使用Pig进行简化的数据流处理
发布时间: 2024-01-16 23:09:58 阅读量: 57 订阅数: 21 

大数据之pig 命令
# 1. 理解Pig和数据流处理
Pig是一个基于Hadoop的平台,用于处理大规模数据集的高级编程接口。它提供了一种称为Pig Latin的脚本语言,利用这种语言可以快速、简单地进行数据流处理和分析。在本章中,我们将深入了解Pig和数据流处理的基本原理,以及Pig在数据处理中的作用。
## 1.1 什么是Pig
Apache Pig是一个用于大规模数据分析的平台,它提供了一种高级的数据流处理语言Pig Latin,这种语言使得用户可以轻松地对大规模数据集进行处理和分析。Pig将数据流处理任务抽象成一系列简单的操作,用户只需要关注数据处理的逻辑,而不需要编写复杂的MapReduce程序。
## 1.2 数据流处理的基本原理
数据流处理是指将数据视为连续的数据流,在数据流中进行实时处理和分析。Pig通过将复杂的数据流处理任务拆分成一系列简单的操作,实现对数据流的高效处理。这些操作包括数据加载、过滤、转换、聚合等,可以帮助用户快速构建数据处理流程。
## 1.3 Pig在数据流处理中的作用
Pig作为数据流处理的平台,提供了丰富的数据处理操作和函数库,同时也支持用户自定义函数和扩展。通过Pig,用户可以方便地进行数据清洗、转换、聚合等操作,快速地构建数据处理流程,并且可以利用Pig的优化特性来提高数据处理的性能。
在接下来的章节中,我们将深入学习Pig的安装配置、数据流处理基础、数据清洗和转换、性能优化,以及实际案例分析。
# 2. 安装和配置Pig环境
在开始使用Pig进行数据流处理之前,我们首先需要下载和安装Pig,并配置好相应的运行环境。下面将详细介绍如何进行这些操作。
### 2.1 下载和安装Pig
首先,我们需要下载Pig的安装文件。你可以在Pig的官方网站([pig.apache.org](http://pig.apache.org))上找到最新的发布版本。选择适用于你操作系统的二进制文件,下载并解压到你想要安装的目录。
以Linux系统为例,以下是下载和解压Pig的步骤:
```shell
# 下载Pig二进制文件
wget https://downloads.apache.org/pig/pig-0.17.0/pig-0.17.0.tar.gz
# 解压文件
tar -xzvf pig-0.17.0.tar.gz
# 将解压后的目录移动到你想要安装的位置
sudo mv pig-0.17.0 /opt/pig
```
### 2.2 配置Pig运行环境
安装完成后,我们需要配置Pig的运行环境变量,以便能够在任何位置使用Pig命令。
首先,打开终端并进入你的用户主目录(通常是`/home/[username]`或`/Users/[username]`)。编辑`.bashrc`文件(如果不存在则创建它):
```shell
vi .bashrc
```
在文件末尾添加以下内容:
```shell
# Set Pig home
export PIG_HOME=/opt/pig
# Add Pig to PATH
export PATH=$PATH:$PIG_HOME/bin
```
保存文件并退出编辑器。然后,运行以下命令使配置生效:
```shell
source .bashrc
```
现在,你可以在任何位置运行`pig`命令来启动Pig。
### 2.3 运行第一个Pig脚本
现在,我们已经成功安装和配置了Pig环境。接下来,让我们来运行一个简单的Pig脚本,以验证安装是否正确。
首先,创建一个文本文件,命名为`example.pig`,并将以下代码复制粘贴进去:
```pig
-- example.pig
data = LOAD 'input.txt' USING PigStorage(',');
filtered_data = FILTER data BY $0 == 'Apple';
result = FOREACH filtered_data GENERATE $0, $2;
STORE result INTO 'output.txt' USING PigStorage(',');
```
上述脚本的功能是从名为`input.txt`的文件中加载数据,然后过滤出第一列为'Apple'的记录,最后将第一列和第三列的数据存储到`output.txt`文件中。
确保你已经准备好了`input.txt`文件,并且文件中包含一些逗号分隔的数据。
接下来,在终端中切换到包含`example.pig`文件的目录,并运行以下命令:
```shell
pig example.pig
```
如果一切配置正确,你将看到Pig开始运行,并显示运行过程中的日志信息。
最后,检查`output.txt`文件,你将看到符合过滤条件的数据已经被存储到了该文件中。
通过以上步骤,我们已经成功安装、配置和运行了第一个Pig脚本。现在,你可以开始使用Pig进行数据流处理了。
在本章中,我们介绍了如何下载、安装和配置Pig环境,并演示了如何运行一个简单的Pig脚本。下一章节将深入讲解Pig的数据流处理基础知识和常用操作。
# 3. Pig数据流处理基础
Pig数据流处理基础章节主要介绍Pig Latin语言概述、Pig数据模型和常用数据流处理操作。
#### 3.1 Pig Latin语言概述
Pig Latin是一种类SQL的语言,用于描述数据流处理操作。它提供了简洁的语法来执行数据清洗、转换和分析等操作。Pig Latin脚本通过Pig引擎进行解析和执行,将用户定义的数据流处理操

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Hadoop编程:大数据处理与Hadoop分布式计算》是一本全面介绍Hadoop和大数据处理的专栏。通过各个文章的深入解析,读者将了解Hadoop生态系统的核心组件以及如何使用HDFS进行大规模数据存储与管理。专栏还探讨了MapReduce编程的基础知识以及如何使用Pig进行简化的数据流处理。读者还将了解到Hadoop数据导入和导出的常用工具和技术,以及使用Apache Spark进行基于内存的大数据处理和实时数据处理。此外,专栏还介绍了HBase作为大规模分布式NoSQL数据库的应用,以及YARN作为Hadoop的资源管理和作业调度的重要组件。还有关于Hadoop高可用性配置与故障处理、通过Hadoop处理结构化和非结构化数据、Hadoop与机器学习的结合、提高Hadoop性能的优化技巧、使用Hadoop进行图数据分析以及Spark与深度学习等方面的内容。无论是对于想要入门Hadoop和大数据处理的初学者,还是对已经有一定经验的专业人士,这本专栏都将是他们学习和了解Hadoop及大数据处理的宝贵资源。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
扇形菜单设计原理

# 摘要
扇形菜单作为一种创新的界面设计,通过特定的布局和交互方式,提升了用户在不同平台上的导航效率和体验。本文系统地探讨了扇形菜单的设计原理、理论基础以及实际的设计技巧,涵盖了菜单的定义、设计理念、设计要素以及理论应用。通过分析不同应用案例,如移动应用、网页设计和桌面软件,本文展示了扇形菜单设计的实际效果,并对设计过程中的常见问题提出了改进策略。最后,文章展望了扇形菜单设计的未来趋势,包括新技术的应用和设计理念的创新。
# 关键字
扇形菜
传感器在自动化控制系统中的应用:选对一个,提升整个系统性能
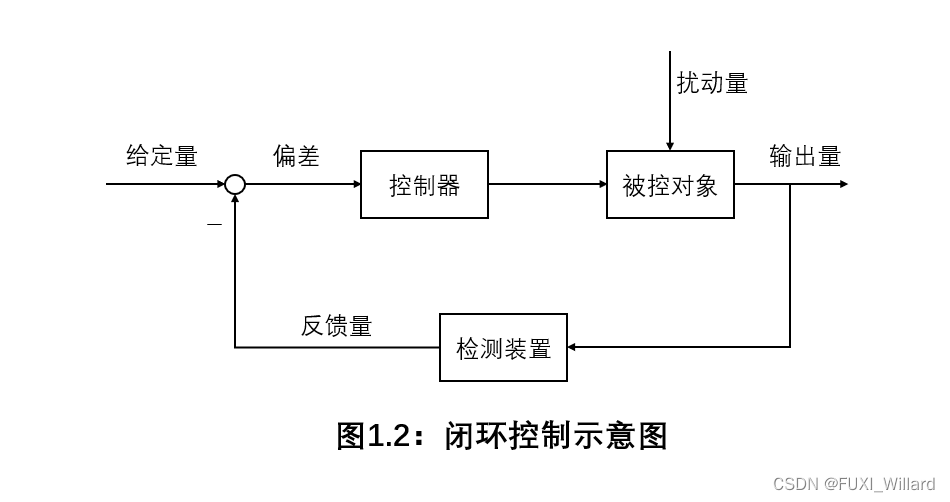
# 摘要
传感器在自动化控制系统中发挥着至关重要的作用,作为数据获取的核心部件,其选型和集成直接影响系统的性能和可靠性。本文首先介绍了传感器的基本分类、工作原理及其在自动化控制系统中的作用。随后,深入探讨了传感器的性能参数和数据接口标准,为传感器在控制系统中的正确集成提供了理论基础。在此基础上,本文进一步分析了传感器在工业生产线、环境监测和交通运输等特定场景中的应用实践,以及如何进行
CORDIC算法并行化:Xilinx FPGA数字信号处理速度倍增秘籍

# 摘要
本文综述了CORDIC算法的并行化过程及其在FPGA平台上的实现。首先介绍了CORDIC算法的理论基础和并行计算的相关知识,然后详细探讨了Xilinx FPGA平台的特点及其对CORDIC算法硬件优化的支持。在此基础上,文章具体阐述了CORDIC算法
C++ Builder调试秘技:提升开发效率的十项关键技巧
# 摘要
本文详细介绍了C++ Builder中的调试技术,涵盖了从基础知识到高级应用的广泛领域。文章首先探讨了高效调试的准备工作和过程中的技巧,如断点设置、动态调试和内存泄漏检测。随后,重点讨论了C++ Builder调试工具的高级应用,包括集成开发环境(IDE)的使用、自定义调试器及第三方工具的集成。文章还通过具体案例分析了复杂bug的调试、
MBI5253.pdf高级特性:优化技巧与实战演练的终极指南
# 摘要
MBI5253.pdf作为研究对象,本文首先概述了其高级特性,接着深入探讨了其理论基础和技术原理,包括核心技术的工作机制、优势及应用环境,文件格式与编码原理。进一步地,本文对MBI5253.pdf的三个核心高级特性进行了详细分析:高效的数据处理、增强的安全机制,以及跨平台兼容性,重点阐述了各种优化技巧和实施策略。通过实战演练案
【Delphi开发者必修课】:掌握ListView百分比进度条的10大实现技巧

# 摘要
本文详细介绍了ListView百分比进度条的实现与应用。首先概述了ListView进度条的基本概念,接着深入探讨了其理论基础和技术细节,包括控件结构、数学模型、同步更新机制以及如何通过编程实现动态更新。第三章
先锋SC-LX59家庭影院系统入门指南
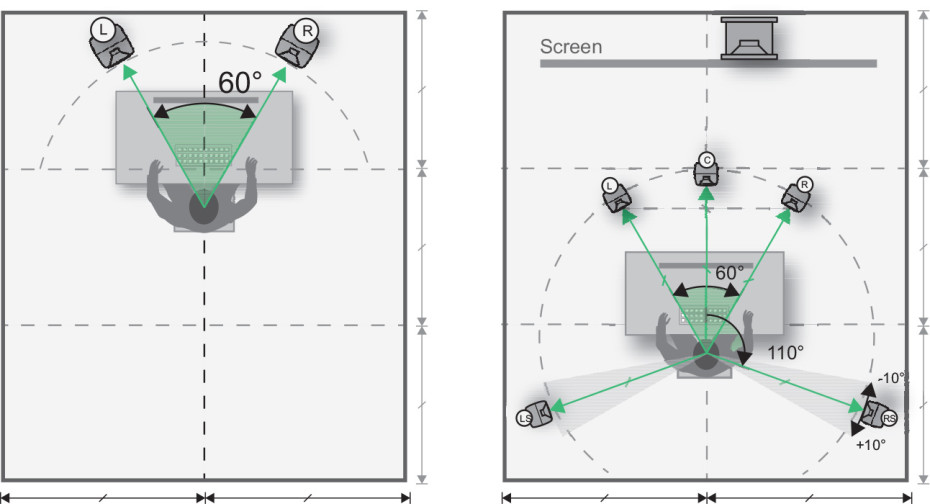
# 摘要
本文全面介绍了先锋SC-LX59家庭影院系统,从基础设置与连接到高级功能解析,再到操作、维护及升级扩展。系统概述章节为读者提供了整体架构的认识,详细阐述了家庭影院各组件的功能与兼容性,以及初始设置中的硬件连接方法。在高级功能解析部分,重点介绍了高清音频格式和解码器的区别应用,以及个
【PID控制器终极指南】:揭秘比例-积分-微分控制的10个核心要点

# 摘要
PID控制器作为工业自动化领域中不可或缺的控制工具,具有结构简单、可靠性高的特点,并广泛应用于各种控制系统。本文从PID控制器的概念、作用、历史发展讲起,详细介绍了比例(P)、积分(I)和微分(D)控制的理论基础与应用,并探讨了PID
【内存技术大揭秘】:JESD209-5B对现代计算的革命性影响
# 摘要
本文详细探讨了JESD209-5B标准的概述、内存技术的演进、其在不同领域的应用,以及实现该标准所面临的挑战和解决方案。通过分析内存技术的历史发展,本文阐述了JESD209-5B提出的背景和核心特性,包括数据传输速率的提升、能效比和成本效益的优化以及接口和封装的创新。文中还探讨了JESD209-5B在消费电子、数据中心、云计算和AI加速等领域的实
【install4j资源管理精要】:优化安装包资源占用的黄金法则

# 摘要
install4j是一款强大的多平台安装打包工具,其资源管理能力对于创建高效和兼容性良好的安装程序至关重要。本文详细解析了install4j安装包的结构,并探讨了压缩、依赖管理以及优化技术。通过对安装包结构的深入理解,本文提供了一系列资源文件优化的实践策略,包括压缩与转码、动态加载及自定义资源处理流程。同时
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )