揭秘Java组织树算法:构建高效组织结构的秘籍
发布时间: 2024-08-28 02:11:20 阅读量: 55 订阅数: 33 

探索数据结构:构建高效算法的基石

# 1. Java组织树算法概述
组织树算法是一种用于表示和管理树形数据的算法。在Java中,组织树算法通常用于表示组织结构、文件系统或其他具有层次关系的数据。组织树算法的关键思想是使用节点来表示树中的元素,每个节点包含指向其子节点的引用。
通过使用组织树算法,可以高效地存储和检索树形数据。组织树算法还提供了对树形数据的快速访问,因为可以轻松地遍历树并访问其节点。此外,组织树算法还可以用于执行各种操作,例如插入、删除和搜索。
# 2. Java组织树算法的理论基础
### 2.1 树数据结构与组织树算法
组织树算法是一种基于树数据结构的算法,用于对复杂的数据结构进行组织和管理。树是一种非线性数据结构,它由一个根节点和多个子节点组成,每个子节点可以进一步拥有自己的子节点,形成一个层级结构。
在组织树算法中,数据元素被组织成一个树形结构,其中根节点代表整个数据集,子节点代表数据集的子集。这种结构允许对数据进行快速有效的搜索、插入和删除操作。
### 2.2 组织树算法的数学模型
组织树算法的数学模型可以表示为:
```
T = (V, E)
```
其中:
* `T`:组织树
* `V`:树中的节点集合
* `E`:连接节点的边集合
组织树算法的数学模型可以用于分析算法的复杂度和性能。例如,树的高度(即从根节点到最深叶节点的路径长度)决定了搜索操作的平均时间复杂度。
### 代码示例
以下代码示例展示了如何使用Java实现一个简单的组织树:
```java
class Node {
private String name;
private List<Node> children;
public Node(String name) {
this.name = name;
this.children = new ArrayList<>();
}
public void addChild(Node child) {
this.children.add(child);
}
public List<Node> getChildren() {
return this.children;
}
}
class OrganizationTree {
private Node root;
public OrganizationTree(Node root) {
this.root = root;
}
public void addNode(Node parent, Node child) {
parent.addChild(child);
}
public Node findNode(String name) {
return findNode(root, name);
}
private Node findNode(Node node, String name) {
if (node.getName().equals(name)) {
return node;
}
for (Node child : node.getChildren()) {
Node foundNode = findNode(child, name);
if (foundNode != null) {
return foundNode;
}
}
return null;
}
}
```
### 逻辑分析
上述代码示例展示了如何使用Java实现一个组织树。`Node`类表示树中的节点,它具有一个名称和一个子节点列表。`OrganizationTree`类表示整个组织树,它具有一个根节点。
`addNode()`方法用于向树中添加一个新节点,该节点作为给定父节点的子节点。`findNode()`方法用于在树中查找具有给定名称的节点。该方法使用递归算法,从根节点开始搜索,直到找到具有匹配名称的节点或遍历完整个树。
### 参数说明
* `name`:节点的名称
* `parent`:要添加子节点的父节点
* `child`:要添加的子节点
* `root`:组织树的根节点
# 3.1 组织树算法的Java代码实现
组织树算法在Java中的实现主要包括以下步骤:
1. **定义节点类:**创建`Node`类来表示组织树中的节点,该类应包含以下属性:
- `id`:节点的唯一标识符
- `name`:节点的名称
- `parent`:节点的父节点
- `children`:节点的子节点列表
2. **创建根节点:**使用`Node`类创建组织树的根节点,该节点没有父节点。
3. **递归创建子节点:**对于根节点的每个子节点,递归创建其子节点,直到所有节点都被创建。
4. **建立父子关系:**在创建子节点时,将子节点的`parent`属性设置为其父节点,将父节点的`children`列表中添加子节点。
5. **遍历组织树:**可以通过深度优先搜索或广度优先搜索遍历组织树,以获取节点的层次结构和关系。
以下是一个示例Java代码,展示了如何创建和遍历组织树:
```java
import java.util.ArrayList;
import java.util.List;
public class OrganizationTree {
private Node root;
public OrganizationTree() {
root = new Node(1, "Root");
}
public void addChild(int parentId, int id, String name) {
Node parent = findNodeById(parentId);
if (parent != null) {
Node child = new Node(id, name);
child.setParent(parent);
parent.getChildren().add(child);
}
}
public Node findNodeById(int id) {
return findNodeById(root, id);
}
private Node findNodeById(Node node, int id) {
if (node.getId() == id) {
return node;
} else {
for (Node child : node.getChildren()) {
Node result = findNodeById(child, id);
if (result != null) {
return result;
}
}
}
return null;
}
public void printTree() {
printTree(root, 0);
}
private void printTree(Node node, int level) {
for (int i = 0; i < level; i++) {
System.out.print(" ");
}
System.out.println(node.getName());
for (Node child : node.getChildren()) {
printTree(child, level + 1);
}
}
public static void main(String[] args) {
OrganizationTree tree = new OrganizationTree();
tree.addChild(1, 2, "Child 1");
tree.addChild(1, 3, "Child 2");
tree.addChild(2, 4, "Grandchild 1");
tree.addChild(2, 5, "Grandchild 2");
tree.addChild(3, 6, "Grandchild 3");
tree.printTree();
}
private static class Node {
private int id;
private String name;
private Node parent;
private List<Node> children;
public Node(int id, String name) {
this.id = id;
this.name = name;
this.children = new ArrayList<>();
}
public int getId() {
return id;
}
public String getName() {
return name;
}
public Node getParent() {
return parent;
}
public void setParent(Node parent) {
this.parent = parent;
}
public List<Node> getChildren() {
return children;
}
}
}
```
**代码逻辑分析:**
* `Node`类定义了组织树中节点的属性和方法。
* `OrganizationTree`类创建组织树并提供添加、查找和遍历节点的方法。
* `addChild`方法将子节点添加到指定的父节点下。
* `findNodeById`方法使用深度优先搜索递归查找具有指定ID的节点。
* `printTree`方法使用深度优先搜索递归打印组织树的层次结构。
* `main`方法创建了一个示例组织树并打印其层次结构。
# 4. Java组织树算法的应用场景
### 4.1 组织结构优化
组织结构优化是组织树算法最常见的应用场景之一。通过构建组织树,可以清晰地展示组织的层级结构、人员关系和职责分工。
**应用步骤:**
1. **收集组织数据:**收集组织成员信息,包括姓名、职务、部门等。
2. **构建组织树:**使用组织树算法构建组织树,将成员按照层级关系组织起来。
3. **分析组织结构:**通过组织树,可以分析组织结构的合理性、效率和协作性。
4. **优化组织结构:**根据分析结果,调整组织结构,优化层级关系、职责分工和沟通渠道。
**代码示例:**
```java
// 构建组织树
OrganizationTree tree = new OrganizationTree();
tree.addMember("John", "Manager", "Sales");
tree.addMember("Mary", "Employee", "Sales");
tree.addMember("Bob", "Employee", "Sales");
tree.addMember("Alice", "Manager", "Marketing");
tree.addMember("Tom", "Employee", "Marketing");
// 分析组织结构
tree.printTree();
tree.analyzeStructure();
// 优化组织结构
tree.optimizeStructure();
```
**逻辑分析:**
* `OrganizationTree`类代表组织树,提供构建、分析和优化组织结构的方法。
* `addMember()`方法添加一个成员到组织树中。
* `printTree()`方法打印组织树的层级结构。
* `analyzeStructure()`方法分析组织结构的合理性、效率和协作性。
* `optimizeStructure()`方法根据分析结果优化组织结构。
### 4.2 人员管理
组织树算法也可以用于人员管理。通过构建组织树,可以方便地管理员工信息、跟踪员工绩效和促进团队合作。
**应用步骤:**
1. **收集员工数据:**收集员工姓名、职务、部门、绩效等信息。
2. **构建组织树:**使用组织树算法构建组织树,将员工按照层级关系组织起来。
3. **管理员工信息:**通过组织树,可以轻松更新员工信息、跟踪员工绩效和分配任务。
4. **促进团队合作:**组织树可以帮助建立团队结构,促进团队成员之间的沟通和协作。
**代码示例:**
```java
// 构建组织树
EmployeeTree tree = new EmployeeTree();
tree.addEmployee("John", "Manager", "Sales", 90);
tree.addEmployee("Mary", "Employee", "Sales", 80);
tree.addEmployee("Bob", "Employee", "Sales", 70);
tree.addEmployee("Alice", "Manager", "Marketing", 85);
tree.addEmployee("Tom", "Employee", "Marketing", 75);
// 管理员工信息
tree.updateEmployee("John", "Senior Manager");
tree.trackPerformance("Mary", 95);
// 促进团队合作
tree.assignTask("Sales Team", "Develop new sales strategy");
```
**逻辑分析:**
* `EmployeeTree`类代表员工树,提供管理员工信息、跟踪绩效和促进团队合作的方法。
* `addEmployee()`方法添加一个员工到员工树中。
* `updateEmployee()`方法更新员工信息。
* `trackPerformance()`方法跟踪员工绩效。
* `assignTask()`方法分配任务给团队。
### 4.3 项目管理
组织树算法还可以用于项目管理。通过构建组织树,可以清晰地展示项目团队成员、任务分配和进度跟踪。
**应用步骤:**
1. **收集项目数据:**收集项目成员信息、任务列表和进度信息。
2. **构建组织树:**使用组织树算法构建组织树,将成员按照任务分配组织起来。
3. **管理项目团队:**通过组织树,可以管理项目团队成员、分配任务和跟踪进度。
4. **监控项目进度:**组织树可以帮助监控项目进度,识别瓶颈和采取纠正措施。
**代码示例:**
```java
// 构建组织树
ProjectTree tree = new ProjectTree();
tree.addMember("John", "Project Manager");
tree.addMember("Mary", "Developer", "Task A");
tree.addMember("Bob", "Tester", "Task B");
tree.addMember("Alice", "Designer", "Task C");
// 管理项目团队
tree.assignTask("Mary", "Task A", 50);
tree.assignTask("Bob", "Task B", 70);
// 监控项目进度
tree.trackProgress("Task A", 80);
tree.trackProgress("Task B", 60);
```
**逻辑分析:**
* `ProjectTree`类代表项目树,提供管理项目团队、分配任务和跟踪进度的方法。
* `addMember()`方法添加一个成员到项目树中。
* `assignTask()`方法分配任务给成员。
* `trackProgress()`方法跟踪任务进度。
# 5.1 算法优化
### 优化方向
组织树算法的优化主要集中在以下几个方面:
- **时间复杂度优化:**降低算法在处理大量数据时的运行时间,如采用平衡树或红黑树等数据结构。
- **空间复杂度优化:**减少算法在内存中的占用空间,如采用引用计数或内存池等技术。
- **算法效率优化:**提高算法的执行效率,如采用并行处理或缓存技术。
### 优化方法
**时间复杂度优化:**
- **平衡树:**采用平衡树(如AVL树或红黑树)作为组织树的数据结构,可以保证树的高度平衡,从而降低查找和插入操作的时间复杂度。
- **跳表:**使用跳表作为组织树的数据结构,可以利用跳表快速查找的特性,提高算法的整体效率。
**空间复杂度优化:**
- **引用计数:**采用引用计数技术,对组织树中的节点进行引用计数,当节点不再被引用时,自动释放其占用的内存空间。
- **内存池:**使用内存池管理组织树中的节点,避免频繁的内存分配和释放操作,降低空间开销。
**算法效率优化:**
- **并行处理:**将组织树算法的某些操作(如查找或插入)并行化,提高算法的整体执行效率。
- **缓存技术:**对组织树中的常用数据进行缓存,减少对底层存储的访问次数,提高算法的响应速度。
### 代码示例
**平衡树优化:**
```java
import java.util.TreeMap;
public class BalancedTreeOrganization {
private TreeMap<Integer, String> organizationTree;
public BalancedTreeOrganization() {
organizationTree = new TreeMap<>();
}
// ... 其他代码 ...
}
```
**引用计数优化:**
```java
class Node {
private int refCount;
private String data;
// ... 其他代码 ...
}
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Java 组织树算法,为构建高效组织结构提供了全面的指南。从算法基础到高级优化技巧,专栏涵盖了各种主题,包括层级遍历、动态规划、时间复杂度分析、数据持久化、可视化、访问控制、分布式架构和智能化集成。通过实战案例和技术解析,专栏帮助读者掌握 Java 组织树算法的精髓,并将其应用于构建企业级组织架构、权限管理、云计算、机器学习、微服务和敏捷开发等场景。专栏旨在帮助读者理解算法的原理、优化方法和实际应用,从而构建高效、灵活和可扩展的组织结构。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【从理论到实践:TRL校准件设计的10大步骤详解】:掌握实用技能,提升设计效率

# 摘要
本文详细介绍了TRL校准件的设计流程与实践应用。首先概述了TRL校准件的设计概念,并从理论基础、设计参数规格、材料选择等方面进行了深入探讨。接着,本文阐述了设计软件与仿真
CDP技术揭秘:从机制到实践,详解持续数据保护的7个步骤

# 摘要
连续数据保护(CDP)技术是一种高效的数据备份与恢复解决方案,其基本概念涉及实时捕捉数据变更并记录到一个连续的数据流中,为用户提供对数据的即
【俄罗斯方块游戏开发宝典】:一步到位实现自定义功能

# 摘要
本文全面探讨了俄罗斯方块游戏的开发过程,从基础理论、编程准备到游戏逻辑的实现,再到高级特性和用户体验优化,最后涵盖游戏发布与维护。详细介绍了游戏循环、图形渲染、编程语言选择、方块和游戏板设计、分数与等级系统,以及自定义功能、音效集成和游戏进度管理等关键内容。此外,文章还讨论了交
【物联网中的ADXL362应用深度剖析】:案例研究与实践指南
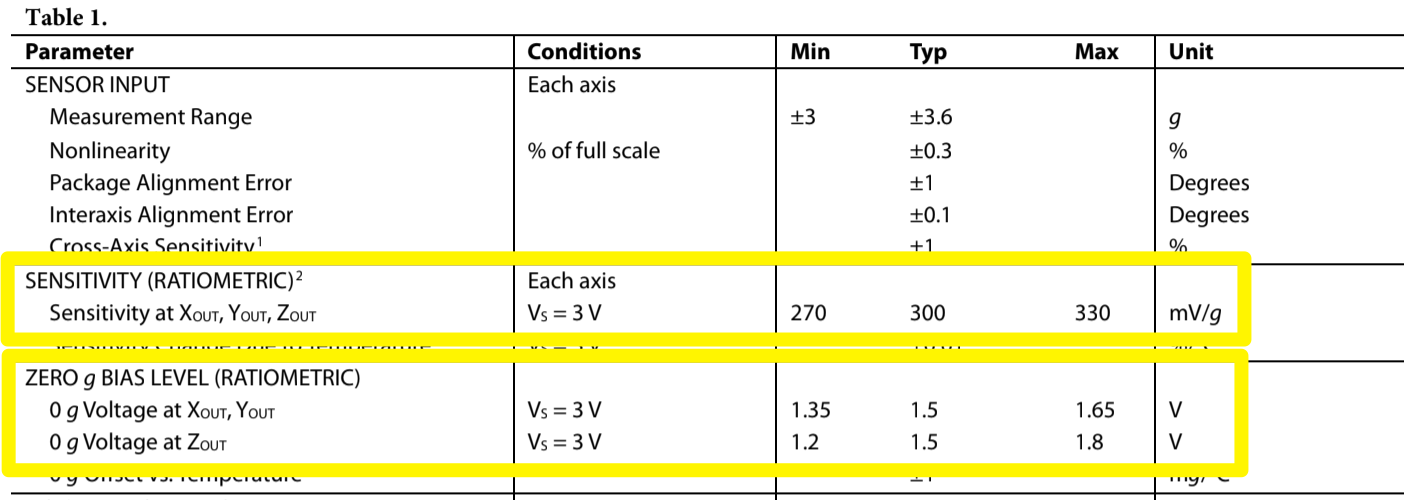
# 摘要
本文针对ADXL362传感器的技术特点及其在物联网领域中的应用进行了全面的探讨。首先概述了ADXL362的基本技术特性,随后详细介绍了其在物联网设备中的集成方式、初始化配置、数据采集与处理流程。通过多个应用案例,包括健康监测、智能农业和智能家居控制,文章展示了ADXL362传感器在实际项目中的应用情况和价值。此外,还探讨了高级数据分析技术和机器学习的应用,以及在物联网应用中面临的挑战和未来发展。本
HR2046技术手册深度剖析:4线触摸屏电路设计与优化

# 摘要
本文综述了4线触摸屏技术的基础知识、电路设计理论与实践、优化策略以及未来发展趋势。首先,介绍了4线触摸屏的工作原理和电路设计中影响性能的关键参数,接着探讨了电路设计软件和仿真工具在实际设计中的应用。然后,详细分析了核心电路设计步骤、硬件调试与测试
CISCO项目实战:构建响应速度极快的数据监控系统

# 摘要
随着信息技术的快速发展,数据监控系统已成为保证企业网络稳定运行的关键工具。本文首先对数据监控系统的需求进行了详细分析,并探讨了其设计基础。随后,深入研究了网络协议和数据采集技术,包括TCP/IP协议族及其应用,以及数据采集的方法和实践案例。第三章分析了数据处理和存储机制,涉及预处理技术、不同数据库的选择及分布式存储技术。第四章详细介绍了高效数据监控系统的架
【CAPL自动化测试艺术】:详解测试脚本编写与优化流程

# 摘要
本文全面介绍了CAPL自动化测试,从基础概念到高级应用再到最佳实践。首先,概述了CAPL自动化测试的基本原理和应用范围。随后,深入探讨了CAPL脚本语言的结构、数据类型、高级特性和调试技巧,为测试脚本编写提供了坚实的理论基础。第三章着重于实战技巧,包括如何设计和编写测试用例,管理测试数
【LDO设计必修课】:如何通过PSRR测试优化电源系统稳定性

# 摘要
线性稳压器(LDO)设计中,电源抑制比(PSRR)是衡量其抑制电源噪声性能的关键指标。本文首先介绍LDO设计基础与PSRR的概念,阐述P
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )