使用STM32F4的定时器功能
发布时间: 2023-12-15 00:41:03 阅读量: 62 订阅数: 42 
# 1. 简介
## 1.1 STM32F4的概述
STM32F4是意法半导体(STMicroelectronics)推出的一种32位微控制器系列,采用ARM Cortex-M4内核。它具有高性能、低功耗和丰富的外设功能,广泛应用于工业控制、嵌入式系统和物联网等领域。
## 1.2 定时器功能的作用和意义
定时器是STM32F4中重要的外设之一,它可以用来产生精确的时间延迟、频率测量、定时中断等功能。在许多应用场景中,定时器功能是必不可少的,例如传感器数据的采集、舵机的控制、PWM信号的生成等。
在本文中,我们将重点介绍STM32F4的定时器功能,包括其基本原理、各种配置方法和高级功能。我们还将提供一些实际应用案例,以帮助读者更好地理解和应用定时器功能。在接下来的章节中,我们将详细介绍这些内容。
# 2. STM32F4定时器功能的基本原理
STM32F4系列微控制器提供了多个定时器模块,其内置的定时器功能可以实现多种定时和计数任务。定时器模块可以根据外部引脚或内部时钟信号来触发定时事件,并生成指定的定时周期或脉冲输出。
在STM32F4中,定时器采用时钟预分频和计数寄存器来实现计时。每个定时器有一个时钟输入源,可以选择系统时钟(HCLK)或内部时钟源(如内部晶振)作为时钟输入。定时器的时钟频率会经过预分频器进行分频,以调整计数速度和计时精度。
2.1 定时器的工作原理
定时器的工作原理可以分为三个步骤:预分频、计数和中断/脉冲输出。
首先,通过配置定时器的预分频寄存器,可以设置时钟输入源的分频系数。预分频器被用来调整定时器的时钟频率,进而影响计数器的计数速度和计时精度。
其次,定时器的计数器根据时钟输入源的频率进行计数,并在计数达到指定值时触发中断或生成脉冲输出。计时过程中,可以通过读取计数器的值来获取定时器当前的计数值。
最后,定时器的中断/脉冲输出模块会根据计数器的计数情况,生成中断信号或脉冲输出。中断可以被用来触发软件中断服务程序,实现定时任务。脉冲输出可以被用来作为激励信号,驱动其他外部设备的工作。
2.2 STM32F4的定时器类型和功能
STM32F4提供了多个定时器类型和功能,包括基本定时器(TIM2、TIM3、TIM4、TIM5)、通用定时器(TIM1、TIM8)、高级定时器(TIM9~TIM14)等。
基本定时器可以实现简单的定时功能,适用于一些简单的计时任务。通用定时器和高级定时器则提供了更多的功能和灵活性,可以实现复杂的定时和计时任务,如脉冲宽度调制(PWM)输出、输入捕获、编码器接口等。
除了基本定时器和通用定时器,STM32F4还具有SysTick定时器,用于系统滴答定时。SysTick定时器是一个24位的向下计数器,可用于实现系统定时器、延时函数等。
在使用定时器功能之前,需要进行相应的配置,包括定时器模式的配置、时钟源的配置、预分频的配置、计数器和重装载值的配置等。接下来,我们将详细介绍STM32F4定时器的配置方法和使用注意事项。
# 3. STM32F4定时器的各种配置方法
在使用STM32F4的定时器功能时,我们需要对其进行一些配置才能达到我们想要的定时器工作方式。本章节将介绍STM32F4定时器的各种配置方法。
#### 3.1 定时器模式的配置
STM32F4的定时器可以分为一般定时器和高级定时器两种模式。一般定时器用于基本的计时和中断功能,而高级定时器则具备更多的功能,如输入捕获、输出比较和PWM输出等。
我们可以使用寄存器来配置定时器的模式。例如,对于一般定时器,我们可以通过设置 TIMx_CR1 寄存器的 ARPE 位启用自动重装载和更新事件。而对于高级定时器,我们还需要配置一些其他寄存器,如 TIMx_CCMR1 和 TIMx_CCMR2 来设置输入捕获和输出比较的功能。
下面是一个使用一般定时器模式的配置示例代码:
```c
#include "stm32f4xx.h"
void TIM_Config(void)
{
// 使能定时器时钟
RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM2, ENABLE);
// 配置定时器
TIM_TimeBaseInitTypeDef TIM_ConfigStruct;
TIM_ConfigStruct.TIM_Prescaler = 999; // 预分频值
TIM_ConfigStruct.TIM_CounterMode = TIM_CounterMode_Up; // 向上计数模式
TIM_ConfigStruct.TIM_Period = 9999; // 重载值
TIM_ConfigStruct.TIM_ClockDivision = TIM_CKD_DIV1; // 时钟分频
TIM_ConfigStruct.TIM_RepetitionCounter = 0; // 重复计数器值
TIM_TimeBaseInit(TIM2, &TIM_ConfigStruct);
// 使能定时器
TIM_Cmd(TIM2, ENABLE);
}
```
#### 3.2 定时器的时钟源配置
STM32F4的定时器可以选择不同的时钟源,包括内部时钟源和外部时钟源。这取决于对应定时器的时钟控制寄存器 (TIMx_CR1) 的配置。
例如,如果我们想把定时器的时钟源设置为内部时钟 (72 MHz),可以使用如下代码:
```c
#include "stm32f4xx.h"
void TIM_Config(void)
{
// 使能定时器时钟
RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM2, ENABLE);
// 配置定时器
TIM_TimeBaseInitTypeDef TIM_ConfigStruct;
TIM_ConfigStruct.TIM_Prescaler = 7199; // 预分频值,时钟分频为 72 MHz / (7199 + 1) = 10 kHz
TIM_ConfigStruct.TIM_CounterMode = TIM_CounterMode_Up; // 向上计数模式
TIM_ConfigStruct.TIM_Period = 9
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏是关于STM32F4系列微控制器的嵌入式开发专栏,旨在帮助读者全面了解并熟练应用STM32F4器件的各种功能和特性。专栏内容涵盖了入门指南,介绍了如何使用STM32F4进行嵌入式开发,以及对STM32F4的GPIO控制、时钟系统、中断处理功能、定时器功能、PWM输出、UART通信、SPI接口、I2C总线控制、ADC模块、DAC模块、DMA技术、RTC实时时钟模块、USB设备开发、SD卡读写操作、以太网通信、CAN总线通信和浮点数处理等进行深入剖析和应用案例的讲解。通过专栏学习,读者将能够全面掌握STM32F4系列微控制器的各项功能,并能熟练应用于嵌入式系统开发中,为实际项目的开发提供有力的支持。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【系统兼容性深度揭秘】:Win10 x64上的TensorFlow与CUDA完美匹配指南
# 摘要
本文详细探讨了在深度学习框架中系统兼容性的重要性,并深入介绍了CUDA的安装、配置以及TensorFlow环境的搭建过程。文章分析了不同版本CUDA与GPU硬件及NVIDIA驱动程序的兼容性需求,并提供了详细的安装步骤和故障排除方法。针对TensorFlow的安装与环境搭建,文章阐述了版本选择、依赖
先农熵数学模型:计算方法深度解析

# 摘要
先农熵模型作为一门新兴的数学分支,在理论和实际应用中显示出其独特的重要性。本文首先介绍了先农熵模型的概述和理论基础,阐述了熵的起源、定义及其在信息论中的应用,并详细解释了先农熵的定义和数学角色。接着,文章深入探讨了先农熵模型的计算方法,包括统计学和数值算法,并分析了软件实现的考量。文中还通过多个应用场景和案例,展示了先农熵模型在金融分析、生物信息学和跨学科研究中的实际应用。最后,本文提出了
【24小时精通电磁场矩量法】:从零基础到专业应用的完整指南

# 摘要
本文系统地介绍了电磁场理论与矩量法的基本概念和应用。首先概述了电磁场与矩量法的基本理论,包括麦克斯韦方程组和电磁波的基础知识,随后深入探讨了矩量法的理论基础,特别是基函数与权函数选择、阻抗矩阵和导纳矩阵的构建。接着,文章详述了矩量法的计算步骤,涵盖了实施流程、编程实现以及结果分析与验证。此外,本文还探讨了矩量法在天线分析、微波工程以及雷达散射截面计算等不同场景的应用,并介绍了高频近似技术、加速技术和
RS485通信原理与实践:揭秘偏置电阻最佳值的计算方法
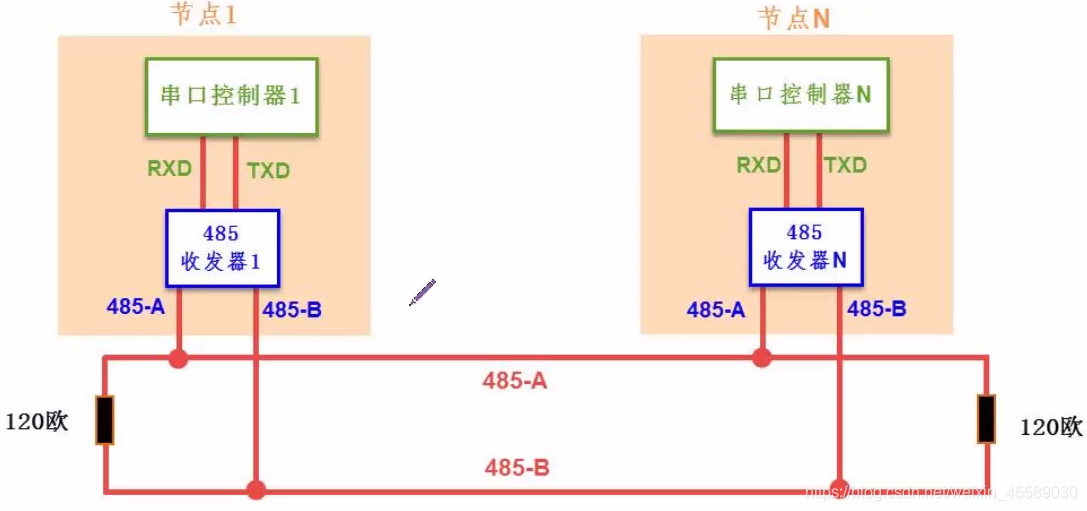
# 摘要
RS485通信作为一种广泛应用的串行通信技术,因其较高的抗干扰能力和远距离传输特性,在工业控制系统和智能设备领域具有重要地位。
【SOEM多线程编程秘籍】:线程同步与资源竞争的管理艺术

# 摘要
本文针对SOEM多线程编程提供了一个系统性的学习框架,涵盖多线程编程基础、同步机制、资源竞争处理、实践案例分析以及进阶技巧,并展望了未来发展趋势。首先,介绍了多线程编程的基本概念和线程同步机制,包括同步的必要性、锁的机制、同步工具的使用等。接着,深入探讨了资源竞争的识别、预防策略和调试技巧。随后
SRIO Gen2在嵌入式系统中的实现:设计要点与十大挑战分析

# 摘要
本文对SRIO Gen2技术在嵌入式系统中的应用进行了全面概述,探讨了设计要点、面临的挑战、实践应用以及未来发展趋势。首先,文章介绍了SRIO Gen2的基本概念及其在嵌入式系统中的系统架构和硬件设计考虑。随后,文章深入分析了SRIO Gen2在嵌入式系统中遇到的十大挑战,包括兼容性、性能瓶颈和实时性能要求。在实践应用方面,本文讨论了硬件设计、软件集成优化以及跨平台部署与维护的策略。最后,文章展望了SRI
【客户满意度提升神器】:EFQM模型在IT服务质量改进中的效果

# 摘要
本论文旨在深入分析EFQM模型在提升IT服务质量方面的作用和重要性。通过对EFQM模型基本原理、框架以及评估准则的阐述,本文揭示了其核心理念及实践策略,并探讨了如何有效实施该模型以改进服务流程和建立质量管理体系。案例研究部分强调了EFQM模型在实际IT服务中的成功应用,以及它如何促进服务创新和持续改进。最后,本论文讨论了应用EFQM模型时可能遇到的挑战,以及未来的发展趋势,包括
QZXing进阶技巧:如何优化二维码扫描速度与准确性?

# 摘要
随着移动设备和电子商务的迅速发展,QZXing作为一种广泛应用的二维码扫描技术,其性能直接影响用户体验。本文首先介绍了QZXing的基础知识及其应用场景,然后深入探讨了QZXing的理论架构,包括二维码编码机制、扫描流程解析,以及影响扫描速度与准确性的关键因素。为了优化扫描速度,文章提出了一系列实践策略,如调整解码算法、图像预处理技术,以及线程和并发优化。此外,本文还探讨了提升扫描准
【架构设计的挑战与机遇】:保险基础数据模型架构设计的思考

# 摘要
保险业务的高效运行离不开科学合理的架构设计,而基础数据模型作为架构的核心,对保险业务的数据化和管理至关重要。本文首先阐述了架构设计在保险业务中的重要性,随后介绍了保险基础数据模型的理论基础,包括定义、分类及其在保险领域的应用。在数据模型设计实践中,本文详细讨论了设计步骤、面向对象技术及数据库选择与部署
【AVR编程效率提升宝典】:遵循avrdude 6.3手册,实现开发流程优化
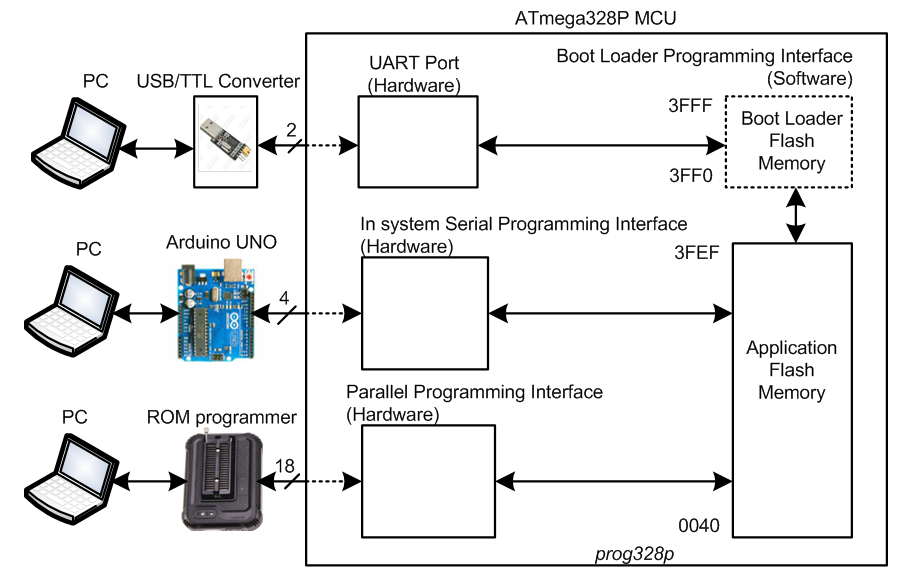
# 摘要
本文深入探讨了AVR编程和开发流程,重点分析了avrdude工具的使用与手册解读,从而为开发者提供了一个全面的指南。文章首先概述了avrdude工具的功能和架构,并进一步详细介绍了其安装、配置和在AVR开发中的应用。在开发流程优化方面,本文探讨了如何使用avrdude简化编译、烧录、验证和调
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )