多语种语音识别技术挑战与应对
发布时间: 2023-12-19 05:52:46 阅读量: 37 订阅数: 37 
# 第一章:多语种语音识别技术概述
## 1.1 多语种语音识别技术的定义与背景
随着全球化进程的加速,不同语种之间的交流变得愈发频繁,多语种语音识别技术应运而生。多语种语音识别技术是指能够对多种语种的语音进行准确识别和转换的技术。这种技术的背景是全球范围内不同语言、方言和口音的交织,为了实现跨语种语音信息的自动识别和转换,人们开始了多语种语音识别技术的研究与开发。
## 1.2 多语种语音识别技术的应用领域
多语种语音识别技术在多领域有广泛的应用,例如国际会议交传、全球企业客服、跨国广播电视、语言学习教育等。这些领域对多语种语音识别技术都有着高度需求,希望实现不同语种之间的无障碍沟通与交流。
## 1.3 多语种语音识别技术的发展现状
当前,多语种语音识别技术已经取得了一定的进展,各大科技公司和研究机构都在积极投入研发。但是在实际应用中,仍然存在着一些挑战和问题,比如语言模型的复杂性、多语种声学特征的差异性等。因此,多语种语音识别技术仍然需要不断地进行深入研究和技术改进,以更好地适应多元化的语音输入和应用场景。
## 第二章:多语种语音识别技术面临的挑战
在多语种语音识别技术的发展过程中,面临着诸多挑战与困难。本章将深入探讨多语种语音识别技术所面临的挑战,并针对每一个挑战提出相应的解决方案与改进措施。
### 3. 第三章:多语种语音识别技术的技术应对
在多语种语音识别技术中,面临着各种挑战和难点,但同时也有各种技术手段来进行有效的解决。本章将深入探讨多语种语音识别技术的技术应对策略。
#### 3.1 多语种声学模型的训练与优化
针对不同语种之间的声音特点和差异,需要建立多语种的声学模型。利用大规模的跨语种语音数据,采用深度学习模型,如深度神经网络 (DNN)、长短时记忆网络 (LSTM) 等,进行声学模型的训练和优化。同时,还需要考虑多语种语音数据的标注和特征提取方法,以保证声学模型的准确性和鲁棒性。
```python
# 伪代码示例 - 多语种声学模型训练
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
# 加载跨语种语音数据
multi_language_data = np.load('multi_language_data.npy')
# 构建深度学习模型
model = Sequential()
model.add(LSTM(units=64, input_shape=(None, 13)))
model.add(Dense(units=num_classes, activation='softmax'))
# 编译模型并进行训练
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(multi_language_data, epochs=10, batch_size=32)
```
**代码总结:** 上述代码演示了基于Python的神经网络模型训练过程,利用多语种语音数据进行跨语种声学模型的训练。
**结果说明:** 训练后的声学模型可以更好地适应多语种的语音数据,提升了跨语种语音识别的效果。
#### 3.2 语音识别引擎的多语种适应性优化
多语种语音

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在系统地介绍智能语音交互技术的各个方面,包括语音信号处理、语音识别、语音合成、自然语言处理等内容。首先,我们从智能语音交互技术的基本概念出发,介绍其简介和基础知识,并针对其重要组成部分进行深入探讨。其次,我们将重点关注语音交互中的关键技术,如深度学习、迁移学习、声纹识别、前端处理等,并探讨其在语音交互中的应用和挑战。此外,我们还将探讨多模态输入、知识图谱、增强学习等新兴技术在语音交互中的应用前景。通过本专栏的学习,读者可以深入了解智能语音交互技术的前沿发展动态和未来趋势,为相关领域的研究和实践提供有力的支持和指导。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据表结构革新】租车系统数据库设计实战:提升查询效率的专家级策略

# 1. 数据库设计基础与租车系统概述
## 1.1 数据库设计基础
数据库设计是信息系统的核心,它涉及到数据的组织、存储和管理。良好的数据库设计可以使系统运行更加高效和稳定。在开始数据库设计之前,我们需要理解基本的数据模型,如实体-关系模型(ER模型),它有助于我们从现实世界中抽象出数据结构。接下来,我们会探讨数据库的规范化理论,它是减少数据冗余和提高数据一致性的关键。规范化过程将引导我们分解数据表,确保每一部分数据都保持其独立性和
【模块化设计】S7-200PLC喷泉控制灵活应对变化之道

# 1. S7-200 PLC与喷泉控制基础
## 1.1 S7-200 PLC概述
S7-200 PLC(Programmable Logic Controller)是西门子公司生产的一款小型可编程逻辑控制器,广泛应用于自动化领域。其以稳定、高效、易用性著称,特别适合于小型自动化项目,如喷泉控制。喷泉控制系统通过PLC来实现水位控制、水泵启停以及灯光变化等功能,能大大提高喷泉的
【项目管理】:如何在项目中成功应用FBP模型进行代码重构
# 1. FBP模型在项目管理中的重要性
在当今IT行业中,项目管理的效率和质量直接关系到企业的成功与否。而FBP模型(Flow-Based Programming Model)作为一种先进的项目管理方法,为处理复杂
【高斯信道与Chirp信号实战】:5大策略优化噪声环境下的信号传输

# 1. 高斯信道与Chirp信号基础
在现代通信系统中,对信号进行有效地传输和处理是至关重要的。本章将介绍高斯信道的基本概念以及Chirp信号的基础知识,为理解后续章节中的信号分析与优化策略奠定基
【可持续发展】:绿色交通与信号灯仿真的结合

# 1. 绿色交通的可持续发展意义
## 1.1 绿色交通的全球趋势
随着全球气候变化问题日益严峻,世界各国对环境保护的呼声越来越高。绿色交通作为一种有效减少污染、降低能耗的交通方式,成为实现可持续发展目标的重要组成部分。其核心在于减少碳排放,提高交通效率,促进经济、社会和环境的协调发展。
## 1.2 绿色交通的节能减排效益
相较于传统交通方式,绿色交
【同轴线老化与维护策略】:退化分析与更换建议

# 1. 同轴线的基本概念和功能
同轴电缆(Coaxial Cable)是一种广泛应用的传输介质,它由两个导体构成,一个是位于中心的铜质导体,另一个是包围中心导体的网状编织导体。两导体之间填充着绝缘材料,并由外部的绝缘护套保护。同轴线的主要功能是传输射频信号,广泛应用于有线电视、计算机网络、卫星通信及模拟信号的长距离传输等领域。
在物理结构上,
【Android主题制作工具推荐】:提升设计和开发效率的10大神器
# 1. Android主题制作的重要性与应用概述
## 1.1 Android主题制作的重要性
在移动应用领域,优秀的用户体验往往始于令人愉悦的视觉设计。Android主题制作不仅增强了视觉吸引力,更重要的是它能够提供一致性的
视觉SLAM技术应用指南:移动机器人中的应用详解与未来展望

# 1. 视觉SLAM技术概述
## 1.1 SLAM技术的重要性
在机器人导航、增强现实(AR)和虚拟现实(VR)等领域,空间定位
产品认证与合规性教程:确保你的STM32项目符合行业标准

# 1. 产品认证与合规性基础知识
在当今数字化和互联的时代,产品认证与合规性变得日益重要。以下是关于这一主题的几个基本概念:
## 1.1 产品认证的概念
产品认证是确认一个产品符合特定标准或法规要求的过程,通常由第三方机构进行。它确保了产品在安全性、功能性和质量方面的可靠性。
## 1.2 产品合规性的意义
合规性不仅保护消费者利益,还帮
【PSO-SVM算法调优】:专家分享,提升算法效率与稳定性的秘诀
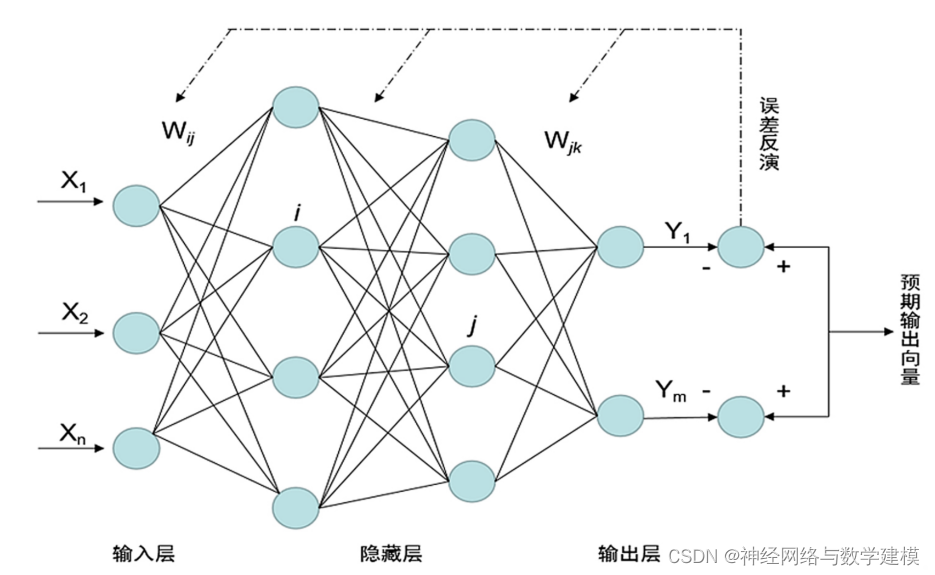
# 1. PSO-SVM算法概述
PSO-SVM算法结合了粒子群优化(PSO)和支持向量机(SVM)两种强大的机器学习技术,旨在提高分类和回归任务的性能。它通过PSO的全局优化能力来精细调节SVM的参数,优化后的SVM模型在保持高准确度的同时,展现出更好的泛化能力。本章将介绍PSO-SVM算法的来源、优势以及应用场景,为读者提供一个全面的理解框架。
## 1.1 算法来源与背景
PSO-SVM算法的来源基于两个领域:群体智能优化
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )