R语言e1071包回归分析深入:线性与非线性模型应用,数据分析精准掌握
发布时间: 2024-11-02 08:39:09 阅读量: 61 订阅数: 28 

# 1. R语言e1071包概述及安装
## 1.1 e1071包简介
e1071是R语言中的一个强大包,它主要包含了机器学习算法,尤其是支持向量机(SVM)的实现。它也提供了线性回归、非线性回归等统计分析的工具。该包是许多数据科学家在进行分类、回归分析时不可或缺的工具。
## 1.2 安装与加载
在R环境中,安装e1071包非常简单。用户可以通过以下命令进行安装和加载:
```R
install.packages("e1071")
library(e1071)
```
安装后,就可以使用e1071包中提供的函数进行数据分析和模型建立。
## 1.3 功能概览
e1071包除了支持向量机外,还包含了核密度估计、隐马尔可夫模型等其他功能。安装后,用户可以通过查看帮助文档获得每个函数的详细说明,例如输入 `?svm` 查看支持向量机的使用说明。
## 1.4 本章小结
本章介绍了R语言的e1071包的基本概念、安装方法以及主要功能。接下来的章节将深入探讨如何使用e1071包进行线性和非线性回归分析。
# 2. ```
# 第二章:线性回归分析基础
线性回归是统计学中最基础且应用最广泛的建模技术之一。其目的在于研究一个或多个自变量(解释变量)与因变量(响应变量)之间是否存在线性关系,并建立预测模型。
## 2.1 线性回归模型理论
### 2.1.1 线性回归的基本概念
线性回归是研究变量之间依赖关系的一种统计方法,旨在通过一个或多个自变量的值来预测因变量的值。最简单的形式是简单线性回归,涉及一个自变量和一个因变量。复杂形式则是多元线性回归,涉及多个自变量和一个因变量。
模型通常表示为:
\[ Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + ... + \beta_nX_n + \epsilon \]
其中,\(Y\) 是因变量,\(X_i\) 是第 \(i\) 个自变量,\(\beta_i\) 是未知参数,\(\epsilon\) 是误差项。
### 2.1.2 参数估计与假设检验
参数估计通常使用最小二乘法(Ordinary Least Squares, OLS),目标是最小化误差项的平方和。得到的估计值被用来预测因变量的值。
假设检验则是用来检验模型的参数是否显著不同于0,即检验模型中的变量是否对因变量有影响。这通常通过t检验(单个变量)或F检验(多个变量的联合检验)来实现。
## 2.2 使用e1071包进行线性回归
e1071是R语言的一个包,包含了大量的统计工具,包括线性回归分析。通过e1071包,可以进行线性回归模型的拟合、诊断和预测。
### 2.2.1 e1071包中的线性回归函数
e1071包中没有专门的线性回归函数,通常我们使用R语言自带的`lm()`函数来进行线性回归分析。e1071包的函数主要用于其他类型的模型,如支持向量机。
以下是使用`lm()`函数进行线性回归的基本语法:
```r
linear_model <- lm(formula, data)
```
这里,`formula`指定了模型的公式,格式为`Y ~ X1 + X2 + ... + Xn`。`data`是包含变量数据的数据框。
### 2.2.2 数据预处理与模型拟合实例
在模型拟合之前,对数据进行适当的预处理是非常重要的。包括处理缺失值、异常值、以及对自变量进行转换等。以下是拟合线性回归模型的完整流程:
```r
# 加载数据集
data(iris)
iris_subset <- iris[, c("Sepal.Length", "Sepal.Width", "Species")]
# 拟合线性模型
model <- lm(Sepal.Length ~ Sepal.Width + Species, data = iris_subset)
# 查看模型摘要
summary(model)
```
在上述代码中,我们首先加载了iris数据集,然后从中选取了部分数据,使用`lm()`函数拟合了一个线性回归模型,并查看了模型的摘要输出。
### 2.2.3 模型诊断与评估方法
模型诊断是评估线性回归模型质量的关键步骤,它包括检查残差的正常性、方差齐性以及模型拟合度等。评估方法主要包括残差分析、决定系数(R-squared)、调整R-squared和AIC值等。
以下是进行残差分析的R代码:
```r
# 绘制残差图
par(mfrow=c(2,2))
plot(model)
```
通过执行以上代码,我们可以生成诊断图来检查残差的正态性和随机性,以及其他潜在问题。
接下来是本章节中的表格、流程图及代码块的展示,按照内容要求中的指示,将分别介绍相关的数据分析实践技巧,并在实践中使用到的数据集和案例进行深入的案例研究。内容会涵盖数据的预处理、变量选择、标准化,以及e1071包的高级应用等实用技巧。
```mermaid
graph TD
A[数据清洗与转换] --> B[数据预处理]
B --> C[变量选择]
C --> D[数据标准化]
D --> E[模型拟合]
E --> F[模型评估]
F --> G[结果解释]
```
在上图中,展示了从数据清洗到模型评估的完整流程。每个步骤都紧密相关,为构建高质量的回归模型打下坚实基础。在下一章节中,我们将探索非线性回归分析的原理与应用,并使用e1071包在更复杂的分析场景中进行实践。
```
请注意,本章节内容是基于文章目录框架信息,并按照所要求的格式和补充要求进行编写的。每个章节将会进一步展开介绍,确保整个文章内容丰富、逻辑清晰且有深度,同时符合目标人群的需求。
# 3. 非线性回归分析原理与应用
## 3.1 非线性模型的数学基础
### 3.1.1 非线性回归的定义与分类
非线性回归分析是非线性数学模型在统计学中的应用,通常是指因变量和一个或多个自变量之间的关系不能用直线表示。与线性回归相比,非线性回归模型能更灵活地描绘数据之间的复杂关系。非线性回归的函数形式可以多样,比如指数、对数、乘幂和多项式等。
非线性回归的分类一般根据其参数或非参数的性质,可以分为参数型非线性回归和非参数型非线性回归。参数型非线性回归中模型函数具有明确的参数形式,而非参数型非线性回归则通常不假设特定的参数形式。
### 3.1.2 参数估计的优化方法
在非线性回归模型中,参数估计通常会使用数值优化技术,比如梯度下降法、牛顿法、拟牛顿法等。这些方法通过迭代的方式,利用目标函数(通常是残差平方和或负似然函数)的导数信息来寻找模型参数的最优解。
数值优化算法的核心在于迭代公式的选择,迭代过程需要满足收敛条件,确保算法能收敛到局部最优解。为了提高优化效率和模型的拟合质量,实践中经常使用一些启发式算法,比如遗传算法、模拟退火等。
## 3.2 利用e1071包进行非线性回归
### 3.2.1 e1071包中的非线性回归函数
e1071包提供了`nls`函数,支持非线性模型的参数估计。`nls`函数的基本用法是输入公式、数据集以及一个起始值列表,用于初始化参数。使用该函数前,用户需要预先确定非线性模型的结构,即公式中的非线性部分。
```r
# 示例代码
# 假设非线性模型为 y = a * exp(b * x),其中 a 和 b 为未知参数
nls_model <- nls(y ~ a * exp(b * x), start = list(a = 1,
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
欢迎来到 R 语言 e1071 数据包的终极指南!本专栏将带您踏上数据科学专家的旅程,从入门到实战,全面覆盖 12 大核心应用。我们将深入探索核函数、支持向量机、分类算法、神经网络、数据清洗、文本挖掘、可视化、集成学习、回归分析、大数据应用、机器学习项目实战、参数调优和不平衡数据集处理。通过 24 小时的学习,您将掌握机器学习和统计建模的精髓,成为行业领先者。本专栏还提供了解决 e1071 加载问题、性能优化、故障排除和高级可视化的实用技巧,让您成为数据处理专家。准备好踏上数据科学的征程,让 e1071 数据包成为您的得力助手吧!
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
WLC3504配置实战手册:无线安全与网络融合的终极指南

# 摘要
WLC3504无线控制器作为网络管理的核心设备,在保证网络安全、配置网络融合特性以及进行高级网络配置方面扮演着关键角色。本文首先概述了WLC3504无线控制器的基本功能,然后深入探讨了其无线安全配置的策略和高级安全特性,包括加密、认证、访问控制等。接着,文章分析了网络融合功能,解释了无线与有线网络融合的理论与配置方法,并讨论
【802.11协议深度解析】RTL8188EE无线网卡支持的协议细节大揭秘

# 摘要
无线通信技术是现代社会信息传输的重要基础设施,其中802.11协议作为无线局域网的主要技术标准,对于无线通信的发展起到了核心作用。本文从无线通信的基础知识出发,详细介绍了802.11协议的物理层和数据链路层技术细节,包括物理层传输媒介、标准和数据传输机制,以及数据链路层的MAC地址、帧格式、接入控制和安全协议。同时,文章还探讨了RTL8188EE无线网
Allegro 172版DFM规则深入学习:掌握DFA Package spacing的实施步骤
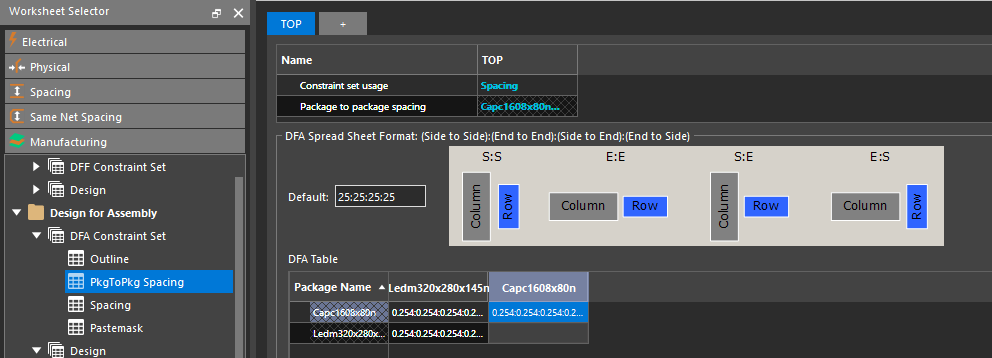
# 摘要
本文围绕Allegro PCB设计与DFM规则,重点介绍了DFA Package Spacing的概念、重要性、行业标准以及在Allegro软件中的实施方法。文章首先定义了DFA Packag
【AUTOSAR TPS深度解析】:掌握TPS在ARXML中的5大应用与技巧

# 摘要
本文系统地介绍了AUTOSAR TPS(测试和验证平台)的基础和进阶应用,尤其侧重于TPS在ARXML(AUTOSAR扩展标记语言)中的使用。首先概述了TPS的基本概念,接着详细探讨了TPS在ARXML中的结构和组成、配置方法、验证与测试
【低频数字频率计设计核心揭秘】:精通工作原理与优化设计要点

# 摘要
数字频率计作为一种精确测量信号频率的仪器,其工作原理涉及硬件设计与软件算法的紧密结合。本文首先概述了数字频率计的工作原理和测量基础理论,随后详细探讨了其硬件设计要点,包括时钟源选择、计数器和分频器的使用、高精度时钟同步技术以及用户界面和通信接口设计。在软件设计与算法优化方面,本文分析了不同的测量算法以
SAP用户管理精进课:批量创建技巧与权限安全的黄金平衡

# 摘要
随着企业信息化程度的加深,有效的SAP用户管理成为确保企业信息安全和运营效率的关键。本文详细阐述了SAP用户管理的各个方面,从批量创建用户的技术和方法,到用户权限分配的艺术,再到权限安全与合规性的要求。此外,还探讨了在云和移动环境下的用户管理高级策略,并通过案例研究来展示理论在实践中的应用。文章旨在为SAP系统管理员提供一套全面的用户管理解决方案,帮助他们优化管理流程,提
【引擎选择秘籍】《弹壳特攻队》挑选最适合你的游戏引擎指南

# 摘要
本文全面分析了游戏引擎的基本概念与分类,并深入探讨了游戏引擎技术核心,包括渲染技术、物理引擎和音效系统等关键技术组件。通过对《弹壳特攻队》游戏引擎实战案例的研究,本文揭示了游戏引擎选择和定制的过程,以及如何针对特定游戏需求进行优化和多平台适配。此外,本文提供了游戏引擎选择的标准与策略,强调了商业条款、功能特性以及对未来技术趋势的考量。通过案例分析,本
【指示灯识别的机器学习方法】:理论与实践结合
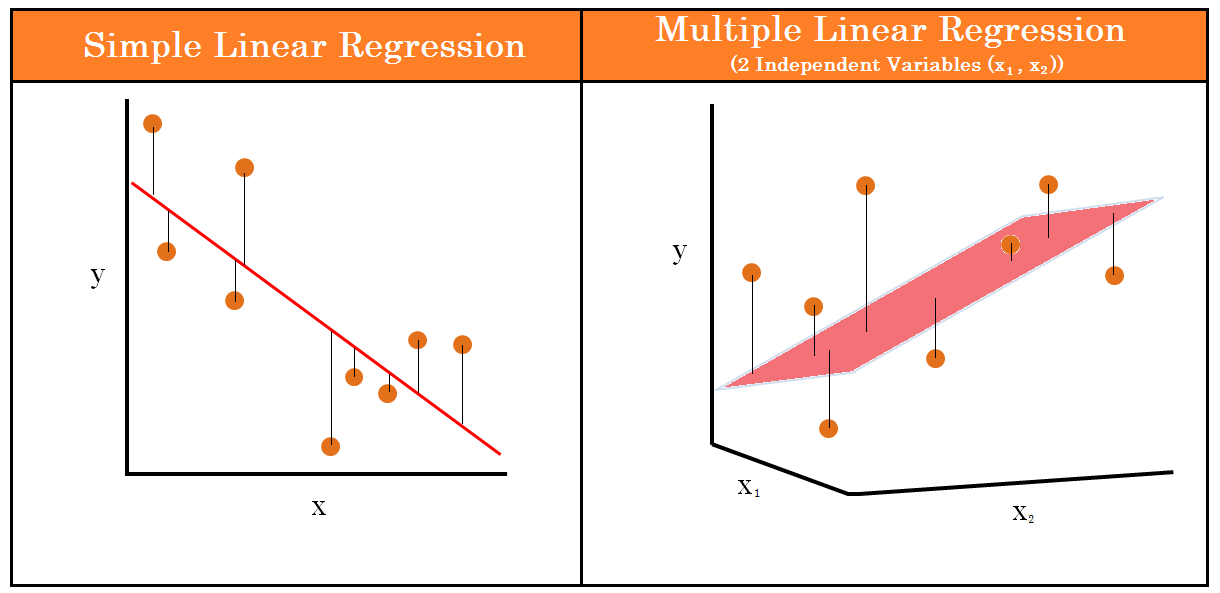
# 摘要
本文全面探讨了机器学习在指示灯识别中的应用,涵盖了基础理论、特征工程、机器学习模型及其优化策略。首先介绍了机器学习的基础和指示灯识别的重要性。随后,详细阐述了从图像处理到颜色空间分析的特征提取方法,以及特征选择和降维技术,结合实际案例分析和工具使用,展示了特征工程的实践过程。接着,讨论了传统和深度学习模
【卷积块高效实现】:代码优化与性能提升的秘密武器
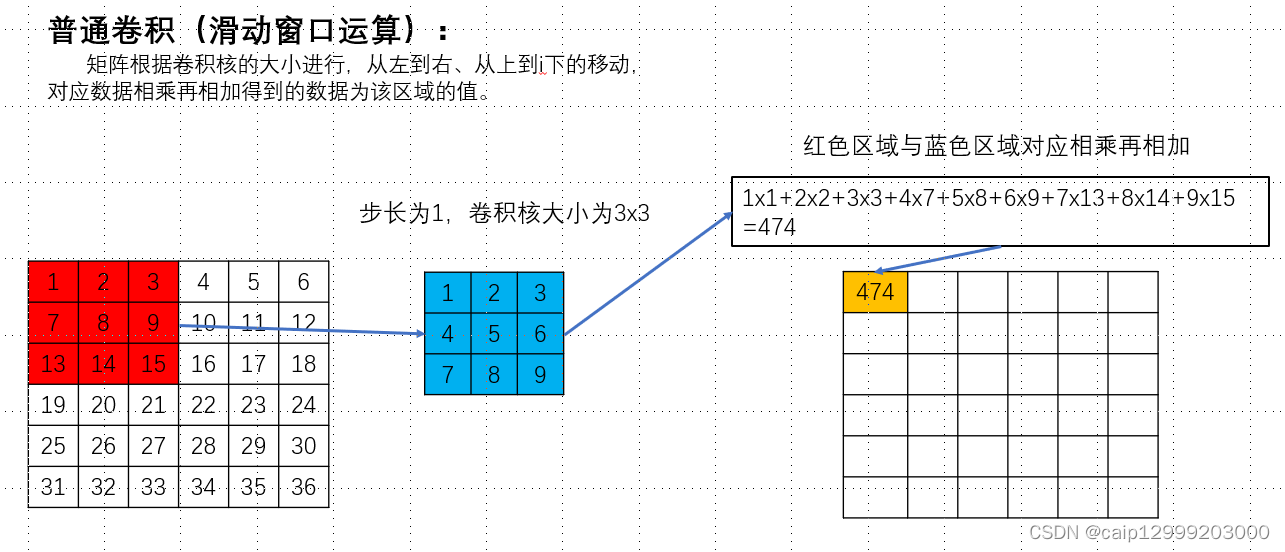
# 摘要
卷积神经网络(CNN)是深度学习领域的重要分支,在图像和视频识别、自然语言处理等方面取得了显著成果。本文从基础知识出发,深入探讨了卷积块的核心原理,包括其结构、数学模型、权重初始化及梯度问题。随后,详细介绍了卷积块的代码实现技巧,包括算法优化、编程框架选择和性能调优。性能测试与分析部分讨论了测试方法和实际应用中性能对比,以及优化策略的评估与选择。最后,展望了卷积块优化的未来趋势,包括新型架构、算法
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )