python爬虫爬取电影数据
时间: 2023-09-03 07:10:28 浏览: 287

python多线程爬虫爬取电影天堂资源
要使用Python爬虫来爬取电影数据,你可以按照以下步骤进行操作:
1. 首先,你需要打开一个文件对象,并以追加的形式打开一个名为"data.csv"的文件。然后,使用csv库的writer方法创建一个csv_writer对象来写入数据。接下来,你可以使用正则表达式来提取电影数据,并将提取的值写入到"data.csv"文件中。代码示例如下:
```
# 以追加的形式打开文件对象
f = open('data.csv', mode='a')
csv_write = csv.writer(f)
# 使用正则表达式提取电影数据并写入文件
for it in p.finditer(response.text):
# 将迭代器it转换为字典
dic = it.groupdict()
# 对键为year的值去除空格
dic['year'] = dic['year'].strip()
# 将字典的values写入data.csv
csv_write.writerow(dic.values())
print('写入完成')
```
这段代码会将提取的电影数据写入到"data.csv"文件中。
2. 其次,你可以定义一个名为"boxoffice"的函数,用来爬取电影的票房数据。你需要通过访问"http://58921.com/boxoffice"网页来获取数据,并使用XPath表达式(//*[@id="2"]/div/h3/text())来提取票房数据。代码示例如下:
```
def boxoffice(url):
# 票房数据的URL
boxoffice_url = 'http://58921.com/boxoffice'
# 发送请求并提取数据
response = requests.get(boxoffice_url)
result = get_page(response.text, boxoffice_regex)
return result<span class="em">1</span><span class="em">2</span><span class="em">3</span>
#### 引用[.reference_title]
- *1* *3* [Python爬虫:爬取电影排行榜数据并写入csv文件](https://blog.csdn.net/qq_51447436/article/details/126024194)[target="_blank" data-report-click={"spm":"1018.2226.3001.9630","extra":{"utm_source":"vip_chatgpt_common_search_pc_result","utm_medium":"distribute.pc_search_result.none-task-cask-2~all~insert_cask~default-1-null.142^v93^chatsearchT3_2"}}] [.reference_item style="max-width: 50%"]
- *2* [Python 爬虫 | 电影数据的获取](https://blog.csdn.net/weixin_44623587/article/details/126070881)[target="_blank" data-report-click={"spm":"1018.2226.3001.9630","extra":{"utm_source":"vip_chatgpt_common_search_pc_result","utm_medium":"distribute.pc_search_result.none-task-cask-2~all~insert_cask~default-1-null.142^v93^chatsearchT3_2"}}] [.reference_item style="max-width: 50%"]
[ .reference_list ]
阅读全文
相关推荐
最新推荐
Python爬虫爬取电影票房数据及图表展示操作示例
1. **Python爬虫**:Python提供了一系列强大的库来帮助我们抓取网页数据,如`requests`用于发送HTTP请求,`BeautifulSoup`或`re`(正则表达式)用于解析HTML内容。在这个例子中,我们使用`requests`库获取网页内容。...
java+sql server项目之科帮网计算机配件报价系统源代码.zip
sql server+java项目之科帮网计算机配件报价系统源代码
【java毕业设计】智慧社区老人健康监测门户.zip
有java环境就可以运行起来 ,zip里包含源码+论文+PPT, 系统设计与功能:
文档详细描述了系统的后台管理功能,包括系统管理模块、新闻资讯管理模块、公告管理模块、社区影院管理模块、会员上传下载管理模块以及留言管理模块。
系统管理模块:允许管理员重新设置密码,记录登录日志,确保系统安全。
新闻资讯管理模块:实现新闻资讯的添加、删除、修改,确保主页新闻部分始终显示最新的文章。
公告管理模块:类似于新闻资讯管理,但专注于主页公告的后台管理。
社区影院管理模块:管理所有视频的添加、删除、修改,包括影片名、导演、主演、片长等信息。
会员上传下载管理模块:审核与删除会员上传的文件。
留言管理模块:回复与删除所有留言,确保系统内的留言得到及时处理。
环境说明:
开发语言:Java
框架:ssm,mybatis
JDK版本:JDK1.8
数据库:mysql 5.7及以上
数据库工具:Navicat11及以上
开发软件:eclipse/idea
Maven包:Maven3.3及以上
JavaScript实现的高效pomodoro时钟教程
资源摘要信息:"JavaScript中的pomodoroo时钟"
知识点1:什么是番茄工作法
番茄工作法是一种时间管理技术,它是由弗朗西斯科·西里洛于1980年代末发明的。该技术使用一个定时器来将工作分解为25分钟的块,这些时间块之间短暂休息。每个时间块被称为一个“番茄”,因此得名“番茄工作法”。该技术旨在帮助人们通过短暂的休息来提高集中力和生产力。
知识点2:JavaScript是什么
JavaScript是一种高级的、解释执行的编程语言,它是网页开发中最主要的技术之一。JavaScript主要用于网页中的前端脚本编写,可以实现用户与浏览器内容的交云互动,也可以用于服务器端编程(Node.js)。JavaScript是一种轻量级的编程语言,被设计为易于学习,但功能强大。
知识点3:使用JavaScript实现番茄钟的原理
在使用JavaScript实现番茄钟的过程中,我们需要用到JavaScript的计时器功能。JavaScript提供了两种计时器方法,分别是setTimeout和setInterval。setTimeout用于在指定的时间后执行一次代码块,而setInterval则用于每隔一定的时间重复执行代码块。在实现番茄钟时,我们可以使用setInterval来模拟每25分钟的“番茄时间”,使用setTimeout来控制每25分钟后的休息时间。
知识点4:如何在JavaScript中设置和重置时间
在JavaScript中,我们可以使用Date对象来获取和设置时间。Date对象允许我们获取当前的日期和时间,也可以让我们创建自己的日期和时间。我们可以通过new Date()创建一个新的日期对象,并使用Date对象提供的各种方法,如getHours(), getMinutes(), setHours(), setMinutes()等,来获取和设置时间。在实现番茄钟的过程中,我们可以通过获取当前时间,然后加上25分钟,来设置下一个番茄时间。同样,我们也可以通过获取当前时间,然后减去25分钟,来重置上一个番茄时间。
知识点5:实现pomodoro-clock的基本步骤
首先,我们需要创建一个定时器,用于模拟25分钟的工作时间。然后,我们需要在25分钟结束后提醒用户停止工作,并开始短暂的休息。接着,我们需要为用户的休息时间设置另一个定时器。在用户休息结束后,我们需要重置定时器,开始下一个工作周期。在这个过程中,我们需要为每个定时器设置相应的回调函数,以处理定时器触发时需要执行的操作。
知识点6:使用JavaScript实现pomodoro-clock的优势
使用JavaScript实现pomodoro-clock的优势在于JavaScript的轻量级和易学性。JavaScript作为前端开发的主要语言,几乎所有的现代浏览器都支持JavaScript。因此,我们可以很容易地在网页中实现pomodoro-clock,用户只需要打开网页即可使用。此外,JavaScript的灵活性也使得我们可以根据需要自定义pomodoro-clock的各种参数,如工作时间长度、休息时间长度等。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
【WebLogic客户端兼容性提升秘籍】:一站式解决方案与实战案例
# 摘要
WebLogic作为一款广泛使用的中间件产品,其客户端兼容性对于企业应用至关重要。本文从基本概念出发,系统地介绍了WebLogic的架构、组件以及兼容性问题的分类和影响。通过深入分析兼容性测试方法和诊断分析技术,探讨了如何有效地识别和解决客户端兼容性问题。进一步,本文提出了提升兼容性的策略,包括代码层面的设计、配置管理、补丁升级以及快速响应流程。最后,结合实战案例,本文详细说明了解决方案的实施过
使用jupyter读取文件“近5年考试人数.csv”,绘制近5年高考及考研人数发展趋势图,数据如下(单位:万人)。
在Jupyter Notebook中读取CSV文件并绘制图表,通常需要几个步骤:
1. 首先,你需要导入必要的库,如pandas用于数据处理,matplotlib或seaborn用于数据可视化。
```python
import pandas as pd
import matplotlib.pyplot as plt
```
2. 使用`pd.read_csv()`函数加载CSV文件:
```python
df = pd.read_csv('近5年考试人数.csv')
```
3. 确保数据已经按照年份排序,如果需要的话,可以添加这一行:
```python
df = df.sor
CMake 3.25.3版本发布:程序员必备构建工具
资源摘要信息:"Cmake-3.25.3.zip文件是一个包含了CMake软件版本3.25.3的压缩包。CMake是一个跨平台的自动化构建系统,用于管理软件的构建过程,尤其是对于C++语言开发的项目。CMake使用CMakeLists.txt文件来配置项目的构建过程,然后可以生成不同操作系统的标准构建文件,如Makefile(Unix系列系统)、Visual Studio项目文件等。CMake广泛应用于开源和商业项目中,它有助于简化编译过程,并支持生成多种开发环境下的构建配置。
CMake 3.25.3版本作为该系列软件包中的一个点,是CMake的一个稳定版本,它为开发者提供了一系列新特性和改进。随着版本的更新,3.25.3版本可能引入了新的命令、改进了用户界面、优化了构建效率或解决了之前版本中发现的问题。
CMake的主要特点包括:
1. 跨平台性:CMake支持多种操作系统和编译器,包括但不限于Windows、Linux、Mac OS、FreeBSD、Unix等。
2. 编译器独立性:CMake生成的构建文件与具体的编译器无关,允许开发者在不同的开发环境中使用同一套构建脚本。
3. 高度可扩展性:CMake能够使用CMake模块和脚本来扩展功能,社区提供了大量的模块以支持不同的构建需求。
4. CMakeLists.txt:这是CMake的配置脚本文件,用于指定项目源文件、库依赖、自定义指令等信息。
5. 集成开发环境(IDE)支持:CMake可以生成适用于多种IDE的项目文件,例如Visual Studio、Eclipse、Xcode等。
6. 命令行工具:CMake提供了命令行工具,允许用户通过命令行对构建过程进行控制。
7. 可配置构建选项:CMake支持构建选项的配置,使得用户可以根据需要启用或禁用特定功能。
8. 包管理器支持:CMake可以从包管理器中获取依赖,并且可以使用FetchContent或ExternalProject模块来获取外部项目。
9. 测试和覆盖工具:CMake支持添加和运行测试,并集成代码覆盖工具,帮助开发者对代码进行质量控制。
10. 文档和帮助系统:CMake提供了一个内置的帮助系统,可以为用户提供命令和变量的详细文档。
CMake的安装和使用通常分为几个步骤:
- 下载并解压对应平台的CMake软件包。
- 在系统中配置CMake的环境变量,确保在命令行中可以全局访问cmake命令。
- 根据项目需要编写CMakeLists.txt文件。
- 在含有CMakeLists.txt文件的目录下执行cmake命令生成构建文件。
- 使用生成的构建文件进行项目的构建和编译工作。
CMake的更新和迭代通常会带来更好的用户体验和更高效的构建过程。对于开发者而言,及时更新到最新稳定版本的CMake是保持开发效率和项目兼容性的重要步骤。而对于新用户,掌握CMake的使用则是学习现代软件构建技术的一个重要方面。"
"互动学习:行动中的多样性与论文攻读经历"
多样性她- 事实上SCI NCES你的时间表ECOLEDO C Tora SC和NCESPOUR l’Ingén学习互动,互动学习以行动为中心的强化学习学会互动,互动学习,以行动为中心的强化学习计算机科学博士论文于2021年9月28日在Villeneuve d'Asq公开支持马修·瑟林评审团主席法布里斯·勒菲弗尔阿维尼翁大学教授论文指导奥利维尔·皮耶昆谷歌研究教授:智囊团论文联合主任菲利普·普雷教授,大学。里尔/CRISTAL/因里亚报告员奥利维耶·西格德索邦大学报告员卢多维奇·德诺耶教授,Facebook /索邦大学审查员越南圣迈IMT Atlantic高级讲师邀请弗洛里安·斯特鲁布博士,Deepmind对于那些及时看到自己错误的人...3谢谢你首先,我要感谢我的两位博士生导师Olivier和Philippe。奥利维尔,"站在巨人的肩膀上"这句话对你来说完全有意义了。从科学上讲,你知道在这篇论文的(许多)错误中,你是我可以依
数字信号处理全攻略:掌握15个关键技巧,提升你的处理效率
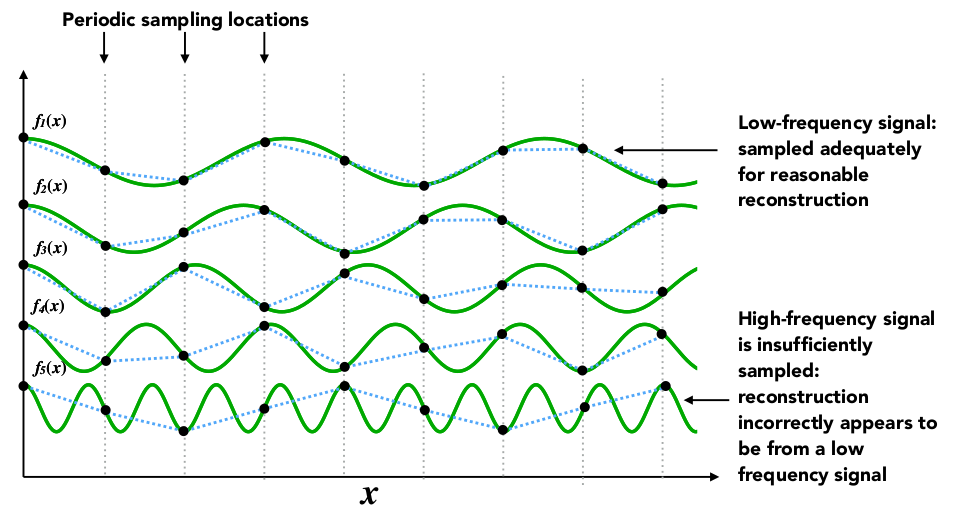
# 摘要
数字信号处理作为信息科技领域的重要分支,涵盖了从基础理论到高级应用的广泛内容。本文首先介绍了数字信号处理的基础知识,包括基本概念、时域与频域分析、以及核心算法和理论框架。接着,详细探讨了实现信号采样和量化、滤波器设计、以及信号增强和重建实践技巧。文章进一步深入到高级应用,包括信号压缩技术、多维信号处理,以及人工智能技术在信号处理中的集成。最后,本文评述了数字信号处理