hive调优explain
时间: 2024-07-03 16:00:28 浏览: 12
Hive是一个基于Hadoop的数据仓库工具,用于对结构化的数据进行查询和分析。Explain命令在Hive中是一个非常重要的工具,用于理解Hive SQL查询的执行计划,这对于优化查询性能至关重要。当你运行一个查询并添加"EXPLAIN"关键字时,Hive会返回一个详细的执行计划,显示了查询如何被分解为更低级别的操作。
以下是使用explain进行Hive查询优化的一些关键点:
1. **执行计划**:查看查询的执行计划可以帮助你识别可能的瓶颈,比如全表扫描、连接操作的顺序等。
2. **Join类型**:理解是合并(INNER JOIN)、左外联接(LEFT JOIN)还是其他类型的连接,以及连接是否使用了索引,对效率有很大影响。
3. **Sort and Limit**:检查是否有不必要的排序和Limit操作,这可能会导致大量数据的额外处理。
4. **分区和分桶**:如果你的表是分区或分桶的,确保查询只涉及所需的分区或范围,避免全表扫描。
5. **索引使用**:检查是否存在合适的索引,特别是在JOIN操作中,适当的索引可以大大提高查询速度。
6. **优化器模式**:设置合适的优化器模式(如`set hive.optimize.sortmergejoin=true`),有时候手动指定可能比默认模式更有效。
相关问题
hive调优的思路,还有就是hive的参数
对于Hive的调优思路,可以从以下几个方面入手:
1. 数据存储和分区设计:合理的数据存储和分区设计可以提高查询性能。根据业务需求,将数据按照合适的列进行分区,这样可以减少数据扫描量。
2. 数据压缩:使用合适的压缩格式可以减小数据存储空间,并提高查询性能。例如,使用Snappy、LZO等压缩算法来减少磁盘IO和网络传输。
3. 数据倾斜处理:当某些列的值过于集中,导致某些Task处理的数据量远大于其他Task时,会导致任务执行时间不均衡。通过对倾斜键进行处理,如使用随机前缀或者进行拆分处理,可以解决数据倾斜问题。
4. 合理设置Hive参数:根据实际情况调整Hive的参数配置,以提高查询性能。常见的参数包括:hive.exec.parallel、hive.tez.container.size、hive.vectorized.execution.enabled等。
关于Hive的参数配置,下面是一些常用的参数:
1. hive.exec.parallel:设置并行执行任务的线程数,默认为1。可以根据集群资源情况适当调整,以提高任务执行效率。
2. hive.tez.container.size:设置每个Tez任务的容器大小,默认为1024(MB)。可以根据具体的任务需求和集群资源情况进行调整,以充分利用集群资源。
3. hive.vectorized.execution.enabled:启用向量化执行,可提高查询性能。默认为false,可以通过设置为true来开启向量化执行。
4. hive.optimize.sort.dynamic.partition:动态分区排序优化,默认为true。对于动态分区表,可以开启该参数以提高插入性能和查询性能。
5. hive.stats.autogather:自动收集统计信息,默认为true。开启该参数可以帮助优化查询计划,提高查询性能。
以上是一些常见的Hive调优思路和参数配置,具体的调优策略还需要根据实际情况进行调整和优化。
hive sql 调优
Hive SQL 调优的核心思路是优化查询计划,以减少查询时间和资源消耗。以下是一些常见的 Hive SQL 调优技巧:
1. 使用分区表:将数据按照某个字段分成多个分区,可以减少查询范围,提高查询效率。
2. 使用索引:通过建立索引可以加速查询速度,提高查询效率。
3. 使用适当的数据类型:选择合适的数据类型,可以减少内存占用,提高查询速度。
4. 使用桶:桶是将相似的数据放在一起,可以减少查询范围,提高查询效率。
5. 避免全表扫描:全表扫描是效率低下的操作,可以通过优化查询条件、使用分区、使用索引等方式减少全表扫描。
6. 优化 JOIN 操作:尽可能使用 map-side join,避免使用 shuffle join。
7. 限制查询结果集大小:在查询中使用 LIMIT、TOP 等限制结果集大小的语句,可以减少查询时间和资源消耗。
8. 合理配置 Hive 参数:例如,调整 mapred.map.tasks 和 mapred.reduce.tasks 的数量,可以提高查询效率。
以上是一些常见的 Hive SQL 调优技巧,实际调优过程中,还需要根据具体的场景和数据性质进行进一步优化。
相关推荐
最新推荐
Hive函数大全.pdf
大佬总结的hive的各种常用函数语法格式及其用法,Hive内部提供了很多函数给开发者使用,包括数学函数,类型转换函数,条件函数,字符函数,聚合函数,表生成函数等等
如何在python中写hive脚本
在Python中编写Hive脚本主要是为了方便地与Hadoop HIVE数据仓库进行交互,这样可以在数据分析和机器学习流程中无缝地集成大数据处理步骤。以下将详细介绍如何在Python环境中执行Hive查询和管理Hive脚本。 1. **直接...
hive常见的优化方案ppt
在大数据处理领域,Hive作为一个基于Hadoop的数据仓库工具,被广泛用于数据分析和查询。然而,随着数据量的增加,Hive性能问题逐渐显现,如数据倾斜、负载不均衡等,严重影响了处理效率。以下是一些针对Hive性能优化...
HIVE-SQL开发规范.docx
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询...
详解hbase与hive数据同步
详解HBase与Hive数据同步 HBase与Hive数据同步是大数据处理中常见的一种数据集成方式。HBase是一种NoSQL数据库,适合存储大量半结构化和非结构化数据,而Hive是基于Hadoop的数据仓库工具,用于数据分析和处理。两者...
图书馆管理系统数据库设计与功能详解
"图书馆管理系统数据库设计.pdf"
图书馆管理系统数据库设计是一项至关重要的任务,它涉及到图书信息、读者信息、图书流通等多个方面。在这个系统中,数据库的设计需要满足各种功能需求,以确保图书馆的日常运营顺畅。
首先,系统的核心是安全性管理。为了保护数据的安全,系统需要设立权限控制,允许管理员通过用户名和密码登录。管理员具有全面的操作权限,包括添加、删除、查询和修改图书信息、读者信息,处理图书的借出、归还、逾期还书和图书注销等事务。而普通读者则只能进行查询操作,查看个人信息和图书信息,但不能进行修改。
读者信息管理模块是另一个关键部分,它包括读者类型设定和读者档案管理。读者类型设定允许管理员定义不同类型的读者,比如学生、教师,设定他们可借阅的册数和续借次数。读者档案管理则存储读者的基本信息,如编号、姓名、性别、联系方式、注册日期、有效期限、违规次数和当前借阅图书的数量。此外,系统还包括了借书证的挂失与恢复功能,以防止丢失后图书的不当借用。
图书管理模块则涉及图书的整个生命周期,从基本信息设置、档案管理到征订、注销和盘点。图书基本信息设置包括了ISBN、书名、版次、类型、作者、出版社、价格、现存量和库存总量等详细信息。图书档案管理记录图书的入库时间,而图书征订用于订购新的图书,需要输入征订编号、ISBN、订购数量和日期。图书注销功能处理不再流通的图书,这些图书的信息会被更新,不再可供借阅。图书查看功能允许用户快速查找特定图书的状态,而图书盘点则是为了定期核对库存,确保数据准确。
图书流通管理模块是系统中最活跃的部分,它处理图书的借出和归还流程,包括借阅、续借、逾期处理等功能。这个模块确保了图书的流通有序,同时通过记录借阅历史,方便读者查询自己的借阅情况和超期还书警告。
图书馆管理系统数据库设计是一个综合性的项目,涵盖了用户认证、信息管理、图书操作和流通跟踪等多个层面,旨在提供高效、安全的图书服务。设计时需要考虑到系统的扩展性、数据的一致性和安全性,以满足不同图书馆的具体需求。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
表锁问题全解析:深度解读,轻松解决
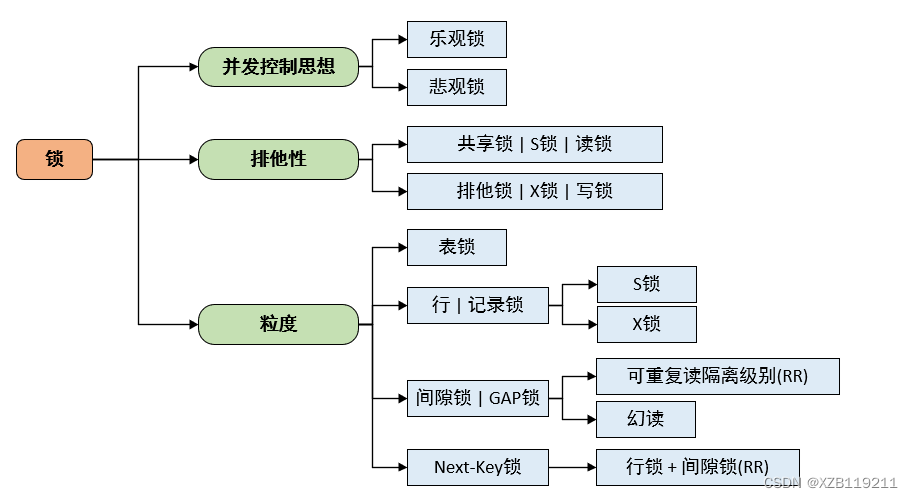
# 1. 表锁基础**
表锁是一种数据库并发控制机制,用于防止多个事务同时修改同一行或表,从而保证数据的一致性和完整性。表锁的工作原理是通过在表或行上设置锁,当一个事务需要访问被锁定的数据时,它必须等待锁被释放。
表锁分为两种类型:行锁和表锁。行锁只锁定被访问的行,而表锁锁定整个表。行锁的粒度更细,可以提高并发性,但开销也更大。表锁的粒度更粗,开销较小,但并发性较低。
表锁还分为共享锁和排他锁。共享锁允许多个事务同时
麻雀搜索算法SSA优化卷积神经网络CNN
麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种生物启发式的优化算法,它模拟了麻雀觅食的行为,用于解决复杂的优化问题,包括在深度学习中调整神经网络参数以提高性能。在卷积神经网络(Convolutional Neural Networks, CNN)中,SSA作为一种全局优化方法,可以应用于网络架构搜索、超参数调优等领域。
在CNN的优化中,SSA通常会:
1. **构建种群**:初始化一组随机的CNN结构或参数作为“麻雀”个体。
2. **评估适应度**:根据每个网络在特定数据集上的性能(如验证集上的精度或损失)来评估其适应度。
3. **觅食行为**:模仿
***物流有限公司仓储配送业务SOP详解
"该文档是***物流有限公司的仓储配送业务SOP管理程序,包含了工作职责、操作流程、各个流程的详细步骤,旨在规范公司的仓储配送管理工作,提高效率和准确性。"
在物流行业中,标准操作程序(SOP)是确保业务流程高效、一致和合规的关键。以下是对文件中涉及的主要知识点的详细解释:
1. **工作职责**:明确各岗位人员的工作职责和责任范围,是确保业务流程顺畅的基础。例如,配送中心主管负责日常业务管理、费用控制、流程监督和改进;发运管理员处理运输调配、计划制定、5S管理;仓管员负责货物的收发存管理、质量控制和5S执行;客户服务员则处理客户指令、运营单据和物流数据管理。
2. **操作流程**:文件详细列出了各项操作流程,包括**入库及出库配送流程**,强调了从接收到发货的完整过程,包括验收、登记、存储、拣选、包装、出库等环节,确保货物的安全和准确性。
3. **仓库装卸作业流程**:详细规定了货物装卸的操作步骤,包括使用设备、安全措施、作业标准,以防止货物损坏并提高作业效率。
4. **货物在途跟踪及异常情况处理流程**:描述了如何监控货物在运输途中的状态,以及遇到异常如延误、丢失或损坏时的应对措施,确保货物安全并及时处理问题。
5. **单据流转及保管流程**:规定了从订单创建到完成的单据处理流程,包括记录、审核、传递和存档,以保持信息的准确性和可追溯性。
6. **存货管理**:涵盖了库存控制策略,如先进先出(FIFO)、定期盘点、库存水平的优化,以避免过度库存或缺货。
7. **仓库标志流程**:明确了仓库内的标识系统,帮助员工快速定位货物,提高作业效率。
8. **仓库5S管理及巡检流程**:5S(整理、整顿、清扫、清洁、素养)是提高仓库环境和工作效率的重要工具,巡检流程则确保了5S的持续实施。
9. **仓库建筑设备设施的维护流程**:强调了设备设施的定期检查、保养和维修,以保证其正常运行,避免因设备故障导致的运营中断。
10. **附件清单**:列出所有相关的附件和表格,便于员工参考和执行。
通过这些详尽的SOP,***物流有限公司能够系统化地管理仓储配送业务,确保服务质量,减少错误,提升客户满意度,并为公司的持续改进提供基础。