:可以定义多种匹配模式,满足不同的重命名需求。
- **图形用户界面**:提供直观的操作界面,简化用户的操作流程。
- **命令行操作**:对于高级用户,可以通过命令行界面进行更为精准的定制化操作。
### 知识点六:与rename相似的其他批量文件重命名工具
除了rename工具之外,还有多种其他工具可以实现批量文件重命名的功能,如:
- **Bulk Rename Utility**:一个功能强大的批量重命名工具,特别适合Windows用户。
- **Advanced Renamer**:提供图形界面,并支持脚本,用户可以创建复杂的重命名方案。
- **MMB Free Batch Rename**:一款免费且易于使用的批量重命名工具,具有直观的用户界面。
### 知识点七:避免批量重命名中的常见错误
在使用批量重命名工具时,有几个常见的错误需要注意:
- **备份重要文件**:在批量重命名之前,确保对文件进行了备份,以防意外发生。
- **仔细检查规则**:设置好规则之后,一定要进行检查,确保规则的准确性,以免出现错误的命名。
- **逐步执行**:如果不确定规则的效果,可以先小批量试运行规则,确认无误后再批量执行。
- **避免使用通配符**:在没有充分理解通配符含义的情况下,不建议使用,以免误操作。
综上所述,批量文件改名工具rename是一个高效、便捷的解决方案,用于处理大量文件的重命名工作。通过掌握其使用方法和技巧,用户可以显著提升文件管理的效率,同时减少重复劳动,保持文件系统的整洁和有序。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
RestTemplate性能优化秘籍:提升API调用效率,打造极致响应速度
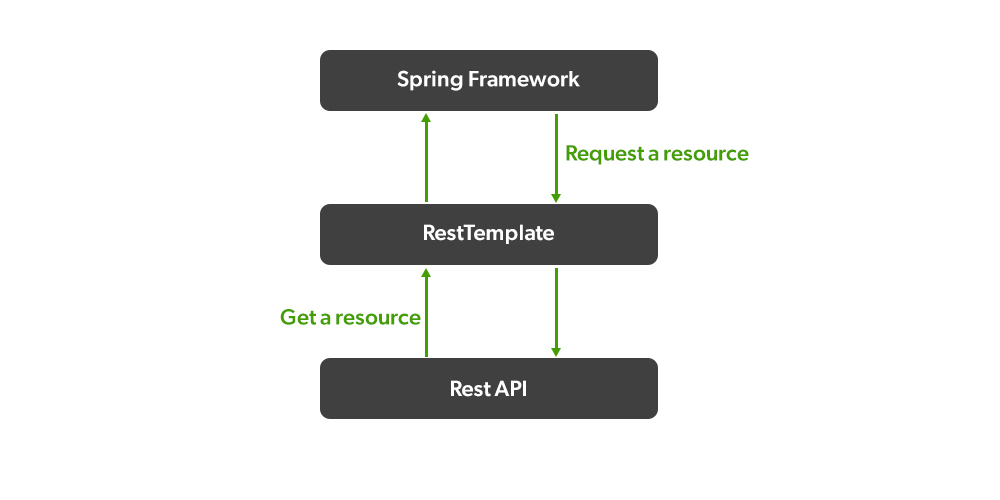
# 1. RestTemplate基础与API调用概述
## 1.1 RestTemplate简介
`RestTemplate`是Spring框架提供的一个同步HTTP客户端,设计用来简化客户端HTTP请求的发送以及HTTP响应的接收。它是针对Java开发者的REST API调用的高级抽象,为调用RESTful服务提供了便利。
Leader和follower 位置反了如何调换zookeeper
在ZooKeeper中,Leader和Follower的角色通常是静态分配的,并通过选举机制确定。如果需要调整它们的位置,通常是在集群初始化或者节点失效的情况下,会触发重新选举过程。
1. **停止服务**:首先,停止ZooKeeper服务的所有节点,包括当前的Leader和Follower。
2. **修改配置**:打开zoo.cfg配置文件,更改服务器列表(server.X=IP:port:角色),将原来的Leader的地址设为Follower,Follower的地址设为Leader。例如:
```
server.1=old_leader_ip:old_leader_po
简洁注册登录界面设计与代码实现
资源摘要信息:"在现代Web开发中,简洁美观的注册登录页面是用户界面设计的重要组成部分。简洁的页面设计不仅能够提升用户体验,还能提高用户完成注册或登录流程的意愿。本文将详细介绍如何创建两个简洁且功能完善的注册登录页面,涉及HTML5和前端技术。"
### 知识点一:HTML5基础
- **语义化标签**:HTML5引入了许多新标签,如`<header>`、`<footer>`、`<article>`、`<section>`等,这些语义化标签不仅有助于页面结构的清晰,还有利于搜索引擎优化(SEO)。
- **表单标签**:`<form>`标签是创建注册登录页面的核心,配合`<input>`、`<button>`、`<label>`等元素,可以构建出功能完善的表单。
- **增强型输入类型**:HTML5提供了多种新的输入类型,如`email`、`tel`、`number`等,这些类型可以提供更好的用户体验和数据校验。
### 知识点二:前端技术
- **CSS3**:简洁的页面设计往往需要巧妙的CSS布局和样式,如Flexbox或Grid布局技术可以实现灵活的页面布局,而CSS3的动画和过渡效果则可以提升交云体验。
- **JavaScript**:用于增加页面的动态功能,例如表单验证、响应式布局切换、与后端服务器交互等。
### 知识点三:响应式设计
- **媒体查询**:使用CSS媒体查询可以创建响应式设计,确保注册登录页面在不同设备上都能良好显示。
- **流式布局**:通过设置百分比宽度或视口单位(vw/vh),使得页面元素可以根据屏幕大小自动调整大小。
### 知识点四:注册登录页面设计细节
- **界面简洁性**:避免过多的装饰性元素,保持界面的整洁和专业感。
- **易用性**:设计简洁直观的用户交互,确保用户能够轻松理解和操作。
- **安全性和隐私**:注册登录页面应特别注意用户数据的安全,如使用HTTPS协议保护数据传输,以及在前端进行基本的输入验证。
### 知识点五:Zip文件内容解析
- **登录.zip**:该压缩包内可能包含登录页面的HTML、CSS和JavaScript文件,以及相关的图片和其他资源文件。开发者可以利用这些资源快速搭建一个登录界面。
- **滑动登录注册界面.zip**:该压缩包内可能包含了两个页面的文件,分别是注册和登录页面。文件可能包含用HTML5实现的滑动动画效果,通过CSS3和JavaScript的结合实现动态交互,提供更流畅的用户体验。
通过这些知识点,开发者能够创建出既简洁又功能完善的注册登录页面。需要注意的是,尽管页面设计要简洁,但安全措施不可忽视。使用加密技术保护用户数据,以及在用户端进行有效的数据验证,都是开发者在实现简洁界面同时需要考虑的安全要素。