【MySQL数据库入门指南】:初识MySQL,解锁数据库世界
发布时间: 2024-07-17 00:23:51 阅读量: 49 订阅数: 25 

# 1. MySQL数据库简介**
MySQL是一种流行的关系型数据库管理系统(RDBMS),以其高性能、可靠性和可扩展性而闻名。它广泛用于各种应用程序,从小型网站到大型企业系统。
MySQL使用结构化查询语言(SQL)来管理和查询数据。SQL是一种强大的语言,允许用户创建、读取、更新和删除数据库中的数据。MySQL还提供了一系列高级功能,如事务、存储过程和触发器,使开发人员能够构建复杂和可扩展的数据库应用程序。
# 2. MySQL数据库基本操作**
**2.1 数据库的创建和管理**
**2.1.1 创建数据库**
创建数据库的语法如下:
```sql
CREATE DATABASE database_name;
```
其中,`database_name`为要创建的数据库名称。
**代码逻辑分析:**
该语句将创建一个名为`database_name`的新数据库。如果数据库已存在,则会返回一个错误。
**参数说明:**
* `database_name`:要创建的数据库名称。
**2.1.2 删除数据库**
删除数据库的语法如下:
```sql
DROP DATABASE database_name;
```
其中,`database_name`为要删除的数据库名称。
**代码逻辑分析:**
该语句将删除名为`database_name`的数据库。如果数据库不存在,则会返回一个错误。
**参数说明:**
* `database_name`:要删除的数据库名称。
**2.2 表的创建和管理**
**2.2.1 创建表**
创建表的语法如下:
```sql
CREATE TABLE table_name (
column_name1 data_type1 [NOT NULL] [DEFAULT default_value1],
column_name2 data_type2 [NOT NULL] [DEFAULT default_value2],
...
);
```
其中:
* `table_name`为要创建的表名称。
* `column_name`为列名称。
* `data_type`为列的数据类型。
* `NOT NULL`表示该列不能为NULL。
* `DEFAULT`指定列的默认值。
**代码逻辑分析:**
该语句将创建一个名为`table_name`的新表,其中包含指定列和数据类型。如果表已存在,则会返回一个错误。
**参数说明:**
* `table_name`:要创建的表名称。
* `column_name`:列名称。
* `data_type`:列的数据类型。
* `NOT NULL`:表示该列不能为NULL。
* `DEFAULT`:指定列的默认值。
**2.2.2 删除表**
删除表的语法如下:
```sql
DROP TABLE table_name;
```
其中,`table_name`为要删除的表名称。
**代码逻辑分析:**
该语句将删除名为`table_name`的表。如果表不存在,则会返回一个错误。
**参数说明:**
* `table_name`:要删除的表名称。
**2.3 数据的插入和查询**
**2.3.1 数据插入**
插入数据的语法如下:
```sql
INSERT INTO table_name (column_name1, column_name2, ...)
VALUES (value1, value2, ...);
```
其中:
* `table_name`为要插入数据的表名称。
* `column_name`为要插入数据的列名称。
* `value`为要插入的数据值。
**代码逻辑分析:**
该语句将向`table_name`表中插入一条新记录,其中包含指定列和值。如果表不存在或列名称不正确,则会返回一个错误。
**参数说明:**
* `table_name`:要插入数据的表名称。
* `column_name`:要插入数据的列名称。
* `value`:要插入的数据值。
**2.3.2 数据查询**
查询数据的语法如下:
```sql
SELECT column_name1, column_name2, ...
FROM table_name
WHERE condition;
```
其中:
* `column_name`为要查询的列名称。
* `table_name`为要查询的表名称。
* `condition`为查询条件。
**代码逻辑分析:**
该语句将从`table_name`表中查询数据,并返回满足`condition`条件的所有记录。如果表不存在或列名称不正确,则会返回一个错误。
**参数说明:**
* `column_name`:要查询的列名称。
* `table_name`:要查询的表名称。
* `condition`:查询条件。
# 3. MySQL数据库高级操作
### 3.1 数据类型的使用
在MySQL数据库中,数据类型决定了数据的存储方式和范围。选择合适的数据类型可以优化存储空间、提高查询效率和保证数据完整性。
#### 3.1.1 整数类型
整数类型用于存储整数,包括正整数、负整数和零。常用的整数类型有:
| 数据类型 | 范围 | 存储字节 |
|---|---|---|
| TINYINT | -128 ~ 127 | 1 |
| SMALLINT | -32768 ~ 32767 | 2 |
| MEDIUMINT | -8388608 ~ 8388607 | 3 |
| INT | -2147483648 ~ 2147483647 | 4 |
| BIGINT | -9223372036854775808 ~ 9223372036854775807 | 8 |
#### 3.1.2 浮点数类型
浮点数类型用于存储小数和科学计数法表示的数字。常用的浮点数类型有:
| 数据类型 | 范围 | 存储字节 |
|---|---|---|
| FLOAT | ±1.7976931348623157e+308 ~ ±2.2250738585072014e-308 | 4 |
| DOUBLE | ±2.2250738585072014e-308 ~ ±1.7976931348623157e+308 | 8 |
#### 3.1.3 字符串类型
字符串类型用于存储文本数据。常用的字符串类型有:
| 数据类型 | 长度 | 存储字节 |
|---|---|---|
| CHAR(n) | 固定长度,n表示字符长度 | n |
| VARCHAR(n) | 可变长度,n表示最大字符长度 | n + 1 |
| TEXT | 可变长度,最大长度为65535个字符 | 2^16 - 1 |
| BLOB | 可变长度,最大长度为65535个字节 | 2^16 - 1 |
### 3.2 约束的应用
约束用于限制表中数据的有效性,确保数据的完整性和一致性。常用的约束有:
#### 3.2.1 主键约束
主键约束指定表中唯一标识每条记录的列。主键列的值必须唯一且非空。
```sql
CREATE TABLE users (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
PRIMARY KEY (id)
);
```
#### 3.2.2 外键约束
外键约束指定表中列与另一张表的主键列之间的关系。外键列的值必须引用另一张表的主键列的值。
```sql
CREATE TABLE orders (
id INT NOT NULL AUTO_INCREMENT,
user_id INT NOT NULL,
product_id INT NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY (user_id) REFERENCES users (id),
FOREIGN KEY (product_id) REFERENCES products (id)
);
```
### 3.3 索引的创建和使用
索引是数据表中的一种数据结构,用于快速查找数据。创建索引可以大大提高查询效率。
#### 3.3.1 创建索引
```sql
CREATE INDEX idx_name ON table_name (column_name);
```
#### 3.3.2 使用索引
MySQL会自动选择合适的索引来优化查询。但是,也可以通过在查询中显式指定索引来强制使用特定的索引。
```sql
SELECT * FROM table_name WHERE column_name = value USE INDEX (idx_name);
```
# 4. MySQL数据库查询优化
### 4.1 查询计划的分析
#### 4.1.1 EXPLAIN命令
EXPLAIN命令用于分析查询语句的执行计划,展示查询语句在执行过程中各个阶段的详细信息,包括:
- **table**:参与查询的表名
- **type**:查询类型,如ALL、INDEX、RANGE等
- **possible_keys**:查询中可能使用的索引
- **key**:实际使用的索引
- **rows**:查询需要扫描的行数
- **Extra**:其他信息,如Using filesort、Using temporary等
**示例:**
```sql
EXPLAIN SELECT * FROM users WHERE name LIKE '%john%';
```
**结果:**
```
+----+-------------+-------+-------+-------+-----------------------------+
| id | select_type | table | type | key | Extra |
+----+-------------+-------+-------+-------+-----------------------------+
| 1 | SIMPLE | users | index | name | Using where; Using index |
+----+-------------+-------+-------+-------+-----------------------------+
```
**分析:**
- 查询类型为SIMPLE,表示这是一个简单的查询。
- 查询表为users。
- 查询类型为index,表示使用了索引。
- 实际使用的索引为name。
- 查询需要扫描1行。
- 使用了where条件,并且使用了索引。
#### 4.1.2 索引的使用
索引是数据库中用于快速查找数据的结构,通过在表中创建索引,可以大幅提高查询效率。
**索引类型:**
- **主键索引:**唯一标识表中每一行的索引,不允许重复值。
- **唯一索引:**不允许重复值,但可以为NULL。
- **普通索引:**允许重复值。
**创建索引:**
```sql
CREATE INDEX index_name ON table_name (column_name);
```
**示例:**
```sql
CREATE INDEX idx_name ON users (name);
```
**使用索引:**
当查询语句中使用索引列时,数据库会自动使用索引来查询数据。
**注意:**
- 索引只能用于等值查询或范围查询。
- 索引会占用额外的存储空间,因此需要根据实际情况合理创建索引。
### 4.2 查询语句的优化
#### 4.2.1 避免不必要的全表扫描
全表扫描是指数据库需要扫描表中的所有行以查找数据。全表扫描效率较低,尤其是对于大型表。
**优化方法:**
- 使用索引:索引可以快速定位数据,避免全表扫描。
- 使用LIMIT子句:LIMIT子句可以限制查询结果的行数,减少扫描的行数。
- 使用分页查询:分页查询将查询结果分成多个页面,每次只查询一页的数据,避免一次性扫描大量数据。
#### 4.2.2 使用合适的连接方式
连接操作是将多个表中的数据组合在一起。不同的连接方式会影响查询效率。
**连接类型:**
- **INNER JOIN:**只返回两个表中都有匹配行的结果。
- **LEFT JOIN:**返回左表中的所有行,以及右表中匹配行的结果。
- **RIGHT JOIN:**返回右表中的所有行,以及左表中匹配行的结果。
- **FULL JOIN:**返回两个表中的所有行,无论是否匹配。
**优化方法:**
- 选择合适的连接类型:根据查询需求选择合适的连接类型。
- 使用索引:在连接列上创建索引可以提高连接效率。
- 使用ON子句:ON子句可以指定连接条件,避免不必要的笛卡尔积。
### 4.3 数据库性能的监控
#### 4.3.1 SHOW STATUS命令
SHOW STATUS命令用于显示数据库的运行状态信息,包括:
- **Threads:**当前活跃的线程数。
- **Queries:**执行过的查询数。
- **Slow queries:**执行时间超过long_query_time阈值的查询数。
- **Connections:**当前连接数。
- **Uptime:**数据库运行时间。
**示例:**
```sql
SHOW STATUS;
```
**结果:**
```
+---------------+-----------+
| Variable_name | Value |
+---------------+-----------+
| Threads | 1 |
| Queries | 100 |
| Slow_queries | 0 |
| Connections | 1 |
| Uptime | 1000 |
+---------------+-----------+
```
#### 4.3.2 慢查询日志
慢查询日志记录了执行时间超过long_query_time阈值的查询语句。通过分析慢查询日志,可以找出性能瓶颈并进行优化。
**启用慢查询日志:**
```sql
SET global slow_query_log=ON;
```
**查看慢查询日志:**
```sql
SHOW FULL PROCESSLIST;
```
# 5. MySQL数据库安全
### 5.1 用户权限管理
**5.1.1 创建用户**
```sql
CREATE USER 'new_user'@'%' IDENTIFIED BY 'new_password';
```
* **参数说明:**
* `new_user`:要创建的新用户名称
* `%`:允许该用户从任何主机连接
* `new_password`:该用户的新密码
**5.1.2 授予权限**
```sql
GRANT SELECT, INSERT, UPDATE, DELETE ON database_name.* TO 'new_user'@'%';
```
* **参数说明:**
* `SELECT`、`INSERT`、`UPDATE`、`DELETE`:授予用户对指定数据库中所有表的指定权限
* `database_name`:要授予权限的数据库名称
* `new_user`:要授予权限的用户名称
* `%`:允许该用户从任何主机连接
### 5.2 数据备份和恢复
**5.2.1 数据备份**
```sql
mysqldump -u root -p database_name > backup.sql
```
* **参数说明:**
* `-u root`:使用root用户进行备份
* `-p`:提示输入root用户的密码
* `database_name`:要备份的数据库名称
* `backup.sql`:备份文件的输出路径
**5.2.2 数据恢复**
```sql
mysql -u root -p database_name < backup.sql
```
* **参数说明:**
* `-u root`:使用root用户进行恢复
* `-p`:提示输入root用户的密码
* `database_name`:要恢复数据的数据库名称
* `backup.sql`:备份文件的路径
### 5.3 安全漏洞的防范
**5.3.1 SQL注入攻击**
SQL注入攻击是一种通过在用户输入中插入恶意SQL语句来攻击数据库的攻击方式。为了防止SQL注入攻击,可以使用以下方法:
* **使用预编译语句:**预编译语句可以防止SQL注入攻击,因为它在执行查询之前将SQL语句和参数分开。
* **转义用户输入:**转义用户输入可以防止SQL注入攻击,因为它将特殊字符替换为转义序列。
* **使用白名单:**白名单是一种仅允许用户输入特定值的方法。这可以防止SQL注入攻击,因为它阻止用户输入恶意SQL语句。
**5.3.2 跨站脚本攻击**
跨站脚本攻击是一种通过在用户输入中插入恶意JavaScript代码来攻击Web应用程序的攻击方式。为了防止跨站脚本攻击,可以使用以下方法:
* **转义用户输入:**转义用户输入可以防止跨站脚本攻击,因为它将特殊字符替换为转义序列。
* **使用内容安全策略(CSP):**CSP是一种允许Web应用程序指定哪些脚本可以执行的HTTP头。这可以防止跨站脚本攻击,因为它阻止恶意脚本执行。
* **使用X-XSS-Protection头:**X-XSS-Protection头是一种HTTP头,可以启用浏览器的XSS过滤器。这可以防止跨站脚本攻击,因为它阻止浏览器执行恶意脚本。
# 6. MySQL数据库实战应用
### 6.1 网站开发中的应用
#### 6.1.1 用户信息管理
**创建用户表**
```sql
CREATE TABLE users (
id INT NOT NULL AUTO_INCREMENT,
username VARCHAR(255) NOT NULL,
password VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
PRIMARY KEY (id)
);
```
**插入用户数据**
```sql
INSERT INTO users (username, password, email) VALUES
('john', '123456', 'john@example.com'),
('mary', '654321', 'mary@example.com'),
('bob', '789012', 'bob@example.com');
```
**查询用户数据**
```sql
SELECT * FROM users WHERE username = 'john';
```
#### 6.1.2 订单管理
**创建订单表**
```sql
CREATE TABLE orders (
id INT NOT NULL AUTO_INCREMENT,
user_id INT NOT NULL,
product_id INT NOT NULL,
quantity INT NOT NULL,
total_price DECIMAL(10, 2) NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY (user_id) REFERENCES users (id),
FOREIGN KEY (product_id) REFERENCES products (id)
);
```
**插入订单数据**
```sql
INSERT INTO orders (user_id, product_id, quantity, total_price) VALUES
(1, 1, 2, 100.00),
(2, 2, 1, 50.00),
(3, 3, 3, 150.00);
```
**查询订单数据**
```sql
SELECT * FROM orders WHERE user_id = 1;
```
### 6.2 数据分析中的应用
#### 6.2.1 数据统计
**统计用户数量**
```sql
SELECT COUNT(*) AS user_count FROM users;
```
**统计订单总金额**
```sql
SELECT SUM(total_price) AS total_amount FROM orders;
```
#### 6.2.2 数据挖掘
**找出购买次数最多的用户**
```sql
SELECT username, COUNT(*) AS order_count
FROM users u
JOIN orders o ON u.id = o.user_id
GROUP BY username
ORDER BY order_count DESC
LIMIT 1;
```
**找出最畅销的产品**
```sql
SELECT product_id, SUM(quantity) AS total_quantity
FROM orders
GROUP BY product_id
ORDER BY total_quantity DESC
LIMIT 1;
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏系列文章深入探讨了 MySQL 数据库的方方面面,为初学者和经验丰富的数据库专业人士提供全面的指南。从入门基础到高级概念,文章涵盖了数据类型、表结构、查询、数据操作、索引、锁机制、备份和恢复、性能优化、数据库设计、管理、存储过程、触发器、视图、用户和权限以及复制等主题。通过深入浅出的讲解和丰富的示例,本专栏旨在帮助读者掌握 MySQL 数据库的精髓,构建高效且安全的数据库系统,满足各种数据管理需求。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Comprehensive Application of Linear Programming in Healthcare: Optimizing Resources and Improving Services
# Fundamental Concepts and Practical Applications of Linear Programming
## 1. Overview of Linear Programming**
Linear programming is a mathematical optimization technique used to solve decision-making problems with linear objective functions and linear constraints. It is widely applied across vari
MATLAB Uninstallation Innovative Techniques: Exploring New Methods and Technologies for MATLAB Uninstallation
# 1. Overview of MATLAB Uninstallation
MATLAB uninstallation refers to the process of removing MATLAB and its associated components, which is crucial for system maintenance, software updates, and troubleshooting. Understanding MATLAB uninstallation technologies and best practices is essential for e
并行化排序:现代硬件加速的策略与技巧

# 1. 并行化排序简介
并行化排序是一种利用并行计算资源来提高数据排序速度的方法。在处理大规模数据集时,传统单线程排序算法往往效率低下,无法满足高性能计算的需求。并行化排序通过分解数据
编程竞赛快速排序策略:解题与优化技巧大公开
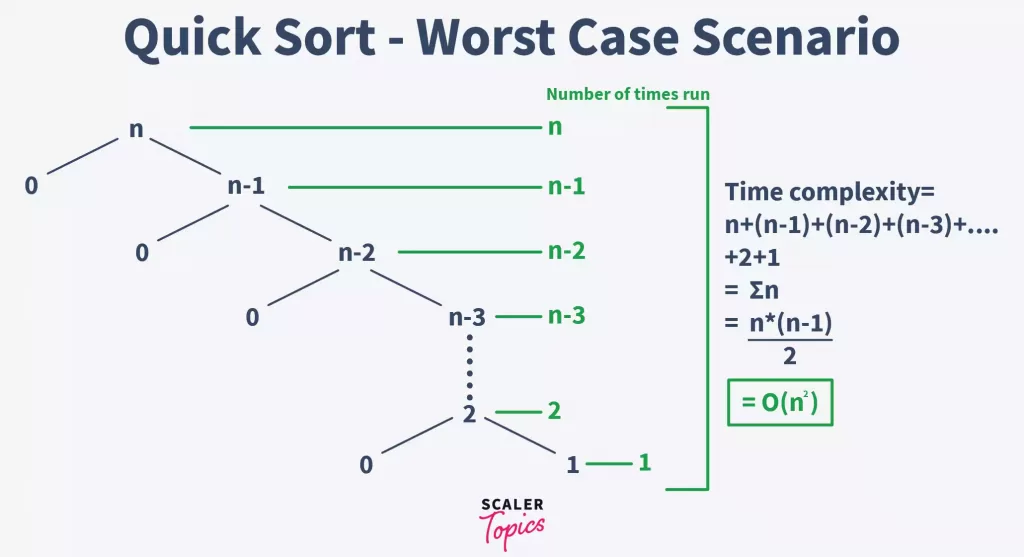
# 1. 快速排序算法概述
快速排序是一种被广泛应用的高效排序算法,由C. A. R. Hoare在1960年提出。它的基本思想是“分治策略”,即先选取一个基准元素,通过一趟排序将待排序的数据分割成独立的两部分,其中一部分的所有数据都比另一部分的所有数据要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快速排序算法的性能
时间复杂度详解:C语言中冒泡排序的深入剖析

# 1. 时间复杂度基础概念解析
在计算机科学中,时间复杂度是用来衡量算法执行时间与输入数据大小之间关系的度量方式。理解时间复杂度对于评估算法性能和选择合适的算法来解决问题至关重要。简单来说,时间复杂度描述了随着输入数据量的增加,算法执行所需时间的增加趋势。
## 1.1 时间复杂度的表示
时间复杂度通常使用大O符号表示,比如O(n)表示线性时间复杂度,其中n是输入数据的大小。这种表示
【Python实践】:拓扑排序算法的简单实现
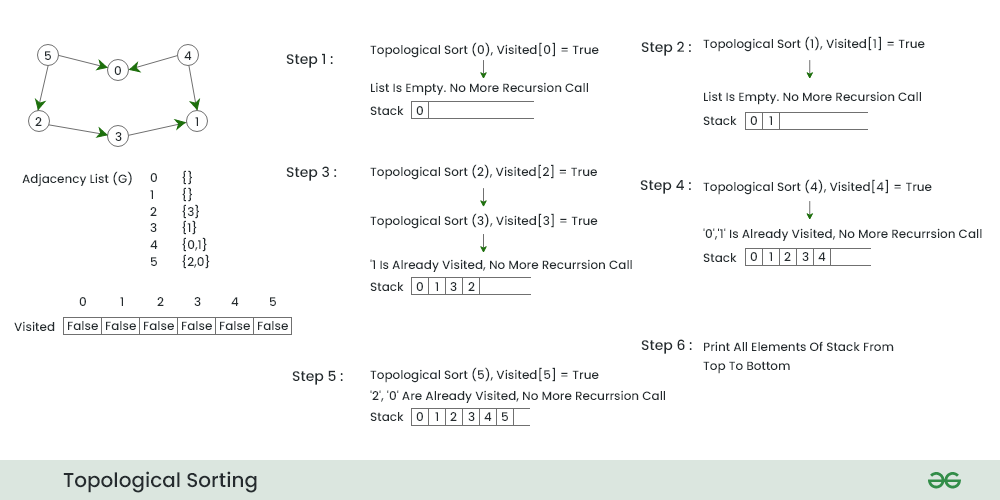
# 1. Python拓扑排序概述
拓扑排序是图论中的一项基础算法,它能够将有向无环图(DAG)中的节点线性排序,以体现节点间的依赖关系。在计算机科学中,这种排序特别适用于解决依赖和优先级问题,例如在编译器设计、项目管理和数据库等领域中。Python语言因其简洁性和强大的库支持,在处理这类算法问题时尤为突出。本章将从概念上简要介绍拓扑排序,并概述在Python中
【Advanced】MATLAB 2D Plotting, Adjustment, and Annotation
# Quick Start Tutorial Collection for MATLAB Learning
## 2.1 Setting and Modification of Graph Attributes
### 2.1.1 Line Style, Color, and Markers
MATLAB offers a rich array of graph attributes, allowing users to customize the appearance and style of their graphs. Among these, line style, color,
VNC Virtualization Applications: Deploying VNC Services in a Virtualized Environment
# 1. Understanding VNC Virtualization Technology
Virtual Network Computing (VNC) is a remote desktop protocol that allows users to connect to a remote computer over a network and control its desktop interface. In the context of virtualization technology, VNC provides a more flexible and convenient
MATLAB Crash Log Analysis Techniques: Extracting Fault Information from Logs for Rapid Issue Localization
# 1. Overview of MATLAB Crashes**
A MATLAB crash refers to the sudden shutdown of the MATLAB application during operation, usually accompanied by an error message or no prompt at all. Crash issues can significantly affect user experience and work efficiency, making it crucial to locate and resolve
【随机化排序】:随机化快速排序的创新实现与分析

# 1. 随机化排序算法概述
排序是计算机科学中的一项基本任务,广泛应用于各种数据处理场景。在众多排序算法中,快速排序(Quick Sort)以其优秀的平均性能脱颖而出。然而,在面对特定数据分布时,标准快速排序的表现可能会退化。随机化快速排序算法正是为解决这一问题而提出,通过对基准(pivot)的选择过程进行随机化,极大地减少了排序性能因输入数据不同而波动的情况。
随机化策略不仅可以提高算法的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )