【数据库设计核心要点】:为你的Python学生管理系统选择最佳存储方案
发布时间: 2024-12-20 14:14:21 阅读量: 7 订阅数: 6 

python基于Django的大学生就业信息管理系统源码数据库.doc
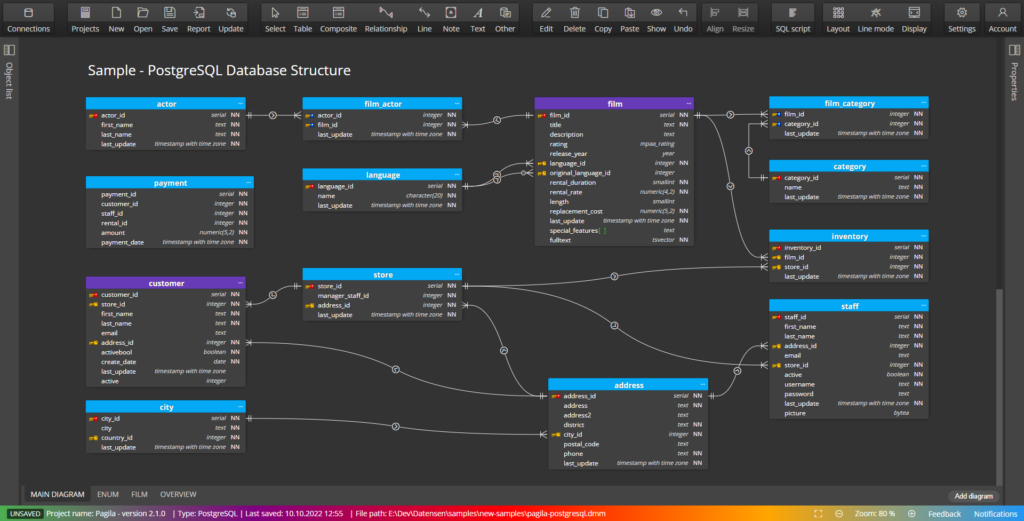
# 摘要
本文主要探讨了数据库设计的基础知识、关系型数据库与Python的交互、数据库设计理论与实践,以及数据库设计的高级应用。首先,介绍了数据库设计的基础知识,包括数据库规范化、性能优化和安全性策略。然后,深入探讨了关系型数据库与Python的交互,包括数据库连接、SQL基础以及ORM工具的使用。接下来,对数据库设计理论与实践进行了全面分析,包括规范化、性能优化和安全性策略。最后,讨论了数据库设计的高级应用,如复杂查询与数据分析、数据库迁移与版本控制以及大数据处理与数据库。本文旨在为Python学生管理系统存储方案的选择提供全面的参考和指导。
# 关键字
数据库设计;关系型数据库;Python交互;规范化;性能优化;安全性策略;数据分析;数据库迁移;大数据处理
参考资源链接:[黑龙江农垦大学学生管理系统Python课程设计实践](https://wenku.csdn.net/doc/5643qwbxie?spm=1055.2635.3001.10343)
# 1. 数据库设计基础知识
## 数据库设计的重要性
对于任何一个需要持久化存储数据的系统,数据库设计都是至关重要的环节。良好的数据库设计不仅能够保证数据的完整性、一致性,而且对系统的性能和未来的可维护性都有显著的影响。掌握数据库设计基础知识是构建高效、稳定、可扩展应用程序的基石。
## 从ER模型到关系模型
数据库设计通常以实体关系图(ER图)开始,其中实体和实体之间的关系被清晰地表达出来。随着设计流程的深入,实体转换为表,关系转换为表之间的关联,最终形成关系模型。理解这种转换对于将现实世界的需求转化为数据库结构至关重要。
## 数据库设计基本步骤
数据库设计可以分为以下几个基本步骤:
1. 需求分析:了解系统需要存储哪些类型的数据以及数据之间的关系。
2. 概念设计:绘制ER图来表示实体和它们之间的关系。
3. 逻辑设计:将概念模型转化为关系模型,确定表结构。
4. 物理设计:针对特定数据库管理系统优化表结构和索引。
5. 实施与测试:创建数据库,填充数据,并进行测试以确保设计满足需求。
本章的后续部分将深入探讨这些步骤,并提供实践中的最佳实践。
# 2. 关系型数据库与Python的交互
关系型数据库因其结构化、稳定的特性和成熟的生态,在企业级应用中一直占据着核心地位。Python作为一门深受开发者喜爱的编程语言,与关系型数据库的交互自然成为其重要应用之一。本章将深入探讨Python如何与关系型数据库进行交互,并分析如何在Python中高效地执行SQL语句、使用ORM工具等。
## 2.1 Python中的数据库连接
### 2.1.1 连接数据库的库选择
在Python中连接关系型数据库主要依赖于第三方库,这些库往往提供了数据库连接、查询、管理等功能。常见的库包括`psycopg2`(PostgreSQL)、`mysql-connector-python`(MySQL)和`sqlite3`(SQLite)。选择合适的库是进行数据库交互的第一步。
以MySQL数据库为例,我们可以选择`mysql-connector-python`库来实现连接。首先需要安装该库:
```bash
pip install mysql-connector-python
```
然后在Python代码中导入并使用它连接到MySQL数据库:
```python
import mysql.connector
# 连接到MySQL数据库
cnx = mysql.connector.connect(user='username', password='password', host='127.0.0.1', database='dbname')
# 创建一个cursor对象
cursor = cnx.cursor()
# 执行一个简单的SQL查询
cursor.execute("SELECT 'Hello World!'")
# 获取查询结果
result = cursor.fetchone()
# 打印结果
print(result)
# 关闭cursor和连接
cursor.close()
cnx.close()
```
### 2.1.2 数据库连接与管理技巧
数据库连接管理是开发过程中的一个重要环节,良好的管理可以提高代码的可读性、可维护性和性能。下面介绍一些管理技巧:
- 使用上下文管理器处理连接和游标,确保资源被正确释放:
```python
from mysql.connector import connect, Error
def query_data(query):
try:
connection = connect(user='username', password='password', host='127.0.0.1', database='dbname')
cursor = connection.cursor()
cursor.execute(query)
rows = cursor.fetchall()
cursor.close()
connection.close()
return rows
except Error as e:
print(f"Error: {e}")
return None
# 使用
data = query_data("SELECT * FROM table_name")
```
- 在多线程环境中正确管理数据库连接池,提高效率:
```python
from mysql.connector import pooling
# 创建连接池
dbconfig = {'user': 'username', 'password': 'password', 'host': '127.0.0.1', 'database': 'dbname'}
pool_name = "mypool"
pool_size = 5
cnxpool = pooling.MySQLConnectionPool(pool_name=pool_name,
pool_size=pool_size,
pool_reset_session=True,
**dbconfig)
# 获取连接
cnx = cnxpool.get_connection()
# 使用连接
cursor = cnx.cursor()
cursor.execute("SELECT * FROM table_name")
rows = cursor.fetchall()
cursor.close()
# 归还连接到连接池
cnx.close()
```
## 2.2 SQL基础与Python的结合
### 2.2.1 Python中的SQL语句执行
在Python中执行SQL语句通常有两种方式:直接执行和使用参数化查询。直接执行SQL语句简单直接,但容易引发SQL注入安全问题。
```python
cursor.execute("INSERT INTO table_name (column1, column2) VALUES (%s, %s)", (value1, value2))
```
### 2.2.2 参数化查询与安全性
参数化查询是执行SQL语句的推荐方式,它通过使用占位符(如`%s`)来防止SQL注入,提高安全性。
```python
# 使用参数化查询防止SQL注入
cursor.execute("SELECT * FROM table_name WHERE column1 = %s", (value1,))
```
## 2.3 ORM工具的使用与优势
### 2.3.1 ORM工具对比分析
对象关系映射(Object Relational Mapping,简称ORM)工具使得Python中的对象直接映射到关系数据库中的表,从而避免了直接使用SQL语句,提高了开发效率和安全性。
Python中的ORM工具如`SQLAlchemy`、`Django ORM`和`Peewee`各有特色,例如`SQLAlchemy`提供了非常强大的数据库抽象层,而`Django ORM`和`Peewee`则与各自框架的Web应用开发高度集成。
### 2.3.2 选择合适的ORM框架
选择合适的ORM框架需要考虑项目需求、团队熟悉度和框架特点。比如,对于复杂的应用程序,`SQLAlchemy`可能提供了更好的灵活性和控制力;而对于快速开发,`Django ORM`则因其内置的功能提供了便利。
```python
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
# 定义基类
Base = declarative_base()
# 定义一个映射类
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
nickname = Column(String)
# 创建引擎
engine = create_engine('mysql+mysqlconnector://username:password@localhost/dbname')
# 创建所有表
Base.metadata.create_all(engine)
# 创建Session类
Session = sessionmaker(bind=engine)
session = Session()
# 创建实例并添加到会话中
new_user = User(name='John', fullname='John Doe', nickname='johnny')
session.add(new_user)
session.commit()
# 关闭会话
session.close()
```
通过以上各节的介绍,我们可以看到Python与关系型数据库交互的多样性与丰富性。下一章我们将探索数据库设计理论与实践,进一步深化这一主题。
# 3. 数据库设计理论与实践
## 3.1 数据库规范化
数据库规范化是确保数据结构合理、高效、减少数据冗余的过程,它通过一系列规则将数据组织到不同的表中,保证数据的依赖性和完整性。
### 3.1.1 规范化理论介绍
数据库规范化理论提供了一系列的“范式”,用于指导如何设计表结构。常见的范式包括第一范式(1NF)、第二范式(2NF)、第三范式(3NF)以及更高阶的范式如BCNF(Boyce-Codd范式)、第四范式(4NF)和第五范式(5NF)。
- **第一范式(1NF)**要求表的每一列都是不可分割的基本数据项,即每个字段值都是原子性的。
- **第二范式(2NF)**建立在1NF之上,要求表中的非主键字段完全依赖于主键,而非主键的一部分。
- **第三范式(3NF)**建立在2NF之上,进一步要求非主键字段只能依赖于主键,消除传递依赖。
更高阶的范式适用于更复杂的数据依赖场景。例如,BCNF要求每个非平凡的函数依赖都必须包含一个候选键,而第四范式和第五范式则分别处理多值依赖和联合依赖。
### 3.1.2 实现规范化的步骤与技巧
实现规范化首先需要进行需求分析,明确数据如何被使用,并识别出所有的数据实体和它们之间的关系。接下来,将数据结构设计为符合第一范式的形式,然后逐步应用更高阶的范式规则,直到满足设计需求。
**具体步骤包括:**
1. **确定实体和关系**:识别出系统的实体类型,并确定实体间的一对一、一对多或多对多关系。
2. **创建初始表**:为每个实体类型创建一个表,并确保每个表符合1NF。
3. **消除部分函数依赖**:将表分割,使得所有非主键字段仅依赖于整个主键。
4. **消除传递依赖**:创建新的表以消除字段对非直接主键字段的依赖。
5. **应用更高阶的范式**:如果需要,继续对表进行分割和重组,以满足BCNF、4NF或5NF的要求。
**技巧:**
- **设计中间表**:对于多对多关系,创建中间表来关联两个表,以简化数据结构。
- **保持灵活性**:在设计时考虑未来可能的数据变化,确保表结构具有一定的灵活性以适应变化。
- **保持数据一致性**:应用规范化原则,确保数据的一致性和完整性。
在设计过程中,规范化的选择应结合实际应用场景考虑。过度规范化可能会导致性能下降,因此在实践中需要平衡规范化和反规范化(denormalization)来实现最优设计。
## 3.2 数据库性能优化
数据库性能优化是数据库设计的核心任务之一。优化措施可涉及数据库架构、查询执行计划、索引优化等多个层面。
### 3.2.1 索引的作用与优化
索引是数据库中用于加速数据检索的数据结构,它可以极大地提升查询性能,特别是在处理大量数据时。索引的常见类型包括B树索引、哈希索引、全文索引和空间数据索引等。
**索引优化的策略包括:**
- **选择合适的索引类型**:基于查询类型和数据分布选择索引类型。
- **构建复合索引**:对于经常一起使用的列构建复合索引,有助于提升查询效率。
- **定期维护索引**:通过重建和重新组织索引来消除碎片,保持索引的最佳性能。
- **避免过度索引**:虽然索引可以加快查询,但过多索引会降低更新操作的性能,并增加存储空间的使用。
### 3.2.2 查询优化与存储过程
查询优化主要涉及编写高效的SQL查询语句,减少不必要的表扫描和数据排序,避免使用复杂的子查询和全表扫描,使用连接(JOIN)代替子查询来减少数据处理量。
**优化技术包括:**
- **使用EXPLAIN分析**:使用EXPLAIN关键字来查看查询的执行计划,找到瓶颈并进行优化。
- **减少数据检索量**:只选择需要的列而不是使用SELECT *。
- **使用存储过程**:通过预编译的代码块来提升复杂业务逻辑的执行效率。
通过深入理解数据库的工作机制,可以更好地使用索引和编写高效的查询语句,从而使数据库性能得到显著提升。
## 3.3 数据库的安全性策略
数据库安全性是保护数据不被未授权访问或破坏的措施。安全性策略是数据库管理的重要组成部分,需要从数据备份、恢复机制以及权限管理等方面进行综合考虑。
### 3.3.1 数据备份与恢复机制
数据备份是复制数据库数据的过程,以防止数据丢失或损坏。恢复机制是将备份数据还原到数据库系统中,确保业务连续性。
**备份策略:**
- **完全备份**:定期备份数据库中所有的数据。
- **增量备份**:仅备份自上一次备份以来发生变化的数据,节省时间和存储空间。
- **差异备份**:备份自上一次完全备份以来发生变化的数据。
**恢复策略:**
- **恢复到特定时间点**:如果系统崩溃,恢复到最近的一个完整状态。
- **日志文件恢复**:使用事务日志文件恢复到故障发生前的最新状态。
### 3.3.2 数据库权限管理和监控
权限管理是确保数据安全的关键措施,它涉及对用户访问数据库的控制,包括读、写、修改和删除数据的权限。
**权限管理策略:**
- **角色划分**:定义不同的用户角色,为每个角色分配不同的访问权限。
- **最小权限原则**:只授予用户完成任务所必需的最小权限集。
- **密码策略**:实施强密码策略,定期更换密码。
- **审计日志**:记录用户对数据库的访问和操作,以便于问题追踪和安全审计。
数据库监控则是实时跟踪数据库的性能和安全状况,可以使用数据库管理系统自带的监控工具,或第三方监控工具来实现。
通过实施以上策略,可以有效地保障数据库系统的安全性和稳定性。在实际操作中,安全策略的制定应基于业务需求、数据敏感性和合规性要求综合考量。
以上是对本章节关于数据库设计理论与实践的内容概述。在接下来的文章中,我们将深入了解数据库规范化、性能优化和安全性策略的更详细实践应用。
# 4. Python学生管理系统存储方案选择
## 4.1 存储方案的评估标准
### 4.1.1 性能需求分析
在选择适合的存储方案时,性能需求分析是一个关键环节。不同场景下,对数据库的读写速度、并发处理能力以及事务管理的要求会有所不同。在学生管理系统中,我们通常需要处理大量学生信息的增删改查操作,这些操作的性能直接影响系统响应速度和用户体验。
评估性能时,我们需要关注以下几个方面:
- **读写速度**:系统在处理数据时,对于读操作和写操作的响应时间,尤其是在高峰时段的表现。
- **并发能力**:系统能否有效地处理多用户同时进行的数据库操作,这对于系统的稳定性至关重要。
- **事务管理**:数据库管理系统(DBMS)在处理事务时的性能,特别是对于需要保证数据一致性的操作。
- **索引优化**:通过建立合理的索引,可以显著提升查询效率,减少数据检索的时间。
### 4.1.2 可扩展性考量
随着学生人数的增加和数据量的膨胀,学生管理系统对于数据库的可扩展性要求也越来越高。可扩展性考量包括纵向扩展(提升单个数据库服务器的处理能力)和横向扩展(增加数据库服务器的数量)。
在评估可扩展性时,以下几个方面不容忽视:
- **硬件升级**:服务器硬件的升级能够提升数据库的处理能力,但成本较高,且存在物理限制。
- **读写分离**:通过将查询操作(读)和数据修改操作(写)分到不同的服务器上,可以在不增加单个服务器负担的情况下提高系统的处理能力。
- **分片与分区**:通过将数据分散存储在不同的数据库分片中,可以提高数据的读写效率,并能平滑地增加数据库容量。
- **云数据库服务**:利用云数据库服务可以动态地扩展数据库资源,根据负载自动调整计算和存储资源。
## 4.2 关系型数据库方案对比
### 4.2.1 MySQL、PostgreSQL与SQLite比较
在关系型数据库领域,MySQL、PostgreSQL和SQLite是三种广泛使用的数据库管理系统。它们各有特点,在不同的应用场景下表现各有优劣。
**MySQL**:
- **优点**:MySQL是高性能、高可靠性的关系型数据库,广泛应用在互联网企业中。它的社区支持强大,拥有丰富的插件和工具。
- **缺点**:尽管性能优秀,但在复杂的查询和大数据量下可能会出现性能瓶颈。
**PostgreSQL**:
- **优点**:PostgreSQL是一个全功能的开源关系型数据库,支持复杂的数据类型,如JSON、数组等。它以稳定性和强大的事务支持闻名。
- **缺点**:相比MySQL,PostgreSQL的扩展性和性能在某些情况下略逊一筹,尤其是在高并发场景。
**SQLite**:
- **优点**:SQLite是一个轻量级的关系型数据库,不需要单独的服务器进程,便于在应用程序中嵌入和部署。
- **缺点**:由于设计简单,SQLite不适合用于大规模的并发处理和存储大量数据。
### 4.2.2 特定场景下的数据库选择
选择合适的数据库,不仅要考虑其通用性能,还要根据特定的应用场景进行考量。
对于**高并发读写**的应用,如在线教育平台,可能需要一个能够支持大规模并发操作的数据库。在这里,MySQL可能是更好的选择,因为它提供了较为全面的并发控制功能。
对于需要**处理复杂查询和大量数据**的场景,比如学生信息分析和报告生成,PostgreSQL的复杂数据类型支持和强大的事务处理能力,使其成为更合适的选择。
对于**轻量级应用**,如小型学校的信息查询系统,SQLite由于其嵌入式特性可以大大简化部署和维护工作,是理想的解决方案。
## 4.3 NoSQL与Python的结合
### 4.3.1 NoSQL数据库简介
NoSQL(Not Only SQL)数据库是一种非关系型的、分布式的数据库,主要用于处理结构化数据、半结构化数据或非结构化数据。其主要优势在于水平扩展能力、灵活的数据模型以及高性能。
常见的NoSQL数据库类型包括键值存储(如Redis)、文档存储(如MongoDB)、列式存储(如Cassandra)和图数据库(如Neo4j)。
### 4.3.2 在Python中使用MongoDB
MongoDB是一个基于文档的NoSQL数据库,由于其灵活的存储模式和高性能,它在多种应用场景中都很受欢迎。下面是在Python中使用MongoDB的一个例子。
首先,你需要安装MongoDB的Python驱动程序:
```bash
pip install pymongo
```
接着,可以使用以下Python代码连接到MongoDB数据库并执行基本操作:
```python
from pymongo import MongoClient
# 连接到本地MongoDB实例
client = MongoClient('localhost', 27017)
# 连接到数据库(如果数据库不存在,将会自动创建)
db = client['student_management']
# 连接到集合(如果集合不存在,将会自动创建)
students = db.students
# 插入一个文档
student = {
"name": "John Doe",
"age": 20,
"major": "Computer Science",
"grades": [85, 93, 90]
}
students.insert_one(student)
# 查询文档
query = {"major": "Computer Science"}
results = students.find(query)
for result in results:
print(result)
# 更新文档
students.update_one(query, {"$set": {"age": 21}})
```
在使用MongoDB时,需要特别注意的是,由于其灵活的数据模型,对于数据的一致性和完整性要求较高的场景需要谨慎使用。另外,为了保证数据的可维护性,合理地设计文档结构和索引策略也是必要的。
在实际项目中,NoSQL数据库往往与关系型数据库联合使用,以满足系统的多方面需求。例如,使用关系型数据库来处理事务和复杂的关联查询,使用NoSQL数据库来处理大规模的非关系型数据操作。
### 4.3.3 代码逻辑解读
在上面的代码示例中,我们首先导入了`pymongo`库,并创建了一个`MongoClient`实例来连接到本地运行的MongoDB服务器。然后,我们通过指定的名称连接到一个数据库,并在该数据库下创建或连接到一个集合。
我们定义了一个学生信息的文档,并使用`insert_one`方法将其添加到集合中。接着,我们使用`find`方法查询了计算机科学专业的所有学生,并遍历打印了查询结果。
最后,我们使用`update_one`方法更新了查询到的第一个文档,将学生的年龄更改为21岁。这个操作展示了如何通过Python代码对MongoDB进行读取、更新等操作。
### 4.3.4 数据库选择的注意事项
在选择使用NoSQL数据库时,还需要注意以下几点:
- **数据模型设计**:根据应用场景灵活设计数据模型,避免过度规范化,同时也要注意文档的大小和复杂度。
- **一致性和事务**:NoSQL数据库往往采用最终一致性模型,对于某些需要ACID属性的场景需要特别处理。
- **数据备份与恢复**:制定合适的数据备份策略和恢复流程,以防止数据丢失。
- **索引优化**:合理的索引可以显著提升查询效率,减少数据检索的时间。
综上所述,在Python学生管理系统的存储方案选择上,需要综合考量性能需求、可扩展性以及数据模型的匹配度等因素,从而选择最适合项目需求的数据库技术。
# 5. 数据库设计高级应用
在信息技术不断进步的今天,对数据库的高级应用需求也日益增长。本章将深入探讨复杂查询与数据分析、数据库迁移与版本控制以及大数据处理与数据库等方面的内容,让读者能更好地应用和优化数据库系统。
## 5.1 复杂查询与数据分析
### 5.1.1 高级查询技术
在数据库中执行复杂查询是数据分析的关键。数据库管理系统(DBMS)提供了强大的SQL语句支持,可以进行多表联结、子查询、分组、聚合等操作。这些操作能让我们从数据集中提取出有价值的信息。
```sql
-- SQL示例:联结查询
SELECT Students.name, Grades.subject, Grades.grade
FROM Students
JOIN Grades ON Students.id = Grades.student_id;
```
### 5.1.2 利用Python进行数据统计与分析
Python是数据科学领域的重要工具之一,Pandas库则提供了强大的数据分析能力。通过Pandas,我们可以轻松地从数据库中提取数据,进行清洗、分析和可视化。
```python
import pandas as pd
from sqlalchemy import create_engine
# 创建数据库引擎
engine = create_engine('sqlite:///example.db')
# 从数据库中查询数据
df = pd.read_sql_query("SELECT * FROM Students", engine)
# 数据分析
df.groupby('Class').size().plot(kind='bar')
```
## 5.2 数据库迁移与版本控制
### 5.2.1 数据库迁移策略
随着系统的发展,数据库结构需要不断更新和升级。数据库迁移是指通过一定的手段和流程,将数据从一个数据库转换到另一个数据库的过程。迁移策略包括版本控制、数据完整性保持和迁移脚本编写等。
```python
# 使用Alembic进行数据库迁移(示例)
from alembic import command
from alembic.config import Config
# 创建迁移配置对象
config = Config('alembic.ini')
# 生成迁移脚本
command.revision(config, message='Initial migration.')
```
### 5.2.2 版本控制工具的运用
在数据库迁移中,版本控制工具(如Git)能帮助我们管理数据库架构的变更历史。通过版本控制,可以回滚到之前的版本,也可以比较不同版本之间的差异,从而保证数据结构的正确性和完整性。
## 5.3 大数据处理与数据库
### 5.3.1 大数据处理场景下的存储方案
在大数据场景下,传统的关系型数据库可能在性能和可扩展性上面临挑战。选择适合大数据处理的存储方案是关键,比如分布式数据库、NoSQL数据库等。
### 5.3.2 在Python中处理大数据
Python处理大数据的能力得益于其丰富的库支持。Pandas、NumPy等库可用于小到中等规模的数据处理,而Dask、Vaex等库则扩展到大规模数据集。
```python
import dask.dataframe as dd
# 从文件读取数据
df = dd.read_csv('large_dataset.csv')
# 基本的数据操作
sum_of_column = df['column_name'].sum().compute()
```
在本章中,我们详细探讨了如何利用Python进行复杂查询和数据分析、数据库迁移与版本控制的最佳实践,以及大数据处理在数据库中的应用。每个知识点都有具体的代码示例和操作步骤,以帮助读者深入理解并应用于实际项目中。
在下一章中,我们将对整个数据库设计流程进行回顾和总结,同时探讨未来数据库技术的发展趋势。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Omni-Peek教程】:掌握网络性能监控与优化的艺术

# 摘要
网络性能监控与优化是确保网络服务高效运行的关键环节。本文首先概述了网络性能监控的重要性,并对网络流量分析技术以及网络延迟和丢包问题进行了深入分析。接着,本文介绍了Omni-Peek工具的基础操作与实践应用,包括界面介绍、数据包捕获与解码以及实时监控等。随后,文章深入探讨了网络性能问题的诊断方法,从应用层和网络层两方面分析问题,并探讨了系统资源与网络性能之间的关系。最后,提出了网络性能优
公钥基础设施(PKI)深度剖析:构建可信的数字世界
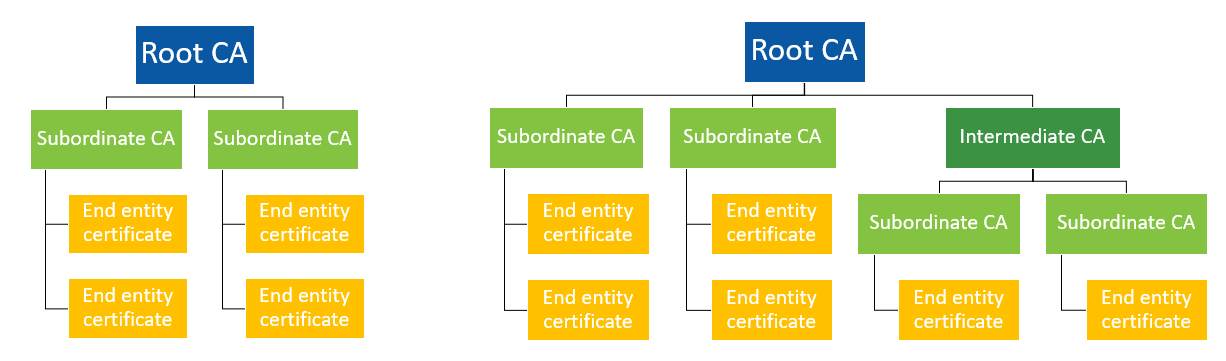
# 摘要
公钥基础设施(PKI)是一种广泛应用于网络安全领域的技术,通过数字证书的颁发与管理来保证数据传输的安全性和身份验证。本文首先对PKI进行概述,详细解析其核心组件包括数字证书的结构、证书认证机构(CA)的职能以及证书颁发和撤销过程。随后,文章探讨了PKI在SSL/TLS、数字签名与身份验证、邮件加密等领域的应用实践,指出其在网络安全中的重要性。接着,分析了PKI实施过程中的
硬件工程师的挑战:JESD22-A104F温度循环测试中的故障诊断与解决方案

# 摘要
JESD22-A104F温度循环测试是电子组件可靠性评估的重要方法,本文概述了其原理、故障分析、实践操作指南及解决方案。文中首先介绍了温度循环测试的理论基础,阐释了测试标准和对电子组件影响的原理。接着,分析了硬件故障类型及其诊断方法,强调了故障诊断工具的应用。第三章深入探讨了测试设备的配置、测试流程及问题应对策略。第四章则集中于
机器人动力学计算基础:3种方法利用Robotics Toolbox轻松模拟

# 摘要
本论文探讨了机器人动力学计算的基础知识,并对Robotics Toolbox的安装、配置及其在机器人建模和动力学模拟中的应用进行了详细介绍。通过对机器人连杆表示、运动学计算方法的阐述,以及Robotics Toolbox功能的介绍,本文旨在提供机器人建模的技术基础和实践指南。此外,还比较了基于拉格朗日方程、牛顿-欧拉方法和虚功原理的三种动力学模拟方法,并
【AST2400兼容性分析】:与其他硬件平台的对比优势

# 摘要
本文全面探讨了AST2400硬件平台的兼容性问题,从兼容性理论基础到与其他硬件平台的实际对比分析,再到兼容性实践案例,最后提出面临的挑战与未来发展展望。AS
【线性规划在电影院座位设计中的应用】:座位资源分配的黄金法则
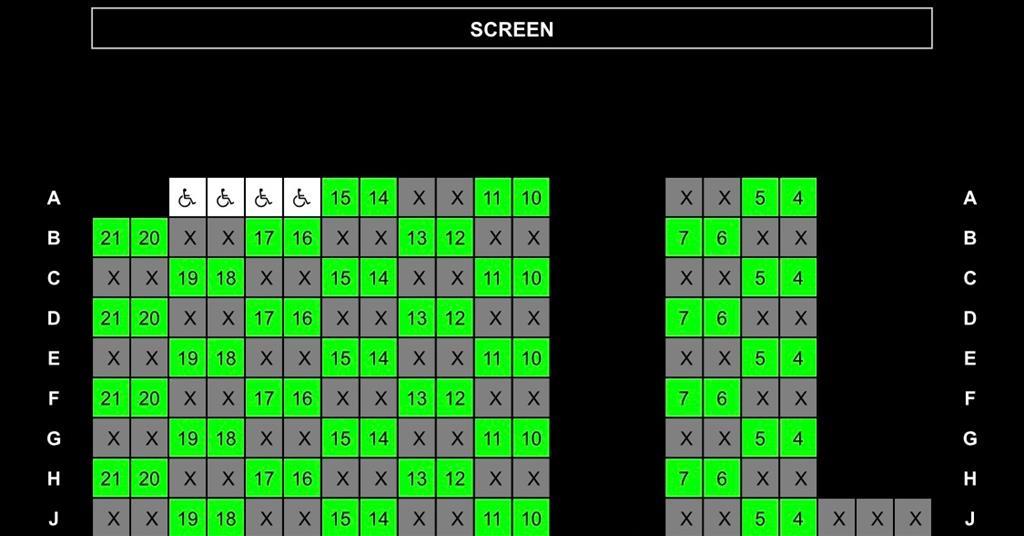
# 摘要
本文系统介绍了线性规划的基本概念、数学基础及其在资源分配中的应用,特别关注了电影院座位设计这一具体案例。文章首先概述了线性规划的重要性,接着深入分析了线性规划的理论基础、模型构建过程及求解方法。然后,本文将线性规划应用于电影院座位设计,包括资源分配的目标与限制条件,以及实际案例的模型构建与求解过程。文章进一步讨论
【语义分析与错误检测】:编译原理中的5大常见错误处理技巧

# 摘要
语义分析与错误检测是编译过程中的关键步骤,直接影响程序的正确性和编译器的健壮性。本文从编译器的错误处理机制出发,详细探讨了词法分析、语法分析以及语义分析中错误的
【PCB Layout信号完整性:深入分析】
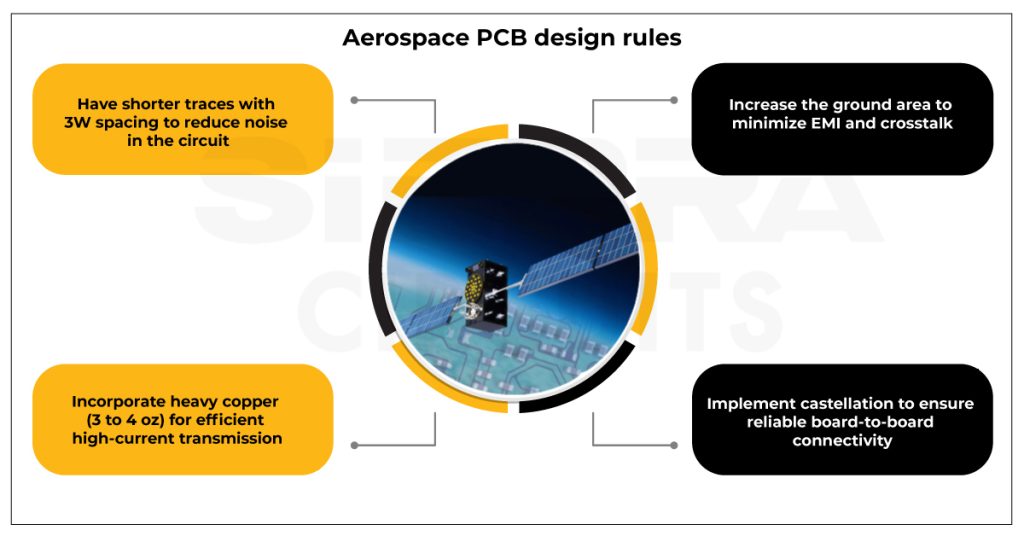
# 摘要
本文深入探讨了PCB布局与信号完整性之间的关系,并从理论基础到实验测试提供了全面的分析。首先,本文阐述了信号完整性的关键概念及其重要性,包括影响因素和传输理论基础。随后,文章详细介绍了PCB布局设计的实践原则,信号层与平面设计技巧以及接地与电源设计的最佳实践。实验与测试章节重点讨论了信号完整性测试方法和问题诊断策略。最后,文章展望了新兴技术
【文件和参数精确转换】:PADS数据完整性提升的5大策略
# 摘要
在数字化时代背景下,文件和参数的精确转换对保持数据完整性至关重要。本文首先探讨了数据完整
MapReduce深度解析:如何从概念到应用实现精通

# 摘要
MapReduce作为一种分布式计算模型,在处理大数据方面具有重要意义。本文首先概述了MapReduce的基本概念及其计算模型,随后深入探讨了其核心理论,包括编程模型、数据流和任务调度、以及容错机制。在实践应用技巧章节中,本文详细介绍了Hadoop环境的搭建、MapReduce程序的编写和性能优化,并通过具体案例分析展示了MapReduce在数据分析中的应用。接着,文章探讨了MapR
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )