




【Pandas DataFrame核心概念】:行和列求和的逻辑与实践

参考资源链接:python中pandas.DataFrame对行与列求和及添加新行与列示例
1. Pandas DataFrame简介与安装
Pandas是Python中一个强大的数据处理库,而DataFrame是Pandas库的核心数据结构,它是一种二维标签数据结构,类似于Excel表格、SQL表或Series对象的字典类型。每个列都有一个名称,并且可以包含不同类型的数据。DataFrame对于数据清洗、处理和分析至关重要,是数据科学家进行数据挖掘的利器。
安装Pandas
要开始使用Pandas,首先需要安装它。可以使用pip包管理器进行安装:
- pip install pandas
安装完成后,在Python脚本中通过以下方式导入Pandas库:
- import pandas as pd
DataFrame的引入
在Pandas中,你可以通过将字典或NumPy数组等数据类型传递给pd.DataFrame()函数来创建DataFrame。例如,创建一个基础的DataFrame,可以这样做:
- data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
- df = pd.DataFrame(data)
- print(df)
上述代码会输出一个结构化的数据表:
- A B
- 0 1 4
- 1 2 5
- 2 3 6
这样,你就成功创建了你的第一个DataFrame,并且理解了如何使用Pandas库。在接下来的章节中,我们将逐步深入了解DataFrame的更多特性。
2. DataFrame基础结构理解
在深入了解Pandas DataFrame之前,我们需要掌握其基础结构,以便能够更加熟练地操纵和分析数据。本章节主要关注于DataFrame的创建、索引机制以及数据类型与结构的理解。
2.1 DataFrame的创建与基本属性
2.1.1 创建DataFrame的方法
在Pandas中,创建DataFrame是一个非常基础且重要的操作。它可以由字典、列表、Series、另一个DataFrame等不同的数据源来创建。以下是几种创建DataFrame的基本方法:
- 使用字典创建DataFrame:
- import pandas as pd
- data = {
- 'Name': ['Tom', 'Nick', 'Krish', 'Jack'],
- 'Age': [20, 21, 19, 18]
- }
- df = pd.DataFrame(data)
在这个例子中,字典的键成为了DataFrame的列名,字典的值则构成了DataFrame的列数据。
- 使用列表创建DataFrame:
- data = [['Tom', 20], ['Nick', 21], ['Krish', 19], ['Jack', 18]]
- df = pd.DataFrame(data, columns=['Name', 'Age'])
这里使用列表的列表来创建DataFrame,并指定了列名。
- 由Series创建DataFrame:
- s1 = pd.Series([1, 2, 3, 4], name='Numbers')
- s2 = pd.Series(['a', 'b', 'c', 'd'], name='Letters')
- df = pd.concat([s1, s2], axis=1)
此处展示了如何将两个Series对象合并为DataFrame,axis=1参数意味着横向合并。
2.1.2 访问DataFrame的基本属性
创建好DataFrame后,我们需要了解如何访问其基本属性。这些属性帮助我们更好地了解数据的结构和内容。
.columns属性可以用来查看DataFrame的所有列名:
- print(df.columns)
.index属性可以用来查看DataFrame的索引:
- print(df.index)
.values属性可以用来获取DataFrame中的实际数据,返回的是一个NumPy数组:
- print(df.values)
.shape属性可以用来获取DataFrame的维度:
- print(df.shape)
了解这些基本属性,能让我们在对数据进行后续操作之前,先有个大致的认识和准备。
2.2 DataFrame的索引机制
DataFrame的索引机制是其强大功能的一部分,这让我们可以方便地访问和操作数据。
2.2.1 行索引和列索引的设置
索引在Pandas中是非常灵活的,既可以通过.set_index()方法设置新的索引,也可以通过创建DataFrame时的参数直接指定。
- 设置新的索引:
- df.set_index('Name', inplace=True)
在这个例子中,'Name'列现在变成了索引。
- 创建时指定索引:
- df = pd.DataFrame({
- 'Age': [20, 21, 19, 18]
- }, index=['Tom', 'Nick', 'Krish', 'Jack'])
这里在创建DataFrame的同时,指定了行索引。
2.2.2 索引的选择与修改
通过索引我们可以精确地访问DataFrame中的数据。Pandas提供了多种选择数据的方式,包括.loc[]和.iloc[]。
- 使用
.loc[]进行标签选择:
- print(df.loc['Tom'])
- 使用
.iloc[]进行位置选择:
- print(df.iloc[0])
索引的修改则涉及到对索引的重新赋值,例如:
- df.index = ['T', 'N', 'K', 'J']
这会将原有的索引修改为新的标签。
2.3 DataFrame的数据类型与结构
理解DataFrame的数据类型和结构是分析数据时非常关键的一个步骤。
2.3.1 数据类型及其转换
Pandas支持多种数据类型,例如int64、float64、bool、datetime64等。要查看各列的数据类型,可以使用.dtypes属性:
- print(df.dtypes)
数据类型的转换可以通过.astype()方法来完成:
- df['Age'] = df['Age'].astype('float')
这行代码将'Age'列的数据类型从整数转换为了浮点数。
2.3.2 数据结构的查看与操作
查看DataFrame的内部数据结构,可以使用.info()方法:
- df.info()
这个方法会显示每个列的数据类型以及非空值的数量。
操作数据结构包括增加、删除、重新排列列等。例如,删除一列可以使用.drop()方法:
- df.drop('NewColumn', axis=1, inplace=True)
而添加列则可以简单地赋值:
- df['NewColumn'] = df['Age'] + 1
通过这些操作,我们可以灵活地管理DataFrame的数据结构以适应我们的数据分析需求。
以上内容详细介绍了DataFrame的基础结构,包括其创建方法、基本属性以及索引机制和数据类型的转换操作。这为进一步的数据分析打下了坚实的基础。
3. DataFrame的数据操作
3.1 数据的插入与删除
数据插入与删除是数据处理中常见的操作,它们对于数据清洗和预处理至关重要。在本节中,我们将探讨如何使用Pandas进行数据插入和删除操作,包括新增列和行,以及删除不需要的数据。
3.1.1 新增列和行的方法
新增列
在DataFrame中新增一个列,可以直接对DataFrame对象进行赋值操作。假设我们有一个包含学生信息的DataFrame,需要增加一个表示年龄的列。
- import pandas as pd
- # 创建一个示例DataFrame
- students = pd.DataFrame({
- 'name': ['Alice', 'Bob', 'Charlie'],
- 'score': [88, 95, 82]
- })
- # 新增一个'age'列
- students['age'] = [20, 21, 22]
- print(students)
上述代码执行后,会在students DataFrame中新增一个名为age的列,数据类型应与赋值列表的数据类型一致。
新增行
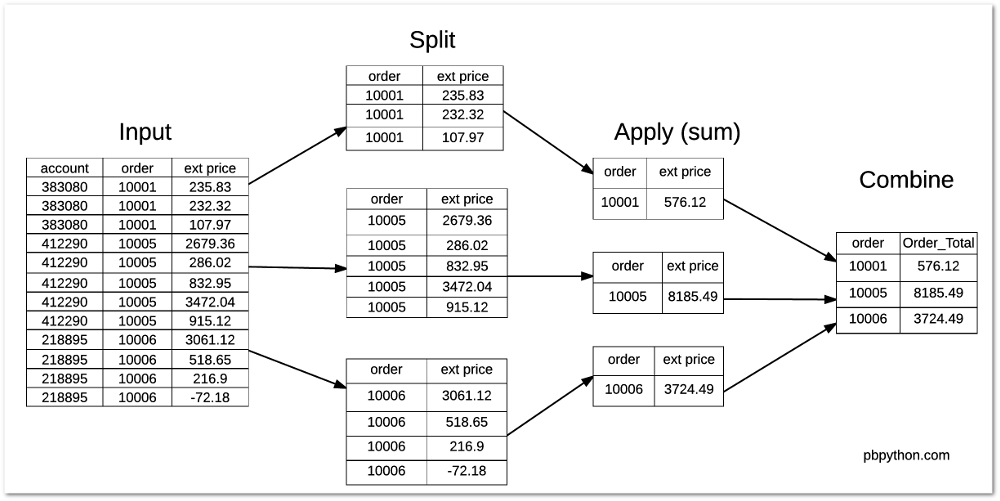
新增行则通常使用append方法,或者直接使用pd.concat函数将另一个DataFrame合并到现有的DataFrame中。假设有新的学生信息需要添加到students DataFrame。
- #

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解
【T-Box能源管理】:智能化节电解决方案详解
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略
Cygwin系统监控指南:性能监控与资源管理的7大要点
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南
【精准测试】:确保分层数据流图准确性的完整测试方法


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















