randperm人工智能新星:机器学习与深度学习中的随机排列之道
发布时间: 2024-07-01 22:24:29 阅读量: 4 订阅数: 7 
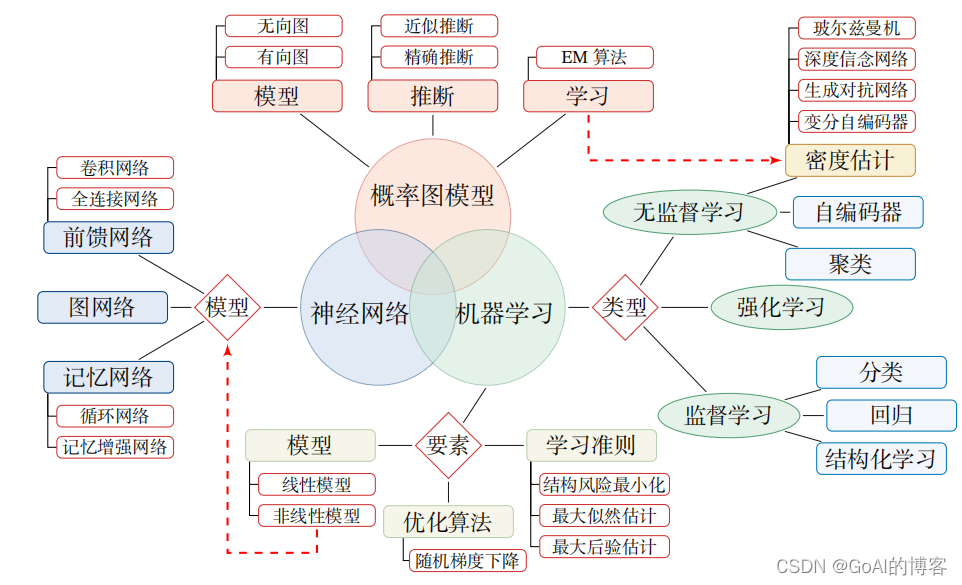
# 1. randperm简介和基本原理
**1.1 randperm简介**
randperm函数是MATLAB中用于生成随机排列的函数。它接受一个正整数n作为输入,并返回一个包含1到n之间的数字的随机排列。例如,randperm(5)可能返回[4 2 1 5 3]。
**1.2 randperm的基本原理**
randperm函数通过使用伪随机数生成器(PRNG)来生成随机排列。PRNG是一种算法,它可以生成一个看起来随机的数字序列,但实际上是由一个确定性种子决定的。randperm函数使用PRNG来生成一个0到n-1之间的均匀分布的随机数序列。然后,它将这些数字排列成一个随机排列。
# 2. randperm在机器学习中的应用
### 2.1 数据集划分与交叉验证
#### 2.1.1 数据集划分策略
数据集划分是机器学习中至关重要的步骤,用于将原始数据集分割为训练集、验证集和测试集。randperm函数可以帮助我们随机地划分数据集,以确保不同子集之间数据的独立性和代表性。
**代码块:**
```python
import numpy as np
# 原始数据集
dataset = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 使用randperm随机划分数据集
train_idx = np.random.randperm(len(dataset))[:int(len(dataset) * 0.8)]
val_idx = np.random.randperm(len(dataset))[int(len(dataset) * 0.8):int(len(dataset) * 0.9)]
test_idx = np.random.randperm(len(dataset))[int(len(dataset) * 0.9):]
# 划分后的子集
train_set = dataset[train_idx]
val_set = dataset[val_idx]
test_set = dataset[test_idx]
```
**逻辑分析:**
1. 首先,使用`np.random.randperm`函数生成一个长度为数据集长度的随机排列。
2. 然后,根据训练集、验证集和测试集的比例,使用切片操作从随机排列中提取相应的索引。
3. 最后,使用这些索引从原始数据集中提取对应的子集。
#### 2.1.2 交叉验证原理与实践
交叉验证是一种评估机器学习模型性能的有效方法,它通过多次训练和评估模型来减轻过拟合和提高模型的泛化能力。randperm函数可以帮助我们随机地生成交叉验证的折数和索引。
**代码块:**
```python
import numpy as np
# 原始数据集
dataset = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 设置交叉验证折数
k = 5
# 使用randperm随机生成交叉验证折数和索引
folds = np.random.randperm(len(dataset))
# 划分交叉验证折数
for i in range(k):
test_idx = folds[i * int(len(dataset) / k):(i + 1) * int(len(dataset) / k)]
train_idx = np.setdiff1d(folds, test_idx)
# 训练和评估模型
# ...
```
**逻辑分析:**
1. 首先,使用`np.random.randperm`函数生成一个长度为数据集长度的随机排列。
2. 然后,根据交叉验证折数,将随机排列划分为k个折数。
3. 对于每个折数,使用`np.setdiff1d`函数从随机排列中提取训练集和测试集的索引。
4. 最后,使用这些索引从原始数据集中提取对应的子集,并对模型进行训练和评估。
### 2.2 特征选择与降维
#### 2.2.1 特征选择算法
特征选择是机器学习中的一种技术,用于从原始特征集中选择最相关的特征子集。randperm函数可以帮助我们随机地生成特征子集,以进行特征选择算法的评估。
**代码块:**
```python
import numpy as np
# 原始特征集
features = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 使用randperm随机生成特征子集
subset_idx = np.random.randperm(features.shape[1])[:int(features.shape[1] * 0.5)]
# 选择特征子集
subset = features[:, subset_idx]
```
**逻辑分析:**
1. 首先,使用`np.random.randperm`函数生成一个长度为原始特征集列数的随机排列。
2. 然后,根据特征子集的大小,使用切片操作从随机排列中提取相应的索引。
3. 最后,使用这些索引从原始特征集中提取对应的特征子集。
#### 2.2.2 降维技术
降维是机器学习中的一种技术,用于将高维数据投影到低维空间中。randperm函数可以帮助我们随机地生成投影矩阵,以进行降维算法的评估。
**代码块:**
```python
import numpy as np
# 原始高维数据
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 设置投影维度
d = 2
# 使用randperm随机生成投影矩阵
projection_matrix = np.random.randperm(data.shape[1])[:d]
# 降维
reduced_data = data[:, projection_matrix]
```
**逻辑分析:**
1. 首先,使用`np.random.randperm`函数生成一个长度为原始数据列数的随机排列。
2. 然后,根据投
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏《randperm》深入探讨了 Python 中的随机数生成神器 randperm,揭示了其在数据分析、机器学习、统计推断、数据可视化、密码学、博弈论、金融建模、生物信息学、大数据、云计算、人工智能、物联网、区块链、网络安全、游戏开发和科学计算等领域的强大功能。专栏涵盖了 randperm 的性能优化、并行计算、数据增强、假设检验、交互式图表、加密算法安全性、策略模拟、风险评估、基因序列分析、随机数据流生成、区块链安全、恶意活动检测、随机关卡创建和复杂系统模拟等广泛应用。通过深入浅出的讲解和丰富的示例,专栏旨在帮助读者充分掌握 randperm 的强大功能,解锁数据科学和机器学习的无限潜力。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
威布尔分布在航空航天领域的应用:飞机部件可靠性和寿命预测,保障飞行安全

# 1. 威布尔分布的理论基础**
威布尔分布是一种广泛应用于可靠性分析和寿命预测的概率分布。它由美国统计学家沃伦·威布尔于1951年提出,具有以下特点:
- **非对称性:**威布尔分布的概率密度函数呈非对称性,尾部较长,表示随着时间的推移,故障率逐渐增加。
- **形状参数:**威布尔分布的形状参数β控制
从头开始构建通信框架:NFC 协议栈实现指南
# 1. NFC 协议栈基础**
NFC(近场通信)协议栈是一组通信协议,用于在近距离(通常小于 10 厘米)的设备之间建立安全通信。NFC 协议栈基于 ISO/IEC 1
stm32单片机在医疗设备中的应用:助力医疗设备创新和发展,提升医疗服务质量

# 1. STM32单片机简介
STM32单片机是意法半导体(STMicroelectronics)推出的一系列基于ARM Cortex-M内核的32位微控制器。它以其高性能、低功耗、丰富的外部设备和接口而闻名,广泛应用于医疗设备、工业控制、汽车电子等领域。
STM32单片机采用ARM Cortex-M内核,具有卓越的处理能力和能效。其低功耗特性使其非常适合于电池
ResNet50模型在科学研究中的应用:加速科学发现和突破,推动科学研究更深入
# 1. ResNet50模型简介
ResNet50模型是计算机视觉领域中一种深度残差网络,由何恺明等人于2015年提出。它是一种卷积神经网络(CNN),具有50层卷积层,以其深度和残差连接而著称。
残差连接是ResNet50模型的关键特征,它允许网络跳过中间层,直接将输入与输出相连接。这有助于解决深度神经网络中梯度消失的问题,并允许模型学习更深层次的特征。
ResNet50模型在图像分类、目标检测和语义分割等任务上取得了出色的性能。它已成
STM32 SRAM 与外设交互:实现高效数据交换,提升嵌入式系统性能
# 1. STM32 SRAM 简介**
SRAM(静态随机存取存储器)是一种易失性存储器,在 STM32 微控制器中广泛使用。它具有以下特点:
- **低功耗:**在空闲状态下,SRAM 的功耗极低。
- **高速:**SRAM 的访问速度比其他类型的内存(如闪存)快。
- **易于使用:**SRAM 可以通过简单的读写指令访问。
STM32 微控制器中的 SRAM 通常分为两类:
STM32在线编程在教育领域的应用:培养未来工程师,推动科技创新
# 1. STM32在线编程简介
STM32在线编程是一种通过互联网连接远程控制和编程微控制器的技术。它允许工程师和学生在无需物理接触设备的情况下进行编程、调试和更新。
在线编程为教育领域带来了革命性的变化,因为它消除了传统编程方法中对专用硬件和软件的依赖。它使学生能够随时随地通过互联网访问和操作STM32微控制器,从而极大地提高了学习效率和灵活性。
此外,在线编程还提供了丰富的协作和远程学习机会。学生可以与同
sinc函数:环境科学中的遥感和污染监测利器

# 1. 遥感与污染监测简介
遥感是一种从遥远距离获取地球信息的技术,它通过传感器收集目标区域的电磁辐射信号,并对其进行分析和处理,从而提取目标的物理、化学和生物特征信息。遥感技术广泛应用于环境
用半对数线图分析网络流量:揭示隐藏趋势,优化网络性能

# 1. 半对数线图概述
半对数线图是一种特殊类型的线图,其中一个轴(通常是 y 轴)采用对数刻度。这种刻度转换可以揭示数据中的模式和趋势,否则这些模式和趋势在常规线性刻度上可能不会明显。半对数线图广泛用于网络流量分析、金融数据可视化和科学研究等领域。
# 2. 半对数线图的理论基础
setenv在代码审查中的应用:提升代码审查的效率和质量,确保代码的正确性和可维护性

# 1. 代码审查概述**
代码审查是软件开发过程中至关重要的一步,旨在提高代码质量、减少错误并促进最佳实践。它涉及对代码进行系统检查,以识别潜在问题、改进设计并确保符合既定的标准。代码审查可以手动进行,也可以使用自动化工具辅助。
# 2. setenv在代码审查中的应用
### 2.1 setenv的原理和使用方法
setenv是一个用于设
存储和管理自动驾驶系统数据:Matlab mat文件在自动驾驶中的应用
# 1. 自动驾驶系统数据存储和管理概述**
自动驾驶系统需要处理大量的数据,包括传感器数据、决策数据和控制数据。为了有效地存储和管理这些数据,需要采用适当的数据存储和管理策略。
本概述将介绍自动驾驶系统中常用的数据存储格式,包括MATLAB mat文件、数据库和分布式文件系统。此外,还将讨论数据管理的最佳实践,包括数据组织、压缩和安全。
# 2. MATLAB mat文件在自动驾
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )