GSolver软件进阶秘籍:揭秘性能优化与高级应用的6大技巧
发布时间: 2024-12-27 20:44:55 阅读量: 5 订阅数: 5 

GSolver光栅软件
# 摘要
GSolver是一款专业软件,本文从基础操作、性能优化、高级编程、系统集成、实际应用案例五个方面进行深入介绍。首先,概述GSolver的基础操作和性能优化技巧,包括性能瓶颈的识别和代码级性能提升策略。接着,探讨了GSolver的高级编程技巧,重点在数据处理、算法实现和自定义扩展。第四部分,详述如何通过跨平台兼容性策略和系统集成优化提升软件的兼容性。最后,通过多个行业解决方案和成功案例分析,讨论了GSolver在不同环境下的应用,并提供了常见问题的解决策略。本文旨在为GSolver用户提供全面的技术支持和指导。
# 关键字
GSolver;性能优化;代码重构;资源管理;算法优化;系统兼容性
参考资源链接:[GSolver光栅设计软件用户手册](https://wenku.csdn.net/doc/6412b6d8be7fbd1778d482e9?spm=1055.2635.3001.10343)
# 1. GSolver软件简介与基础操作
## 简介
GSolver是一款先进的软件解决方案,专门针对复杂系统建模、仿真和优化问题设计。它集成了强大的算法库和灵活的用户界面,适用于科研、工程设计等多领域的需求。
## 安装与启动
要开始使用GSolver,首先需要在官方网站下载对应操作系统的安装包。安装完成后,双击桌面图标或通过命令行启动软件。GSolver会自动进行环境配置检查,确保软件可以顺利运行。
## 基础操作
GSolver的操作界面分为菜单栏、工具栏、工作区和状态栏。用户可以通过菜单栏选择项目、打开、保存工作,或进行系统设置。工具栏提供快速访问常用功能的途径,工作区是建模和仿真操作的主要区域,状态栏显示软件运行状态及提示信息。
通过以上步骤,即使是初学者也能快速上手GSolver,开始其在特定领域的探索之旅。接下来的章节会深入探讨如何进行性能优化、高级编程以及系统集成,让GSolver更好地服务于复杂的工程任务。
# 2. GSolver性能优化技巧
性能优化是每个软件开发周期中至关重要的一环,特别是在处理复杂计算和大数据量的应用时。GSolver作为一种强大的计算软件,其性能优化尤为重要。本章节将深入探讨如何识别GSolver的性能瓶颈,并进行代码级优化和资源管理。
## 2.1 识别性能瓶颈
性能瓶颈是指系统在运行时遇到的限制因素,导致运行效率降低。GSolver中性能瓶颈的识别通常涉及两个主要方面:使用性能监控工具和分析方法。
### 2.1.1 性能监控工具的使用
在GSolver中,性能监控工具有助于开发者实时了解软件运行状态,可以收集有关CPU使用率、内存消耗、磁盘I/O、网络活动等关键性能指标。常用的性能监控工具有System Monitor、htop、Perf等。
以System Monitor为例,我们可以监控GSolver的内存和CPU使用情况。在Linux系统中,可以通过以下命令启动System Monitor:
```bash
gnome-system-monitor
```
或者使用htop,它可以提供更直观的性能信息:
```bash
htop
```
在监控过程中,应着重观察GSolver在处理大型数据集或复杂计算时的性能变化,这样可以帮助我们快速定位可能出现瓶颈的地方。
### 2.1.2 瓶颈分析方法
瓶颈分析方法包括日志分析、性能测试、压力测试等。在进行瓶颈分析时,应该对GSolver的运行时数据进行记录,并根据记录数据来分析可能的问题。
压力测试是一个常用的技术,它可以通过模拟高负载环境来观察GSolver的反应。可以使用Apache JMeter这类工具来对GSolver进行压力测试。
```bash
# 使用JMeter进行压力测试的简化示例
jmeter -n -t <测试计划文件>.jmx -l <测试结果文件>.jtl
```
分析瓶颈时,关注的指标包括响应时间、事务吞吐量、错误率等。通过这些指标的变化,结合代码逻辑,可以逐步缩小瓶颈所在的范围,直至具体到某段代码或某个资源。
## 2.2 代码级性能优化
性能优化不仅需要系统层面的调整,更需要对代码进行细致的优化。
### 2.2.1 代码重构的原则
代码重构是改善代码质量、提高软件性能的常用手段。重构的原则主要包括:
- 保持代码的可读性和可维护性。
- 避免过早优化。
- 重构时应先编写测试用例,确保重构后的行为与预期一致。
重构时,可以利用GSolver提供的重构工具或集成开发环境(IDE)中的重构功能,比如IntelliJ IDEA或Eclipse。
### 2.2.2 常见性能提升方法
提升代码性能的方法多种多样,以下是一些常见的方法:
- **循环优化**:减少循环内的计算量,使用循环展开等技术。
- **算法替换**:使用时间复杂度更低的算法,比如从O(n^2)优化到O(nlogn)。
- **缓存利用**:通过缓存中间计算结果来减少重复计算。
- **并行计算**:在多核处理器上并行处理任务,提高效率。
例如,考虑以下代码段,该代码计算大数的阶乘,可以通过引入缓存机制来优化:
```python
def factorial(n):
cache = {}
if n == 0:
return 1
elif n in cache:
return cache[n]
else:
cache[n] = n * factorial(n-1)
return cache[n]
```
这里使用了Python字典作为缓存,缓存了已计算过的阶乘值,从而避免了不必要的递归调用。
## 2.3 资源管理和分配
资源管理是性能优化的另一个关键部分,合理的资源分配策略可以显著提升GSolver的性能。
### 2.3.1 资源优化策略
资源优化策略包括内存管理、处理器时间分配、IO资源使用等。对于内存管理,应该避免内存泄漏和过度使用内存。GSolver提供了内存分析工具来帮助开发者监测内存使用情况。
在处理器资源分配方面,应该确保高优先级的任务能够及时获得足够的处理时间。在Linux系统中,可以通过nice和cpulimit命令来管理进程优先级和CPU时间配额。
### 2.3.2 负载均衡技术
负载均衡技术用于分配工作负载,确保系统资源得到充分使用,而不会因为某些资源过度使用而导致瓶颈。
在GSolver中,可以使用负载均衡算法来实现多个实例间的合理任务分配。常见算法包括轮询调度、最少连接调度、响应时间调度等。这些算法可以内置在GSolver中,也可以借助外部负载均衡器如Nginx、HAProxy实现。
负载均衡的配置示例可以参考以下伪代码:
```python
# 伪代码:轮询调度算法示例
load_balancer = RoundRobinLoadBalancer()
while True:
task = next_task_queue.get_task()
server = load_balancer.assign_server(task)
server.process(task)
```
在这个例子中,load_balancer对象根据轮询算法为每个任务选择一个服务器进行处理。
通过上述章节的内容,我们已经了解了性能优化的基础知识和实践方法。接下来的章节将介绍GSolver在高级编程技巧方面的应用,以及如何将这些优化技巧应用于实际开发中。
# 3. GSolver高级编程技巧
### 3.1 高级数据处理技术
#### 3.1.1 数据缓存与预处理
在处理大规模数据集时,缓存和数据预处理是提高效率和减少资源消耗的关键。GSolver作为一个高性能的软件,它在处理数据方面提供了丰富的功能。为了减少I/O操作的次数和提高数据处理速度,合理利用缓存是一个非常实用的策略。在GSolver中,可以使用内置的缓存机制来存储频繁访问的数据,以避免重复读写磁盘。
在实践中,数据预处理可以大幅减少在实际计算时的计算量。例如,在进行复杂的统计分析之前,可以先对数据进行清洗、归一化、标准化等处理。GSolver支持自定义的数据处理模块,允许开发者在数据进入核心处理流程之前,实现特定的预处理逻辑。
```
// 示例代码块展示了GSolver中的数据预处理函数
def preprocess_data(data):
# 数据清洗:去除无用或错误的数据条目
clean_data = remove_errors_and_duplicates(data)
# 数据归一化处理
normalized_data = normalize(clean_data)
return normalized_data
# 使用缓存机制减少重复处理
cached_preprocessed_data = cache.get('preprocessed_data_key')
if cached_preprocessed_data:
data = cached_preprocessed_data
else:
data = preprocess_data(original_data)
cache.set('preprocessed_data_key', data)
```
在上述代码中,首先定义了一个`preprocess_data`函数来清洗和归一化数据。此外,通过使用缓存系统`cache`,我们减少了对`preprocess_data`函数的重复调用。这是通过首先检查缓存是否已经存储了所需的数据,如果没有,则调用该函数并将其结果存储在缓存中。
#### 3.1.2 复杂数据结构的应用
在处理复杂的算法问题时,合理选择和应用数据结构能够大幅度提高代码效率。GSolver支持多种数据结构,包括但不限于哈希表、树、图和优先队列等。例如,在需要快速查询和更新信息的场景中,可以使用哈希表来存储数据。
在一些特定的算法中,如图算法,GSolver提供了对图数据结构的原生支持。这意味着开发者可以更方便地实现如最短路径搜索、网络流计算等算法。树结构在处理层次化数据和递归问题中也非常有用,例如,进行语法分析时构建的抽象语法树。
```
// 示例代码块展示了GSolver中如何使用图数据结构来构建和操作图
graph = Graph()
node_a = graph.add_node("A")
node_b = graph.add_node("B")
edge_ab = graph.add_edge(node_a, node_b, weight=1)
// 使用深度优先搜索遍历图
def dfs(graph, start_node):
visited = set()
def visit(node):
if node not in visited:
print(node.id)
visited.add(node)
for neighbor in node.neighbors:
visit(neighbor)
visit(start_node)
dfs(graph, node_a)
```
在这个例子中,我们创建了一个图对象`graph`,向其中添加了节点和边。然后实现了深度优先搜索算法`dfs`来遍历图结构。GSolver的数据结构库使得处理复杂的图操作变得简单。
### 3.2 高效算法实现
#### 3.2.1 算法复杂度分析
在软件开发和优化中,算法复杂度是一个重要概念。复杂度分析帮助开发者了解算法在处理数据时的资源消耗,包括时间和空间复杂度。时间复杂度是指算法执行时间与输入数据大小之间的关系,而空间复杂度是指算法所需存储空间与输入数据大小之间的关系。
在GSolver中,可以通过分析算法的复杂度来指导优化工作。例如,可以寻找更优的算法来替换那些时间或空间复杂度过高的算法。对于优化前后的算法复杂度,我们通常使用大O符号来表示上界,例如O(n), O(nlogn), O(1)等。
```
// 示例代码块展示了如何在GSolver中实现一个具有O(nlogn)时间复杂度的排序算法
def mergesort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = mergesort(arr[:mid])
right_half = mergesort(arr[mid:])
return merge(left_half, right_half)
def merge(left, right):
sorted_arr = []
left_index, right_index = 0, 0
while left_index < len(left) and right_index < len(right):
if left[left_index] <= right[right_index]:
sorted_arr.append(left[left_index])
left_index += 1
else:
sorted_arr.append(right[right_index])
right_index += 1
sorted_arr.extend(left[left_index:])
sorted_arr.extend(right[right_index:])
return sorted_arr
# 测试复杂度为O(nlogn)的mergesort算法
array_to_sort = [5, 3, 8, 4, 2]
sorted_array = mergesort(array_to_sort)
```
在此代码片段中,我们使用了归并排序算法`mergesort`,该算法具有O(nlogn)的时间复杂度。通过递归地将数组分成两半,然后合并排序,最终得到一个有序数组。
#### 3.2.2 算法优化实例
在实际开发中,算法优化是提高软件性能的关键环节。GSolver提供了多种内置函数和算法来帮助用户进行算法的优化。算法优化通常包括减少不必要的计算、简化循环逻辑、避免在算法中产生不必要的内存分配等。
在优化算法时,需要关注算法的实际运行时间,并对其进行基准测试。此外,还可以考虑一些高级技术,如记忆化搜索、动态规划、贪心算法等,这些都可以有效地优化算法性能。
```
// 示例代码块展示了使用记忆化技术优化递归算法
from functools import lru_cache
# 计算斐波那契数列的函数
@lru_cache(maxsize=None)
def fibonacci(n):
if n < 2:
return n
else:
return fibonacci(n - 1) + fibonacci(n - 2)
# 使用优化后的函数计算斐波那契数列
fib_number = fibonacci(30)
```
在这个例子中,我们使用了Python的`lru_cache`装饰器,它是一个简单的记忆化技术实现。它允许我们在不改变原有递归算法的基础上,缓存函数调用的结果,从而避免重复计算。这极大地提升了计算斐波那契数列的效率。
### 3.3 自定义扩展与插件开发
#### 3.3.1 扩展机制的理解
GSolver提供了一个灵活的扩展机制,允许开发者根据自己的需求来添加新的功能模块。这些扩展通常以插件的形式存在,可以是新的算法、数据处理方式、用户界面组件或第三方服务集成等。
理解GSolver的扩展机制,首先要了解其插件体系结构。它通常包括了插件的发现、加载、初始化和注册等环节。插件开发者需要遵循GSolver定义的接口和约定,以确保插件能够在软件中无缝集成并正常工作。
#### 3.3.2 插件开发流程与技巧
在开发GSolver插件时,开发者首先需要确定插件的具体需求和功能。然后,在遵循GSolver的插件开发文档的基础上,开始编码工作。开发者需要熟悉GSolver提供的API和框架,以便能够开发出能够与主程序良好交互的插件。
在插件开发过程中,特别需要注意版本兼容性、错误处理和性能问题。版本兼容性确保插件能在不同版本的GSolver中正常工作;错误处理则要确保插件在遇到异常情况时能够稳定地处理错误,避免整个软件崩溃;而性能问题则关系到插件运行的效率,需要在设计和编码阶段就考虑进去。
```
// 示例代码块展示了GSolver插件开发的基本框架
class MyGSolverPlugin:
def __init__(self):
self.name = 'My Plugin'
self.description = 'This is an example plugin for GSolver.'
def initialize(self):
# 插件初始化逻辑
print(f"{self.name} initialized.")
def execute(self, data):
# 执行插件逻辑
print(f"Processing data with {self.name}")
return self.process_data(data)
def process_data(self, data):
# 实际处理数据的函数
return data
# 插件注册和加载
def register_plugin():
plugin = MyGSolverPlugin()
plugins.register(plugin.name, plugin)
return plugin
# 在GSolver启动时注册插件
if __name__ == "__main__":
plugin = register_plugin()
```
在这个例子中,`MyGSolverPlugin`类代表了一个基本的插件结构。其中包含初始化方法`__init__`和执行逻辑`execute`,用于处理传入的数据。通过`register_plugin`函数,该插件在程序启动时被注册和加载。
GSolver的高级编程技巧涉及数据处理、算法实现以及插件开发,这些技术的应用可以极大地提升软件的性能和灵活性。开发者通过掌握这些高级技巧,可以将GSolver的功能推向新的高度。
# 4. GSolver集成与系统兼容性提升
## 4.1 跨平台兼容性策略
### 4.1.1 跨平台架构设计
在跨平台应用的开发过程中,架构设计是至关重要的一步,它决定了软件能否在不同的操作系统和硬件架构上无缝运行。GSolver软件的跨平台架构设计涵盖了多种设计模式和编程范式,包括但不限于模型-视图-控制器(MVC)模式、面向服务架构(SOA)以及组件化设计。
首先,模型-视图-控制器模式将应用分为三个主要部分,模型(Model)负责数据和业务逻辑,视图(View)负责用户界面,控制器(Controller)负责处理输入和管理用户界面。GSolver将复杂的功能封装在模型中,通过控制器与视图进行交互,确保了不同平台界面的一致性和数据处理的统一性。
其次,面向服务架构(SOA)通过将应用程序的不同功能组件抽象为独立的服务,促进了代码的重用性和模块化。GSolver将通用功能如数据处理、算法执行等抽象成服务,并通过统一的接口进行交互,为跨平台部署提供了便利。
最后,组件化设计允许开发者将应用的不同部分拆分成独立的模块,每个模块完成一组特定的任务。GSolver通过清晰定义的API和接口来实现组件间的通信,保证了各个模块在不同环境下的兼容性和灵活性。
### 4.1.2 兼容性测试与问题解决
兼容性测试是确保GSolver在不同平台上运行正常的关键步骤。为了进行有效的兼容性测试,我们采用了多种策略:
- **自动化测试框架**:利用Selenium和Appium等自动化测试工具,编写跨平台测试脚本,对GSolver的各项功能进行自动化测试。
- **虚拟化环境测试**:使用Docker和虚拟机技术,构建不同的操作系统环境,以模拟真实世界的运行环境。
- **真实设备测试**:在尽可能多的物理设备上运行GSolver,包括不同的操作系统版本和硬件配置。
在兼容性问题的解决方面,需要对发现的问题进行详细分类并采取相应措施:
- **平台特定问题**:对于特定操作系统特有的问题,开发特定的适配代码,解决平台间的差异性。
- **依赖库问题**:由于不同平台对库的依赖和支持程度不同,需要选择跨平台支持良好的库,或者提供相应的适配层。
- **性能问题**:在某些平台上性能低下可能是由于系统调用、资源管理等方面的原因,这时需要针对性能瓶颈进行优化。
在兼容性测试过程中,我们使用了下面的表格来记录测试结果和问题:
| 平台 | 版本 | 功能测试 | 性能测试 | 兼容性问题 |
| ------------ | ------ | -------- | -------- | ---------- |
| Windows | 10 | 通过 | 通过 | 无 |
| macOS | 10.15 | 通过 | 通过 | 无 |
| Linux | Ubuntu | 通过 | 通过 | 依赖缺失 |
| Android | 9 | 通过 | 通过 | 界面适配 |
| iOS | 13 | 通过 | 通过 | 安全限制 |
| ... | ... | ... | ... | ... |
接下来是具体的代码块,展示如何实现跨平台的日志记录功能:
```python
import platform
import logging
def setup_logging():
# 根据不同的操作系统设置日志
os_name = platform.system()
log_filename = f"gsolver_log_{os_name}.log"
logging.basicConfig(filename=log_filename,
level=logging.INFO,
format='%(asctime)s %(levelname)s %(message)s')
# 输出日志到控制台
console = logging.StreamHandler()
console.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s %(levelname)s %(message)s')
console.setFormatter(formatter)
logging.getLogger('').addHandler(console)
if __name__ == "__main__":
setup_logging()
logging.info("跨平台日志记录初始化完成")
```
在上述代码中,GSolver通过检查系统名称`platform.system()`,自适应地调整日志文件的名称。这种处理确保了日志记录的跨平台兼容性。每个平台的日志都保存在以该平台命名的文件中,便于后续的分析和调试。
## 4.2 系统集成优化
### 4.2.1 集成模式与方法
系统集成是一个复杂的过程,涉及将GSolver与其他系统或服务集成,以确保它们能够协同工作。GSolver采用了灵活的集成模式,其中包括但不限于以下几种:
- **直接集成**:将GSolver作为库或模块直接集成到现有系统中。这种方法通常需要较少的配置,并且对系统的影响最小。
- **服务集成**:通过API或Web服务将GSolver作为一个独立服务集成。这种方式适合微服务架构,可以实现松耦合集成。
- **数据集成**:通过数据同步和交换机制将GSolver与数据源集成。这种集成模式专注于数据流转和处理。
集成方法的选择取决于目标系统的架构和需求。例如,如果目标系统需要高可用性和扩展性,可能会选择服务集成模式;如果目标系统注重性能和资源利用,则直接集成可能是更合适的选择。
### 4.2.2 集成过程中的性能调整
在集成过程中,性能调整是确保GSolver在新环境中运行效率的关键环节。性能调整主要包括以下几个方面:
- **资源分配**:根据目标系统的资源状况,合理分配GSolver所需的内存和CPU等资源。
- **数据库优化**:调整数据库配置和查询逻辑,确保数据处理的高效性。
- **并发处理**:针对不同的集成场景,实现并发控制和任务调度优化,以提高整体性能。
性能调整的示例代码如下:
```java
// Java代码段,展示如何调整线程池的大小以优化并发性能
ExecutorService executorService = Executors.newFixedThreadPool(Math.max(2, Runtime.getRuntime().availableProcessors() - 1));
// 提交任务到线程池
executorService.execute(() -> {
// 执行任务代码
});
// 关闭线程池
executorService.shutdown();
```
在上述代码中,GSolver通过`Executors.newFixedThreadPool`创建了一个固定大小的线程池。线程池的大小通过`availableProcessors()`方法确定,这个方法返回可用处理器的数量,保证了并行任务能够充分利用CPU资源,而不会造成资源浪费或过载。
## 4.3 第三方库和工具的整合
### 4.3.1 第三方库的选择与评估
GSolver的开发过程中大量依赖于第三方库,它们提供了丰富的功能,缩短了开发周期,同时也有助于保持代码的质量和稳定性。在选择第三方库时,我们遵循以下原则:
- **社区活跃度**:优先选择社区活跃且持续更新的库。
- **文档完整性**:选择文档齐全的库,便于理解和使用。
- **兼容性**:确保库的兼容性与GSolver的目标平台和依赖库兼容。
- **安全性**:选择声誉良好且经过安全审计的库,避免潜在的安全风险。
评估第三方库的表格如下:
| 库名称 | 社区活跃度 | 文档完整性 | 兼容性 | 安全性评估 |
| ------------ | ---------- | ---------- | ------ | ---------- |
| Library X | 高 | 完整 | 良好 | 无已知风险 |
| Library Y | 中 | 一般 | 有局限 | 需进一步评估 |
| Library Z | 低 | 缺少 | 未知 | 存在风险 |
| ... | ... | ... | ... | ... |
### 4.3.2 集成第三方工具的实践技巧
GSolver集成第三方工具的实践技巧涉及到了解工具的接口和集成方式,以实现工具与GSolver的无缝对接。例如,集成版本控制系统Git时,GSolver通过以下步骤进行:
1. **确定接口规范**:研究Git的API,了解其提供的接口和功能。
2. **编写适配器代码**:实现一个适配层,使得GSolver可以调用Git的功能。
3. **集成测试**:在不同的Git版本和配置上运行集成测试,确保GSolver可以稳定地使用Git。
集成第三方工具的代码示例:
```python
import git
def clone_repo(repo_url, branch='master', clone_path='./'):
# 使用Git库克隆仓库
git.Repo.clone_from(repo_url, clone_path, branch=branch)
if __name__ == "__main__":
repo_url = 'https://github.com/user/repo.git'
clone_repo(repo_url)
```
在此示例中,GSolver通过Python的Git库来克隆远程的Git仓库。`clone_from`方法允许用户指定仓库的URL、克隆路径以及想要检出的分支。这样的集成方式简化了版本控制的流程,使得GSolver可以高效地管理软件版本。
通过这些实践技巧,GSolver能够实现与各类工具和库的有效集成,从而提升软件的整体功能和性能。
# 5. GSolver的实际应用案例分析
## 5.1 行业解决方案概述
### 5.1.1 行业特定需求分析
在实际应用GSolver的过程中,针对不同行业领域,GSolver能够提供量身定制的解决方案。例如,在金融行业,GSolver可以用于高频交易数据分析,帮助投资银行分析市场趋势,或者在保险行业中用于风险评估模型。工业领域中,GSolver可以协助进行生产流程优化,通过分析生产数据,预测设备故障,从而提高生产效率。
### 5.1.2 解决方案的实施步骤
为了实施GSolver的解决方案,可以遵循以下步骤:
1. 需求调研:与客户沟通,理解他们的业务需求和目标。
2. 方案设计:根据需求设计解决方案,包括选择合适的GSolver工具和组件。
3. 系统集成:将GSolver集成到现有系统中,确保各个组件协调工作。
4. 数据准备:收集和处理必要的数据,为分析和计算做准备。
5. 模型部署:在测试环境中验证模型的准确性,然后部署到生产环境中。
6. 监控与优化:持续监控系统性能,并根据反馈进行优化。
## 5.2 成功案例深度剖析
### 5.2.1 案例背景与目标
在一家大型零售连锁企业中,GSolver被用来分析销售数据,优化库存管理,提升产品补货的准确性和及时性。目标是通过精确的需求预测,减少库存积压和缺货情况,从而提高客户满意度和运营效率。
### 5.2.2 项目实施过程与成果
项目实施过程中,首先对历史销售数据进行了清洗和预处理,然后使用GSolver的高级算法进行需求预测。在预测模型构建后,该模型被集成到公司的库存管理系统中。
实施结果表明,通过GSolver的预测模型,库存周转率提高了20%,而缺货率降低了30%。这直接导致了销售增长和成本节约。
## 5.3 常见问题与解决方案
### 5.3.1 遇到的问题及分析
在将GSolver集成到各种不同系统时,我们面临了一系列挑战。比如,数据格式和接口的不兼容、系统间的性能不匹配以及数据安全和隐私问题。
### 5.3.2 解决方案的总结与反思
为解决这些挑战,我们采取了以下措施:
- 使用数据转换工具处理不同格式的数据,确保它们与GSolver兼容。
- 在性能不匹配的系统间部署缓存和负载均衡技术,以提高整体效率。
- 加强数据加密措施和访问控制,确保数据安全。
这些措施不仅解决了现有问题,还提升了系统的整体性能和可靠性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MTBF计算基础:从零开始,一文读懂MIL-HDBK-217F标准(附实战教程)

# 摘要
本文详细探讨了MTBF(平均无故障时间)与可靠性的基本概念,并深入解读了MIL-HDBK-217F标准,该标准广泛应用于评估电子和机械设备的可靠性。通过对MIL-HDBK-217F标准的历史背景、应用、基本假设和计算模型的解析,本文阐述了MTBF的计算方法,并提供了一个实战计算教程。此外,文章还探讨了如何通过优化策略和常见技术来提高MTBF,并通过案例研究展示这些策略的实际应用。最后,本文介绍了MTBF的测试方法、验证流
【通达信公式实战演练】:掌握高级调试技巧,最佳实践大公开

# 摘要
通达信公式是为金融市场分析设计的一套强大的工具语言,广泛应用于交易策略构建、市场指标分析以及图表分析等领域。本文首先介绍了通达信公式的概念和基础,然后深入解析了其语言的基本语法、数据类型和结构、高级特性。随后,文章通过实战应用,探讨了市场指标分析、交易策略构建与回测、高级图表应用等关键主题。进一步,本文对通达信公式的调试、性能优化以及安全性问题进行了详细讨论,并探讨
ODB++兼容性挑战:掌握不同软件间无缝转换的秘诀

# 摘要
本文综合探讨了ODB++格式在印刷电路板(PCB)设计中的应用及其与其他格式的兼容性问题。首先概述了ODB++格式及其在PCB设计中的作用,接着分析了ODB++与其他PCB设计格式如Gerber和Excellon之间的差异及兼容性挑战的原因。文章还介绍了ODB++兼容性转换的理论基础,包括数据转换模型和关键技术,并提供了实践应用中的转换工具介绍、设置与配置,以及转换过程中问题的解决方案。通过案例研究
激光对刀仪精度优化秘籍:波龙型号的精准校准
# 摘要
激光对刀仪作为制造业中重要的精密测量工具,对于提高机械加工的精确度和效率具有重要作用。本文首先介绍了激光对刀仪的技术背景及其在制造业中的应用,进而探讨了波龙型号激光对刀仪的理论基础,包括其工作原理、关键技术和精度参数。接着,本文详细阐述了精度校准的实践步骤、关键操作以及校准后的精度验证方法。进一步地,本文探讨了精度提升的技巧、设备维护策略,并通过案例分析提炼了成功经验。最后,本文展望了激光对刀仪精度优化的未来发展方向,包括人工智能、机器学习以及高精度传感器技术的应用前景,并讨论了行业发展趋势与挑战。通过对这些方面的深入分析,本文旨在为激光对刀仪的研究和应用提供有价值的参考。
# 关
【Fluent UDF高级应用技巧】:解锁复杂流体模拟的新世界

# 摘要
Fluent UDF(User-Defined Functions)为ANSYS Fluent提供了一种强大的自定义功能,使得用户能够通过编写代码来扩展Fluent内置的功能。本文首先介绍了Fluent UDF的基础知识,包括函数类型、声明、宏定义及使用,以及数据存储和管理。接着,文中探讨了流体模拟中的高级特性应用,如边界条件处理、复杂流体模型自定义和多相流、反应流模拟的U
ISO 16845-1标准物理信号传输机制:专家技术细节与实现指南

# 摘要
ISO 16845-1标准是针对物理信号传输的一套详细指南,涵盖了从理论基础到实际应用的全面内容。本文首先概述了ISO 16845-1标准,接着深入探讨了物理信号的定义、特性、传输原理以及标准中所规定的传输机制
确保Verilog除法器正确性的关键:验证与测试的最佳实践
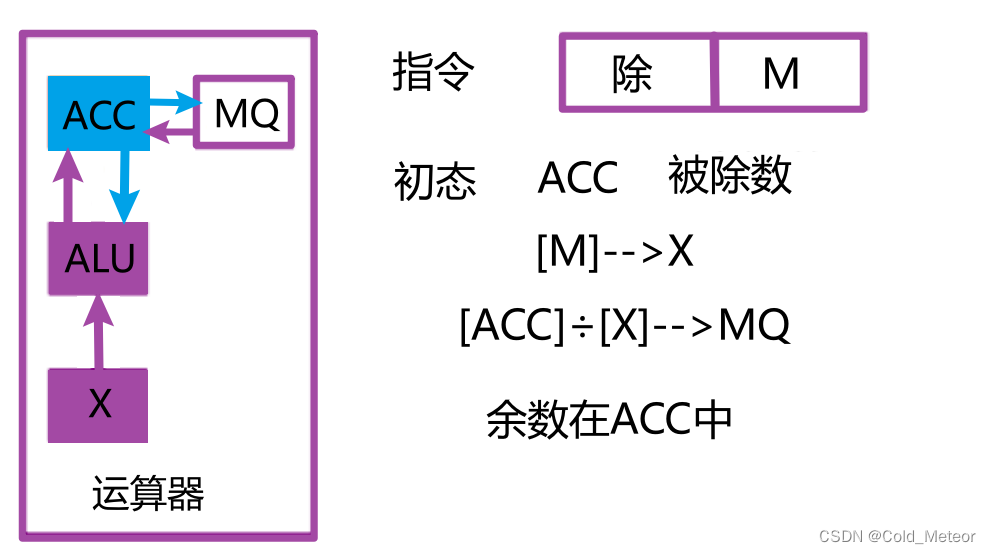
# 摘要
本文详细介绍了Verilog除法器的设计基础、理论基础、验证方法、测试策略以及高级验证技巧。首先,探讨了除法器设计的基础知识和数学原理,随后深入讨论了除法器的硬件实现,包括不同类型的除法器和硬件优化技术。接着,文章详述了除法器的验证方法,涵盖功能仿真验证和形式化验证,并解释了自动化测试框架和覆盖率分析在测试策略中的应用。文章最后介绍了断言驱动开发、跨时钟域验证以及验证计划和管理的高级技巧,为硬件设计者提供了一
【文档转换专家】:掌握Word到PDF无缝转换的终极技巧
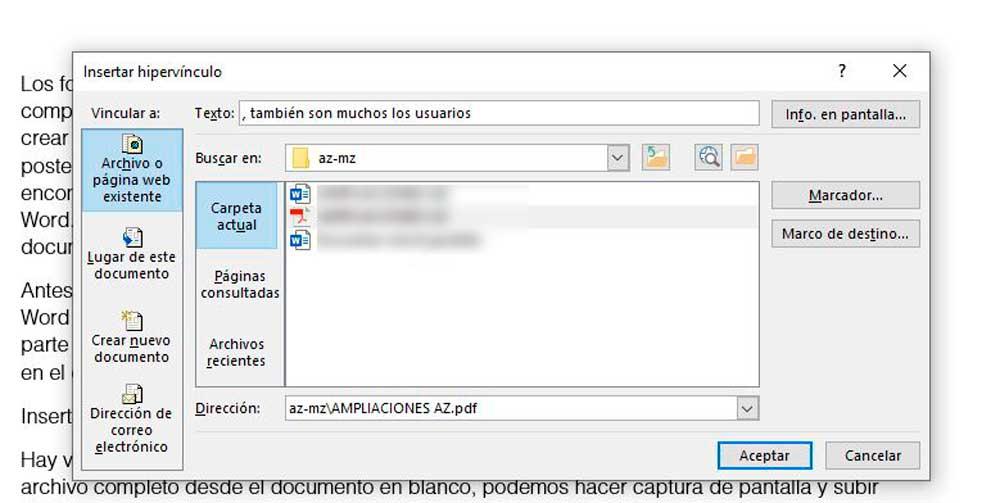
# 摘要
文档转换是电子文档处理中的一个重要环节,尤其是从Word到PDF的转换,因其实用性广泛受到关注。本文首先概述了文档转换的基础知识及Word到PDF转换的必要性。随后,深入探讨了转换的理论基础,包括格式转换原理、Word与PDF格式的差异,以及转换过程中遇到的布局、图像、表格、特殊字符处理和安全可访问性挑战。接着,文章通过介绍常用转换工具,实践操作步骤及解决
计算机二级Python实战:文件操作与数据持久化的巧妙应用

# 摘要
本文深入探讨了Python中文件操作的基础知识、数据持久化的机制以及它们在实际应用中的结合。首先,本文介绍了Python进行文件操作的基础,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )