CloudFront的基本概念与原理解析
发布时间: 2023-12-23 21:14:12 阅读量: 10330 订阅数: 315 
# 1. 什么是CloudFront
CloudFront是亚马逊网络服务(AWS)提供的一项全球内容分发网络(CDN)服务。它通过在全球各地部署分布式边缘节点,将静态内容、视频、应用程序和其他文件高效地分发给用户,从而提供低延迟和高可用性的内容分发。
## AWS的CDN服务架构和功能
在深入了解CloudFront之前,我们先来了解AWS的CDN服务架构和功能。AWS的CDN服务是以全球部署的边缘位置(Edge Location)为基础的。这些边缘位置位于世界各地,包括北美、南美、欧洲、亚洲和澳大利亚等地区。
AWS的CDN服务架构中包含以下组件:
1. 边缘节点(Edge Location):位于全球各地的边缘位置,用于缓存和传送内容给最终用户。
2. 源站(Origin):存储原始内容的源站,可以是AWS的各种存储服务(例如S3存储桶),也可以是自定义的HTTP服务器。
3. 分发(Distribution):通过配置将源站上的内容分发给边缘节点,以便用户可以从最近的边缘节点获取内容。
## CloudFront与传统CDN的区别与优势
相比传统的CDN服务,CloudFront具有以下几个重要的区别和优势:
1. 高度分布式:CloudFront全球范围内部署了大量的边缘节点,可以更接近用户,提供更低的延迟和更快的速度。
2. 弹性可伸缩:CloudFront可以根据实际的流量需求自动扩展,并且可以方便地与其他AWS服务集成,如Amazon S3、Amazon EC2等。
3. 多种内容传输方式:CloudFront支持静态和动态内容的传输,并且可以通过配置多种选项来优化内容传输。
4. 安全可靠:CloudFront提供多层次的安全机制,包括SSL/TLS加密、防跨站脚本攻击(XSS)等,保障用户和内容的安全。
通过以上介绍,我们对CloudFront有了初步的了解。接下来,我们将深入探讨CloudFront的架构和基本工作原理。
希望这篇章节符合你的要求。接下来,我会继续完成其他章节的内容。如果有需要进行进一步编写,请告诉我。
# 2. CloudFront的架构和组件
CloudFront的基本架构和组件概述
CloudFront是AWS提供的一种全球分布式CDN(内容分发网络)服务。它通过将内容缓存到离用户更近的边缘节点上,提供更快的访问速度和更低的延迟。CloudFront的基本架构由以下几个组件组成:
- Edge Location(边缘节点):分布在全球各地的数据中心,用于缓存和分发内容。每个边缘节点都有多个网络链接,可以与多个传输网络(ISP)连接。
- Origin(源站):存储原始内容的服务器,可以是AWS S3存储桶、Elastic Load Balancer、EC2实例或其他HTTP服务器。当边缘节点无法满足用户请求时,会向源站请求内容。
- Distribution(分发):指定Edge Location和源站之间的关联关系。每个分发都有唯一的DNS名称,用户通过该名称访问内容。
分布式边缘节点的功能与特点
CloudFront的边缘节点具有以下功能和特点:
1. 内容缓存:边缘节点会缓存从源站获取的内容,当用户请求相同资源时,会从最近的边缘节点中返回缓存的内容,从而提高访问速度。
2. 动态请求路由:边缘节点可以根据用户的地理位置和网络状况,自动选择最佳的边缘节点来处理用户的请求。
3. 内容分发:用户从就近的边缘节点获取内容,减少延迟和网络拥塞,提高用户体验。
4. 加密和安全性:边缘节点可以提供HTTPS协议的加密传输,保护数据安全。
5. 请求响应优化:边缘节点可以对请求进行压缩、缓存和处理,以提高响应速度和效率。
源站和Edge Location的关系与原理
CloudFront的源站是存储原始内容的服务器。当用户请求内容时,边缘节点首先检查是否在其缓存中是否有该资源的副本。如果有,边缘节点会直接返回缓存的内容,从而提高响应速度。如果没有,边缘节点会向源站请求内容,并将内容缓存到本地。
源站和Edge Location之间的关系遵循最近邻原则,即边缘节点会选择离用户最近的源站来获取内容。这样可以减少请求的延迟,并提高访问速度。边缘节点和源站之间的通信通常使用HTTP或HTTPS协议进行。
当源站更新内容时,边缘节点会根据缓存策略的设置来判断是否需要更新缓存的内容。可以通过配置缓存时间、版本号等参数来控制缓存的策略。
以上是CloudFront的架构和组件相关的介绍,下一章将详细解析CloudFront的基本工作原理。
如果需要进一步了解CloudFront的架构和组件,可以参考以下代码示例:
```python
# Python代码示例
import boto3
def create_cloudfront_distribution():
cloudfront = boto3.client('cloudfront')
distribution_config = {
'Comment': 'My CloudFront Distribution',
'Origins': {
'Items': [
{
'Id': 'my-origin',
'DomainName': 'example.com',
'OriginPath': '/path',
'CustomOriginConfig': {
'HTTPPort': 80,
'HTTPSPort': 443,
'OriginProtocolPolicy': 'http-only',
'OriginSslProtocols': {
'Quantity': 1,
'Items': ['TLSv1.2']
}
}
}
],
'Quantity': 1
},
'DefaultCacheBehavior': {
'TargetOriginId': 'my-origin',
'ViewerProtocolPolicy': 'allow-all',
'AllowedMethods': {
'Quantity': 3,
'Items': ['GET', 'HEAD', 'OPTIONS']
},
'ForwardedValues': {
'QueryString': False,
'Cookies': {'Forward': 'none'}
}
},
'DefaultRootObject': 'index.html',
'PriceClass': 'PriceClass_All',
'Enabled': True,
'WebACLId': 'my-web-acl',
}
response = cloudfront.create_distribution(DistributionConfig=distribution_config)
return response['Distribution']
distribution = create_cloudfront_distribution()
print(distribution)
```
这个示例代码演示了如何使用Python SDK(boto3)来创建一个CloudFront分发。可以根据实际需求,调整相关参数,来配置CloudFront的分发设置。
以上是第二章内容的核心要点,希望对你有帮助。如果需要继续了解CloudFront的基本工作原理,请阅读下一章节的内容。
# 3. CloudFront的基本工作原理
CloudFront是AWS提供的内容分发网络(CDN)服务,其基本工作原理涉及缓存与分发的基本原理、Origin服务器与Edge服务器的交互流程以及请求处理和内容分发的流程解析。在本章节中,我们将详细解析CloudFront的基本工作原理,包括相关的技术原理和交互流程。
## 缓存与分发的基本原理
CloudFront通过将全球范围内的内容分发到位于不同地理位置的Edge Location节点,实现用户访问加速和降低源站压力的目的。其中,缓存是CloudFront实现内容加速和分发的关键。当用户请求访问特定内容时,CloudFront会首先检查Edge Location节点上是否存在该内容的缓存副本。如果存在,则直接将该内容返回给用户,从而加快访问速度;如果不存在,则会向源站请求该内容,并在Edge Location节点进行缓存,以便下次用户请求时能够加速响应。
## Origin服务器与Edge服务器的交互流程
在CloudFront中,Origin服务器指的是存储原始内容的源站,可以是Amazon S3存储桶、自定义源站或其他AWS服务。当Edge Location节点上未命中缓存时,会向指定的Origin服务器请求内容。Origin服务器将响应内容返回给Edge Location节点,节点再将内容缓存并返回给用户。这个交互流程中,CloudFront使用多种技术手段来加速内容传输和优化数据传输,以提高用户体验和性能。
## 请求处理和内容分发的流程解析
CloudFront的请求处理和内容分发流程非常复杂,涉及到内容路由、访问控制、数据压缩、SSL协议处理等多个环节。当用户发起请求时,请求会经过一系列流程,包括DNS解析、内容路由、缓存命中、数据传输等环节,最终将内容返回给用户。在这个过程中,CloudFront的各个组件和功能起到关键作用,保证了内容的高可用性和快速响应。
以上是关于CloudFront基本工作原理的详细解析,包括缓存与分发的原理、Origin服务器与Edge服务器的交互流程以及请求处理和内容分发的流程解析。在后续章节中,我们将深入探讨CloudFront的高可用性、性能优化和安全机制。
# 4. CloudFront的高可用性与性能优化
在本章中,我们将详细探讨CloudFront的高可用性与性能优化方面的内容。我们将深入了解CloudFront的负载均衡策略和故障转移机制,以及加速内容传输与数据压缩的技术手段。同时,我们也会对CloudFront的性能优化与数据传输加速原理进行分析和讨论。
## CloudFront的负载均衡策略和故障转移机制
CloudFront作为一个全球分布式的内容分发网络,通过多节点分布式架构来保证负载均衡和故障转移。它采用智能DNS来根据用户的地理位置,将请求路由到最近的可用边缘节点,从而提供更快的响应时间和更高的可用性。
在故障转移方面,CloudFront通过实时监控各个边缘节点的健康状态,并在节点发生故障时自动将流量转移到其他健康的节点,从而实现故障转移和负载均衡。
## 加速内容传输与数据压缩的技术手段
为了加速内容传输,CloudFront采用了多种技术手段。其中包括:
- **内容预取和预加载**:CloudFront能够根据用户的请求行为,提前将内容缓存到边缘节点,从而加速内容传输。
- **分段传输技术**:针对大文件或流媒体内容,CloudFront可以实现分段传输,提高传输效率。
- **数据压缩**:CloudFront支持对传输的内容进行压缩,减少传输数据量,从而加速内容传输。
## CloudFront的性能优化与数据传输加速原理
CloudFront在性能优化方面主要包括以下几个方面:
- **智能调度和路由**:根据用户地理位置和网络条件,选择最佳的边缘节点进行内容传输,以提高传输速度和性能。
- **本地缓存与持久连接**:CloudFront利用本地边缘节点的缓存和持久连接,减少对源站的请求次数,提高内容传输效率。
- **动态内容加速**:CloudFront支持对动态内容的加速传输,通过灵活的配置策略,提高动态内容的传输效率。
通过上述技术手段和性能优化策略,CloudFront能够有效地提高内容传输的速度和性能,满足不同场景下的需求。
以上是 CloudFront的高可用性与性能优化的基本原理和技术手段,它们为互联网业务的高效运行和用户体验提供了重要的支撑。在实际应用中,针对具体的业务需求和场景特点,可以选择合适的性能优化策略,以达到最佳的效果。
# 5. CloudFront的安全性与访问控制
CloudFront作为AWS的CDN服务,提供了多种安全机制和防护措施,确保分发内容的安全性和可靠性。本章将介绍CloudFront的安全性能,并讨论如何使用CloudFront提供多层访问控制的方案。
### CloudFront的安全机制与防护措施
CloudFront通过以下几种方法保障分发内容的安全:
1. **SSL/TLS加密**:CloudFront支持使用HTTPS协议进行内容分发,通过SSL/TLS加密保障数据传输过程的安全性。
2. **Access Control Lists (ACL)**:ACL允许您根据需要控制对分发内容的访问权限。可以通过ACL设置IP地址、网络、Geolocation等限制条件,限制特定用户或地区的访问。
3. **AWS Web Application Firewall (WAF)**:WAF是一项Web应用防火墙服务,可以与CloudFront集成使用,提供对Web应用程序的防护。WAF可以根据预定义规则或自定义规则,阻止来自恶意请求的访问。
4. **AWS Shield**:Shield是AWS的DDoS保护服务,可提供在多种层次上保护CloudFront分发的资源免受DDoS攻击。
### 使用CloudFront提供多层访问控制的方案
CloudFront提供了多种方法来控制用户对内容的访问权限,可以根据实际需求选择合适的方式:
1. **Origin Access Identity (OAI)**:OAI是用于与CloudFront关联的S3存储桶或自定义Origin服务器之间进行身份验证的机制。可以为CloudFront分配一个特定的OAI,并授予其访问目标Origin的权限,从而限制只有通过CloudFront访问的请求才能正常获取内容。
2. **Signed URLs/Cookies**:使用Signed URLs或Signed Cookies可以为特定的资源生成带有时间限制和访问权限的URL或Cookie。只有具有有效签名的URL或Cookie才能访问资源,从而提供更严格的访问控制。
3. **AWS Identity and Access Management (IAM)**:通过与IAM集成,可以控制对CloudFront的管理权限,并基于IAM策略为用户和角色分配特定的CloudFront操作权限。
4. **AWS S3 Bucket Policies**:可以使用S3 Bucket Policies为CloudFront分发的S3存储桶设置更严格的访问控制规则,从而限制特定的用户或角色对存储桶中的对象的访问权限。
### 防止DDoS攻击和安全漏洞的防范措施
为了保护CloudFront分发的内容免受DDoS攻击和其他安全漏洞的影响,可以采取以下措施:
1. **使用AWS Shield**:启用AWS Shield可以为CloudFront提供DDoS保护,防止来自网络、传输和应用层的DDoS攻击。
2. **使用WAF防护**:通过与AWS WAF集成,可以定义和实施规则,以防止恶意请求和安全漏洞对Web应用程序和CloudFront分发的资源造成损害。
3. **定期进行安全审计**:定期审核和更新CloudFront分发的安全设置,并进行漏洞扫描和安全测试,以确保安全性。
通过使用CloudFront的安全机制、访问控制和防护措施,您可以确保您的分发内容在传输和访问过程中的安全性,并抵御各种网络攻击和威胁。
希望本章内容对您理解CloudFront的安全性和访问控制有所帮助。下一章我们将探讨CloudFront的应用场景和最佳实践。
请注意,以上内容仅为示例,详细的代码实现可能需要参考AWS官方文档和相关示例。
# 6. 我会按照Markdown格式输出文章的第六章节内容,请稍等片刻。
## 第六章:CloudFront的应用场景与最佳实践
在本章中,我们将探讨一些CloudFront的实际应用场景和最佳实践,帮助读者更好地了解如何在实际项目中使用CloudFront来提升性能和用户体验。
### 互联网业务应用CDN的实际案例
互联网业务应用通常需要将内容快速传送给用户,以提供更好的用户体验。CDN作为分发内容的关键组件,可以帮助我们实现快速的内容分发和加速。下面是一个互联网业务应用CDN的实际案例:
```python
from flask import Flask
from flask_cdn import CDN
app = Flask(__name__)
CDN(app)
@app.route("/")
def index():
return "Welcome to my website!"
if __name__ == "__main__":
app.run()
```
上面的代码使用了Flask框架和flask_cdn扩展库,通过CDN扩展将静态资源(图片、CSS、JS等)分发到CloudFront的边缘节点上。这样,当用户访问网站时,静态资源可以从离用户较近的边缘节点获取,加速网页加载速度。
### Web应用页面加速和静态资源分发的最佳实践
为了实现Web应用的页面加速和静态资源分发,我们可以采取一些最佳实践:
1. 静态资源文件的缓存:在静态资源的响应头中设置合适的Cache-Control和Expires字段,让浏览器缓存这些静态资源,减少对源站的请求,提升页面加载速度。
2. 图片优化:将图片进行压缩和缩放,减小图片的文件大小,提高图片的加载速度。
3. 懒加载:延迟加载页面上的某些元素,例如图片、视频等,当用户滚动到可见区域时再进行加载,减少首屏加载的时间,提升用户体验。
```java
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.servlet.ModelAndView;
@Controller
public class HomeController {
@GetMapping("/")
public ModelAndView home() {
ModelAndView modelAndView = new ModelAndView("home");
// 设置静态资源的缓存
modelAndView.addObject("cacheControl", "public, max-age=3600");
modelAndView.addObject("expires", "Sat, 01 Jan 2022 00:00:00 GMT");
return modelAndView;
}
}
```
上述示例代码是使用Spring MVC框架的一个HomeController,通过设置响应头中的Cache-Control和Expires字段,来实现静态资源的缓存。这样,静态资源文件将被缓存在用户的浏览器中,提升页面的加载速度。
### 全球多地域内容分发的实施方案和经验分享
要实现全球多地域内容分发,我们可以考虑以下方案和经验:
1. 使用CloudFront的分布式边缘节点:CloudFront具有全球各地的边缘节点,可以将内容缓存到离用户较近的边缘节点上,提高用户访问速度。
2. 配置多个源站:我们可以针对不同地区的用户,配置不同的源站,然后使用CloudFront的分布式路由功能,将用户请求转发到最近的源站,提供更快的响应速度。
3. 使用GeoDNS技术:通过将DNS解析与内容分发相结合,可以根据用户的地理位置,将用户请求解析到最近的边缘节点,提高内容的响应速度和用户体验。
这些方案和经验可以帮助我们在实施全球多地域内容分发时,提升性能和用户体验。
希望这些示例和经验可以让读者更好地了解如何应用CloudFront的功能来解决实际问题,实现更好的性能和用户体验。
这是第六章的内容,涉及了互联网业务应用CDN的案例、Web应用页面加速和静态资源分发的最佳实践,以及全球多地域内容分发的实施方案和经验分享。如果有进一步的问题或需求,请随时告诉我。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"cloudfront"为主题,深入探讨了AWS CloudFront服务的各个方面。涵盖了从入门指南到高级应用的广泛内容,包括CloudFront的基本概念与原理解析、静态网站加速、动态内容传输效率提高、安全防护功能和最佳实践、与Lambda@Edge的集成应用、定制域名与HTTPS配置、缓存策略与性能优化、与S3的高效集成、Geo Restriction配置与优化、与API Gateway的集成与优化、日志与监控报警管理、与WAF的集成以及Web应用安全防护等多个方面的内容。此外,还涵盖了Lambda@Edge中间件开发与应用、IP黑名单和白名单设置、与RDS数据库的结合应用、构建弹性高效的云端应用、费用优化与成本控制等内容,最后以CloudFront与Route 53的最佳实践作为总结。适合AWS CloudFront用户及相关应用开发者参考,是一份全面系统的专栏资源。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
大规模深度学习系统:Dropout的实施与优化策略
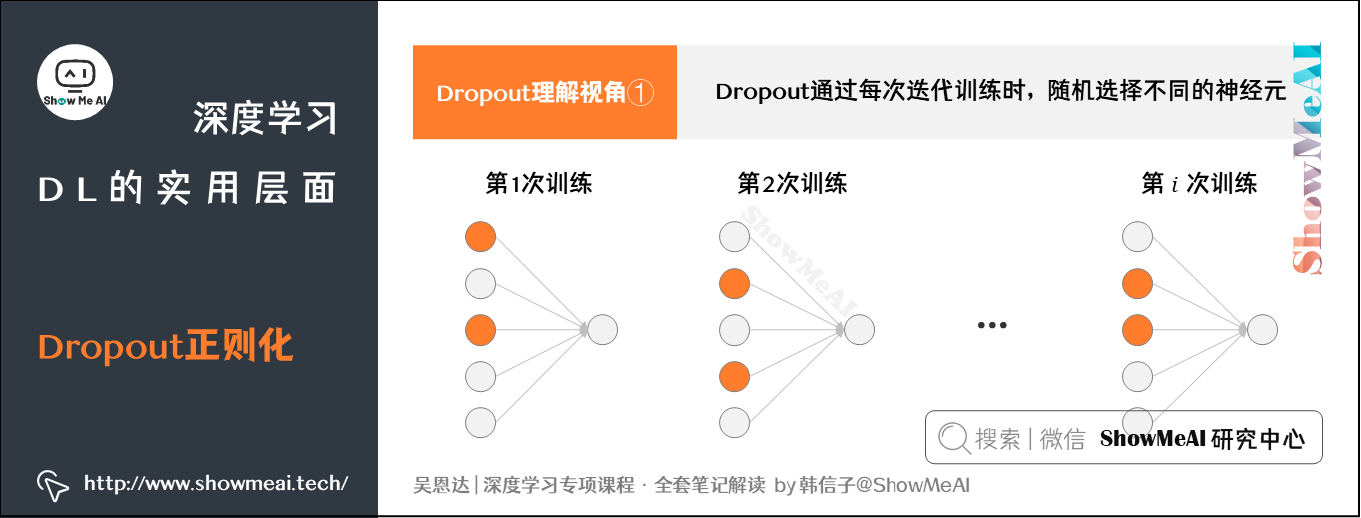
# 1. 深度学习与Dropout概述
在当前的深度学习领域中,Dropout技术以其简单而强大的能力防止神经网络的过拟合而著称。本章旨在为读者提供Dropout技术的初步了解,并概述其在深度学习中的重要性。我们将从两个方面进行探讨:
首先,将介绍深度学习的基本概念,明确其在人工智能中的地位。深度学习是模仿人脑处理信息的机制,通过构建多层的人工神经网络来学习数据的高层次特征,它已
推荐系统中的L2正则化:案例与实践深度解析
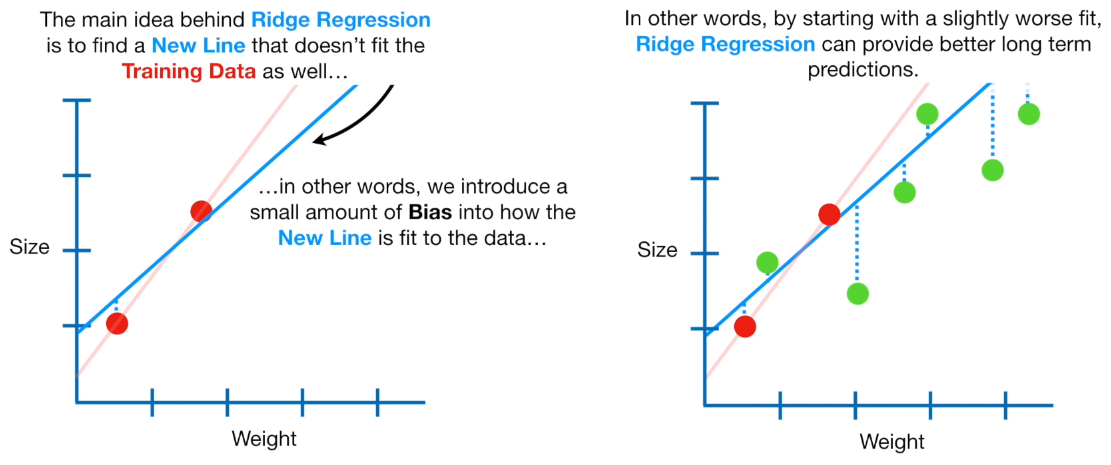
# 1. L2正则化的理论基础
在机器学习与深度学习模型中,正则化技术是避免过拟合、提升泛化能力的重要手段。L2正则化,也称为岭回归(Ridge Regression)或权重衰减(Weight Decay),是正则化技术中最常用的方法之一。其基本原理是在损失函数中引入一个附加项,通常为模型权重的平方和乘以一个正则化系数λ(lambda)。这个附加项对大权重进行惩罚,促使模型在训练过程中减小权重值,从而达到平滑模型的目的。L2正则化能够有效地限制模型复
预测建模精准度提升:贝叶斯优化的应用技巧与案例

# 1. 贝叶斯优化概述
贝叶斯优化是一种强大的全局优化策略,用于在黑盒参数空间中寻找最优解。它基于贝叶斯推理,通过建立一个目标函数的代理模型来预测目标函数的性能,并据此选择新的参数配置进行评估。本章将简要介绍贝叶斯优化的基本概念、工作流程以及其在现实世界
机器学习中的变量转换:改善数据分布与模型性能,实用指南
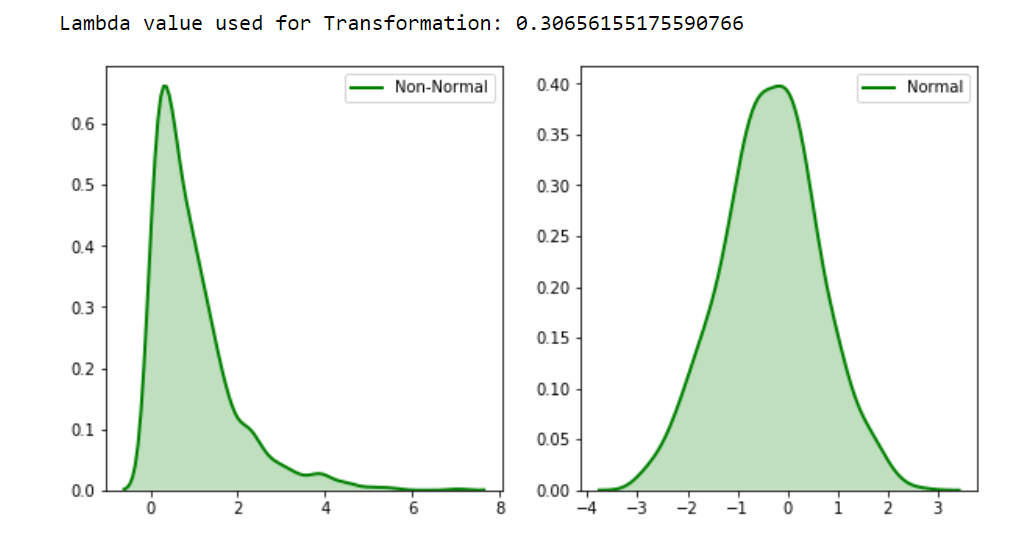
# 1. 机器学习与变量转换概述
## 1.1 机器学习的变量转换必要性
在机器学习领域,变量转换是优化数据以提升模型性能的关键步骤。它涉及将原始数据转换成更适合算法处理的形式,以增强模型的预测能力和稳定性。通过这种方式,可以克服数据的某些缺陷,比如非线性关系、不均匀分布、不同量纲和尺度的特征,以及处理缺失值和异常值等问题。
## 1.2 变量转换在数据预处理中的作用
图像处理中的正则化应用:过拟合预防与泛化能力提升策略

# 1. 图像处理与正则化概念解析
在现代图像处理技术中,正则化作为一种核心的数学工具,对图像的解析、去噪、增强以及分割等操作起着至关重要
自然语言处理中的过拟合与欠拟合:特殊问题的深度解读
# 1. 自然语言处理中的过拟合与欠拟合现象
在自然语言处理(NLP)中,过拟合和欠拟合是模型训练过程中经常遇到的两个问题。过拟合是指模型在训练数据上表现良好
【过拟合克星】:网格搜索提升模型泛化能力的秘诀

# 1. 网格搜索在机器学习中的作用
在机器学习领域,模型的选择和参数调整是优化性能的关键步骤。网格搜索作为一种广泛使用的参数优化方法,能够帮助数据科学家系统地探索参数空间,从而找到最佳的模型配置。
## 1.1 网格搜索的优势
网格搜索通过遍历定义的参数网格,可以全面评估参数组合对模型性能的影响。它简单直观,易于实现,并且能够生成可重复的实验结果。尽管它在某些
【Lasso回归与岭回归的集成策略】:提升模型性能的组合方案(集成技术+效果评估)
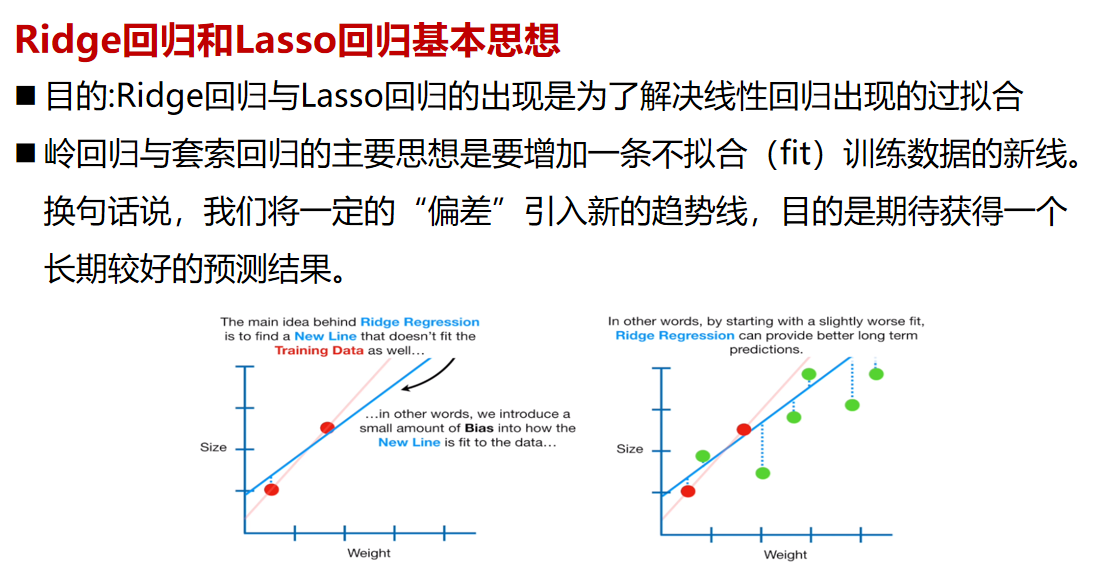
# 1. Lasso回归与岭回归基础
## 1.1 回归分析简介
回归分析是统计学中用来预测或分析变量之间关系的方法,广泛应用于数据挖掘和机器学习领域。在多元线性回归中,数据点拟合到一条线上以预测目标值。这种方法在有多个解释变量时可能会遇到多重共线性的问题,导致模型解释能力下降和过度拟合。
## 1.2 Lasso回归与岭回归的定义
Lasso(Least
随机搜索在强化学习算法中的应用

# 1. 强化学习算法基础
强化学习是一种机器学习方法,侧重于如何基于环境做出决策以最大化某种累积奖励。本章节将为读者提供强化学习算法的基础知识,为后续章节中随机搜索与强化学习结合的深入探讨打下理论基础。
## 1.1 强化学习的概念和框架
强化学习涉及智能体(Agent)与环境(Environment)之间的交互。智能体通过执行动作(Action)影响环境,并根据环境的反馈获得奖
机器学习调试实战:分析并优化模型性能的偏差与方差
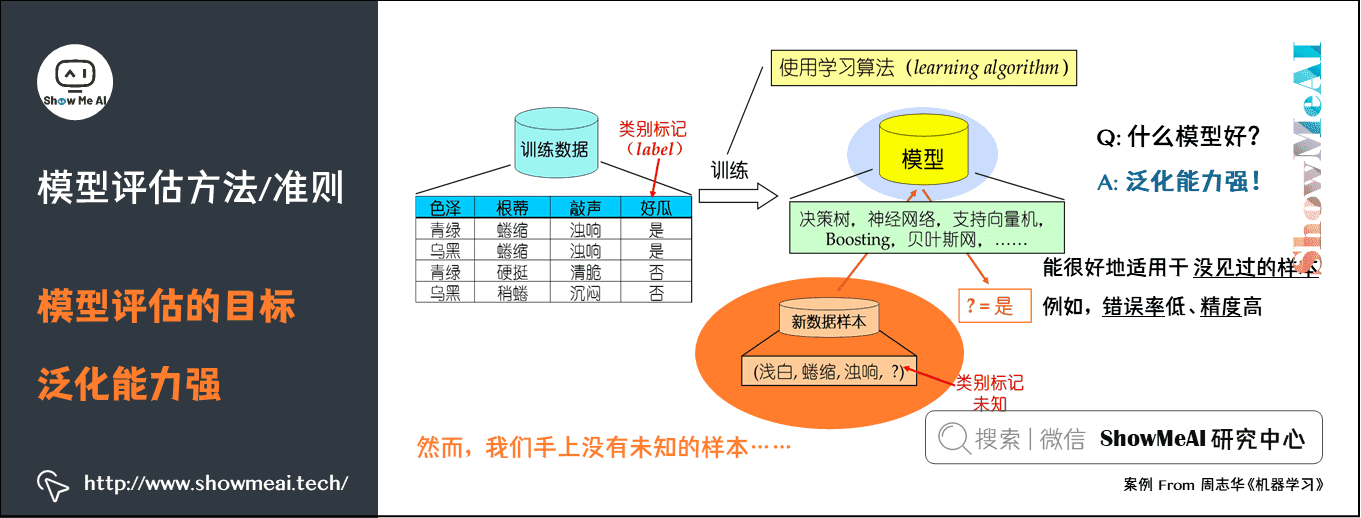
# 1. 机器学习调试的概念和重要性
## 什么是机器学习调试
机器学习调试是指在开发机器学习模型的过程中,通过识别和解决模型性能不佳的问题来改善模型预测准确性的过程。它是模型训练不可或缺的环节,涵盖了从数据预处理到最终模型部署的每一个步骤。
## 调试的重要性
有效的调试能够显著提高模型的泛化能力,即在未见过的数据上也能作出准确预测的能力。没有经过适当调试的模型可能无法应对实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )