怎么才能通过代码调用chargpt,请列举详细案例
时间: 2024-02-01 08:13:29 浏览: 21
首先,需要安装 PyTorch 和 Transformers 库。可以通过以下命令来安装:
```
pip install torch
pip install transformers
```
然后,需要下载并加载预训练的模型。可以使用 Transformers 库中的 `AutoModelForCausalLM` 类来加载预训练模型。例如,加载 `gpt2` 模型的代码如下:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "gpt2"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
接下来,我们可以使用 `model.generate()` 方法来生成文本。例如,以下代码使用 `gpt2` 模型生成一段文本:
```python
input_text = "Hello, how are you?"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids, max_length=50, do_sample=True)
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(output_text)
```
这里,我们首先使用 `tokenizer.encode()` 方法将输入文本编码为输入张量,并将其传递给 `model.generate()` 方法。`max_length` 参数指定了输出的最大长度,`do_sample` 参数表示是否使用随机采样的方式生成输出。最后,使用 `tokenizer.decode()` 方法将输出张量解码为文本。
以上就是一个简单的调用例子。当然,具体使用时还需要根据实际情况进行调整。
相关推荐
最新推荐
使用C++调用Python代码的方法详解
主要介绍了使用C++调用Python代码并给大家介绍了.py和.pyc的区别,本文给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下
Flutter调用Android和iOS原生代码的方法示例
本文主要给大家介绍了关于Flutter调用Android和iOS原生代码的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 分3个大步骤: 1.在flutter中调用原生方法 2.在Android中实现被调用的方法...
DSP编程技巧之--从C/C++代码调用汇编代码中的函数与变量
在C/C++与汇编语言混合编程的情况下,一般我们都会选择C/C++来实现所期待的大部分功能,对于少数和硬件关联度...C/C++与汇编的交互都是从C/C++代码调用汇编代码中的函数与变量,所以在此我们就来看一下这种调用的规则。
使用c++调用windows打印api进行打印的示例代码
主要介绍了使用c++调用windows打印api进行打印的示例代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
Python如何通过subprocess调用adb命令详解
python可以说是写一些小脚本的利器语法简单,做为最著名的就“胶水语言...下面这篇文章主要给大家介绍了关于Python如何通过subprocess调用adb命令的相关资料,需要的朋友可以参考借鉴,下面随着小编来一起学习学习吧。
zigbee-cluster-library-specification
最新的zigbee-cluster-library-specification说明文档。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
MySQL数据库性能提升秘籍:揭秘性能下降幕后真凶及解决策略
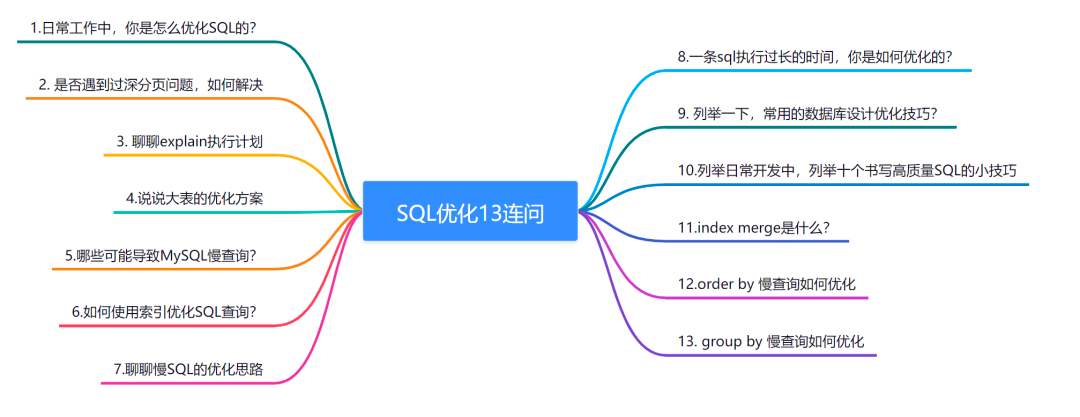
# 1. MySQL数据库性能优化概述**
MySQL数据库性能优化是一项至关重要的任务,可以显著提高应用程序的响应时间和整体用户体验。优化涉及识别和解决影响数据库性能的因素,包括硬件资源瓶颈、软件配置不当和数据库设计缺陷。通过采取适当的优化策略,可以显著提升数据库性能,满足业务需求并提高用户满意度。
# 2. MySQL数据库性能下降的幕后真凶
### 2.1 硬件资源瓶颈
#### 2.1.1 CPU利用率过高
**症状:
如何在unity创建按钮
在 Unity 中创建按钮的步骤如下:
1. 在 Unity 中创建一个 UI Canvas,选择 GameObject -> UI -> Canvas。
2. 在 Canvas 中创建一个按钮,选择 GameObject -> UI -> Button。
3. 在场景视图中调整按钮的位置和大小。
4. 在 Inspector 中设置按钮的文本、颜色、字体等属性。
5. 添加按钮的响应事件,选择按钮,在 Inspector 的 On Click () 中添加相应的方法。
这样就可以创建一个按钮了,你可以在游戏中使用它来触发相应的操作。
JSBSim Reference Manual
JSBSim参考手册,其中包含JSBSim简介,JSBSim配置文件xml的编写语法,编程手册以及一些应用实例等。其中有部分内容还没有写完,估计有生之年很难看到完整版了,但是内容还是很有参考价值的。