GSolver软件性能提升攻略:7个步骤优化运行效率
发布时间: 2024-12-27 21:03:20 阅读量: 5 订阅数: 6 

GSolver软件说明书

# 摘要
本文详细介绍了GSolver软件性能优化的全方位策略,首先概述了性能优化的重要性并提供了一个综合概述。接着,通过性能诊断方法识别和分析软件的性能瓶颈,包括系统资源使用情况和优化前的准备。在代码级别,重点讨论了代码审查、重构、算法和数据结构优化以及内存管理。系统级优化方面,阐述了系统配置调整、并行计算、多线程应用和资源调度的实施。最后,论文讲述了GSolver软件的后续维护和性能监控,强调了持续监控的重要性,以及用户反馈在性能问题处理中的作用。通过这些方法和策略的实施,旨在显著提高GSolver软件的运行效率和可靠性。
# 关键字
性能优化;性能诊断;代码审查;内存管理;系统配置;并行计算
参考资源链接:[GSolver光栅设计软件用户手册](https://wenku.csdn.net/doc/6412b6d8be7fbd1778d482e9?spm=1055.2635.3001.10343)
# 1. GSolver软件性能优化概述
GSolver软件作为一个在多个领域被广泛应用的解决方案,其性能的优劣直接影响着用户的使用体验和生产效率。在当前技术发展日新月异的背景下,性能优化变得尤为重要。本章将介绍性能优化的必要性,探讨优化前应具备的理论基础和方法,并为后续章节中的诊断方法、代码级优化以及系统级优化奠定基础。
在深入到具体的优化策略之前,首先需要了解性能优化的基本概念。性能优化不仅仅局限于提升软件运行速度,它还包括对资源消耗、稳定性、可扩展性等多方面的考量。通过优化,GSolver能够以更少的系统资源提供更流畅的用户体验,从而在竞争激烈的市场中保持优势地位。
为了达到这一目标,本章节会概述性能优化的总体框架和基本思路,为接下来的章节提供一个清晰的路线图。我们将会从性能评估和诊断开始,逐步深入到代码层面的改进、系统架构的调整,以及后续维护和监控的策略。
# 2. GSolver软件性能诊断方法
## 2.1 性能评估的重要性
### 2.1.1 理解性能评估的目的和方法
性能评估是提升软件性能的先决条件,其核心目的是识别和分析软件运行中的性能瓶颈,为后续的性能优化提供科学依据。性能评估通常涉及多个方面,包括但不限于响应时间、资源利用率、吞吐量等。在进行性能评估时,需要采用适当的工具和方法来监控和分析系统的运行情况。
为了确保性能评估的全面性和准确性,通常会采用以下几种方法:
1. **基准测试(Benchmarking)**:通过与特定标准或先前的性能数据比较,评估软件在规定条件下的性能水平。
2. **压力测试(Stress Testing)**:通过不断增加系统负载来观察系统在高压力下的表现,以发现潜在的性能问题。
3. **性能分析(Profiling)**:收集软件运行时的详细性能数据,包括CPU、内存使用情况,以及函数调用频率等,来确定性能瓶颈。
### 2.1.2 常用的性能评估工具和指标
性能评估过程中,选择合适的工具至关重要。在实际操作中,开发者和运维团队经常会用到的性能评估工具包括:
- **JMeter**:广泛用于Web应用程序的负载和性能测试。
- **VisualVM**:提供了丰富的监控和故障排查功能,支持Java虚拟机(JVM)的应用程序。
- **Percona Monitoring and Management (PMM)**:为MySQL和MongoDB等数据库提供监控和分析功能。
此外,性能评估的指标体系也是评估的关键组成部分。常见的性能评估指标包括:
- **响应时间**:用户请求到系统响应所需的总时间。
- **吞吐量**:单位时间内系统可以处理的事务数或请求数。
- **资源使用率**:包括CPU、内存、磁盘I/O和网络I/O的利用率。
- **错误率**:请求处理过程中出现错误的比率。
## 2.2 识别性能瓶颈
### 2.2.1 系统资源使用情况分析
分析系统资源使用情况是识别性能瓶颈的重要步骤。GSolver软件的资源使用分析主要包括以下几个方面:
- **CPU使用情况**:监控CPU时间消耗,区分用户态和系统态的CPU使用情况,以及是否存在CPU密集型的操作。
- **内存使用情况**:跟踪内存分配、回收情况以及内存泄漏的可能。
- **磁盘I/O**:监测文件读写操作的频率和速度,以及是否存在I/O密集型操作。
- **网络I/O**:记录网络请求和响应的时间,以及数据传输的效率。
在分析资源使用情况时,可以使用如下的代码块来展示如何使用工具来获取这些信息:
```bash
# 使用vmstat命令监控系统资源使用情况
vmstat 1 5
```
解释:
上述命令将每隔1秒采样一次系统资源使用情况,共采样5次。输出结果包括CPU的空闲、用户态、系统态使用率,以及内存、磁盘、进程和CPU上下文切换等信息。
### 2.2.2 瓶颈诊断技术与实践
当识别出系统资源的使用情况后,接下来需要运用瓶颈诊断技术来确定影响性能的具体瓶颈点。一些常见的诊断技术包括:
- **火焰图(Flame Graphs)**:用于可视化CPU采样的调用栈信息,快速定位高CPU消耗的代码区域。
- **堆转储分析(Heap Dump Analysis)**:分析内存泄漏和内存使用峰值时的堆内存快照,找出内存占用过多的对象。
- **分析I/O瓶颈**:使用`iostat`和`iotop`命令监控磁盘I/O操作,确定是否存在磁盘性能问题。
实践示例:
```bash
# 使用火焰图来分析CPU瓶颈
# 首先运行perf命令来记录CPU的性能数据
perf record -F 99 -a -g
# 之后使用perf script和FlameGraph工具生成火焰图
perf script | FlameGraph/stackcollapse-perf.pl | FlameGraph/flamegraph.pl >火焰图.svg
```
解释:
上述脚本首先使用`perf`命令对所有进程和CPU核心进行性能数据的采样记录,`-F 99`参数表示每秒采样99次,以获得尽可能详细的数据。然后使用`FlameGraph`工具集将采样数据转化为可视化的火焰图,帮助开发者直观地识别出CPU热点代码。
## 2.3 优化前的准备和规划
### 2.3.1 评估优化风险和成本
在着手性能优化之前,评估可能面临的风险和成本是至关重要的。性能优化可能带来的风险包括:
- **破坏现有功能**:在进行优化时可能会引入新的bug,破坏软件的现有功能。
- **优化效果不明显**:某些优化可能因为方法不当,或优化空间有限而无法达到预期效果。
与此同时,优化的成本也需要评估,包括:
- **开发成本**:开发和测试新功能或优化方案的时间成本。
- **维护成本**:优化后的代码可能需要额外的维护工作。
### 2.3.2 制定优化计划和步骤
制定一个详细的优化计划和步骤,是确保性能优化工作有序进行的保障。优化计划一般包括以下几个步骤:
1. **收集性能数据**:使用各种性能分析工具和方法来获取性能数据。
2. **分析性能数据**:识别性能瓶颈,并确定优化的优先级。
3. **实施优化**:基于瓶颈分析结果,选择合适的优化策略进行实施。
4. **验证优化效果**:对优化后的系统进行测试,验证性能是否得到提升。
5. **持续优化**:根据性能监控数据,进行持续的性能优化工作。
代码块示例:
```python
# 示例Python代码,用于收集性能数据
import cProfile
def test_function():
# 此处为被测试的代码段
pass
cProfile.run('test_function()')
```
解释:
上述代码使用了Python内置的`cProfile`模块来对特定函数`test_function`进行性能分析。通过`cProfile.run`函数执行该函数,并输出性能分析报告,包括函数调用次数、总时间、平均时间等,从而可以分析出性能瓶颈。
通过本章节的介绍,读者应已了解到性能评估的重要性,识别性能瓶颈的方法,以及优化前的准备和规划。在下一章节中,我们将深入了解GSolver软件代码级优化的策略和实践。
# 3. GSolver软件代码级优化
在IT行业中,软件性能优化是持续的过程,而代码级别的优化是实现性能提升的基础。代码级优化不仅可以提高软件运行效率,减少资源消耗,还可以改善软件的整体架构,为系统级优化打下坚实的基础。
## 3.1 代码审查与重构
代码审查与重构是提高代码质量的有效手段。通过严格的代码审查,可以发现潜在的代码问题,并在问题尚未影响软件性能之前进行修正。重构则是一项持续进行的技术活动,它通过改进软件的设计和编码来提高代码的可读性和可维护性。
### 3.1.1 代码质量评估标准
代码质量评估是通过一系列可量化的标准来进行的。常见的评估指标包括代码的可读性、可维护性、可扩展性和可复用性。评估工具如SonarQube可以帮助开发者对代码库进行自动化的质量检查,检测出代码中的潜在问题,如代码复杂度过高、重复代码、未使用的代码以及潜在的bug。
### 3.1.2 重构实践与案例分析
重构实践要求开发者不仅要编写功能代码,还要关注代码的结构和质量。常见的重构手法包括提炼函数、合并重复代码块、拆分大型类或方法等。在进行重构时,应当结合具体的案例来展示优化的效果。例如,在GSolver软件中,原始的算法实现可能过于复杂,通过提炼公共算法组件,不仅代码变得简洁,而且后续维护和性能优化也变得更加容易。
## 3.2 算法和数据结构优化
在GSolver软件中,算法和数据结构的选择对于性能影响至关重要。优化算法和数据结构可以提高算法执行效率,减少不必要的资源消耗。
### 3.2.1 理解算法复杂度
算法复杂度是衡量算法性能的主要指标,它包括时间复杂度和空间复杂度。优化算法的第一步是理解现有算法的复杂度,评估其在处理大数据量时的性能表现。例如,排序算法的选择会直接影响到软件处理大规模数据集时的性能表现。
### 3.2.2 数据结构的选择与调整
正确的数据结构可以显著提高程序的效率。在GSolver软件中,合理选择数据结构可以加快查找、排序等操作的速度。例如,在处理多维数据时,选择合适的数据结构可以减少存储空间,提升访问速度。需要重点考虑数据结构的访问效率、存储密度和更新频率等因素。
## 3.3 内存管理与优化
内存泄漏和不合理的内存使用是导致软件性能下降的常见原因。良好的内存管理习惯可以避免这些性能问题。
### 3.3.1 内存泄漏的检测与修复
内存泄漏是内存管理中最常见的问题之一。通过内存泄漏检测工具如Valgrind,可以识别出代码中内存泄漏的位置,并采取相应的修复措施。修复内存泄漏需要程序员对代码逻辑有深刻的理解,以确保在修复过程中不会引入新的错误。
### 3.3.2 内存使用优化技巧
优化内存使用涉及到减少内存分配次数、使用内存池以及合理管理内存块大小等策略。此外,对于动态分配的内存,应确保在使用完毕后及时释放,避免造成内存资源的浪费。例如,在GSolver软件中,可以采用内存池机制来管理大量对象的创建与销毁,从而提升整体的内存使用效率。
在下一章节中,我们将深入探讨GSolver软件的系统级优化策略,包括系统配置调整、并行计算与多线程应用等重要话题。
# 4. GSolver软件系统级优化
随着GSolver软件的复杂度增加,仅仅依靠代码级别的优化已无法满足性能需求。系统级优化涉及到对整个软件架构的调整和资源管理,以达到提升效率、增强稳定性的目的。本章节将深入探讨系统级优化中的关键策略和技术细节。
## 4.1 系统配置调整
系统配置是影响软件性能的重要因素之一。合理的系统配置能够使GSolver软件更好地运行在特定的硬件平台上。
### 4.1.1 系统资源分配的调整
GSolver软件在运行时会消耗CPU、内存、磁盘IO、网络等资源。为了优化性能,需要根据实际运行环境合理分配这些资源。例如,如果发现内存使用过高,可以考虑增加物理内存或优化内存使用。调整虚拟内存大小、文件系统类型和配置、网络配置参数等,都有助于提升性能。
```mermaid
graph TD
A[系统资源分配调整] --> B[物理内存优化]
A --> C[虚拟内存配置]
A --> D[文件系统优化]
A --> E[网络参数配置]
```
### 4.1.2 系统参数优化
系统参数优化包括对操作系统和数据库系统的参数调整。如Linux系统的内核参数、IO调度器选择、文件系统的挂载选项等;数据库系统中的缓存大小、连接池配置等,这些参数对性能都有较大影响。
```markdown
系统参数优化实例:
- Linux内核参数:`vm.dirty_ratio`、`vm.dirty_background_ratio`、`vm.swappiness`
- IO调度器:`deadline`、`cfq`、`noop`、`mq-deadline`
- 文件系统挂载选项:`noatime`、`nodiratime`、`relatime`
- 数据库缓存大小:`shared_buffers`、`work_mem`、`effective_cache_size`
```
## 4.2 并行计算与多线程应用
GSolver软件作为一个高性能的解决平台,对多核心CPU的利用至关重要。合理使用并行计算和多线程技术能显著提高处理速度。
### 4.2.1 多线程编程模型的选取
选择合适的多线程编程模型对于实现并行计算至关重要。现代编程语言如C++11及以上版本提供了多线程库,而Java、Python等语言也有成熟的并发框架。在选取多线程编程模型时,应考虑语言特性、线程管理的复杂性、线程间的同步与通信等因素。
```markdown
多线程编程模型比较:
- Pthreads:适用于C/C++语言,底层控制丰富,但编程难度较高。
- Java Concurrency:Java语言提供的并发工具,如Executor框架、锁机制等。
- Python Threading/Multiprocessing:Python中实现多线程和多进程的标准库。
```
### 4.2.2 并行算法的实现与调优
并行算法的实现需要将问题分解为可以并行处理的多个子问题,并合理管理任务的调度。在实现并行算法时,需要考虑数据分割方式、负载均衡、线程安全和同步开销等因素。调优则涉及到工作单元的粒度选择、避免线程争抢和减少上下文切换等。
```c
// 示例代码:使用C++11实现简单的并行计算任务
#include <iostream>
#include <vector>
#include <thread>
void process_data(std::vector<int>& data) {
for (size_t i = 0; i < data.size(); ++i) {
// 对数据进行处理
data[i] *= 2;
}
}
int main() {
std::vector<int> data(1000000);
std::vector<std::thread> threads;
size_t chunk_size = data.size() / std::thread::hardware_concurrency();
for (size_t i = 0; i < std::thread::hardware_concurrency(); ++i) {
threads.emplace_back(process_data, std::ref(data[i*chunk_size...(i+1)*chunk_size]));
}
for (auto& t : threads) {
t.join();
}
// 输出处理后的数据
for (size_t i = 0; i < data.size(); ++i) {
std::cout << data[i] << std::endl;
}
}
```
在上述代码中,我们使用了C++11中的`std::thread`来创建多个线程,每个线程处理数据的一个分片。这种数据分割的策略能够充分利用多核CPU进行并行计算。
## 4.3 负载均衡与资源调度
为了进一步提升性能,GSolver软件需要在多个服务或节点之间有效分配工作负载,同时合理调度系统资源。
### 4.3.1 负载均衡策略
负载均衡旨在均匀分配请求或工作负载到多个服务器或计算单元,以避免过载和资源浪费。常见的负载均衡策略包括轮询、最小连接、响应时间、加权轮询等。
```markdown
负载均衡策略对比:
- 轮询(Round Robin):顺序将每个请求分配给服务器。
- 最小连接(Least Connections):将新请求分配给当前连接数最少的服务器。
- 响应时间(Response Time):基于服务器的响应时间动态分配请求。
- 加权轮询(Weighted Round Robin):根据服务器的权重分配请求,权重高的处理更多请求。
```
### 4.3.2 资源调度算法的应用实例
在GSolver软件中,资源调度算法可用于优化计算任务的执行顺序和分配策略。如蚁群算法、粒子群优化等启发式算法可用于优化复杂的资源调度问题。下面是一个简化的粒子群优化算法示例,用于解决任务调度问题。
```python
# 示例代码:使用Python实现简单的粒子群优化算法
import random
import numpy as np
def objective_function(x):
# 定义一个简单的目标函数,例如:最小化任务的总完成时间
return sum(x)
def generate_particles(n_particles, bounds):
particles = np.random.rand(n_particles, len(bounds))
for i, bound in enumerate(bounds):
particles[:, i] = bounds[i][0] + particles[:, i] * (bounds[i][1] - bounds[i][0])
return particles
def update_velocity(particles, velocities, bounds, c1=2, c2=2):
# 更新粒子的速度
pass
def update_position(particles, bounds):
# 更新粒子的位置
pass
def pso(n_particles, bounds, n_iterations):
particles = generate_particles(n_particles, bounds)
velocities = np.zeros(particles.shape)
best_particles = np.copy(particles)
best_scores = np.full(n_particles, float('inf'))
global_best_score = float('inf')
global_best_particle = np.zeros(len(bounds))
for i in range(n_iterations):
for j in range(n_particles):
score = objective_function(particles[j])
if score < best_scores[j]:
best_scores[j] = score
best_particles[j] = np.copy(particles[j])
if score < global_best_score:
global_best_score = score
global_best_particle = np.copy(particles[j])
update_velocity(particles, velocities, bounds)
update_position(particles, bounds)
return global_best_particle, global_best_score
bounds = [(0, 100)] * 5 # 假设有5个任务需要调度
best_particle, best_score = pso(30, bounds, 100)
print(f"Best particle: {best_particle}, Best score: {best_score}")
```
在本示例中,我们使用粒子群优化算法来寻找最优的任务调度顺序,以最小化任务的总完成时间。每个粒子代表一种可能的任务调度方案,通过迭代更新粒子的位置和速度,逐步逼近最优解。
通过本章节的介绍,读者应能理解并掌握GSolver软件在系统级优化方面的重要概念和实践方法。下一章节将探讨如何通过持续的性能监控、定期的性能评估和优化策略的迭代,确保软件长期运行在最佳状态。
# 5. GSolver软件后续维护与性能监控
持续的性能监控、评估和优化是保障GSolver软件长期稳定运行的关键环节。本章将深入探讨如何建立有效的性能监控机制,规划定期的性能评估与优化流程,并处理用户反馈的性能问题。
## 5.1 持续性能监控机制
性能监控是确保GSolver软件性能稳定性的第一道防线。它涉及到实时收集运行时数据,以便快速识别和响应性能波动。
### 5.1.1 性能监控工具的集成与使用
要实现有效的性能监控,首先需要集成性能监控工具。常用的监控工具有Prometheus、Grafana等,这些工具能够提供实时的性能数据和可视化的展示界面。
```mermaid
flowchart LR
subgraph "性能监控系统"
A[GSolver软件] -->|性能指标| B[Prometheus]
B -->|数据抓取| C[Grafana]
C -->|可视化展示| D[管理员]
end
```
在这个流程图中,GSolver软件输出的性能指标被Prometheus所抓取,然后这些数据被Grafana展示出来,使得管理员可以实时监控到软件的性能状态。
### 5.1.2 性能数据分析与报告
收集到的数据需要被分析以产生有价值的见解。这通常涉及使用分析工具,如Elasticsearch和Kibana,进行日志分析和可视化。
```mermaid
graph LR
A[数据收集] --> B[Elasticsearch]
B --> C[Kibana]
C -->|可视化报告| D[性能分析报告]
```
通过这样的分析流程,可以生成详细的性能分析报告,帮助团队了解性能趋势和热点问题。
## 5.2 定期性能评估与优化
为了维持和提升GSolver的性能,需要定期进行性能评估和优化。
### 5.2.1 建立定期评估制度
定期评估制度应当明确评估周期、责任分配、评估指标和流程等。
```markdown
评估周期:每周一次
责任分配:运维团队负责数据收集,开发团队负责分析
评估指标:响应时间、吞吐量、资源利用率
流程:数据收集 -> 数据分析 -> 评估报告 -> 优化计划
```
### 5.2.2 优化策略的迭代与更新
性能优化不是一次性的任务,而是一个持续的过程。优化策略需要根据评估结果不断迭代和更新。
## 5.3 用户反馈与性能问题处理
用户反馈是性能优化中不可或缺的部分,它直接反映了软件在实际使用中的性能表现。
### 5.3.1 收集用户反馈
收集用户反馈可以通过多种渠道,如用户调查、社区讨论、技术支持等。
### 5.3.2 性能问题的快速响应与解决
对于用户反馈的问题,需要建立快速响应机制。这可能包括:
```markdown
1. 建立问题跟踪系统,记录和管理用户报告的每个问题。
2. 分配响应团队,迅速定位问题并制定临时或长期解决方案。
3. 持续跟踪问题的解决进度,及时向用户通报情况。
```
通过上述流程,可以确保用户反馈得到及时处理,从而提高用户满意度,同时持续优化GSolver软件的性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
大数据处理技术精讲:Hadoop生态与Spark的高级使用技巧
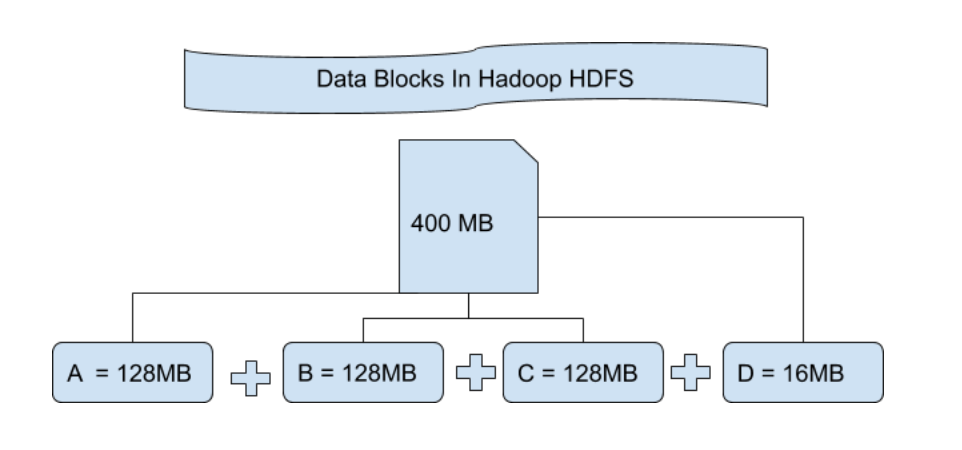
# 摘要
本文综述了大数据处理的概要、Hadoop生态系统、Spark高级使用技巧以及大数据安全与隐私保护技术。首先,介绍了大数据处理的基础概念。接着,深入分析了Hadoop的核心组件,包括其核心文件系统HDFS和MapReduce编程模型,以及Hadoop生态系统中Hive和HBase的扩展应用。此外,探讨了Hadoop集群的管理和优化,以及Spark的基础架构、数据
nRF2401 vs 蓝牙技术:跳频协议优劣对比及实战选择

# 摘要
无线通信技术是现代社会不可或缺的技术之一,尤其在远程控制和物联网项目中扮演重要角色。本文对nRF2401和蓝牙技术进行了全面分析,涵盖了它们的工作原理、特点以及在不同场景中的应用案例。文章详细探讨了跳频协议在这些技术中的应用和性能表现,为无线通信技术的实际选择提供了详实的指导。通过对nRF2401与蓝牙技术的对比分析,本文旨在为技术人员和
服务效率革命:7中心系统接口性能优化的关键策略
# 摘要
随着信息技术的快速发展,系统接口性能优化成为了提升用户体验和系统效率的关键。本文首先概述了接口性能优化的重要性,并介绍了衡量接口性能的多个关键指标。随后,深入探讨了在代码级别、系统架构和硬件资源方面的优化策略,并提供了实用的实践策略。文章还对接口性能监控与
构建低功耗通信解决方案:BT201模块蓝牙BLE集成实战

# 摘要
蓝牙低功耗(BLE)技术在近年来的物联网和可穿戴设备中扮演着核心角色。本文首先概述了BLE技术的基本概念和应用范围,然后深入探讨了BT201模块的硬件特性和配置,包括其硬件架构、固件和软件环境的搭建。文章接着分析了BT201模块如何集成BLE协议栈及其广播与扫描机制,并探讨了实现低
Arduino与物联网实战:构建智能设备的必备技能
# 摘要
本文旨在探讨Arduino在物联网领域的应用,从基础概念出发,深入到硬件与传感器的集成、网络通信、智能应用的构建,最后讨论项目优化与安全防护。首先介绍了Arduino开发板和传感器的基础知识,然后阐述了无线通信技术的选择和物联网平台的接入方法。通过智能家居控制系统、环境监测系统和远程控制机器人的实例,展示了如何利用Arduino构建智能应用。最后,本文还探讨了Arduino项目的代码优化、安全性考量以及部署与维护的最佳实践。
# 关键字
【工程问题流体动力学解决方案】:ANSYS CFX的实际应用案例
# 摘要
本文旨在全面介绍ANSYS CFX在流体动力学仿真中的应用,从软件基础到高级功能,涵盖了从理论概念到实际操作的整个流程。第一章提供了ANSYS CFX软件的简介和流体动力学的基本知识,为后续内容奠定基础。第二章详细介绍了ANSYS CFX仿真前处理的技巧,包括几何模型建立、网格划分、材料与边界条件的设置,以及初始条件和参
高级数据流图技巧:优化业务建模流程的7大策略

# 摘要
数据流图作为系统分析和设计的重要工具,用于描述信息系统的数据处理流程。本文从基础知识出发,详细探讨了数据流图的设计原则,包括层次结构设计、符号和规范,以及粒度控制。接着,文章聚焦于业务流程优化策略,包括流程简化与合并、流程标准化和流程自动化,并分析了其在业务连续性和效率提升方面的影响。第四章介绍了数据流图的分析与改进方法,包括静态分析、动态模拟以及持续改进措施。最后一章通过具体实践案
C语言错误处理的艺术:打造鲁棒性程序的关键
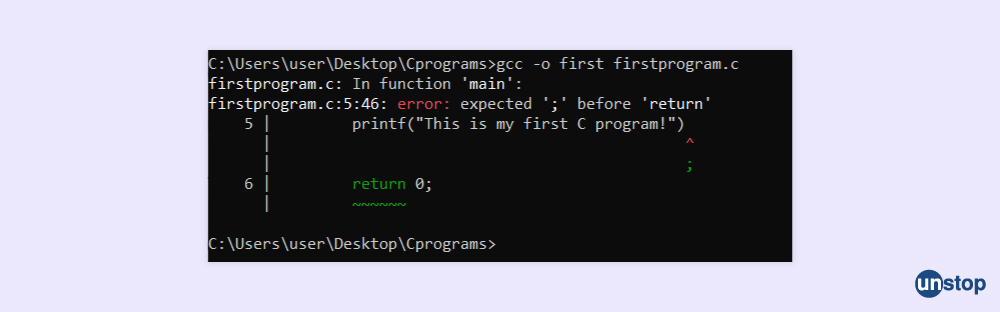
# 摘要
C语言作为编程领域的重要语言,其错误处理机制直接关系到软件的健壮性和稳定性。本文首先概述了C语言错误处理的重要性,接着详细介绍了错误检测机制,包括错误码、异常、断言、日志记录以及面向对象的错误处理方法。通过实践章节,本文进一步探讨了编写健壮函数、内存管理、文件操作及I/O错误处理的具体技巧。进阶技巧章节则涉及到错误处理与性能
频偏校正:数字通信系统的3大关键步骤及实践案例
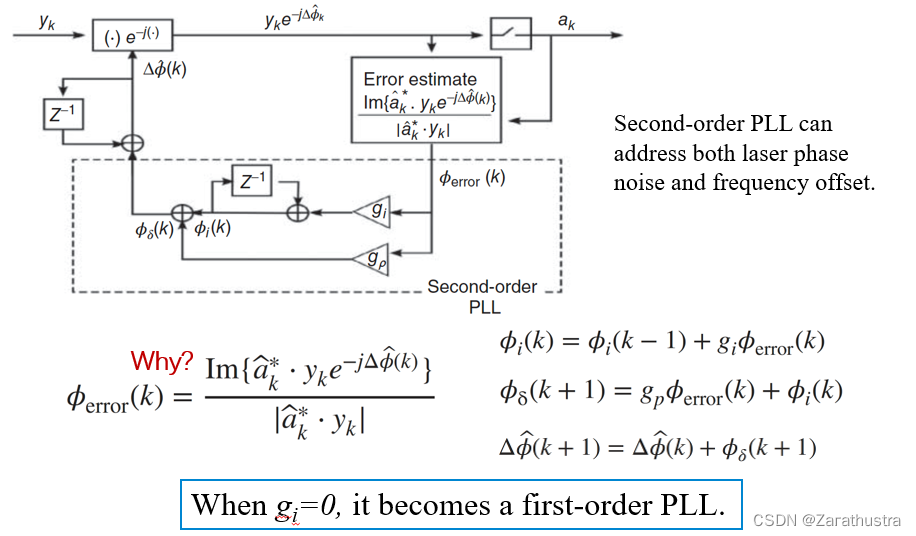
# 摘要
频偏校正是数字通信系统中确保通信质量的关键技术,涉及到信号同步、估计和补偿等多个步骤。本文从频偏的概念及其对通信系统的影响入手,深入分析了频偏产生的物理机制、影响因素及其对信号完整性和数据传输速率的负面影响。随后,本文探讨了频偏校正的理论方法、关键步骤和实践案例,包括时频同步技术、盲估计与非盲估计方法、载波恢复技术等。文章还针对实际系统中的应用和软件工具进行了分析,并讨论了频偏校正在硬件技术、软件算
网络隔离与优化:H3C-MSR路由器VLAN配置与管理的深度解析

# 摘要
本文介绍了VLAN的基础知识和网络隔离的原理,并对H3C-MSR路由器上的VLAN配置方法进行了详细介绍。文章首先解释了VLAN的概念、作用及其在网络中的重要性,随后深入探讨了H3C-MSR路由器的硬件架构与操作系统,以及如何进行基本的VLAN创建和接口分配。进一步,本文论述了VLAN间路由配置、优化策略,以及故障诊断和维护的高级配置与管
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )