InfluxDB与Grafana的集成与优化
发布时间: 2024-02-22 19:48:44 阅读量: 46 订阅数: 43 

docker-influxdb-grafana:一个运行InfluxDB和Grafana的Docker容器准备持久存储数据
# 1. 介绍InfluxDB与Grafana
## 1.1 InfluxDB的概述与特点
InfluxDB 是一个开源的时序数据库,专门用于处理时间序列数据。它具有以下特点:
- 高性能:能够快速存储和查询大量时间序列数据。
- 高可扩展性:支持集群部署和水平扩展。
- 数据模型简单:通过以时间为索引的设计,使得数据写入和读取效率高。
```python
# 示例代码: 连接InfluxDB数据库并写入数据
from influxdb import InfluxDBClient
# 连接InfluxDB数据库
client = InfluxDBClient(host='localhost', port=8086)
# 创建数据库
client.create_database('mydb')
# 写入数据
json_body = [
{
"measurement": "cpu_usage",
"tags": {
"host": "server1",
"region": "us-west"
},
"fields": {
"value": 0.64
}
}
]
client.write_points(json_body, database='mydb')
```
**代码总结:** 上述代码通过Python连接到InfluxDB数据库,并写入了一个名为`cpu_usage`的时间序列数据。
**结果说明:** 数据成功写入InfluxDB数据库中的 `mydb` 数据库中。
## 1.2 Grafana的概述与特点
Grafana 是一个流行的监控与数据可视化工具,具有以下特点:
- 多数据源支持:可连接多种数据源,包括InfluxDB、Prometheus、MySQL等。
- 灵活的Dashboard设计:通过简单的拖拽操作可以设计出各种个性化的数据展示界面。
- 大量插件支持:拥有丰富的插件生态系统,可以扩展功能。
```java
// 示例代码:在Grafana中创建一个简单的Dashboard
import java.util.List;
public class GrafanaDashboard {
public static void main(String[] args) {
Dashboard dashboard = new Dashboard();
// 添加一个Panel显示CPU利用率
List<Panel> panels = dashboard.getPanels();
Panel cpuPanel = new Panel();
cpuPanel.setTitle("CPU Usage");
cpuPanel.setType("graph");
panels.add(cpuPanel);
// 输出Dashboard JSON配置
String dashboardJson = dashboard.toJson();
System.out.println(dashboardJson);
}
}
```
**代码总结:** 以上Java代码演示了如何通过代码创建一个简单的Grafana Dashboard,并输出其JSON配置。
**结果说明:** 代码将输出一个包含CPU利用率图表的Dashboard配置JSON串。
通过本章节的介绍,读者可以了解到InfluxDB和Grafana各自的特点及基本用法。接下来我们将深入讨论它们的安装与配置。
# 2. InfluxDB的安装与配置
InfluxDB是一个开源的时间序列数据库,专为高性能查询和存储时序数据而设计。它具有高性能、水平扩展、易于安装和使用等特点。
### 2.1 安装InfluxDB数据库
在本节中,我们将介绍如何安装InfluxDB数据库。下面是在Linux系统上使用apt安装InfluxDB的步骤:
```bash
# 添加InfluxData存储库密钥
wget -qO- https://repos.influxdata.com/influxdb.key | sudo apt-key add -
# 添加InfluxData存储库
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
# 更新软件包索引并安装InfluxDB
sudo apt update
sudo apt install influxdb
```
### 2.2 配置InfluxDB的基本参数
安装完成后,我们需要配置InfluxDB的基本参数。以下是一个示例InfluxDB配置文件`influxdb.c

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了Grafana监控平台的各个方面,从简介与安装配置指南开始,涵盖了数据源与数据可视化、仪表盘创建与管理、告警与通知配置、图表类型与数据展示效果等多个主题。读者将学习如何使用Prometheus实现实时监控、优化InfluxDB与Grafana集成、进行时序数据的分析与预测,甚至探讨插件开发、仪表盘优化与集群监控等高级主题。此外,还介绍了容器化环境下的监控、自动化报表生成与导出等实用技能。无论您是初学者还是有经验的用户,都能从本专栏中获取关于Grafana监控平台的全面指南,帮助您更好地利用这一强大工具进行各种监控和分析任务。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Visual Studio 2019 C51单片机开发全攻略:一步到位的配置秘籍
# 摘要
本文旨在为技术开发者提供一个全面的指南,涵盖了从环境搭建到项目开发的整个流程。首先介绍了Visual Studio 2019和C51单片机的基本概念以及开发环境的配置方法,包括安装步骤、界面布局以及Keil C51插件的安装和配置。接着,深入探讨了C51单片机编程的理论基础和实践技巧,包括语言基础知识、硬件交互方式以及
延迟环节自动控制优化策略:10种方法减少时间滞后

# 摘要
本文探讨了延迟环节自动控制的优化策略,旨在提高控制系统的响应速度和准确性。通过分析延迟环节的定义、分类、数学模型和识别技术,提出了一系列减少时间滞后的控制方法,包括时间序列预测、自适应控制和预测控制技术。进一步,本文通过工业过程控制实例和仿真分析,评估了优化策略的实际效果,并探讨了在实施自动化控制过程中面临的挑战及解决方案。文章最后展望了
华为IPD流程全面解读:掌握370个活动关键与实战技巧

# 摘要
本文全面概述了华为IPD(集成产品开发)流程,对流程中的关键活动进行了详细探讨,包括产品需求管理、项目计划与控制、以及技术开发与创新管理。文中通过分析产品开发实例,阐述了IPD流程在实际应用中的优势和潜在问题,并提出跨部门协作、沟通机制和流程改进的策略。进阶技巧
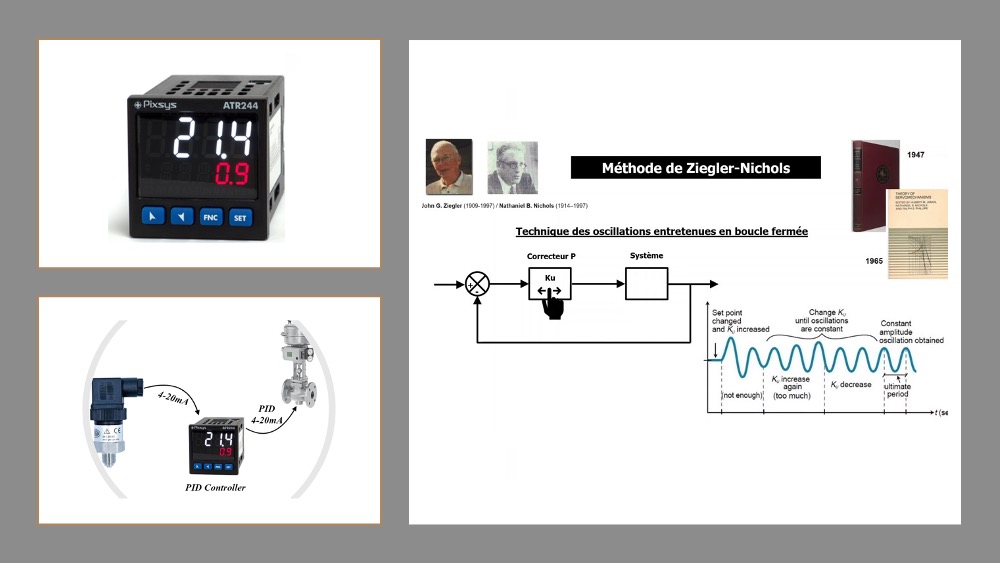
案例研究:51单片机PID算法在温度控制中的应用:专家级调试与优化技巧
# 摘要
本论文详细探讨了PID控制算法在基于51单片机的温度控制系统中的应用。首先介绍了PID控制算法的基础知识和理论,然后结合51单片机的硬件特性及温度传感器的接口技术,阐述了如何在51单片机上实现PID控制算法。接着,通过专家级调试技巧对系统进行优化调整,分析了常见的调试问题及其解决方法,并提出了一些高级
【Flutter生命周期全解析】:混合开发性能提升秘籍
# 摘要
Flutter作为一种新兴的跨平台开发框架,其生命周期的管理对于应用的性能和稳定性至关重要。本文系统地探讨了Flutter生命周期的概念框架,并深入分析了应用的生命周期、组件的生命周期以及混合开发环境下的生命周期管理。特别关注了性能管理、状态管理和优化技巧,包括内存使用、资源管理、状态保持策略及动画更新等。通过对比不同的生命周期管理方法和分析案例研究,本文揭示了Flutter生命周期优化的实用技巧,并对社区中的最新动态和未来发展趋势进行了展望。本文旨在为开发者提供深入理解并有效管理Flutter生命周期的全面指南,以构建高效、流畅的移动应用。
# 关键字
Flutter生命周期;性
【VS2012界面设计精粹】:揭秘用户友好登录界面的构建秘诀
# 摘要
本文探讨了用户友好登录界面的重要性及其设计与实现。第一章强调了界面友好性在用户体验中的作用,第二章详细介绍了VS2012环境下界面设计的基础原则、项目结构和控件使用。第三章聚焦于视觉和交互设计,包括视觉元素的应用和交互逻辑的构建,同时关注性能优化与跨平台兼容性。第四章讲述登录界面功能实现的技术细节和测试策略,确保后端服务集成和前端实现的高效性与安全性。最后,第五章通过案例研究分析了设计流程、用户反馈和界面迭代,并展望了
【梅卡曼德软件使用攻略】:掌握这5个技巧,提升工作效率!
# 摘要
梅卡曼德软件作为一种功能强大的工具,广泛应用于多个行业,提供了从基础操作到高级应用的一系列技巧。本文旨在介绍梅卡曼德软件的基本操作技巧,如界面导航、个性化设置、数据管理和自动化工作流设计。此外,本文还探讨了高级数据处理、报告与图表生成、以及集成第三方应用等高级应用技巧。针对软件使用中可能出现的问题,本文提供了问题诊断与解决的方法,包括常见问题排查、效能优化策略和客户支持资源。最后,通过案例
面向对象设计原则:理论与实践的完美融合
# 摘要
本文全面探讨了面向对象设计中的五大原则:单一职责原则、开闭原则、里氏替换原则、接口隔离原则以及依赖倒置原则和组合/聚合复用原则。通过详细的概念解析、重要性阐述以及实际应用实例,本文旨在指导开发者理解和实践这些设计原则,以构建更加灵活、可维护和可扩展的软件系统。文章不仅阐述了每个原则的理论基础,还着重于如何在代码重构和设计模式中应用这些原则,以及它们如何影响系统的扩
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )