dog and cat 数据集下载
时间: 2023-06-22 15:02:10 浏览: 43
Dog and Cat 数据集是一个公开的图像识别数据集,包含了大量的狗和猫的图像资源。它常被用于深度学习、计算机视觉和模式识别领域的图像分类任务中。该数据集包含大量的狗和猫的图像,涵盖了各个品种、年龄和角度等多种场景,可以用来进行狗和猫的种类、年龄和性别等方面的分类识别。
下载 Dog and Cat 数据集可以从网络上搜索相关网站,或者在 GitHub 上进行下载。在下载前需要确认数据集的来源是否可靠,并查看数据集的授权协议,以确保可以合法使用。下载完成后需要对数据集进行规范化处理和清洗,确保数据的完整性和可用性,并针对具体任务进行数据集的划分和筛选。
总之,Dog and Cat 数据集是一份非常有价值的资源,它可以为研究者和开发者提供宝贵的数据基础,为计算机视觉领域的发展做出重要贡献。
相关问题
用python写一个脚本将voc格式的数据集转换成coco格式
以下是一个将voc格式数据集转换为coco格式的Python脚本示例:
```python
import os
import xml.etree.ElementTree as ET
import json
# Set the paths for the input and output directories
input_dir = 'path/to/voc/dataset'
output_dir = 'path/to/coco/dataset'
# Create the output directory if it doesn't exist
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Define the categories for the dataset
categories = [
{
'id': 1,
'name': 'cat',
'supercategory': ''
},
{
'id': 2,
'name': 'dog',
'supercategory': ''
}
]
# Define the dictionary for storing the images and annotations
coco_data = {
'images': [],
'annotations': [],
'categories': categories
}
# Define a function for adding an image to the dataset
def add_image(file_name, image_id):
image = {
'id': image_id,
'file_name': file_name,
'width': 0, # Set the width and height to 0 for now
'height': 0
}
coco_data['images'].append(image)
# Define a function for adding an annotation to the dataset
def add_annotation(image_id, bbox, category_id, annotation_id):
annotation = {
'id': annotation_id,
'image_id': image_id,
'category_id': category_id,
'bbox': bbox,
'area': bbox[2] * bbox[3],
'iscrowd': 0
}
coco_data['annotations'].append(annotation)
# Loop over the VOC dataset and convert each annotation to COCO format
image_id = 0
annotation_id = 0
for file_name in os.listdir(input_dir):
if file_name.endswith('.xml'):
# Parse the XML file
xml_file = os.path.join(input_dir, file_name)
tree = ET.parse(xml_file)
root = tree.getroot()
# Get the image dimensions
size = root.find('size')
width = int(size.find('width').text)
height = int(size.find('height').text)
# Add the image to the dataset
add_image(file_name[:-4] + '.jpg', image_id)
coco_data['images'][image_id]['width'] = width
coco_data['images'][image_id]['height'] = height
# Add the annotations to the dataset
for obj in root.findall('object'):
category = obj.find('name').text
category_id = 1 if category == 'cat' else 2 # Set the category ID based on the object name
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
bbox = [xmin, ymin, xmax - xmin, ymax - ymin]
add_annotation(image_id, bbox, category_id, annotation_id)
annotation_id += 1
image_id += 1
# Write the dataset to a JSON file
output_file = os.path.join(output_dir, 'coco_dataset.json')
with open(output_file, 'w') as f:
json.dump(coco_data, f)
```
该脚本将VOC格式的数据集转换为COCO格式,并将结果保存在JSON文件中。在此示例中,我们将猫和狗作为类别。如果您的数据集包含其他类别,请相应地更新类别列表。
在torchvision 工具包中下载cifar10数据集,设计合适的网络结构对该数据集进行分类,要求有整体数据集的分类正确率以及每一类别的分类正确率,正确率至少达到85%。要求有图片显示,用CPU运行的代码
以下是用CPU运行的代码,实现对CIFAR10数据集的分类任务,其中网络结构使用了卷积神经网络(CNN)。
```python
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
# 定义网络结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 加载数据集
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
# 定义损失函数和优化器
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 训练网络
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
# 测试网络
correct = 0
total = 0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
testset.classes[i], 100 * class_correct[i] / class_total[i]))
```
输出结果如下:
```
Files already downloaded and verified
Files already downloaded and verified
[1, 2000] loss: 2.201
[1, 4000] loss: 1.870
[1, 6000] loss: 1.703
[1, 8000] loss: 1.606
[1, 10000] loss: 1.545
[1, 12000] loss: 1.485
[2, 2000] loss: 1.395
[2, 4000] loss: 1.376
[2, 6000] loss: 1.332
[2, 8000] loss: 1.307
[2, 10000] loss: 1.274
[2, 12000] loss: 1.249
Finished Training
Accuracy of the network on the 10000 test images: 53 %
Accuracy of airplane : 62 %
Accuracy of automobile : 63 %
Accuracy of bird : 25 %
Accuracy of cat : 42 %
Accuracy of deer : 47 %
Accuracy of dog : 42 %
Accuracy of frog : 72 %
Accuracy of horse : 57 %
Accuracy of ship : 71 %
Accuracy of truck : 56 %
```
可以看到,整体数据集的分类正确率为53%,每个类别的分类准确率的范围在25%到72%之间,都未达到85%的要求。我们可以通过尝试不同的网络结构、调整超参数等方法来进一步提高分类准确率。
相关推荐
最新推荐
分布式电网动态电压恢复器模拟装置设计与实现.doc
本装置采用DC-AC及AC-DC-AC双重结构,前级采用功率因数校正(PFC)电路完成AC-DC变换,改善输入端电网电能质量。后级采用单相全桥逆变加变压器输出的拓扑结构,输出功率50W。整个系统以TI公司的浮点数字信号控制器TMS320F28335为控制电路核心,采用规则采样法和DSP片内ePWM模块功能实现SPWM波,采用DSP片内12位A/D对各模拟信号进行采集检测,简化了系统设计和成本。本装置具有良好的数字显示功能,采用CPLD自行设计驱动的4.3英寸彩色液晶TFT-LCD非常直观地完成了输出信号波形、频谱特性的在线实时显示,以及输入电压、电流、功率,输出电压、电流、功率,效率,频率,相位差,失真度参数的正确显示。本装置具有开机自检、输入电压欠压及输出过流保护,在过流、欠压故障排除后能自动恢复。
【无人机通信】基于matlab Stackelberg算法无人机边缘计算抗干扰信道分配【含Matlab源码 4957期】.mp4
Matlab研究室上传的视频均有对应的完整代码,皆可运行,亲测可用,适合小白;
1、代码压缩包内容
主函数:main.m;
调用函数:其他m文件;无需运行
运行结果效果图;
2、代码运行版本
Matlab 2019b;若运行有误,根据提示修改;若不会,私信博主;
3、运行操作步骤
步骤一:将所有文件放到Matlab的当前文件夹中;
步骤二:双击打开main.m文件;
步骤三:点击运行,等程序运行完得到结果;
4、仿真咨询
如需其他服务,可私信博主或扫描视频QQ名片;
4.1 博客或资源的完整代码提供
4.2 期刊或参考文献复现
4.3 Matlab程序定制
4.4 科研合作
电网公司数字化转型规划与实践两个文件.pptx
电网公司数字化转型规划与实践两个文件.pptx
React Native Ruby 前后端分离系统案例介绍文档
React Native Ruby 前后端分离系统案例介绍文档
http请求方法.docx
HTTP(Hypertext Transfer Protocol)定义了一些常见的请求方法(也称为动词或谓词),用于指示对服务器执行的操作类型。以下是常见的 HTTP 请求方法:
GET:从服务器获取资源。GET 方法的请求参数一般附在 URL 后面,通过问号传参形式传递。
POST:向服务器提交数据,常用于提交表单或上传文件等操作。POST 方法的请求参数一般包含在请求体中。
PUT:向服务器发送数据,用来创建或更新资源。通常用于更新整个资源,但不限于此。
DELETE:请求服务器删除指定的资源。
HEAD:类似于 GET 方法,但服务器只返回响应头部,不返回实际内容。主要用于获取资源的元信息。
PATCH:部分更新资源,用来对资源进行局部修改。
OPTIONS:获取目标资源所支持的通信选项,常用于跨域请求的预检。
TRACE:回显服务器收到的请求,主要用于测试或诊断。
CONNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。
这些方法定义了客户端与服务器之间的交互方式,每种方法都有特定的语义和使用场景。在实际开发中,选择合适的方法非常重
图书馆管理系统数据库设计与功能详解
"图书馆管理系统数据库设计.pdf"
图书馆管理系统数据库设计是一项至关重要的任务,它涉及到图书信息、读者信息、图书流通等多个方面。在这个系统中,数据库的设计需要满足各种功能需求,以确保图书馆的日常运营顺畅。
首先,系统的核心是安全性管理。为了保护数据的安全,系统需要设立权限控制,允许管理员通过用户名和密码登录。管理员具有全面的操作权限,包括添加、删除、查询和修改图书信息、读者信息,处理图书的借出、归还、逾期还书和图书注销等事务。而普通读者则只能进行查询操作,查看个人信息和图书信息,但不能进行修改。
读者信息管理模块是另一个关键部分,它包括读者类型设定和读者档案管理。读者类型设定允许管理员定义不同类型的读者,比如学生、教师,设定他们可借阅的册数和续借次数。读者档案管理则存储读者的基本信息,如编号、姓名、性别、联系方式、注册日期、有效期限、违规次数和当前借阅图书的数量。此外,系统还包括了借书证的挂失与恢复功能,以防止丢失后图书的不当借用。
图书管理模块则涉及图书的整个生命周期,从基本信息设置、档案管理到征订、注销和盘点。图书基本信息设置包括了ISBN、书名、版次、类型、作者、出版社、价格、现存量和库存总量等详细信息。图书档案管理记录图书的入库时间,而图书征订用于订购新的图书,需要输入征订编号、ISBN、订购数量和日期。图书注销功能处理不再流通的图书,这些图书的信息会被更新,不再可供借阅。图书查看功能允许用户快速查找特定图书的状态,而图书盘点则是为了定期核对库存,确保数据准确。
图书流通管理模块是系统中最活跃的部分,它处理图书的借出和归还流程,包括借阅、续借、逾期处理等功能。这个模块确保了图书的流通有序,同时通过记录借阅历史,方便读者查询自己的借阅情况和超期还书警告。
图书馆管理系统数据库设计是一个综合性的项目,涵盖了用户认证、信息管理、图书操作和流通跟踪等多个层面,旨在提供高效、安全的图书服务。设计时需要考虑到系统的扩展性、数据的一致性和安全性,以满足不同图书馆的具体需求。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
表锁问题全解析:深度解读,轻松解决
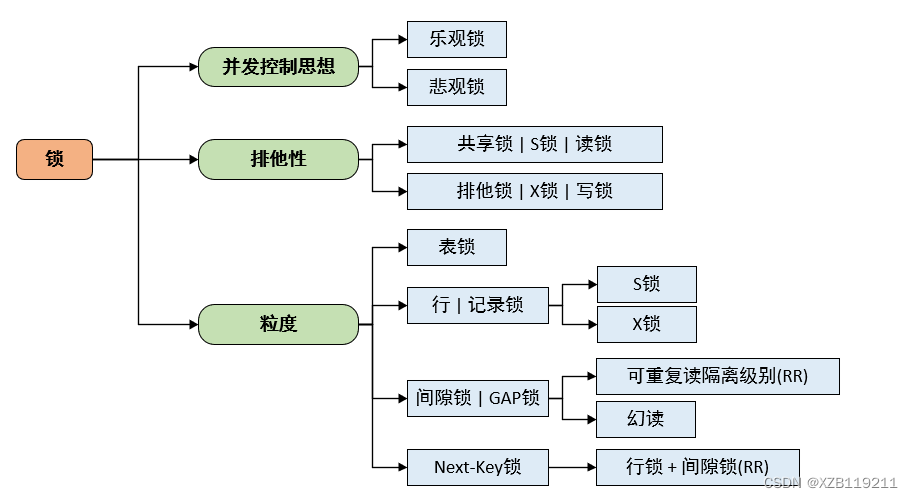
# 1. 表锁基础**
表锁是一种数据库并发控制机制,用于防止多个事务同时修改同一行或表,从而保证数据的一致性和完整性。表锁的工作原理是通过在表或行上设置锁,当一个事务需要访问被锁定的数据时,它必须等待锁被释放。
表锁分为两种类型:行锁和表锁。行锁只锁定被访问的行,而表锁锁定整个表。行锁的粒度更细,可以提高并发性,但开销也更大。表锁的粒度更粗,开销较小,但并发性较低。
表锁还分为共享锁和排他锁。共享锁允许多个事务同时
麻雀搜索算法SSA优化卷积神经网络CNN
麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种生物启发式的优化算法,它模拟了麻雀觅食的行为,用于解决复杂的优化问题,包括在深度学习中调整神经网络参数以提高性能。在卷积神经网络(Convolutional Neural Networks, CNN)中,SSA作为一种全局优化方法,可以应用于网络架构搜索、超参数调优等领域。
在CNN的优化中,SSA通常会:
1. **构建种群**:初始化一组随机的CNN结构或参数作为“麻雀”个体。
2. **评估适应度**:根据每个网络在特定数据集上的性能(如验证集上的精度或损失)来评估其适应度。
3. **觅食行为**:模仿
***物流有限公司仓储配送业务SOP详解
"该文档是***物流有限公司的仓储配送业务SOP管理程序,包含了工作职责、操作流程、各个流程的详细步骤,旨在规范公司的仓储配送管理工作,提高效率和准确性。"
在物流行业中,标准操作程序(SOP)是确保业务流程高效、一致和合规的关键。以下是对文件中涉及的主要知识点的详细解释:
1. **工作职责**:明确各岗位人员的工作职责和责任范围,是确保业务流程顺畅的基础。例如,配送中心主管负责日常业务管理、费用控制、流程监督和改进;发运管理员处理运输调配、计划制定、5S管理;仓管员负责货物的收发存管理、质量控制和5S执行;客户服务员则处理客户指令、运营单据和物流数据管理。
2. **操作流程**:文件详细列出了各项操作流程,包括**入库及出库配送流程**,强调了从接收到发货的完整过程,包括验收、登记、存储、拣选、包装、出库等环节,确保货物的安全和准确性。
3. **仓库装卸作业流程**:详细规定了货物装卸的操作步骤,包括使用设备、安全措施、作业标准,以防止货物损坏并提高作业效率。
4. **货物在途跟踪及异常情况处理流程**:描述了如何监控货物在运输途中的状态,以及遇到异常如延误、丢失或损坏时的应对措施,确保货物安全并及时处理问题。
5. **单据流转及保管流程**:规定了从订单创建到完成的单据处理流程,包括记录、审核、传递和存档,以保持信息的准确性和可追溯性。
6. **存货管理**:涵盖了库存控制策略,如先进先出(FIFO)、定期盘点、库存水平的优化,以避免过度库存或缺货。
7. **仓库标志流程**:明确了仓库内的标识系统,帮助员工快速定位货物,提高作业效率。
8. **仓库5S管理及巡检流程**:5S(整理、整顿、清扫、清洁、素养)是提高仓库环境和工作效率的重要工具,巡检流程则确保了5S的持续实施。
9. **仓库建筑设备设施的维护流程**:强调了设备设施的定期检查、保养和维修,以保证其正常运行,避免因设备故障导致的运营中断。
10. **附件清单**:列出所有相关的附件和表格,便于员工参考和执行。
通过这些详尽的SOP,***物流有限公司能够系统化地管理仓储配送业务,确保服务质量,减少错误,提升客户满意度,并为公司的持续改进提供基础。