【Pandas DataFrame实战】:案例分析与求和技巧
发布时间: 2024-12-16 09:52:00 阅读量: 3 订阅数: 4 

Pandas实战指南:数据分析的Python利器
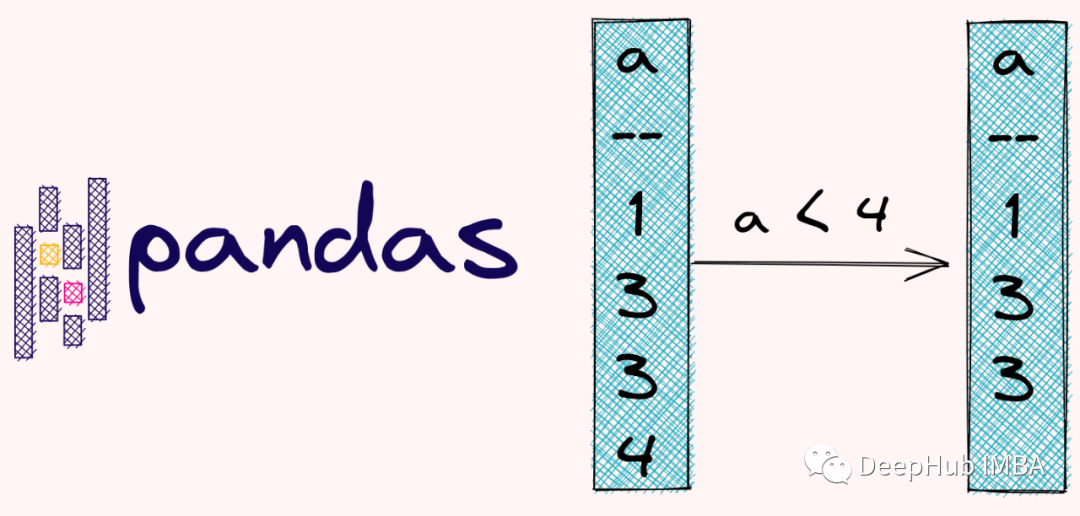
参考资源链接:[python中pandas.DataFrame对行与列求和及添加新行与列示例](https://wenku.csdn.net/doc/cyhdalx4m0?spm=1055.2635.3001.10343)
# 1. Pandas DataFrame入门基础
在当今的数据科学领域,Pandas库成为了数据处理的利器,尤其是其核心数据结构DataFrame。DataFrame是一个二维标签化数据结构,具有高度的灵活性,支持各种类型的数据操作。它能够处理结构化数据,使数据分析变得更加简单高效。
## 1.1 DataFrame的创建与初始化
首先,需要导入Pandas库,并创建一个简单的DataFrame实例。可以通过字典和列表来初始化DataFrame,这样可以模拟出具有行标签和列标签的表格数据。例如:
```python
import pandas as pd
data = {'Name': ['John', 'Anna'], 'Age': [28, 22]}
df = pd.DataFrame(data)
```
## 1.2 DataFrame的基本操作
创建好DataFrame后,我们可以进行一系列基本操作,如查看数据维度、数据类型、统计信息、对数据进行排序和访问等。下面的代码展示了如何查看DataFrame的基本信息:
```python
print(df.head()) # 查看前5行数据
print(df.describe()) # 获取数据的统计摘要
```
通过这些操作,我们可以快速对数据集的结构和内容有一个初步的了解。在此基础上,进一步深入学习Pandas的高级功能将为数据处理和分析工作带来极大的便利。
# 2. 数据处理技巧与实战案例
## 2.1 数据筛选与清洗
数据筛选与清洗是数据处理中至关重要的一步。它涉及到使用条件筛选数据,以及对缺失数据的处理策略。良好的数据筛选与清洗可以减少后续分析的错误和偏差,提高数据处理的效率和准确性。
### 2.1.1 使用条件筛选数据
在Pandas中,我们可以使用布尔索引来筛选数据。布尔索引是一种非常强大的数据筛选方法,它允许我们使用条件表达式来选择满足特定条件的行或列。例如,如果我们要筛选出DataFrame中所有年龄大于30的记录,可以使用以下代码:
```python
import pandas as pd
# 假设df是我们的DataFrame,且包含一个名为'age'的列
filtered_data = df[df['age'] > 30]
```
### 2.1.2 缺失数据处理策略
在实际的数据集中,缺失值是经常遇到的问题。Pandas提供了多种处理缺失数据的方法,其中包括删除含有缺失值的行或列,以及用特定的值或统计方法填充缺失值。例如,我们可以用均值填充缺失值:
```python
df['age'].fillna(df['age'].mean(), inplace=True)
```
## 2.2 数据聚合与分析
数据聚合与分析是将数据分组,并对各组数据应用统计函数的过程。这一阶段可以揭示数据集中的模式和趋势。
### 2.2.1 分组与聚合操作
分组与聚合是通过`groupby`方法实现的。我们可以按照一个或多个列进行分组,并对每个组应用聚合函数,如求和、平均、计数等。例如,我们可以计算不同类别商品的平均销售额:
```python
grouped_data = df.groupby('category')['sales'].mean()
```
### 2.2.2 数据统计分析方法
除了基本的聚合函数,Pandas还提供了一系列的统计分析方法,比如描述性统计、相关性分析、交叉表等。这些方法可以让我们深入理解数据集的特征。描述性统计可以通过`describe`方法轻松获得:
```python
statistics = df.describe()
```
## 2.3 数据可视化基础
数据可视化是将数据转换为图表和图形的过程,这有助于我们更快地理解和解释数据集。
### 2.3.1 常用数据可视化类型
在Pandas中,我们可以使用内置的绘图功能或者结合Matplotlib库来创建数据可视化。常用的可视化类型包括条形图、折线图、散点图、直方图等。例如,我们可以使用`plot`方法来绘制一个简单的折线图:
```python
df['sales'].plot(kind='line')
```
### 2.3.2 Pandas与Matplotlib的数据绘图
Matplotlib是Python中最常用的绘图库之一,与Pandas结合可以创建更复杂和定制化的图表。例如,我们可以绘制一个散点图来表示两个变量之间的关系:
```python
import matplotlib.pyplot as plt
df.plot(kind='scatter', x='x_column', y='y_column')
plt.show()
```
通过本章节的介绍,我们可以了解到如何在Pandas中进行数据的筛选与清洗,以及数据的聚合与分析,还有数据可视化的基本方法。这些知识和技巧为我们提供了深入理解和分析数据的能力,是进行数据分析不可或缺的步骤。
# 3. DataFrame求和技巧深度剖析
在Pandas库中,DataFrame是一种二维的、大小可变的、潜在异质型的表格型数据结构,带有一组标签的轴(行和列)。求和是数据分析中常见的操作,可以对列(axis=0)或行(axis=1)进行,或者按照其他轴进行更复杂的分组聚合操作。本章节将深入探讨DataFrame的求和技术,以及如何优化求和操作的性能和结果。
## 3.1 基本求和方法
### 3.1.1 axis参数的使用
在Pandas中,`axis`参数是控制函数在哪个轴上操作的重要参数。当进行求和操作时,我们可以指定`axis=0`表示按列求和,`axis=1`表示按行求和。如果不指定`axis`参数,则默认按列求和。
```python
import pandas as pd
# 创建示例DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# 按列求和
column_sum = df.sum(axis=0)
# 按行求和
row_sum = df.sum(axis=1)
print("按列求和结果:\n", column_sum)
print("按行求和结果:\n", row_sum)
```
在这个例子中,`column_sum`将得到每列的和,而`row_sum`将得到每行的和。
### 3.1.2 使用groupby进行复杂求和
当需要对数据分组求和时,`groupby`方法提供了一种灵活而强大的方式。我们可以通过某一个或多个列来对数据进行分组,并对每个组进行求和操作。
```python
# 假设我们有一个包含类别的DataFrame
df = pd.DataFrame({
'Category': ['A', 'B', 'A', 'C', 'B', 'A'],
'Data': [10, 20, 10, 30, 40, 50]
})
# 按照'Category'列进行分组求和
grouped_sum = df.groupby('Category')['Data'].sum()
print("分组求和结果:\n", grouped_sum)
```
在这个例子中,我们将数据按照'Category'列的不同值分成了几个组,并计算了每个组中'Data'列的和。
## 3.2 高级求和技术
### 3.2.1 条件求和技巧
在很多情况下,我们可能只希望对满足特定条件的数据进行求和。Pandas提供了一个非常灵活的条件表达式系统,可以帮助我们实现这一点。
```python
# 仅对满足'Data'大于20的行进行求和
conditional_sum = df[df['Data'] > 20]['Data'].sum()
print("条件求和结果:", conditional_sum)
```
### 3.2.2 多条件求和实例
当我们需要根据多个条件进行求和时,可以使用逻辑运算符将这些条件组合起来。
```python
# 按照'Category'分组,并且只对'Data'大于20的行进行求和
grouped_multi_conditional_sum = df.groupby('Category').apply(
lambda x: x[x['Data'] > 20]['Data'].sum()
)
print("多条件分组求和结果:\n", grouped_multi_conditional_sum)
```
## 3.3 求和结果的优化处理
### 3.3.1 优化求和结果的存储
在处理大型数据集时,求和操作可能会生成大型的结果对象。优化这些对象的存储可以节省内存和提高性能。
```python
# 将求和结果转换为NumPy数组,以节省内存
column_sum_array = df.sum(axis=0).to_numpy()
print("转换为NumPy数组的求和结果:\n", column_sum_array)
```
### 3.3.2 大数据环境下的求和优化
在大数据环境下,数据往往不能完全加载到内存中。在这些情况下,使用`dask.dataframe`可以进行分布式求和。
```python
import dask.dataframe as dd
# 读取大型CSV文件作为Dask DataFrame
dask_df = dd.read_csv('large_dataset.csv')
# 对Dask DataFrame进行求和操作
dask_sum = dask_df.sum()
print("Dask DataFrame的求和结果:\n
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中 pandas.DataFrame 的行与列求和及数据扩展操作。从基础的行列求和到进阶的新列添加,再到高级的动态行添加,专栏全面覆盖了 DataFrame 的求和和数据扩展功能。通过深入理解 DataFrame 结构和高效策略,读者可以掌握在数据分析中有效处理和操作数据的技巧。专栏还提供了实战案例和数据处理技巧,帮助读者将理论知识应用于实际场景。无论是数据分析新手还是经验丰富的从业者,本专栏都提供了宝贵的见解和实用指南,帮助读者充分利用 pandas.DataFrame 的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【弹塑性材料模型新手指南】:5大基础概念和6大应用案例解密

参考资源链接:[ANSYS/LS-DYNA 弹塑性材料模型详解](https://wenku.csdn.net/doc/4nws5pf579?spm=1055.2635.3001.10343)
# 1. 弹塑性材料模型概述
在工程实践中
内存故障诊断宝典:DDR4笔记本内存条常见问题与解决方案
参考资源链接:[DDR4笔记本内存条jedec标准设计规范](https://wenku.csdn.net/doc/2o4prfgnp8?spm=1055.2635.3001.10343)
# 1. DDR4笔记本内存条概述
DDR4作为第四代双倍数据速率同步动态随机存取存储器,是目前笔记本电脑中常见的内存类型。相较于前代DDR3,DDR4内存条在速度
WT230-U 数据手册故障排除:硬件问题快速诊断与解决的黄金法则
参考资源链接:[恒玄WT230-U:高性能蓝牙5.0音频平台规格书](https://wenku.csdn.net/doc/6460a81a5928463033af4768?spm=1055.2635.3001.10343)
# 1. WT230-U数据手册概述
WT230-U作为一款广泛应用的工业级数据采集装置,拥有
【WPS-Excel函数使用大全】:掌握这20个常用函数,工作效率翻倍
参考资源链接:[WPS表格+JS宏编程实战教程:从入门到精通](https://wenku.csdn.net/doc/27j8j6abc6?spm=1055.2635.3001.10343)
# 1. WPS-Excel函数使用概览
在现代办公自动化中,WPS-Excel作为一个功能强大的电子表格软件,其内置的函数系统为数据处理提供了极
【TJA1050数据手册】:工程师必备的核心特性与技术要点解析

参考资源链接:[TJA1050 CAN总线控制器详细应用与特性介绍](https://wenku.csdn.net/doc/646b40f6543f844488c9cad1?spm=1055.2635.3001.10343)
# 1. TJA1050芯片概述
## 1.1 芯片简
【TFC系统安装指南】:一步到位的安装、故障排除与优化技巧

参考资源链接:[TFCalc优化指南:打造最佳膜系设计](https://wenku.csdn.net/doc/4projjd9br?spm=1055.2635.3001.10343)
# 1. TFC系统的介绍与安装基础
## 简介
TFC系统(Total Flow Control)是一种先进的系统管理工具,它集成了工作流管理、资源
【兼容性革命】:轻松应对ATA8-ACS的兼容性挑战
参考资源链接:[2016年ATA8-ACS标准:ACS-4草案——信息存储技术指南](https://wenku.csdn.net/doc/4qi00av1o9?spm=1055.2635.3001.10343)
# 1. ATA8-ACS技术概述
## 1.1 ATA8-ACS技术简介
ATA8-ACS(Advanced Technology Attachment
ACS800变频器全面优化指南:提升性能与寿命的20个秘技

参考资源链接:[ABB ACS800变频器用户手册:参数设置与控制操作指南](https://wenku.csdn.net/doc/z83fd7rcv0?spm=1055.2635.3001.10343)
# 1. ACS800变频器基础知识概述
ACS800变频器是ABB公司的一款高性能电机控制设备,广泛应用于工业自动化领域。它不仅能够
图像评价技术深度探讨:如何在实际项目中应用UCIQE和UICM

参考资源链接:[水下图像质量评估:UCIQE、UIQM与关键指标解析](https://wenku.csdn.net/doc/36v1jj2vck?spm=1055.2635.3001.10343)
# 1. 图像评价技术的理论基础
在数字图像处理领域,图像评价技术是衡量图像质量和处理效果的基石。本章将探讨图像评价技术的基础理论,为后续章节中对UCIQE和UICM评价指标的深入解析打下坚实的基础。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )