pandas数据预处理头哥
时间: 2024-06-05 07:05:41 浏览: 31
Pandas是Python编程语言的一种开源库,提供了丰富的数据结构和数据分析工具,特别适合于处理结构化数据。Pandas主要包含两种数据结构:Series和DataFrame。Series是一种一维数组类型,可以存储整数、浮点数和字符串等类型的数据,同时也具有各种方法来操作这些数据;DataFrame则是一个二维表格型的数据结构,可以看作是由多个Series组成的。
在数据预处理中,Pandas可以用于数据清洗、转换、合并、分组和聚合等操作。具体来说,Pandas的数据预处理过程通常包括以下几个步骤:
1. 数据读取:从文件、数据库或网络等数据源中读取数据,并将其转换为Pandas的DataFrame格式。
2. 缺失值处理:对于缺失值,可以进行删除、插值、填充等处理。
3. 数据变换:可以对数据进行过滤、排序、去重等操作。
4. 数据合并:可以将多个DataFrame按照一定规则进行合并。
5. 数据分组和聚合:可以根据某些列对数据进行分组,然后对每个分组进行聚合操作(如求平均值、最大值等)。
相关问题
pandas数据预处理头歌
pandas是一个强大的数据处理和分析工具,它提供了丰富的函数和方法来进行数据预处理。下面是一些常用的pandas数据预处理操作:
1. 数据读取:pandas可以读取各种格式的数据,如CSV、Excel、SQL数据库等。使用`read_csv()`函数可以读取CSV文件,使用`read_excel()`函数可以读取Excel文件。
2. 数据清洗:在数据预处理过程中,常常需要对数据进行清洗,包括处理缺失值、异常值、重复值等。使用`dropna()`函数可以删除包含缺失值的行或列,使用`fillna()`函数可以填充缺失值,使用`drop_duplicates()`函数可以删除重复值。
3. 数据转换:有时候需要对数据进行转换,如数据类型转换、字符串处理、日期处理等。使用`astype()`函数可以进行数据类型转换,使用`str`属性可以进行字符串处理,使用`to_datetime()`函数可以将字符串转换为日期类型。
4. 特征选择:在进行机器学习任务时,需要选择合适的特征进行建模。使用`loc`或`iloc`属性可以选择指定的行或列,使用`drop()`函数可以删除指定的行或列。
5. 特征缩放:有时候需要对特征进行缩放,以便它们具有相似的尺度。使用`StandardScaler`类可以进行标准化缩放,使用`MinMaxScaler`类可以进行最小-最大缩放。
6. 特征编码:对于分类变量,需要将其转换为数值型变量。使用`LabelEncoder`类可以进行标签编码,使用`OneHotEncoder`类可以进行独热编码。
7. 数据合并:当有多个数据集需要合并时,可以使用`concat()`函数或`merge()`函数进行数据合并。
头歌pandas数据预处理
Pandas是一个强大的数据处理库,可以用于对数据进行清洗、转换和分析。以下是一些常用的Pandas数据预处理方法:
1. 查看数据前几行: df.head()
2. 查看数据类型: df.dtypes
3. 查看数据的行数和列数: df.shape
4. 获取数据的基本信息,包括缺失值: df.info()
5. 描述性统计,包括平均值、标准差、最大值、最小值和分位数: df.describe()
6. 查看某一列的唯一值: df['column_name'].unique()
7. 查找空值: df.isnull().any(axis=0)
8. 定位含有空值的行列: df.loc[df.isnull().any(axis=1)]
9. 统计空值的数量: df.isnull().sum(axis=0)
10. 删除含有空值的整行: df.dropna()
11. 将空值替换为指定值: df.fillna(0)
以上是一些常用的Pandas数据预处理方法,根据你的需求可以选择适合的方法进行数据清洗和处理。
相关推荐
最新推荐
Pandas 数据处理,数据清洗详解
今天小编就为大家分享一篇Pandas 数据处理,数据清洗详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
python数据预处理(1)———缺失值处理
提高数据质量即数据预处理成为首要步骤,也会影响后期模型的表现。在此对利用Python进行预处理数据做一个总结归纳。 首先是缺失值处理。 #读取数据 import pandas as pd filepath= 'F:/...'#本地文件目录 df= pd....
Pandas 按索引合并数据集的方法
今天小编就为大家分享一篇Pandas 按索引合并数据集的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
“人力资源+大数据+薪酬报告+涨薪调薪”
人力资源+大数据+薪酬报告+涨薪调薪,在学习、工作生活中,越来越多的事务都会使用到报告,通常情况下,报告的内容含量大、篇幅较长。那么什么样的薪酬报告才是有效的呢?以下是小编精心整理的调薪申请报告,欢迎大家分享。相信老板看到这样的报告,一定会考虑涨薪的哦。
springboot+vue小区物业管理系统(源码+文档)
系统包括业主登录、管理员登录2部分,登录者身份不同,其管理权限也不一样。业主只能查询,而管理员则可以增删改查各个部分。业主部分主要包括报修信息管理,缴欠费信息查询,房屋信息查询以及业主信息查询这4个模块;管理员部分主要包括用户权限管理,报修信息管理,缴欠费信息管理,房屋信息管理以及业主信息管理 5个模块。
工业AI视觉检测解决方案.pptx
工业AI视觉检测解决方案.pptx是一个关于人工智能在工业领域的具体应用,特别是针对视觉检测的深入探讨。该报告首先回顾了人工智能的发展历程,从起步阶段的人工智能任务失败,到专家系统的兴起到深度学习和大数据的推动,展示了人工智能从理论研究到实际应用的逐步成熟过程。
1. 市场背景:
- 人工智能经历了从计算智能(基于规则和符号推理)到感知智能(通过传感器收集数据)再到认知智能(理解复杂情境)的发展。《中国制造2025》政策强调了智能制造的重要性,指出新一代信息技术与制造技术的融合是关键,而机器视觉因其精度和效率的优势,在智能制造中扮演着核心角色。
- 随着中国老龄化问题加剧和劳动力成本上升,以及制造业转型升级的需求,机器视觉在汽车、食品饮料、医药等行业的渗透率有望提升。
2. 行业分布与应用:
- 国内市场中,电子行业是机器视觉的主要应用领域,而汽车、食品饮料等其他行业的渗透率仍有增长空间。海外市场则以汽车和电子行业为主。
- 然而,实际的工业制造环境中,由于产品种类繁多、生产线场景各异、生产周期不一,以及标准化和个性化需求的矛盾,工业AI视觉检测的落地面临挑战。缺乏统一的标准和模型定义,使得定制化的解决方案成为必要。
3. 工业化前提条件:
- 要实现工业AI视觉的广泛应用,必须克服标准缺失、场景多样性、设备技术不统一等问题。理想情况下,应有明确的需求定义、稳定的场景设置、统一的检测标准和安装方式,但现实中这些条件往往难以满足,需要通过技术创新来适应不断变化的需求。
4. 行业案例分析:
- 如金属制造业、汽车制造业、PCB制造业和消费电子等行业,每个行业的检测需求和设备技术选择都有所不同,因此,解决方案需要具备跨行业的灵活性,同时兼顾个性化需求。
总结来说,工业AI视觉检测解决方案.pptx着重于阐述了人工智能如何在工业制造中找到应用场景,面临的挑战,以及如何通过标准化和技术创新来推进其在实际生产中的落地。理解这个解决方案,企业可以更好地规划AI投入,优化生产流程,提升产品质量和效率。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL运维最佳实践:经验总结与建议
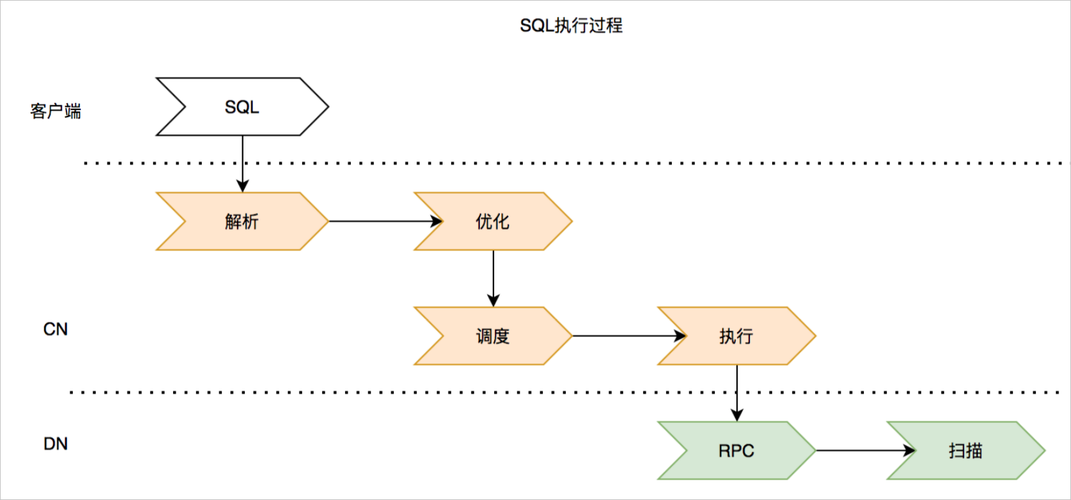
# 1. MySQL运维基础**
MySQL运维是一项复杂而重要的任务,需要深入了解数据库技术和最佳实践。本章将介绍MySQL运维的基础知识,包括:
- **MySQL架构和组件:**了解MySQL的架构和主要组件,包括服务器、客户端和存储引擎。
- **MySQL安装和配置:**涵盖MySQL的安装过
stata面板数据画图
Stata是一个统计分析软件,可以用来进行数据分析、数据可视化等工作。在Stata中,面板数据是一种特殊类型的数据,它包含了多个时间段和多个个体的数据。面板数据画图可以用来展示数据的趋势和变化,同时也可以用来比较不同个体之间的差异。
在Stata中,面板数据画图有很多种方法。以下是其中一些常见的方法
智慧医院信息化建设规划及愿景解决方案.pptx
"智慧医院信息化建设规划及愿景解决方案.pptx"
在当今信息化时代,智慧医院的建设已经成为提升医疗服务质量和效率的重要途径。本方案旨在探讨智慧医院信息化建设的背景、规划与愿景,以满足"健康中国2030"的战略目标。其中,"健康中国2030"规划纲要强调了人民健康的重要性,提出了一系列举措,如普及健康生活、优化健康服务、完善健康保障等,旨在打造以人民健康为中心的卫生与健康工作体系。
在建设背景方面,智慧医院的发展受到诸如分级诊疗制度、家庭医生签约服务、慢性病防治和远程医疗服务等政策的驱动。分级诊疗政策旨在优化医疗资源配置,提高基层医疗服务能力,通过家庭医生签约服务,确保每个家庭都能获得及时有效的医疗服务。同时,慢性病防治体系的建立和远程医疗服务的推广,有助于减少疾病发生,实现疾病的早诊早治。
在规划与愿景部分,智慧医院的信息化建设包括构建完善的电子健康档案系统、健康卡服务、远程医疗平台以及优化的分级诊疗流程。电子健康档案将记录每位居民的动态健康状况,便于医生进行个性化诊疗;健康卡则集成了各类医疗服务功能,方便患者就医;远程医疗技术可以跨越地域限制,使优质医疗资源下沉到基层;分级诊疗制度通过优化医疗结构,使得患者能在合适的层级医疗机构得到恰当的治疗。
在建设内容与预算方面,可能涉及硬件设施升级(如医疗设备智能化)、软件系统开发(如电子病历系统、预约挂号平台)、网络基础设施建设(如高速互联网接入)、数据安全与隐私保护措施、人员培训与技术支持等多个方面。预算应考虑项目周期、技术复杂性、维护成本等因素,以确保项目的可持续性和效益最大化。
此外,"互联网+医疗健康"的政策支持鼓励创新,智慧医院信息化建设还需要结合移动互联网、大数据、人工智能等先进技术,提升医疗服务的便捷性和精准度。例如,利用AI辅助诊断、物联网技术监控患者健康状态、区块链技术保障医疗数据的安全共享等。
智慧医院信息化建设是一项系统工程,需要政府、医疗机构、技术供应商和社会各方共同参与,以实现医疗服务质量的提升、医疗资源的优化配置,以及全民健康水平的提高。在2023年的背景下,这一进程将进一步加速,为我国的医疗健康事业带来深远影响。