Grafana监控平台简介与安装配置指南
发布时间: 2024-02-22 19:38:40 阅读量: 47 订阅数: 43 
# 1. Grafana监控平台简介
## 1.1 什么是Grafana监控平台
Grafana是一个流行的开源数据可视化和监控平台,广泛应用于各种领域的数据分析和监控任务中。通过Grafana,用户可以将不同数据源的数据进行集成,以直观、交互式的方式展现在仪表盘上,帮助用户更好地理解数据、分析数据,并进行实时监控。
## 1.2 Grafana的特点与优势
- **数据可视化**: Grafana提供了丰富多样的图表和工具,支持用户根据需求自定义展示方式,形成直观的数据展示。
- **易于扩展**: Grafana支持各种数据源,同时具有丰富的插件和扩展机制,可以灵活扩展功能。
- **跨平台性**: Grafana可以运行在各种操作系统上,包括Linux、Windows等。
- **开源免费**: Grafana基于Apache License 2.0开源协议发布,用户可以免费使用,并且可以根据自身需求定制开发。
## 1.3 Grafana在监控领域的应用场景
- **系统监控**: 通过监控主机的CPU、内存、磁盘等资源利用率,及时发现异常,保障系统稳定性。
- **应用性能监控**: 实时监控应用程序的性能指标,如请求响应时间、接口调用次数等,及时优化和改进。
- **日志监控**: 结合日志系统,对日志数据进行分析和展示,帮助排查问题和优化系统。
通过第一章的介绍,读者可以初步了解Grafana监控平台的基本概念和优势,为后续章节的学习打下基础。
# 2. Grafana安装准备
### 2.1 系统要求和环境准备
在安装Grafana之前,需要确保系统满足以下要求:
- 操作系统:推荐使用Linux系统,如Ubuntu、CentOS等
- 内存:建议至少4GB RAM
- 存储空间:至少20GB可用空间
- 网络:确保能够访问Grafana官方仓库
### 2.2 下载Grafana
可以通过以下步骤下载Grafana:
1. 打开终端或命令提示符
2. 执行以下命令下载Grafana安装包:
```bash
wget https://dl.grafana.com/oss/release/grafana-7.5.11-linux-amd64.tar.gz
```
或
```bash
curl -O https://dl.grafana.com/oss/release/grafana-7.5.11-linux-amd64.tar.gz
```
### 2.3 安装Grafana
安装Grafana的步骤如下:
1. 解压下载的安装包:
```bash
tar -zxvf grafana-7.5.11-linux-amd64.tar.gz
```
2. 进入解压后的目录:
```bash
cd grafana-7.5.11
```
3. 启动Grafana服务器:
```bash
./bin/grafana-server
```
4. 在浏览器中打开地址:http://localhost:3000,使用默认用户名admin和密码admin登录Grafana。
以上是Grafana的安装准备过程,确保按照上述步骤逐一执行,即可顺利安装并启动Grafana监控平台。
希望这些信息能帮到您。
# 3. Grafana基本配置
Grafana作为一个功能强大的监控平台,其基本配置是使用的关键步骤之一。在这一章节中,我们将介绍如何进行Grafana的基本配置,包括初始化设置、用户认证和权限配置、数据源配置,以及邮件和警报配置。
#### 3.1 Grafana初始化设置
首先,我们需要进行Grafana的初始化设置,包括设置管理员账号和密码,配置服务器端口等。以下是一个Python脚本示例,用于通过Grafana的API进行初始化设置:
```python
import requests
url = 'http://localhost:3000/api/admin/settings'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer YOUR_API_KEY'
}
data = {
'name': 'admin',
'password': 'admin_password',
'role': 'Admin'
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
```
**代码总结:**
- 通过Grafana的API进行管理员账号和密码的初始化设置;
- 需要替换`YOUR_API_KEY`为实际的API密钥;
- 管理员账号为`admin`,密码为`admin_password`。
**结果说明:**
成功执行该脚本后,将设置成功管理员账号和密码,确保安全性和权限控制。
#### 3.2 用户认证和权限配置
在Grafana中,用户认证和权限配置是非常重要的一部分。以下是一个Java代码示例,用于通过Grafana API设置用户权限:
```java
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.HttpClientBuilder;
public class GrafanaAuthSetup {
public static void main(String[] args) {
HttpClient httpClient = HttpClientBuilder.create().build();
HttpPost request = new HttpPost("http://localhost:3000/api/admin/users");
request.addHeader("Content-Type", "application/json");
request.addHeader("Authorization", "Bearer YOUR_API_KEY");
// 添加用户权限配置代码
HttpResponse response = httpClient.execute(request);
System.out.println("Response Code : " + response.getStatusLine().getStatusCode());
}
}
```
**代码总结:**
- 使用Java代码通过Grafana API设置用户权限;
- 需要替换`YOUR_API_KEY`为实际的API密钥;
- 可根据实际情况添加具体的用户权限配置代码。
**结果说明:**
成功执行该Java程序后,将设置用户权限,确保用户具有适当的权限访问监控数据。
#### 3.3 数据源配置
数据源配置是Grafana中非常关键的一步,它用于连接到监控数据源,比如InfluxDB、Prometheus等。以下是一个Go代码示例,用于通过Grafana API配置数据源:
```go
package main
import (
"bytes"
"encoding/json"
"net/http"
)
func main() {
url := "http://localhost:3000/api/datasources"
apiKey := "YOUR_API_KEY"
data := map[string]string{
"name": "InfluxDB",
"type": "influxdb",
"url": "http://localhost:8086",
"access": "proxy",
"basicAuth": true,
"user": "admin",
"password": "influx_password",
}
payload, _ := json.Marshal(data)
req, _ := http.NewRequest("POST", url, bytes.NewBuffer(payload))
req.Header.Set("Content-Type", "application/json")
req.Header.Set("Authorization", "Bearer "+apiKey)
client := &http.Client{}
resp, _ := client.Do(req)
defer resp.Body.Close()
fmt.Println("Data source configuration response status:", resp.Status)
}
```
**代码总结:**
- 使用Go语言通过Grafana API配置数据源连接;
- 需要替换`YOUR_API_KEY`为实际的API密钥;
- 配置了InfluxDB数据源的相关信息。
**结果说明:**
成功执行该Go程序后,将配置InfluxDB数据源,确保Grafana能够连接到相应的监控数据源。
# 4. Grafana面板与仪表盘
在Grafana中,面板和仪表盘是展示监控数据和指标的核心元素。通过创建和配置面板和仪表盘,用户可以实现对监控数据的可视化展示和定制化设置。
#### 4.1 仪表盘的创建与配置
要创建仪表盘,可以按照以下步骤操作:
1. 登录Grafana,进入"仪表盘"页面。
2. 点击"新建仪表盘"按钮,选择"添加面板"。
3. 在"数据源"选项中选择相应的数据源。
4. 点击新建面板后,可以选择数据来源、图表类型、指标字段等配置信息。
5. 点击"保存"按钮保存新建的仪表盘。
#### 4.2 数据可视化和定制化
Grafana提供丰富的图表类型和样式设置,用户可以根据监控需求进行数据可视化和定制化操作,例如:
```javascript
// 示例:配置图表为折线图,并设置标题和坐标轴
{
"title": "CPU利用率监控",
"datasource": "Prometheus",
"targets": [
{
"query": "cpu_usage{job='node-exporter'}",
"legendFormat": "{{instance}}",
"refId": "A"
}
],
"panelType": "graph",
"lines": true,
"fill": 1,
"linewidth": 2,
"bars": false,
"stack": false,
"percentage": false,
"span": 6,
"nullPointMode": "null"
}
```
#### 4.3 数据查询与过滤
在仪表盘配置中,可以通过数据查询语句和过滤条件获取所需的监控数据,例如:
```python
# 示例:使用Python语言编写数据查询脚本
import requests
url = 'http://localhost:3000/api/datasources/proxy/1/api/v1/query?query=up'
response = requests.get(url)
data = response.json()
# 处理监控数据
if data['status'] == 'success':
result = data['data']['result']
for item in result:
print(item['metric'], item['value'])
```
通过以上几点,可以帮助用户更好地创建和配置Grafana的面板与仪表盘,并实现对监控数据的可视化展示和定制化操作。
# 5. Grafana插件与扩展
Grafana作为一个开放式监控平台,提供了丰富的插件和扩展功能,可以满足不同用户的需求。在本章节中,我们将重点介绍Grafana插件的安装、管理以及常用插件的介绍与应用,同时探讨如何自定义开发Grafana插件。
### 5.1 插件的安装与管理
在Grafana中,插件提供了各种功能的扩展和定制化。下面是安装和管理Grafana插件的基本步骤:
1. 从Grafana插件市场或官方网站上找到需要安装的插件,并获取插件的URL或ID。
2. 通过Grafana的CLI或Web界面进入插件管理页面。
3. 在插件管理页面中,输入插件的URL或ID,然后点击安装按钮。
4. 安装完成后,在Grafana的仪表盘设置中即可找到新安装的插件,并进行配置和使用。
### 5.2 常用插件介绍与应用
Grafana社区开发了许多优秀的插件,提供了各种数据源连接、图表样式、报警功能等扩展功能。以下是一些常用插件的介绍与应用场景:
- **Grafana Pie Chart插件**:用于展示数据的饼图,适用于展示数据占比情况。
```javascript
// 示例代码
pieChart({
data: [
{ label: 'A', value: 30 },
{ label: 'B', value: 50 },
{ label: 'C', value: 20 }
]
});
```
- **Grafana Worldmap插件**:展示全球地图上的数据分布情况,适用于监控各地区指标的变化情况。
```python
# 示例代码
worldMap({
data: [
{ country: 'USA', value: 100 },
{ country: 'China', value: 80 },
{ country: 'India', value: 60 }
]
});
```
### 5.3 如何自定义开发Grafana插件
如果需要定制化的功能无法通过已有插件实现,可以考虑自定义开发Grafana插件。以下是自定义开发Grafana插件的基本步骤:
1. 确定插件的功能和需求。
2. 使用Grafana提供的插件模板或SDK进行插件开发。
3. 编写插件的前端和后端代码,实现所需功能。
4. 测试插件并进行部署,让Grafana加载并运行自定义插件。
通过自定义开发插件,可以实现更加个性化和专业化的监控功能,满足特定场景下的监控需求。
希望以上内容能够帮助您更好地了解Grafana插件与扩展功能。
# 6. 优化与故障排查
在使用Grafana监控平台的过程中,为了确保其性能稳定和可靠性,我们需要进行一些优化和故障排查操作。本章将详细介绍如何进行Grafana的性能优化以及常见问题的解决方法。
#### 6.1 Grafana性能优化
为了提升Grafana监控平台的性能,我们可以采取以下几项优化措施:
1. **保持Grafana版本更新**:及时升级到最新版本,以获取更好的性能表现和新功能支持。
2. **合理配置数据存储**:使用高性能的数据库存储,如InfluxDB或Graphite,优化数据查询和展示效率。
3. **定期清理无用数据**:定期清理历史数据和过期的监控信息,以减少数据库负担和提高查询速度。
4. **合理使用缓存**:配置合适的缓存机制,如设置数据缓存时间和缓存大小,以提升数据读取速度。
代码示例(性能优化设置):
```python
# 示例代码
def performance_optimization():
# Grafana性能优化设置
update_to_latest_version()
configure_data_storage()
clean_up_unused_data()
optimize_cache_settings()
# 性能优化总结
# 通过保持更新、合理配置存储、清理无用数据和优化缓存等措施,可以有效提升Grafana监控平台的性能表现。
```
#### 6.2 常见问题与解决方法
在使用Grafana过程中,可能会遇到一些常见问题,这里列举几种常见问题及其解决方法:
1. **数据显示异常**:可能是数据源配置错误或数据格式转换问题,需要检查数据源设置和数据格式是否正确。
2. **图表加载缓慢**:可能是数据量过大或查询复杂度高,可以通过优化查询语句或增加数据索引来提高加载速度。
3. **邮件报警无法发送**:可能是邮件配置有误或网络问题导致,需要检查邮件服务器设置和网络连接是否正常。
代码示例(常见问题解决方法):
```java
// 示例代码
public void trobuleshoot_common_problems(){
// 解决常见问题:数据异常,图表加载缓慢,邮件报警无法发送
check_data_source_configuration();
optimize_query_performance();
troubleshoot_email_alerts();
}
// 常见问题解决总结
// 定期检查数据源配置,优化查询性能,及时排查邮件报警问题,可提升Grafana监控平台的稳定性和可靠性。
```
#### 6.3 Grafana监控平台的日常维护与备份
为了确保Grafana监控平台的正常运行,我们还需要进行日常维护和备份工作。以下是一些建议的日常维护和备份操作:
1. **定期备份数据**:定期对Grafana配置文件和数据进行备份,以防止意外数据丢失。
2. **监控系统运行状况**:通过Grafana自身的监控功能或第三方工具监控系统性能,及时发现并解决问题。
3. **定期清理日志**:定期清理无用日志文件,释放存储空间,减少系统负担。
代码示例(日常维护与备份):
```go
// 示例代码
func daily_maintenance_and_backup(){
// 日常维护与备份操作:定期备份数据,监控系统状况,清理日志文件
backup_data_regularly()
monitor_system_performance()
clean_up_logs_periodically()
}
// 日常维护与备份总结
// 通过定期备份、系统监控和日志清理等操作,可以有效保证Grafana监控平台的稳定性和可靠性。
```
通过以上优化和日常维护措施,可以提升Grafana监控平台的性能和稳定性,确保监控数据的准确性和可靠性。如果遇到其他问题,也可以通过查阅官方文档或咨询社区获得更多帮助。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了Grafana监控平台的各个方面,从简介与安装配置指南开始,涵盖了数据源与数据可视化、仪表盘创建与管理、告警与通知配置、图表类型与数据展示效果等多个主题。读者将学习如何使用Prometheus实现实时监控、优化InfluxDB与Grafana集成、进行时序数据的分析与预测,甚至探讨插件开发、仪表盘优化与集群监控等高级主题。此外,还介绍了容器化环境下的监控、自动化报表生成与导出等实用技能。无论您是初学者还是有经验的用户,都能从本专栏中获取关于Grafana监控平台的全面指南,帮助您更好地利用这一强大工具进行各种监控和分析任务。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
QPSK调制解调信号处理艺术:数学模型与算法的实战应用
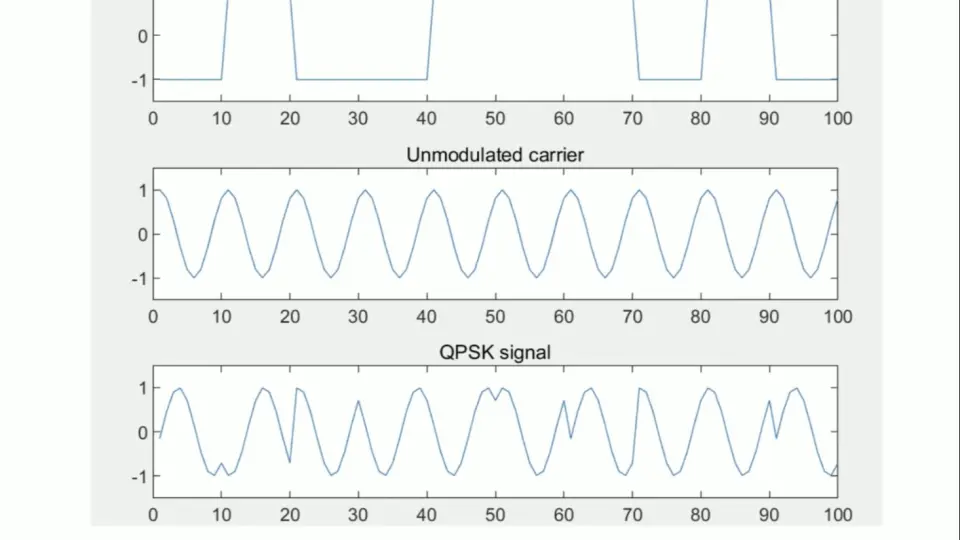
# 摘要
本文系统地探讨了QPSK(Quadrature Phase Shift Keying)调制解调技术的基础理论、实现算法、设计开发以及在现代通信中的应用。首先介绍了QPSK调制解调的基本原理和数学模型,包括信号的符号表示、星座图分析以及在信号处理中的应用。随后,深入分析了QPSK调制解调算法的编程实现步骤和性能评估,探讨了算法优化与
Chan氏算法之信号处理核心:揭秘其在各领域的适用性及优化策略

# 摘要
Chan氏算法作为信号处理领域的先进技术,其在通信、医疗成像、地震数据处理等多个领域展现了其独特的应用价值和潜力。本文首先概述了Cha
全面安防管理解决方案:中控标软件与第三方系统的无缝集成

# 摘要
随着技术的进步,安防管理系统集成已成为构建现代化安全解决方案的重要组成部分。本文首先概述了安防管理系统集成的概念与技术架构,强调了中控标软件在集成中的核心作用及其扩展性。其次,详细探讨了与门禁控制、视频监控和报警系统的第三方系统集成实践。在集成过程中遇到的挑战,如数据安全、系统兼容性问题以及故障排除等,并提出相应的对策。最后,展望了安防集成的未来趋势,包括人工智能、物联网技术
电力系统继电保护设计黄金法则:ETAP仿真技术深度剖析
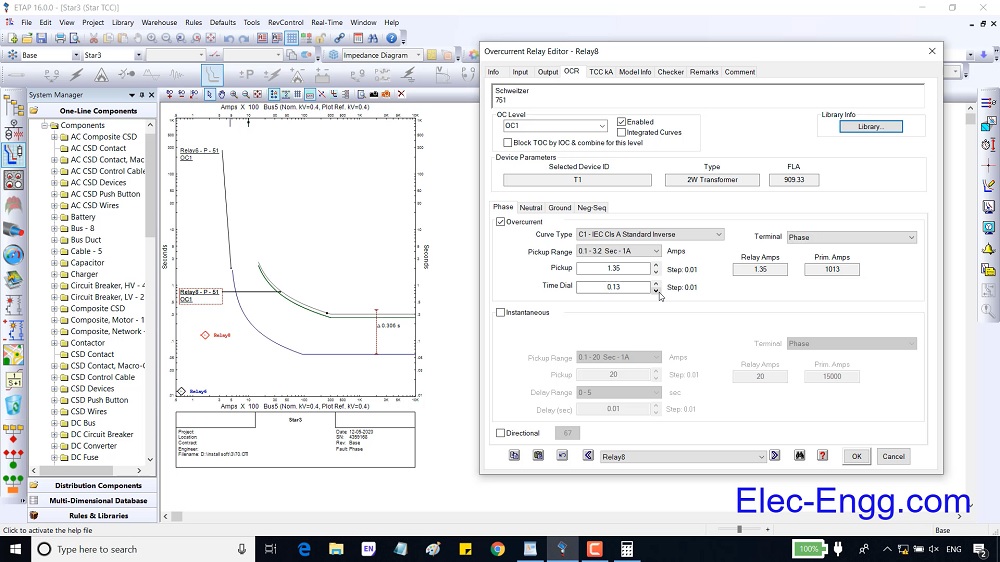
# 摘要
本文对电力系统继电保护进行了全面概述,详细介绍了ETAP仿真软件在继电保护设计中的基础应用与高级功能。文章首先阐述了继电保护的基本理论、设计要求及其关键参数计算,随后深入探讨了ETAP在创建电力系统模型、故障分析、保护方案配置与优化方面的应用。文章还分析了智能化技术、新能源并网对继电保护设计的影响,并展望了数字化转型下的新挑战。通过实际案例分析
进阶技巧揭秘:新代数控数据采集优化API性能与数据准确性

# 摘要
数控数据采集作为智能制造的核心环节,对提高生产效率和质量控制至关重要。本文首先探讨了数控数据采集的必要性与面临的挑战,并详细阐述了设计高效数据采集API的理论基础,包括API设计原则、数据采集流程模型及安全性设计。在实践方面,本文分析了性能监控、数据清洗预处理以及实时数据采集的优化方法。同时,为提升数据准确性,探讨了数据校验机制、数据一致性
从零开始学FANUC外部轴编程:基础到实战,一步到位

# 摘要
本文旨在全面介绍FANUC外部轴编程的核心概念、理论基础、实践操作、高级应用及其在自动化生产线中的集成。通过系统地探讨FANUC数控系统的特点、外部轴的角色以及编程基础知识,本文提供了对外部轴编程技术的深入理解。同时,本文通过实际案例,演示了基本与复杂的外部轴编程技巧,并提出了调试与故障排除的有效方法。文章进一步探讨了外部轴与工业机器人集成的高级功能,以及在生产线自动化
GH Bladed 高效模拟技巧:中级到高级的快速进阶之道

# 摘要
GH Bladed是一款专业的风力发电设计和模拟软件,广泛应用于风能领域。本文首先介绍了GH Bladed的基本概念和基础模拟技巧,涵盖软件界面、参数设置及模拟流程。随后,文章详细探讨了高级模拟技巧,包括参数优化和复杂模型处理,并通过具体案例分析展示了软件在实际项目中的应
【跨平台驱动开发挑战】:rockusb.inf在不同操作系统的适应性分析

# 摘要
本文旨在深入探讨跨平台驱动开发领域,特别是rockusb.inf驱动在不同操作系统环境中的适配性和性能优化。首先,对跨平台驱动开发的概念进行概述,进而详细介绍rockusb.inf驱动的核心功能及其在不同系统中的基础兼容性。随后,分别针对Windows、Linux和macOS操作系统下rockusb.inf驱动的适配问题进行了深入分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )