Lasso回归参数调优精要:【网格搜索与随机搜索】的策略对比(调优技巧+案例对比)
发布时间: 2024-11-24 04:13:29 阅读量: 47 订阅数: 42 

# 1. Lasso回归基本概念和数学原理
Lasso回归,全名Least Absolute Shrinkage and Selection Operator Regression,是一种用于回归分析的线性模型,它通过引入L1正则化(即参数绝对值之和)来实现变量选择和正则化,其目的是增强模型的预测准确性和解释性。该方法由Robert Tibshirani在1996年首次提出,特别适用于具有大量特征的情况,它能够在拟合数据的同时进行特征选择,自动将一些系数压缩到零,从而达到选择变量的效果。
从数学角度来看,Lasso回归试图解决以下优化问题:
\[
\min_{\beta} \left\{ \frac{1}{2n} \sum_{i=1}^n (y_i - \sum_{j=1}^p x_{ij}\beta_j)^2 + \lambda \sum_{j=1}^p |\beta_j| \right\}
\]
其中,\( y_i \) 表示因变量,\( x_{ij} \) 表示第 \( j \) 个特征的第 \( i \) 个观测值,\( \beta_j \) 是模型参数,\( \lambda \) 是正则化参数(常通过交叉验证来选择),\( p \) 是特征的总数。
Lasso的关键在于它为每个模型参数引入了一个非零的惩罚项,这导致了参数估计的收缩。当 \( \lambda \) 足够大时,某些参数 \( \beta_j \) 可能会收缩到零,这相当于在模型中排除了这些特征。这一特性使得Lasso回归成为处理高维数据集的有效工具,尤其是在特征选择和稀疏模型构建方面。
# 2. 参数调优基础与网格搜索策略
## 2.1 参数调优的重要性
### 2.1.1 模型性能与参数的关系
在机器学习模型中,参数是影响模型性能的关键因素。在Lasso回归模型中,正则化参数λ的选择尤为关键,它控制了模型的复杂度和过拟合的风险。模型参数的不同取值会直接影响模型对数据的拟合程度,一个好的参数可以提高模型的预测准确性,减少模型对训练数据的依赖,使得模型具备更好的泛化能力。因此,模型参数的调整是一个重要环节,正确的参数能够帮助模型在保留重要特征的同时去除噪声,实现更好的拟合效果。
### 2.1.2 正则化参数对模型的影响
Lasso回归是一种带有L1正则化的线性回归模型,其通过在损失函数中加入L1范数项来实现特征选择和正则化。正则化参数λ的大小决定了模型惩罚力度的强弱。λ值较大时,惩罚项对模型影响更大,模型可能会趋向于简单,但过度简化会导致模型无法捕获数据的真实结构,从而影响模型的性能。反之,较小的λ值可能导致模型复杂度过高,容易过拟合,即在训练集上表现良好而在未知数据上表现差。因此,恰当地选择λ是Lasso回归模型调优的关键。
## 2.2 网格搜索策略详解
### 2.2.1 网格搜索的基本工作原理
网格搜索是一种暴力的参数优化方法,通过构建一个参数的网格,然后在这个网格上穷举所有参数组合,并对每个组合使用交叉验证来进行评估。具体来说,它首先定义一个参数网格,然后逐一尝试每个网格点上的参数组合,评估每种组合下的模型性能,最终选择最佳的参数组合。
### 2.2.2 实施网格搜索的步骤
网格搜索的实施可以分为以下几个步骤:
1. **定义参数网格**:确定需要优化的参数以及这些参数的可能取值。
2. **循环遍历参数组合**:通过嵌套循环遍历参数网格中的每一个可能的参数组合。
3. **交叉验证评估**:对于每一个参数组合,使用交叉验证方法进行评估,并记录下评估指标。
4. **选择最佳组合**:根据交叉验证的结果,选出表现最好的参数组合。
代码示例可以使用Python的`sklearn.model_selection`中的`GridSearchCV`函数:
```python
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import Lasso
# 假设我们已经准备好了数据集X和y
# 定义参数网格
param_grid = {'alpha': [0.0001, 0.001, 0.01, 0.1, 1, 10, 100, 1000]}
# 创建Lasso回归实例
lasso = Lasso()
# 使用网格搜索
grid_search = GridSearchCV(lasso, param_grid, cv=5, scoring='neg_mean_squared_error')
# 执行网格搜索
grid_search.fit(X, y)
# 输出最佳参数
print("Best parameters:", grid_search.best_params_)
```
### 2.2.3 网格搜索的优势与局限性
网格搜索方法的优势在于其简单直观,易于理解和实施。它不需要了解模型的内部工作机制,通过穷举所有可能性,理论上总能找到最优的参数组合。但是,网格搜索也有明显的局限性,主要体现在计算成本高和效率低。当参数网格较大时,需要评估的参数组合数量呈指数级增长,这在计算上是非常昂贵的。此外,当参数之间的相互作用比较复杂时,网格搜索可能无法找到全局最优解,因为模型性能不仅与单个参数有关,还与多个参数的相互作用有关。
## 表格展示不同参数范围下的模型表现
下面是一个假设的表格,展示不同正则化强度下的Lasso模型表现:
| alpha (λ) | 训练集MSE | 验证集MSE | 参数数量 |
|-----------|-----------|-----------|----------|
| 0.0001 | 0.034 | 0.047 | 1000 |
| 0.001 | 0.031 | 0.045 | 900 |
| 0.01 | 0.033 | 0.049 | 700 |
| 0.1 | 0.041 | 0.052 | 500 |
| 1 | 0.058 | 0.065 | 300 |
| 10 | 0.120 | 0.125 | 100 |
| 100 | 0.200 | 0.210 | 50 |
| 1000 | 0.300 | 0.310 | 10 |
**注**:MSE表示均方误差,参数数量表示模型中非零系数的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
L1正则化(Lasso回归)专栏深入探讨了L1正则化在机器学习中的核心价值和应用。从基础概念到高级技术,该专栏涵盖了广泛的主题,包括特征选择、模型优化、稀疏性分析、实战攻略、算法优化、高维数据分析、限制和替代方案、变量筛选、Python和R语言实践、预测建模、正则化对决、统计学基础、稀疏建模、参数调优、模型诊断和集成策略。通过专家解读、代码实现、实例演示、实战演练和案例研究,该专栏为读者提供了全面深入的理解,使他们能够掌握L1正则化在机器学习中的强大功能和有效应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
高效DSP编程揭秘:VisualDSP++代码优化的五大策略

# 摘要
本文全面介绍了VisualDSP++开发环境,包括其简介、基础编程知识、性能优化实践以及高级应用案例分析。首先,文中概述了VisualDSP++的环境搭建、基本语法结构以及调试工具的使用,为开发者提供了一个扎实的编程基础。接着,深入探讨了在代码、算法及系统三个层面的性能优化策略,旨在帮助开发者提升程序的运行效率。通过高级应用和案例分析,本文展示了VisualD
BRIGMANUAL高级应用技巧:10个实战方法,效率倍增

# 摘要
BRIGMANUAL是一种先进的数据处理和管理工具,旨在提供高效的数据流处理与优化,以满足不同环境下的需求。本文首先介绍BRIGMANUAL的基本概念和核心功能,随后深入探讨了其理论基础,包括架构解析、配置优化及安全机制。接着,本文通过实战技巧章节,展示了如何通过该工具优化数据处理和设计自动化工作流。文章还具体分析了BRIGMANUAL在大数据环境、云服务平台以及物联网应用中的实践案例。最后,文
QNX Hypervisor调试进阶:专家级调试技巧与实战分享

# 摘要
QNX Hypervisor作为一种先进的实时操作系统虚拟化技术,对于确保嵌入式系统的安全性和稳定性具有重要意义。本文首先介绍了QNX Hypervisor的基本概念,随后详细探讨了调试工具和环境的搭建,包括内置与第三方调试工具的应用、调试环境的配置及调试日志的分析方法。在故障诊断方面,本文深入分析了内存泄漏、性能瓶颈以及多虚拟机协同调试的策略,并讨论了网络和设备故障的排查技术。此外,文中还介绍了QNX Hypervis
协议层深度解析:高速串行接口数据包格式与传输协议
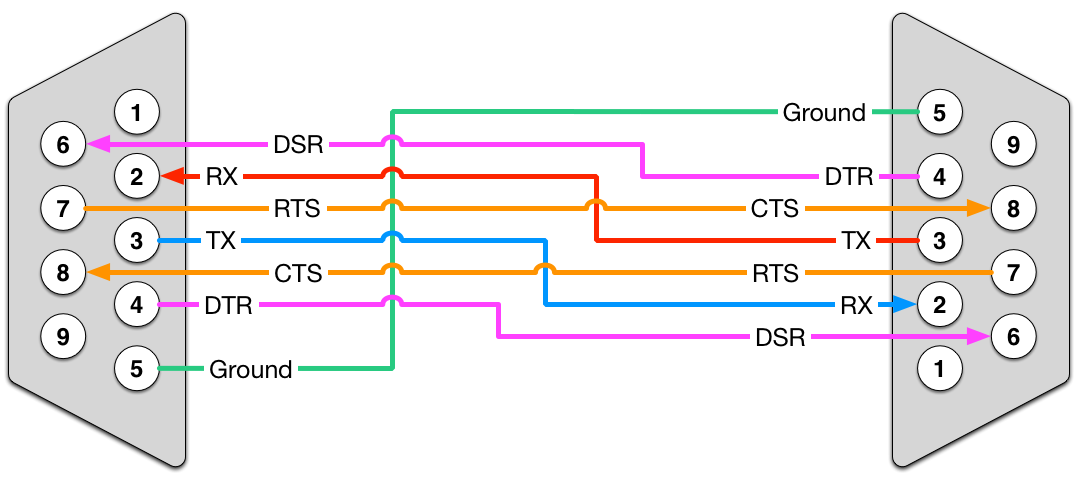
# 摘要
高速串行接口技术是现代数据通信的关键部分,本文对高速串行接口的数据包概念、结构和传输机制进行了系统性的介绍。首先,文中阐述了数据包的基本概念和理论框架,包括数据包格式的构成要素及传输机制,详细分析了数据封装、差错检测、流量控制等方面的内容。接着,通过对比不同高速串行接口标准,如USB 3.0和PCI Express,进一步探讨了数据包格式的实践案例分析,以及数据包的生成和注入技术。第四章深入分析了传输协议的特性、优化策略以及安全
SC-LDPC码性能评估大公开:理论基础与实现步骤详解
# 摘要
低密度奇偶校验(LDPC)码,特别是短周期LDPC(SC-LDPC)码,因其在错误校正能力方面的优势而受到广泛关注。本文对SC-LDPC码的理论基础、性能评估关键指标和优化策略进行了全面综述。首先介绍了信道编码和迭代解码原理,随后探讨了LDPC码的构造方法及其稀疏矩阵特性,以及SC-LDPC码的提出和发展背景。性能评估方面,本文着重分析了误码率(BER)、信噪比(SNR)、吞吐量和复杂度等关键指标,并讨论了它们在SC-LDPC码性能分析中的作用。在实现步骤部分,本文详细阐述了系统模型搭建、仿真实验设计、性能数据收集和数据分析的流程。最后,本文提出了SC-LDPC码的优化策略,并展望了
CU240BE2调试速成课:5分钟掌握必备调试技巧

# 摘要
本文详细介绍了CU240BE2变频器的应用与调试过程。从基础操作开始,包括硬件连接、软件配置,到基本参数设定和初步调试流程,以及进阶调试技巧,例如高级参数调整、故障诊断处理及调试工具应用。文章通过具体案例分析,如电动机无法启动
【Dos与大数据】:应对大数据挑战的磁盘管理与维护策略

# 摘要
随着大数据时代的到来,磁盘管理成为保证数据存储与处理效率的重要议题。本文首先概述了大数据时代磁盘管理的重要性,并从理论基础、实践技巧及应对大数据挑战的策略三个维度进行了系统分析。通过深入探讨磁盘的硬件结构、文件系统、性能评估、备份恢复、分区格式化、监控维护,以及面向大数据的存储解决方案和优化技术,本文提出了适合大数据环境的磁盘管理策略。案例分析部分则具体介绍
【电脑自动关机问题全解析】:故障排除与系统维护的黄金法则

# 摘要
电脑自动关机问题是一个影响用户体验和数据安全的技术难题,本文旨在全面概述其触发机制、可能原因及诊断流程。通过探讨系统命令、硬件设置、操作系统任务等触发机制,以及软件冲突、硬件故障、病毒感染和系统配置错误等可能原因,本文提供了一套系统的诊断流程,包括系统日志分析、硬件测试检查和软件冲突
MK9019故障排除宝典:常见问题的诊断与高效解决方案
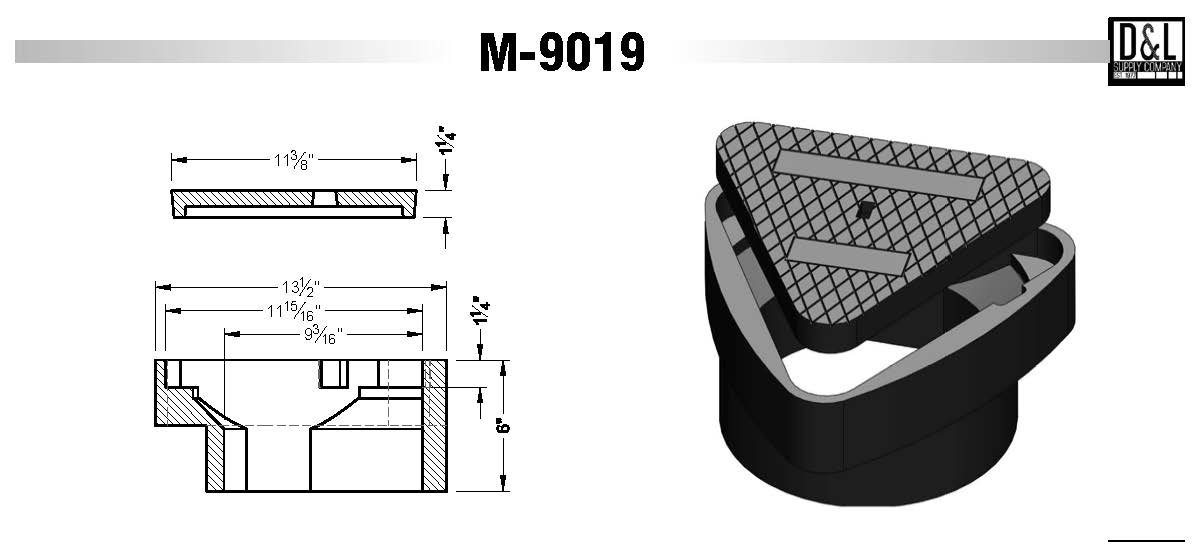
# 摘要
MK9019作为一种复杂设备,在运行过程中可能会遇到各种故障问题,从而影响设备的稳定性和可靠性。本文系统地梳理了MK9019故障排除的方法和步骤,从故障诊断基础到常见故障案例分析,再到高级故障处理技术,最后提供维护与预防性维护指南。重点介绍了设备硬件架构、软件系统运行机制,以及故障现象确认、日志收集和环境评估等准备工作。案例分析部分详细探讨了硬件问题、系统崩溃、性能问题及其解决方案。同时,本文还涉及
LTE-A技术新挑战:切换重选策略的进化与实施

# 摘要
本文首先介绍了LTE-A技术的概况,随后深入探讨了切换重选策略的理论基础、实现技术和优化实践。在切换重选策略的理论基础部分,重点分析了LTE-A中切换重选的定义、与传统LTE的区别以及演进过程,同时指出了切换重选过程中可能遇到的关键问题。实现技术章节讨论了自适应切换、多连接切换以及基于负载均衡的切换策略,包括其原理和应用场景。优化与实践章节则着重于切换重选参数的优化、实时监测与自适应调整机制以及切换重选策略的测试与评估方法。最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )