06-Hash算法在数据库中的应用
发布时间: 2024-02-27 10:47:55 阅读量: 34 订阅数: 23 
# 1. 引言
在当今信息时代,数据是无处不在的。随着大数据和云计算的兴起,数据库作为数据的存储和管理基础设施,扮演着越来越重要的角色。而在数据库中,数据的快速查找和高效存储是至关重要的,而Hash算法的应用为数据库的性能优化和提升提供了有效的解决方案。
本章将从Hash算法在数据库中的重要性和作用出发,介绍Hash算法的基本原理和优势,为后续对Hash算法在数据库中的具体应用及实现进行铺垫。
## 1.1 引言
在当今信息时代,数据得到越来越多的关注。而对于数据库来说,快速的查找和高效的存储对于数据处理来说是至关重要的。为了解决这一问题,Hash算法在数据库中得到了广泛的应用。通过将数据转化为哈希值,可以实现快速的数据查找和存储,并且减少数据检索的时间复杂度。
## 1.2 Hash算法的重要性
Hash算法在数据库中的重要性不言而喻。它可以大大提高数据的查找和存储效率,减少数据库的负担。通过Hash算法,可以将数据转换为索引值,使得数据的查找速度更快。此外,Hash算法还可以降低数据检索的时间复杂度,提高数据库的性能和效率。
## 1.3 本文结构
本文将首先介绍Hash算法的基本概念和原理,然后深入探讨Hash算法在数据库中的应用,以及在不同数据库管理系统中的具体实现。同时,我们还将讨论Hash算法的安全性与一致性,并对Hash算法在未来数据库发展中的潜力进行展望。最后,本文将提出对Hash算法在数据库中应用的未来研究方向与建议。通过本文的阐述,读者将对Hash算法在数据库中的应用有一个全面的了解,同时也能够对未来数据库发展方向有一定的启发。
# 2. Hash算法概述
### 2.1 Hash算法基本概念介绍
Hash算法是一种将任意长度的输入数据转换为固定长度输出的算法。它通过对输入数据进行散列运算,能够快速、方便地找到对应的输出值。Hash算法的输出值通常称为哈希值或摘要,具有固定的长度,且对输入数据的任何改动都会导致输出结果的不可预测性。
### 2.2 Hash算法的原理和特点
Hash算法的核心原理是通过一系列复杂的数学运算,将输入数据映射到一个固定长度的哈希值上。其特点包括:
- 输入数据产生唯一的哈希值
- 哈希值的长度固定
- 输入数据的微小改动会导致完全不同的哈希值
- 无法从哈希值反推出原始数据
### 2.3 Hash算法在数据存储和查找中的优势
在数据库中,Hash算法能够快速索引和查找数据,极大地提高了数据存储和检索的效率。通过哈希索引,可以直接定位到数据存储位置,而不需要进行全表扫描,减小了数据查找的时间复杂度,提高了数据库的性能。
以上就是Hash算法概述部分的内容,包括基本概念介绍、原理和特点分析、以及在数据存储和检索中的优势。接下来我将会为你展示第三章的内容。
# 3. Hash算法在数据库中的应用
在现代数据库系统中,Hash算法被广泛应用于数据存储和查找过程中。本章将讨论Hash算法在数据库中的具体应用场景,分析其如何提高数据库的性能和效率,并探讨一些实际的应用案例。
#### 3.1 Hash算法在数据索引中的应用
Hash算法在数据库中常用于数据索引,通过将数据的关键字经过Hash运算后得到一个对应的索引值,从而加快数据的检索速度。在索引大规模数据时,Hash算法能够更快速地确定数据所在的位置,从而提高数据库的查询效率。
#### 3.2 Hash算法在分布式数据库中的应用
在分布式数据库系统中,数据通常会根据某种规则被分散存储到不同的节点中,而Hash算法可以通过对数据的关键字进行Hash运算,将其均匀地分布到不同的节点中,从而实现数据的分布式存储与管理。
#### 3.3 Hash算法在数据去重中的应用
Hash算法可以帮助数据库快速进行数据去重处理。通过计算数据的Hash值,并将Hash值作为数据的唯一标识存储在Hash表中,数据库可以快速识别重复数据并进行去重处理,避免数据重复存储,节省存储空间。
#### 3.4 Hash算法在缓存管理中的应用
数据库中的缓存管理通常会使用Hash算法来实现快速的缓存数据查找和更新。利用Hash算法,数据库可以将缓存数据的关键字映射到对应的缓存位置,提高缓存数据的读写效率。
#### 3.5 实际应用案例
以实际案例展示Hash算法在数据库中的应用,例如在大规模数据处理中的索引优化、分布式数据库系统中的数据分布与负载均衡、数据去重与缓存管理等方面的应用实践,进一步说明Hash算法在数据库中的重要性和价值。
通过以上内容的探讨,可以清晰地了解到Hash算法在数据库中的多种应用场景,以及其在提升数据库性能和效率方面的重要作用。
# 4. Hash算法的安全性与一致性
在数据库中应用Hash算法时,我们不仅需要关注其性能和效率,还需要重点考虑其安全性和一致性。本章节将探讨Hash算法在数据库中的安全性问题、一致性和碰撞处理方法,以及如何确保Hash算法在数据库中的稳定性和可靠性。
#### 4.1 Hash算法在数据库中的安全性问题
Hash算法在数据库中的安全性问题是一个非常重要的议题。在数据库中使用Hash算法进行数据加密、身份验证或完整性检查时,必须确保Hash值不易被破解或伪造。因此,选择合适的Hash算法和正确的加密方式至关重要。
一些常见的Hash算法,如MD5和SHA-1,由于存在碰撞问题和计算速度较快,已经逐渐被认为不够安全。相比之下,SHA-256和SHA-3等算法被认为具有更高的安全性,因为它们具有更大的输出长度和更复杂的计算过程。
#### 4.2 Hash算法的一致性和碰撞处理方法
在数据库中,一致性是指对相同输入始终生成相同输出的特性。而碰撞则是指当不同输入生成相同输出时发生的现象。为了确保Hash算法的一致性,我们需要选择适当的Hash函数,并实现有效的碰撞处理方法。
常见的碰撞处理方法包括开放寻址法、链地址法和再哈希法。其中,链地址法是一种常用且高效的碰撞处理方法,通过在Hash桶中维护一个链表来存储具有相同Hash值的元素。
#### 4.3 确保Hash算法在数据库中的稳定性和可靠性
为了确保Hash算法在数据库中的稳定性和可靠性,我们需要进行充分的测试和验证。在实际应用中,可以通过大规模数据测试、压力测试和安全审计等手段来评估Hash算法的性能和可靠性。
此外,在数据库设计和开发过程中,需要合理选择Hash函数的种子值、散列长度和碰撞处理方法,以及定期对Hash算法进行更新和升级,以及备份和恢复机制的建立,来确保数据库系统的稳定性和可靠性。
# 5. 常见数据库中的Hash算法实现
在实际的数据库管理系统中,不同的数据库可能会采用不同的Hash算法实现来优化查询性能。本章将分析和对比不同数据库中Hash算法的实现方式,并探讨如何选择合适的Hash算法来提高数据库性能。
#### 1. MySQL中的Hash算法实现
MySQL提供了多种Hash函数来供用户选择,如MD5、SHA1等。这些Hash函数可以用于数据库中存储密码、数字摘要等场景,以及优化数据库中大量数据的查找效率。以下是一个在MySQL中使用MD5哈希算法的示例:
```sql
SELECT MD5('your_string');
```
#### 2. MongoDB中的Hash算法实现
在MongoDB中,可以使用BSON对象ID来作为Hash值来确保唯一性和快速查找。BSON对象ID是一个12字节的唯一标识符,其中包含时间戳、机器ID、进程ID和随机数等信息。以下是一个在MongoDB中使用BSON对象ID的示例:
```javascript
const objectId = ObjectId();
```
#### 3. Redis中的Hash算法实现
在Redis中,可以使用Hash数据结构作为Hash算法的一种实现方式。Redis的Hash数据结构类似于Python中的字典,可以存储键值对,非常适合存储和查询具有相同Field的对象。以下是一个在Redis中使用Hash数据结构的示例:
```java
Jedis jedis = new Jedis("localhost");
jedis.hset("hashKey", "field1", "value1");
String value = jedis.hget("hashKey", "field1");
```
#### 4. 对比各种数据库中Hash算法的性能和适用场景
不同数据库中的Hash算法实现各有优劣,根据具体数据库的特点和应用场景来选择合适的Hash算法是非常重要的。比如,如果需要存储大量密码或者敏感数据,可以选择较为安全的MD5或SHA1算法;如果需要快速的唯一标识符,可以选择MongoDB的BSON对象ID等。
#### 5. 探讨如何选择合适的Hash算法来优化数据库性能
在选择合适的Hash算法时,除了考虑数据安全性外,还需要考虑数据库的查询性能和存储空间的利用率。合理选择Hash算法可以提高数据库的查询效率,降低数据冗余,从而提升整体数据库性能。
通过本章的讨论,读者可以更加全面地了解不同数据库中Hash算法的实现方式及适用场景,有助于在实际应用中优化数据库性能。
# 6. 总结与展望
### 总结Hash算法在数据库中的应用优势和挑战
在本文中我们深入探讨了Hash算法在数据库中的应用,讨论了Hash算法的原理、特点以及在数据存储和查找中的优势。我们还具体分析了Hash算法在数据库中的应用场景和提高数据库性能和效率的方法。此外,我们对Hash算法的安全性、一致性和稳定性也进行了详细讨论。通过对不同数据库中的Hash算法实现方式进行比较,我们可以更好地选择适合的Hash算法来优化数据库性能。
### 展望Hash算法在未来数据库发展中的潜力和可能性
随着数据量的不断增加和数据库应用场景的不断拓展,Hash算法在数据库中的应用将变得越来越重要。未来,我们可以继续深入研究Hash算法在数据库中的应用,探索更多的优化方法和技术手段,以满足数据库处理大规模数据的需求。同时,随着技术的进步,我们可以期待Hash算法在数据库中的应用在性能和效率方面取得更大的突破。
### 提出对Hash算法在数据库中应用的未来研究方向与建议
未来的研究可以集中在以下几个方面:
1. 发展更加高效的Hash算法,以应对数据库处理大规模数据的挑战。
2. 继续深入研究Hash算法在数据库中的安全性和一致性问题,加强数据的保护和管理。
3. 探索Hash算法与其他技术的结合,如机器学习和人工智能,以提高数据库的处理能力和智能化水平。
4. 关注Hash算法在分布式数据库系统中的应用,探索多节点之间的数据分片和负载均衡问题,提高系统的可扩展性和稳定性。
通过持续的研究和探索,Hash算法在数据库中的应用将会迎来新的发展机遇,为数据库系统的性能和效率提供更加可靠的支持。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Hash算法原理剖析》专栏深入探讨了Hash算法在计算机科学领域中的重要性和应用。文章首先介绍了Hash算法的原理和基本概念,然后分析了Hash算法中可能出现的碰撞问题以及解决方法,进一步探讨了Hash算法的冲突率与性能评估。接着,专栏还深入讨论了Hash算法在数据库、分布式系统、负载均衡、缓存系统、区块链、机器学习、图像处理以及大数据处理等领域中的具体应用。通过对这些领域的案例分析,读者可以全面了解Hash算法在各种实际应用中的作用和效果。本专栏旨在帮助读者深入理解Hash算法,并为他们在实际开发和应用中提供指导和启发。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
库转换项目管理:高效处理.a转.lib批量任务的方法

参考资源链接:[mingw 生成.a 转为.lib](https://wenku.csdn.net/doc/6412b739be7fbd1778d4987e?spm=1055.2635.3001.10343)
# 1. 库转换项目管理的基本概念与重要性
在IT领域中,库转换项目管理是一个关键的活动,它涉及软件库的版本控制、兼容性管理、
WINCC依赖性危机:彻底解决安装时遇到的所有依赖问题

参考资源链接:[Windows XP下安装WINCC V6.0/V6.2错误解决方案](https://wenku.csdn.net/doc/6412b6dcbe7fbd1778d483df?spm=1055.2635.3001.10343)
# 1. WINCC依赖性问题概述
## 依赖性问题定义
在工业自动化领域,依赖性问题指的是在安装、运行WINCC(Windows Control Ce
【VCS数据保护策略】:备份与恢复技巧,确保数据万无一失

参考资源链接:[VCS用户手册:2020.03-SP2版](https://wenku.csdn.net/doc/hf87hg2b2r?spm=1055.2635.3001.10343)
# 1. VCS数据保护策略概述
在信息技术飞速发展的今天,数据保护已经成为企业运营中不可或缺的一环。尤其是对于依赖于关键数据的业务系统来说,VCS(Virtual Cluste
Strmix Simplis安装配置:最佳实践指南,避免仿真软件的坑

参考资源链接:[Simetrix/Simplis仿真教程:从基础到进阶](https://wenku.csdn.net/doc/t5vdt9168s?spm=1055.2635.3001.10343)
# 1. Strmix Simplis软件介绍与安装前准备
Strmix Sim
【系统集成挑战】:RTC6激光控制卡在复杂系统中的应用案例与策略

参考资源链接:[SCANLAB激光控制卡-RTC6.说明书](https://wenku.csdn.net/doc/71sp4mutsg?spm=1055.2635.3001.10343)
# 1. RTC6激光控制卡概述
RTC6激光控制卡是业界领先的高精度激光控制系统,专门设计用于满足
电动汽车充电效率提升:SAE J1772标准实施难点的解决方案

参考资源链接:[SAE J1772-2017.pdf](https://wenku.csdn.net/doc/6412b74abe7fbd1778d
【Maxwell仿真与实验对比】:验证铁耗与涡流损耗计算的准确性和可靠性
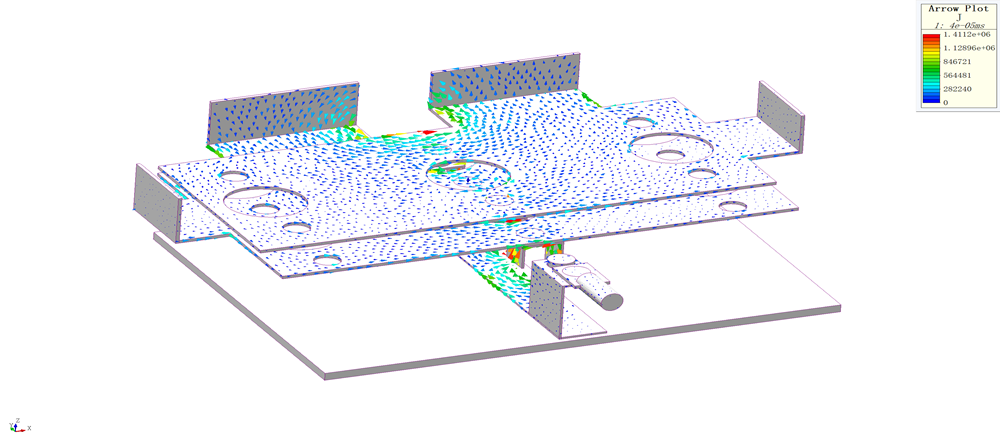
参考资源链接:[Maxwell中的铁耗分析与B-P曲线设置详解](https://wenku.csdn.net/doc/69syjty4c3?spm=1055.2635.3001.10343)
# 1. Maxwell仿真软件概述
在本章中,我们将介绍Maxwell仿真软件的基础知识,它是一款由Ansys公司开发的领先电磁场仿真工具,广泛
【可持续发展与自动化】:提高能源效率在FANUC 0i-MF系统中的3个实践策略
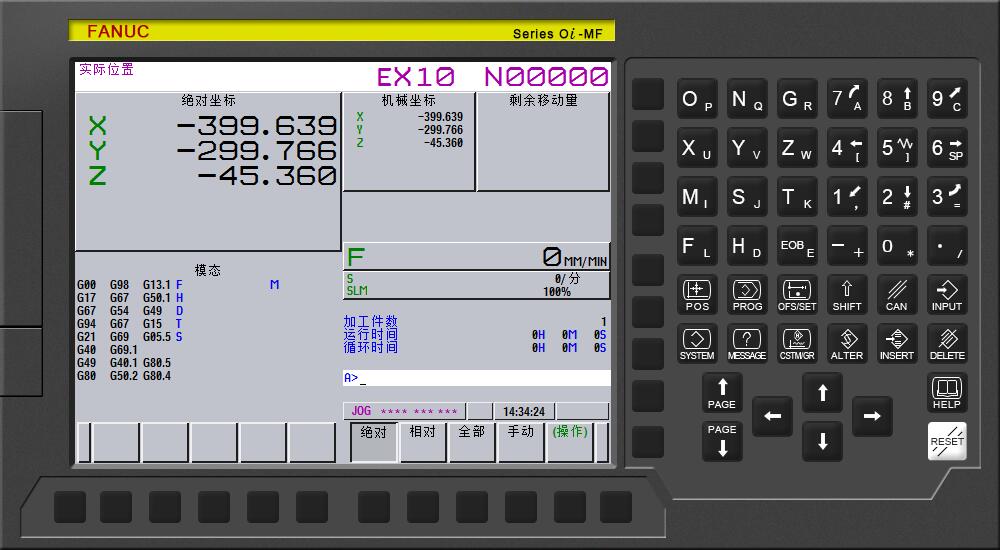
参考资源链接:[FANUC 0i-MF 加工中心系统操作与安全指南](https://wenku.csdn.net/doc/6401ac08cce7214c316ea60a?spm=1055.2635.3001.10343)
# 1. 可持续发展与自动化的关系
在追求工业化快速发展的当今社会,可持续发展和自动化技术的关系日益紧密。可持续发展不仅是一个环境概念,更是一种社会责任
【ASP.NET中间件设计模式】:打造可扩展应用的黄金法则
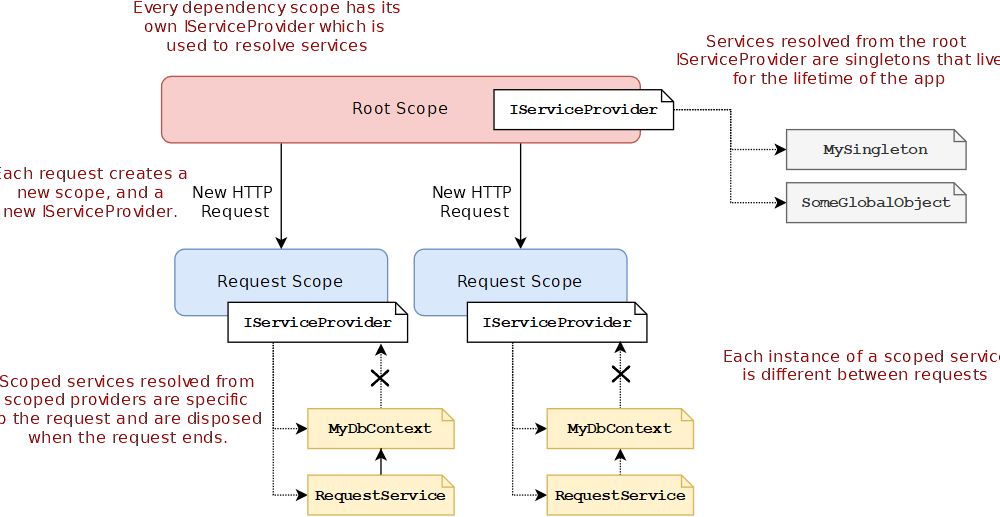
参考资源链接:[ASP.NET实用开发:课后习题详解与答案](https://wenku.csdn.net/doc/649e3a1550e8173efdb59dbe?spm=1055.2635.3001.10343)
# 1. ASP.NET中间件设计模式概述
## 1.1 中间件在软件架构中的位置
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )