572369写出哈夫曼树
时间: 2023-07-01 08:22:41 浏览: 85
很高兴回答你的问题!以下是一个示例哈夫曼树:
```
29
/ \
/ \
12 17
/ \ / \
6 6 8 9
/ \ / \
3 3 3 3
```
在上面的示例中,每个节点都是一个权重(或频率)和一个字符。哈夫曼树是一个二叉树,它的叶子节点代表字符,而每个非叶子节点代表权重。
哈夫曼树的构建过程可以是:
1. 统计每个字符在文本中出现的频率。
2. 将每个字符和它的频率作为一个节点插入到优先队列中。
3. 从队列中选择两个具有最小频率的节点,将它们合并成一个新的节点,并将合并后节点的频率设置为它们的和。
4. 将新节点插入到队列中。
5. 重复步骤3和4,直到队列中只剩下一个节点,这个节点就是哈夫曼树的根节点。
在上面的示例中,我们可以看到字符出现的频率和对应的节点。我们可以从下往上看,每次将两个最小的节点合并成一个新节点,最后得到了一个哈夫曼树。
相关问题
用C语言写出哈夫曼树的代码和注释
以下是用C语言实现哈夫曼树的代码和注释:
```c
#include <stdio.h>
#include <stdlib.h>
// 定义哈夫曼树节点结构体
typedef struct huffman_node {
int value; // 节点权值
struct huffman_node *left; // 左子节点指针
struct huffman_node *right; // 右子节点指针
} HuffmanNode;
// 定义优先队列(小根堆)结构体
typedef struct priority_queue {
HuffmanNode **nodes; // 节点数组指针
int size; // 当前队列大小
int capacity; // 队列容量
} PriorityQueue;
// 创建一个新的哈夫曼树节点
HuffmanNode *new_huffman_node(int value) {
HuffmanNode *node = (HuffmanNode *) malloc(sizeof(HuffmanNode));
node->value = value;
node->left = NULL;
node->right = NULL;
return node;
}
// 交换两个哈夫曼树节点的位置
void swap_nodes(HuffmanNode **a, HuffmanNode **b) {
HuffmanNode *tmp = *a;
*a = *b;
*b = tmp;
}
// 初始化优先队列
PriorityQueue *init_priority_queue(int capacity) {
PriorityQueue *queue = (PriorityQueue *) malloc(sizeof(PriorityQueue));
queue->nodes = (HuffmanNode **) malloc(sizeof(HuffmanNode *) * capacity);
queue->size = 0;
queue->capacity = capacity;
return queue;
}
// 向优先队列插入一个节点
void insert_node(PriorityQueue *queue, HuffmanNode *node) {
// 如果队列已满则返回
if (queue->size == queue->capacity) {
return;
}
// 将新节点插入队列末尾
queue->nodes[queue->size++] = node;
int index = queue->size - 1;
// 将新节点上浮到正确的位置
while (index > 0 && queue->nodes[index]->value < queue->nodes[(index - 1) / 2]->value) {
swap_nodes(&queue->nodes[index], &queue->nodes[(index - 1) / 2]);
index = (index - 1) / 2;
}
}
// 从优先队列中取出最小的节点
HuffmanNode *pop_min_node(PriorityQueue *queue) {
// 如果队列为空则返回 NULL
if (queue->size == 0) {
return NULL;
}
// 取出队列头部节点
HuffmanNode *min_node = queue->nodes[0];
// 将队列尾部节点移到头部
queue->nodes[0] = queue->nodes[--queue->size];
int index = 0;
// 将头部节点下沉到正确的位置
while (index * 2 + 1 < queue->size) {
int left_child_index = index * 2 + 1;
int right_child_index = index * 2 + 2;
int min_child_index = left_child_index;
if (right_child_index < queue->size && queue->nodes[right_child_index]->value < queue->nodes[left_child_index]->value) {
min_child_index = right_child_index;
}
if (queue->nodes[min_child_index]->value >= queue->nodes[index]->value) {
break;
}
swap_nodes(&queue->nodes[index], &queue->nodes[min_child_index]);
index = min_child_index;
}
return min_node;
}
// 构建哈夫曼树
HuffmanNode *build_huffman_tree(int *weights, int size) {
PriorityQueue *queue = init_priority_queue(size);
// 将所有树叶节点插入优先队列
for (int i = 0; i < size; i++) {
insert_node(queue, new_huffman_node(weights[i]));
}
// 不断取出两个最小的节点合并成一个新节点,直到队列中只有一个节点为止
while (queue->size > 1) {
HuffmanNode *left_child = pop_min_node(queue);
HuffmanNode *right_child = pop_min_node(queue);
HuffmanNode *new_node = new_huffman_node(left_child->value + right_child->value);
new_node->left = left_child;
new_node->right = right_child;
insert_node(queue, new_node);
}
HuffmanNode *root = pop_min_node(queue);
free(queue->nodes);
free(queue);
return root;
}
// 打印哈夫曼树的结构
void print_huffman_tree(HuffmanNode *root, int depth) {
if (root == NULL) {
return;
}
for (int i = 0; i < depth; i++) {
printf(" ");
}
if (root->left == NULL && root->right == NULL) {
printf("%d\n", root->value);
} else {
printf("+-\n");
print_huffman_tree(root->left, depth + 1);
print_huffman_tree(root->right, depth + 1);
}
}
int main() {
int weights[] = {3, 1, 4, 1, 5, 9, 2, 6, 5, 3};
int size = sizeof(weights) / sizeof(weights[0]);
HuffmanNode *root = build_huffman_tree(weights, size);
print_huffman_tree(root, 0);
return 0;
}
```
以上代码实现了哈夫曼树的构建和打印结构功能。可以通过修改 `weights` 数组中的元素来构建不同的哈夫曼树。
写出哈夫曼树和哈夫曼编码的实现只用stdio和iostream
下面是哈夫曼树和哈夫曼编码的实现示例,仅使用了stdio和iostream库:
```c++
#include <iostream>
#include <cstdio>
#include <queue>
#include <vector>
#include <cstring>
using namespace std;
const int MAXN = 10005;
int n;
int w[MAXN];
int parent[MAXN], lc[MAXN], rc[MAXN];
char code[MAXN][MAXN];
struct Node {
int id, w;
bool operator<(const Node& o) const {
return w > o.w;
}
};
void huffman() {
priority_queue<Node> q;
for (int i = 1; i <= n; ++i) {
q.push({i, w[i]});
}
int id = n + 1;
while (q.size() > 1) {
Node x = q.top();
q.pop();
Node y = q.top();
q.pop();
parent[x.id] = parent[y.id] = id;
lc[id] = x.id;
rc[id] = y.id;
w[id] = x.w + y.w;
q.push({id, w[id]});
++id;
}
}
void dfs(int u, char* cur) {
if (lc[u] == 0 && rc[u] == 0) {
strcpy(code[u], cur);
return;
}
int len = strlen(cur);
cur[len] = '0';
dfs(lc[u], cur);
cur[len] = '1';
dfs(rc[u], cur);
}
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; ++i) {
scanf("%d", &w[i]);
}
huffman();
dfs(n * 2 - 1, code[n * 2 - 1]);
for (int i = 1; i <= n; ++i) {
printf("char %c : %s\n", 'A' + i - 1, code[i]);
}
return 0;
}
```
上述代码实现了哈夫曼树和哈夫曼编码的构建,其中用到了优先队列和深度优先遍历。在输入时,需要先输入字符集的大小n,然后依次输入每个字符的权值。输出时,对于每个字符,输出它的字符编码。
阅读全文
相关推荐
最新推荐
鸿蒙开发前端学习笔记day02(自用)
鸿蒙开发前端学习笔记day02(自用)
A query builder for PostgreSQL.zip
A query builder for PostgreSQL
【JCR一区级】Matlab实现侏儒猫鼬优化算法DMO-DBN实现轴承故障分类算法研究.rar
1.版本:matlab2014/2019a/2024a
2.附赠案例数据可直接运行matlab程序。
3.代码特点:参数化编程、参数可方便更改、代码编程思路清晰、注释明细。
4.适用对象:计算机,电子信息工程、数学等专业的大学生课程设计、期末大作业和毕业设计。
替换数据可以直接使用,注释清楚,适合新手
AA4MM开源软件:多建模与模拟耦合工具介绍
资源摘要信息:"AA4MM-开源"
知识点:
1. AA4MM概述: AA4MM是一种开源工具,专门用于多建模和模拟耦合。它利用代理(Agent)和人工制品(Artifact)的概念来进行复杂的模拟任务。
2. 开源软件介绍: 开源软件是指源代码可以被公众访问的软件,任何人都可以使用、修改和分发这些软件。开源软件的优势在于其透明性、可定制性和社区支持。
3. 多建模和模拟耦合: 多建模是指使用多种模型来描述和预测一个复杂系统的行为,而模拟耦合则是将这些模型链接起来,以便它们可以协同工作,提供更准确的模拟结果。
4. 代理和人工制品: 在多建模和模拟中,代理通常指具有自主行为能力的个体,可以是实体或者软件中模拟的抽象对象。人工制品则是代理活动的产物,比如软件、数据文件等。
5. AA4MM的应用: AA4MM可能被应用于多个领域,如生态学、社会学、经济学、城市规划等,以理解和预测系统的复杂行为。
6. AA4MM软件包文件: AA4MM软件包可能包含多个文件,以支持其功能。例如,AA4MMDemo.jar可能是一个演示AA4MM功能的可执行JAR文件,而netlogo_models可能包含了NetLogo模型文件,NetLogo是一种用于模拟自然和社会现象的多主体编程语言和平台。
7. 技术栈和依赖: 由于AA4MM可能使用Java作为编程语言(因为存在JAR文件),了解Java技术栈对于理解和使用AA4MM至关重要。此外,如果AA4MM依赖于特定的库或框架,那么对这些技术的了解也是必须的。
8. 社区和资源: 开源软件通常拥有活跃的社区,社区成员互相协助、分享知识和资源。对于AA4MM而言,这意味着用户可以找到相关的文档、教程、示例项目以及如何参与该项目贡献的指南。
9. 许可证和合规性: 使用开源软件时,了解其许可证条款至关重要,以确保合法合规地使用该软件。AA4MM作为开源软件,用户需要确认其遵循的是哪种开源许可证(如GPL、MIT、Apache等)。
10. 安装和配置: 使用AA4MM前,用户可能需要进行安装和配置。这可能涉及到设置环境变量、安装依赖软件包以及进行初始的软件设置。
11. 排错和优化: 在使用AA4MM时,用户可能会遇到一些问题,此时需要能够进行有效的排错。此外,为了提高模拟的效率和准确性,可能需要对软件进行性能优化。
12. 培训和学习: 对于不熟悉多建模和模拟耦合的用户来说,可能需要通过在线课程、研讨会或阅读相关文献来提升自己的技能。
综上所述,AA4MM作为一款开源多建模和模拟耦合工具,具备强大的功能和灵活性,能够应用于多个学科领域中进行复杂系统的模拟与分析。对于技术开发者和科研人员来说,掌握相关的知识点和技术细节,将有助于更高效地利用AA4MM进行研究和开发工作。同时,由于其开源特性,用户还可以参与到项目的开发中,为改进和推广该工具贡献力量。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
HDFS写入超时问题:深入分析与专家提供的10大解决策略
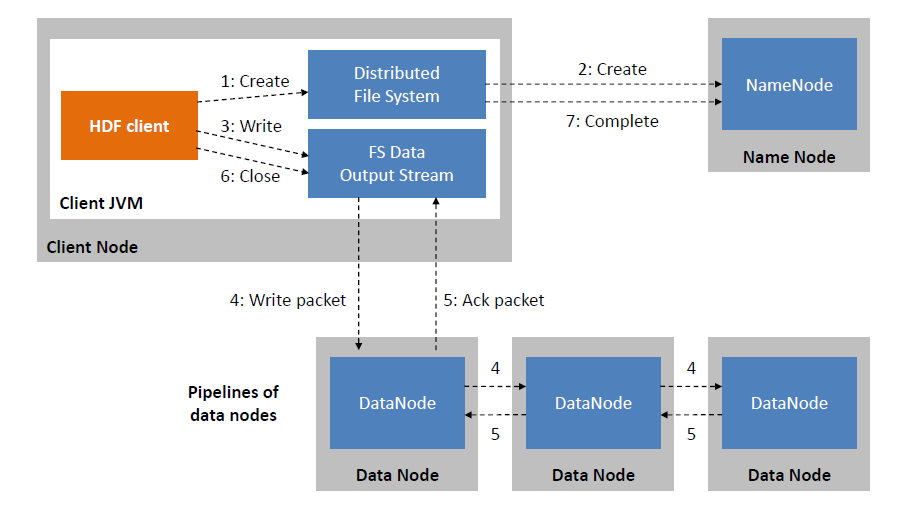
# 1. HDFS写入超时问题概述
## 1.1 HDFS写入超时问题简介
Hadoop分布式文件系统(HDFS)作为大数据生态中存储的核心组件,为大规模数据处理提供了高效支持。然而,在实际应用过程中,用户常遇到写入超时的问题,这会导致数据完整性受损、计算任务失败,甚至业务中断。本文将探讨HDFS写入超时问题,以帮助用户快速定位并解决相关问题。
## 1.2 超时问题的影响
在数据密集型应用中,
如何利用STLINK调试器和WCHISPTool工具将CH32F103C8T6微控制器进行USB下载操作?
为了有效地将CH32F103C8T6微控制器与STLINK调试器配合使用进行程序下载,你需要按照以下步骤操作并注意相应的细节:(步骤、代码、mermaid流程图、扩展内容,此处略)
参考资源链接:[CH32F103C8T6芯片下载教程:STLINK与USB方式](https://wenku.csdn.net/doc/15zenzvboq)
首先,在Keil uVision环境中配置项目以使用STLINK调试器。确保你已经安装了正确的设备支持包`Keil.WCH32F1xx_DFP.1.0.0.pack`,这样软件才能识别CH32F103C8T6微控制器。在项目设置中选择目标设备,配
Swagger实时生成器的探索与应用
资源摘要信息:"Swagger Generator 实时API文档生成工具"
Swagger是一种用于描述、生产和消费RESTful Web服务的接口描述语言,它提供了一套强大的工具集来生成交互式API文档,用于API的设计、测试和文档生成。"swagger-generator-realti"(即Swagger Generator 实时API文档生成工具)是一个专注于通过实时信息来自动化生成API文档的工具。
知识点详细说明:
1. Swagger的定义与作用:
- Swagger是一种规范和完整的框架,用于描述API的结构,使得开发者能够清晰地理解和使用API。
- 它通过一套简洁的接口描述语言(OpenAPI Specification,原名Swagger Specification),来定义API接口的标准语言和结构。
-Swagger工具集包括Swagger Editor(在线编辑器)、Swagger UI(文档展示界面)、Swagger Codegen(代码生成器)等,可以用来设计API、生成API文档、以及客户端和服务端的代码。
2. 实时API文档的概念:
- 实时API文档意味着文档能够即时反映API的最新状态和变更。
- 这种文档能够帮助开发者在API开发和维护过程中,及时了解API的结构、参数、调用示例等信息。
- 实时API文档对于团队协作和API的使用者来说非常有价值,能够减少因文档更新滞后导致的误解和错误。
3. Swagger Generator的功能:
-Swagger Generator通过解析API的规范文件(通常是JSON或YAML格式),自动地生成结构化、可交互的API文档。
-它支持多种编程语言和框架,可以通过简单的配置,生成对应的客户端和服务端代码,极大地提高了开发效率。
-该工具可以集成到持续集成和持续部署(CI/CD)的流程中,确保文档和API的同步更新。
4. Swagger Generator的实时性:
-Swagger Generator实时性强调的是对于API变动的快速响应和文档的即时更新。
-通过集成到API的开发和部署流程中,Swagger Generator可以在API发布后迅速更新文档,减少文档与实际API之间的差异。
-实时API文档不仅减少了开发者查看和理解API所需的维护成本,还能够提升API的可用性和可靠性。
5. 标签说明:
- "swagger_generato"标签指向与Swagger工具相关的生成器,这可以是Swagger Codegen或任何类似的工具,用于生成代码、文档等资源。
6. 文件名称列表解析:
- "swagger_generator_realtime"文件名称暗示了这是一个专注于实时API文档生成的Swagger相关工具或插件。
- 名称中的"realtime"可能表明工具具有实时监控API变更并自动更新文档的能力。
Swagger Generator的实时API文档生成能力,对于API的高效管理和维护提供了重要的支持,极大地提升了API文档的准确性和时效性。开发团队通过使用这样的工具可以更加快速和准确地进行API的设计、开发、测试和文档维护工作,从而提高整个API生态系统的质量。
"互动学习:行动中的多样性与论文攻读经历"
多样性她- 事实上SCI NCES你的时间表ECOLEDO C Tora SC和NCESPOUR l’Ingén学习互动,互动学习以行动为中心的强化学习学会互动,互动学习,以行动为中心的强化学习计算机科学博士论文于2021年9月28日在Villeneuve d'Asq公开支持马修·瑟林评审团主席法布里斯·勒菲弗尔阿维尼翁大学教授论文指导奥利维尔·皮耶昆谷歌研究教授:智囊团论文联合主任菲利普·普雷教授,大学。里尔/CRISTAL/因里亚报告员奥利维耶·西格德索邦大学报告员卢多维奇·德诺耶教授,Facebook /索邦大学审查员越南圣迈IMT Atlantic高级讲师邀请弗洛里安·斯特鲁布博士,Deepmind对于那些及时看到自己错误的人...3谢谢你首先,我要感谢我的两位博士生导师Olivier和Philippe。奥利维尔,"站在巨人的肩膀上"这句话对你来说完全有意义了。从科学上讲,你知道在这篇论文的(许多)错误中,你是我可以依
HDFS写入失败分析:数据节点故障快速定位与解决攻略

# 1. HDFS写入失败问题概述
在大数据生态系统中,Hadoop分布式文件系统(HDFS)是一个关键组件,用于存储和处理海量数据集。然而,在数据写入过程中,可能会遇到失败的情况。这些失败可能是由网络问题、资源限制、硬件故障或配置错误等多种因素引起的。了解HDFS的写入流程对于诊断和解决问题至关重要。本章将概述HDFS写入失败的常见问题,为进一步深入分析提供基础。
# 2. HDFS数据节点故障的理论基础
## 2