




深度学习优化关键:YOLOv8的GPU加速策略详解

1. YOLOv8模型概述及关键优化点
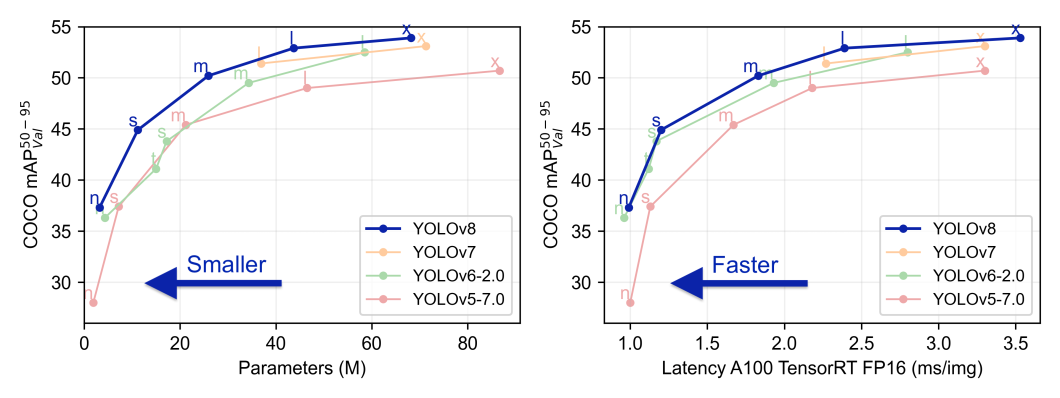
YOLOv8作为新一代的目标检测模型,继承了YOLO系列一贯的高效准确特点,并在多个方面进行了创新和优化。首先,YOLOv8模型的结构设计更为精简,通过减少冗余操作和改进损失函数,有效提高了检测速度和精度。其次,引入了自注意力机制和空洞卷积技术,使得模型在处理小目标和密集场景时表现出色。此外,YOLOv8针对不同硬件平台的兼容性做了深入优化,特别是对GPU加速的支持,使得模型在实际应用中可以实现更快的推理速度。接下来,我们将深入分析YOLOv8的关键优化点,并探讨这些优化如何在GPU加速的环境中发挥最佳效果。
2. GPU加速技术基础
2.1 GPU硬件架构与并行计算原理
2.1.1 GPU硬件组成简介
现代图形处理单元(GPU)是专为处理图形和并行计算任务而设计的硬件设备。GPU拥有大量的计算核心,能够同时执行成千上万的操作,相比于CPU,它在处理大规模并行任务时具有明显优势。GPU的核心组成可以概括为以下几个方面:
- Streaming Multiprocessors (SMs) / Compute Units (CUs):负责执行计算任务的处理器单元。每个SM/CU含有多个流处理器(CUDA核心),执行实际的计算工作。
- 寄存器:每个CUDA核心都有自己的寄存器,用于存储计算中的临时数据。
- 共享内存:位于每个SM/CU中,是一种低延迟的内存,可以被同一SM/CU中的CUDA核心访问。
- 全局内存:GPU上的大容量内存,所有的SM/CU都可以访问,但访问速度较慢。
- 纹理和常量内存:特殊用途的内存,用于存储只读数据,可以被优化以提供快速访问。
- 缓存和带宽:为了支持大流量的数据传输,GPU拥有专用的缓存系统和高带宽接口。
2.1.2 并行计算在GPU中的应用
在GPU上实现并行计算,关键在于将任务分解为可以同时执行的小块(称为“线程”),并有效地管理这些线程的执行。每个线程执行相同的指令,但处理不同的数据——这是SIMD(单指令多数据)的概念。利用GPU进行并行计算主要包括以下几个步骤:
- 任务分解:将计算任务分解为可以并行执行的小任务,即线程。
- 线程组织:根据硬件架构组织线程。GPU通常将线程组织为"线程块"(Block),再将线程块组织为"网格"(Grid)。
- 资源分配:将数据和计算任务映射到GPU的内存层次结构中。
- 执行与同步:在线程块内进行同步操作,确保线程间的正确协作,并在不同块间可能需要进行显式的同步。
- 内存管理:合理利用共享内存、全局内存以及纹理和常量内存,减少内存访问延迟和带宽的浪费。
GPU中的并行计算原理,使得它非常适合执行深度学习中的矩阵运算和特征处理等任务。
2.2 GPU加速的软件支持
2.2.1 CUDA与cuDNN的作用和优化
CUDA(Compute Unified Device Architecture)是由NVIDIA推出的并行计算平台和编程模型,允许开发者使用C、C++等语言为GPU编写应用程序。CUDA编程模型定义了一套API,它使GPU能够执行通用计算任务,而不仅仅是图形渲染。使用CUDA可以有效地利用GPU的计算能力,进行大规模数据处理。
cuDNN(CUDA Deep Neural Network library)是专为深度学习设计的GPU加速库,为卷积神经网络(CNN)和其他深度神经网络提供了高度优化的例程。它减少了实现深度学习算法时的工程复杂性,能够自动进行内存管理,并对一些关键操作提供硬件加速。开发者能够利用cuDNN的优化特性,在GPU上运行复杂的神经网络模型,实现更高效的计算。
优化方面,使用CUDA和cuDNN需要注意以下几点:
- 内存管理:合理分配和管理全局内存、共享内存、常量内存,以减少内存访问延时。
- 核函数(Kernels)调优:优化线程块的大小和数量,以充分利用GPU资源。
- 异步执行和流控制:通过使用CUDA流来管理不同的任务,实现它们的异步执行和重叠计算与数据传输,提高效率。
- 利用cuDNN优化层:使用cuDNN提供的高效层实现替代自定义的层实现,以获得更好的性能。
2.2.2 GPU支持的深度学习框架
目前,市场上存在多种深度学习框架,它们支持在GPU上运行,极大地方便了开发者。这些框架包括但不限于TensorFlow、PyTorch、Keras和MXNet。它们通常构建在CUDA和cuDNN之上,屏蔽了底层的复杂性,使得编写深度学习模型更加容易和高效。
深度学习框架提供了一系列优化措施,以利用GPU强大的计算能力:
- 自动梯度计算:自动计算反向传播过程中的梯度,节约开发者时间。
- 高效的数据并行处理:通过数据并行化自动在多个GPU上分散计算任务。
- 内存优化:动态管理GPU内存,减少内存碎片和溢出的风险。
- 内置优化算子:框架内部实现了一些高效的算子,例如卷积、激活、池化等。
2.3 深度学习模型在GPU上的优化策略
2.3.1 模型并行与数据并行的原理
深度学习模型在GPU上的优化可以分为两种主要策略:模型并行和数据并行。这两种方法各有其优势和适用场景:
- 模型并行:是指将一个大的深度学习模型分割成几个小块,并将这些块分配到不同的GPU上并行处理。在模型很大、单个GPU的内存不足以容纳整个模型时,这种方式尤为适用。模型并行的挑战在于管理跨设备的数据流和同步。
- 数据并行:是指将数据分成多个批次,并将每个批次的数据同时发送到多个GPU进行处理。不同GPU上运行的是相同的模型副本,每份副本处理一部分数据。数据并行较容易实现,且能够有效利用多个GPU的计算资源,是目前最常见的并行策略。
2.3.2 深度学习计算图优化
深度学习模型通常可以通过计算图来表示,其中包含节点和边,节点代表数据或操作,边代表数据流向。计算图优化是提高GPU上模型运行效率的关键技术之一。以下是一些优化计算图的策略:
- 算子融合(Operator Fusion):将多个连续的小操作合并为一个大的操作,减少中间结果的内存写入和读取,降低开销。
- 内核融合(Kernel Fusion):与算子融合类似,但在更低层次上操作,将多个GPU核函数合并为一个,减少线程同步和调度开销。
- 图优化:利用图优化技术简化计算图结构,例如消除冗余操作或简化计算流程。
- 内存预分配:合理地预分配内存,减少动态内存分配带来的延迟。
深度学习模型在GPU上的优化不仅仅局限于计算图层面,还需要综合考虑数据的流动、内存的使用和并行执行的效率。适当的优化可以大幅提升模型训练和推理的速度,使开发者能够更高效地利用GPU的计算资源。
3. YOLOv8的GPU加速实现
3.1 YOLOv8的网络结构分析
3.1.1 YOLOv8架构的关键改进
YOLOv8网络架构的设计在继承了YOLO系列快速准确特点的同时,引入了诸多创新以进一步提升模型性能。关键改进体现在以下几个方面:
-
改进的Backbone:YOLOv8引入了更深层次的卷积层和残差结构,这增强了网络提取复杂特征的能力,提高了对小目标和密集目标的检测精度。
-
增强的neck结构:YOLOv8对特征金字塔网络(FPN)进行优化,通过自适应特征融合技术,使得不同尺度的特征更好地传递信息,提升检测的多尺度适应性。
-
灵活的head设计:在输出头部分,YOLOv8通过引入多尺度预测头和注意力机制,使模型能够更好地关注图像中的重要区域,并提高预测的精度。
3.1.2 特征提取与检测流程
YOLOv8的核心是一个由卷积层组成的深度神经网络,其处理流程主要分为以下几个阶段:
-
输入阶段:网络接收图像作为输入,通常会进行大小调整以符合网络接受的尺寸要求。
-
特征提取:通过Backbone网络,输入图像被转换为一系列卷积特征图。这些特征图捕捉了图像的高层语义信息和空间细节信息。
-
特征融合:特征图随后通过neck结构进一步融合处理,形成一个丰富的特征金字塔。
-
目标检测:在head结构中,特征金字塔被用于预测边界框和类别概率。网络为图像中可能存在的每个目标生成一组候选框,并估计框的位置和类别概率。
-
后处理:最终输出经过非极大值抑制(NMS)算法,以减少重叠的边界框,保留最可能的目标检测结果。
3.1.3 YOLOv8架构的代码实现
为了更好地理解YOLOv8网络架构的工作原理,我们可以借助伪代码来展示其架构的实现过程。以下是一个简化的YOLOv8架构实现的伪代码示例:
- def build_yolov8_model(input_shape, num_classes):
- # 构建Backbone网络
- backbone = create_backbone(input_shape)
- # 构建neck结构,包括特征融合和特征增强
- neck = create_neck(backbone)
- # 构建head,用于目标检测
- head = create_head(neck, num_classes)
- # 定义整个YOLOv8模型
- model = Model(inputs=input_tensor

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【机器人算法优化】:D-H建模基础与数学应用
【性能优化秘籍】:Android USB摄像头性能提升的7个关键步骤
【菊水电源通讯手册:监控与管理技巧】:维护最佳运行状态的策略
TFS2015用户账户与权限迁移:详细操作流程与常见错误避免
VHDL-AMS电路优化:4个策略,快速提升电路设计性能
数据库迁移实战:Genesis-v10.0从Oracle到PostgreSQL操作指南
SAP语言包安装监控:实时监控与性能指标分析
eWebEditor多语言支持与国际化:完美本地化实施手册
STC8 PWM技术揭秘:实现速度与亮度精准控制


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















