揭秘YOLOv5:深度剖析算法原理与实现,赋能你的目标检测项目
发布时间: 2024-08-14 04:01:45 阅读量: 57 订阅数: 26 
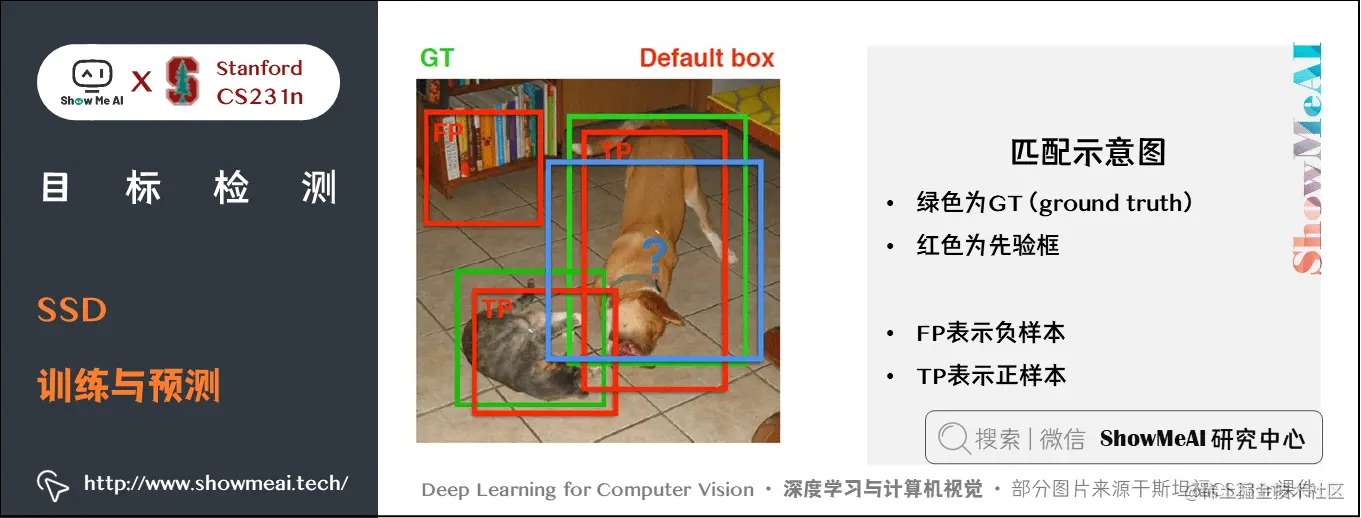
# 1. YOLOv5算法原理
### 1.1 卷积神经网络(CNN)简介
卷积神经网络(CNN)是一种深度学习模型,专门用于处理具有网格状结构的数据,例如图像。CNN通过使用卷积层、池化层和全连接层来提取图像中的特征。卷积层使用可学习的滤波器在图像上滑动,检测特定模式和特征。池化层减少图像的空间维度,同时保留重要特征。全连接层将卷积层提取的特征映射到最终输出。
### 1.2 目标检测概述
目标检测是一项计算机视觉任务,涉及在图像中定位和识别对象。传统的目标检测方法,如R-CNN和Fast R-CNN,采用两阶段流程:首先生成候选区域,然后对每个区域进行分类。YOLOv5采用单阶段方法,直接从输入图像中预测边界框和类别。
# 2. YOLOv5训练技巧
### 2.1 数据增强技术
数据增强是提高模型泛化能力和鲁棒性的关键技术。YOLOv5提供了丰富的图像变换和数据扩充技术,以增强训练数据的多样性。
#### 2.1.1 图像变换
图像变换包括:
- **随机缩放:**将图像缩放至不同尺寸,以模拟不同距离的目标。
- **随机裁剪:**从图像中随机裁剪不同区域,以增加训练数据的多样性。
- **随机翻转:**水平或垂直翻转图像,以增强模型对目标方向的不变性。
- **颜色抖动:**随机调整图像的亮度、对比度、饱和度和色相,以模拟不同的照明条件。
#### 2.1.2 数据扩充
数据扩充技术包括:
- **马赛克数据扩充:**将四张图像随机组合成一张马赛克图像,以增加训练数据的数量和多样性。
- **混合数据扩充:**将两张图像混合,以创建新的训练图像。
- **CutMix数据扩充:**从一张图像中随机裁剪一个区域,并将其粘贴到另一张图像中。
### 2.2 损失函数优化
损失函数是衡量模型预测与真实标签之间差异的函数。YOLOv5使用以下损失函数:
#### 2.2.1 交叉熵损失
交叉熵损失用于分类任务,衡量预测概率分布与真实标签之间的差异。
```python
def cross_entropy_loss(y_true, y_pred):
"""
计算交叉熵损失。
参数:
y_true:真实标签,形状为 (batch_size, num_classes)
y_pred:预测概率分布,形状为 (batch_size, num_classes)
返回:
交叉熵损失,形状为 (batch_size,)
"""
# 计算交叉熵损失
loss = -tf.reduce_sum(y_true * tf.math.log(y_pred), axis=-1)
return loss
```
#### 2.2.2 IOU损失
IOU(交并比)损失用于回归任务,衡量预测边界框与真实边界框之间的重叠程度。
```python
def iou_loss(y_true, y_pred):
"""
计算IOU损失。
参数:
y_true:真实边界框,形状为 (batch_size, num_boxes, 4)
y_pred:预测边界框,形状为 (batch_size, num_boxes, 4)
返回:
IOU损失,形状为 (batch_size,)
"""
# 计算IOU
inter = tf.math.intersect_area(y_true, y_pred)
union = tf.math.union_area(y_true, y_pred)
iou = inter / union
# 计算IOU损失
loss = 1 - iou
return loss
```
### 2.3 训练超参数调整
训练超参数是影响模型训练过程的参数。YOLOv5提供了以下训练超参数:
#### 2.3.1 学习率
学习率控制模型更新权重的速度。较高的学习率可能导致模型不稳定,而较低的学习率可能导致训练缓慢。
#### 2.3.2 批次大小
批次大小是每次训练迭代中使用的样本数量。较大的批次大小可以提高模型训练效率,但可能导致内存消耗增加。
# 3. YOLOv5模型部署
### 3.1 模型优化和压缩
在部署YOLOv5模型之前,为了提高模型的推理速度和降低内存占用,通常需要对模型进行优化和压缩。常用的方法包括量化和剪枝。
#### 3.1.1 量化
量化是一种将浮点权重和激活值转换为低精度格式(如int8或int16)的技术。通过降低精度,可以显著减少模型的大小和内存占用,同时保持模型的准确性。
**代码块:**
```python
import tensorflow as tf
# 加载预训练的YOLOv5模型
model = tf.keras.models.load_model('yolov5s.h5')
# 将模型量化为int8格式
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.int8]
quantized_model = converter.convert()
# 保存量化后的模型
with open('yolov5s_int8.tflite', 'wb') as f:
f.write(quantized_model)
```
**逻辑分析:**
* 使用`tf.keras.models.load_model()`加载预训练的YOLOv5模型。
* 使用`tf.lite.TFLiteConverter.from_keras_model()`创建TFLite转换器。
* 设置转换器的优化级别为`tf.lite.Optimize.DEFAULT`。
* 将目标规范的受支持类型设置为`tf.int8`。
* 调用`converter.convert()`将模型量化为int8格式。
* 将量化后的模型保存到文件中。
#### 3.1.2 剪枝
剪枝是一种移除模型中不重要的权重和神经元的方法。通过剪枝,可以减少模型的大小和计算成本,而不会显著降低模型的准确性。
**代码块:**
```python
import tensorflow as tf
from tensorflow.keras.models import Model
# 加载预训练的YOLOv5模型
model = tf.keras.models.load_model('yolov5s.h5')
# 创建一个新的模型,只包含重要的层
pruned_model = Model(model.input, model.get_layer('output').output)
# 保存剪枝后的模型
pruned_model.save('yolov5s_pruned.h5')
```
**逻辑分析:**
* 使用`tf.keras.models.load_model()`加载预训练的YOLOv5模型。
* 创建一个新的模型`pruned_model`,只包含重要的层。
* 使用`model.get_layer()`获取输出层的引用。
* 将剪枝后的模型保存到文件中。
### 3.2 模型推理引擎
模型推理引擎是用于在设备上部署和执行机器学习模型的软件库。常用的推理引擎包括TensorFlow Lite和ONNX Runtime。
#### 3.2.1 TensorFlow Lite
TensorFlow Lite是一个轻量级的推理引擎,专为移动和嵌入式设备而设计。它支持各种模型格式,包括TFLite模型和Keras模型。
**代码块:**
```python
import tensorflow as tf
# 加载量化后的YOLOv5模型
interpreter = tf.lite.Interpreter('yolov5s_int8.tflite')
interpreter.allocate_tensors()
# 输入图像
input_image = tf.image.resize(image, (416, 416))
input_image = input_image / 255.0
# 执行推理
output = interpreter.invoke([input_image])
# 解析输出
detections = output[0]
```
**逻辑分析:**
* 使用`tf.lite.Interpreter()`加载量化后的YOLOv5模型。
* 分配模型的张量。
* 预处理输入图像,将其调整为模型的输入大小并归一化。
* 调用`interpreter.invoke()`执行推理。
* 解析推理输出,提取检测结果。
#### 3.2.2 ONNX Runtime
ONNX Runtime是一个开源推理引擎,支持多种模型格式,包括ONNX模型和PyTorch模型。它以其高性能和跨平台支持而闻名。
**代码块:**
```python
import onnxruntime
# 加载ONNX模型
session = onnxruntime.InferenceSession('yolov5s.onnx')
# 输入图像
input_image = tf.image.resize(image, (416, 416))
input_image = input_image / 255.0
# 执行推理
output = session.run(['output'], {'input': input_image})
# 解析输出
detections = output[0]
```
**逻辑分析:**
* 使用`onnxruntime.InferenceSession()`加载ONNX模型。
* 预处理输入图像,将其调整为模型的输入大小并归一化。
* 调用`session.run()`执行推理。
* 解析推理输出,提取检测结果。
### 3.3 实时目标检测应用
部署YOLOv5模型后,可以将其集成到实时目标检测应用中。常见的应用场景包括移动端部署和云端部署。
#### 3.3.1 移动端部署
移动端部署是指将YOLOv5模型部署到智能手机或其他移动设备上。这需要使用移动推理引擎,如TensorFlow Lite或Core ML。
**代码块:**
```python
import tensorflow as tf
# 加载量化后的YOLOv5模型
interpreter = tf.lite.Interpreter('yolov5s_int8.tflite')
interpreter.allocate_tensors()
# 创建摄像头对象
cap = cv2.VideoCapture(0)
while True:
# 读取帧
ret, frame = cap.read()
# 预处理帧
frame = tf.image.resize(frame, (416, 416))
frame = frame / 255.0
# 执行推理
output = interpreter.invoke([frame])
# 解析输出
detections = output[0]
# 绘制检测结果
for detection in detections:
cv2.rectangle(frame, (detection[0], detection[1]), (detection[2], detection[3]), (0, 255, 0), 2)
# 显示帧
cv2.imshow('frame', frame)
# 按'q'键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
```
**逻辑分析:**
* 使用`cv2.VideoCapture()`创建摄像头对象。
* 在循环中读取帧并进行预处理。
* 调用`interpreter.invoke()`执行推理。
* 解析推理输出,提取检测结果。
* 绘制检测结果到帧上。
* 显示帧。
* 按'q'键退出循环。
#### 3.3.2 云端部署
云端部署是指将YOLOv5模型部署到云服务器上。这需要使用云推理服务,如AWS SageMaker或Google Cloud AI Platform。
**代码块:**
```python
import boto3
# 创建SageMaker端点
client = boto3.client('sagemaker-runtime')
endpoint_name = 'yolov5-endpoint'
# 预处理图像
image = tf.image.resize(image, (416, 416))
image = image / 255.0
# 发送推理请求
response = client.invoke_endpoint(
EndpointName=endpoint_name,
Body=image.numpy()
)
# 解析推理输出
detections = response['Body'].read()
```
**逻辑分析:**
* 使用`boto3.client()`创建SageMaker客户端。
* 创建SageMaker端点。
* 预处理图像。
* 使用`invoke_endpoint()`发送推理请求。
* 解析推理输出,提取检测结果。
# 4. YOLOv5进阶应用
### 4.1 多目标跟踪
多目标跟踪(MOT)旨在识别、跟踪和关联视频序列中的多个目标。YOLOv5可以作为MOT系统中的目标检测组件,为后续的跟踪算法提供准确的检测结果。
**4.1.1 匈牙利算法**
匈牙利算法是一种解决指派问题的经典算法。在MOT中,它用于将检测到的目标与跟踪目标进行关联。算法的核心思想是找到一个最优匹配,使得目标与跟踪之间的总距离最小。
```python
import numpy as np
def hungarian_algorithm(cost_matrix):
"""
匈牙利算法求解指派问题
参数:
cost_matrix:目标和跟踪之间的代价矩阵
返回:
匹配结果
"""
# 1. 寻找行最小值并减去
row_min = np.min(cost_matrix, axis=1)
cost_matrix -= row_min.reshape(-1, 1)
# 2. 寻找列最小值并减去
col_min = np.min(cost_matrix, axis=0)
cost_matrix -= col_min
# 3. 标记行和列
rows_covered = np.zeros(cost_matrix.shape[0], dtype=bool)
cols_covered = np.zeros(cost_matrix.shape[1], dtype=bool)
# 4. 寻找星号行
star_rows = []
for i in range(cost_matrix.shape[0]):
if np.sum(cost_matrix[i, :]) == 0:
star_rows.append(i)
# 5. 寻找星号列
star_cols = []
for j in range(cost_matrix.shape[1]):
if np.sum(cost_matrix[:, j]) == 0:
star_cols.append(j)
# 6. 寻找增广路径
while len(star_rows) != len(star_cols):
# 寻找未覆盖行中最小值
row_min = np.min(cost_matrix[~rows_covered, :])
# 寻找未覆盖列中最小值
col_min = np.min(cost_matrix[:, ~cols_covered])
# 如果最小值相同,则标记行和列
if row_min == col_min:
for i in range(cost_matrix.shape[0]):
if cost_matrix[i, :] == row_min:
rows_covered[i] = True
for j in range(cost_matrix.shape[1]):
if cost_matrix[:, j] == col_min:
cols_covered[j] = True
# 如果最小值不同,则寻找增广路径
else:
# 寻找未覆盖行中最小值的索引
row_idx = np.argmin(cost_matrix[~rows_covered, :])
# 寻找未覆盖列中最小值的索引
col_idx = np.argmin(cost_matrix[:, ~cols_covered])
# 标记行和列
rows_covered[row_idx] = True
cols_covered[col_idx] = True
# 寻找增广路径
while row_idx != star_rows[-1]:
# 寻找未覆盖行中与当前列相交的最小值
row_min = np.min(cost_matrix[~rows_covered, col_idx])
# 寻找未覆盖列中与当前行相交的最小值
col_min = np.min(cost_matrix[row_idx, ~cols_covered])
# 如果最小值相同,则标记行和列
if row_min == col_min:
for i in range(cost_matrix.shape[0]):
if cost_matrix[i, col_idx] == row_min:
rows_covered[i] = True
for j in range(cost_matrix.shape[1]):
if cost_matrix[row_idx, j] == col_min:
cols_covered[j] = True
# 如果最小值不同,则更新当前行和列
else:
row_idx = np.argmin(cost_matrix[~rows_covered, col_idx])
col_idx = np.argmin(cost_matrix[row_idx, ~cols_covered])
# 添加星号行
star_rows.append(row_idx)
# 7. 寻找匹配结果
matches = []
for i in range(cost_matrix.shape[0]):
if rows_covered[i]:
for j in range(cost_matrix.shape[1]):
if cost_matrix[i, j] == 0 and cols_covered[j]:
matches.append((i, j))
return matches
```
### 4.1.2 卡尔曼滤波
卡尔曼滤波是一种状态估计算法,可以根据观测值预测目标的运动状态。在MOT中,卡尔曼滤波用于预测目标的位置和速度,从而提高跟踪的准确性和鲁棒性。
```python
import numpy as np
class KalmanFilter:
"""
卡尔曼滤波器
参数:
state_size:状态向量维度
measurement_size:测量向量维度
transition_matrix:状态转移矩阵
measurement_matrix:测量矩阵
process_noise_cov:过程噪声协方差矩阵
measurement_noise_cov:测量噪声协方差矩阵
"""
def __init__(self, state_size, measurement_size, transition_matrix, measurement_matrix, process_noise_cov, measurement_noise_cov):
self.state_size = state_size
self.measurement_size = measurement_size
self.transition_matrix = transition_matrix
self.measurement_matrix = measurement_matrix
self.process_noise_cov = process_noise_cov
self.measurement_noise_cov = measurement_noise_cov
# 状态向量
self.state = np.zeros((state_size, 1))
# 协方差矩阵
self.cov = np.eye(state_size)
def predict(self):
"""
预测状态
"""
# 状态转移
self.state = np.dot(self.transition_matrix, self.state)
# 协方差更新
self.cov = np.dot(np.dot(self.transition_matrix, self.cov), self.transition_matrix.T) + self.process_noise_cov
def update(self, measurement):
"""
更新状态
参数:
measurement:测量值
"""
# 计算卡尔曼增益
kalman_gain = np.dot(np.dot(self.cov, self.measurement_matrix.T), np.linalg.inv(self.measurement_noise_cov + np.dot(np.dot(self.measurement_matrix, self.cov), self.measurement_matrix.T)))
# 更新状态
self.state = self.state + np.dot(kalman_gain, (measurement - np.dot(self.measurement_matrix, self.state)))
# 更新协方差
self.cov = np.dot((np.eye(self.state_size) - np.dot(kalman_gain, self.measurement_matrix)), self.cov)
def get_state(self):
"""
获取状态向量
"""
return self.state
```
### 4.2 人体姿态估计
人体姿态估计旨在检测和识别图像或视频中人体的关键点。YOLOv5可以作为姿态估计系统中的检测组件,为后续的关键点检测算法提供准确的边界框。
**4.2.1 OpenPose**
OpenPose是一个流行的人体姿态估计库,它使用卷积神经网络来检测和识别图像或视频中的人体关键点。
```python
import cv2
import numpy as np
import openpose
# 初始化OpenPose
op = openpose.WrapperPython()
# 设置参数
params = dict()
params["model_folder"] = "models/"
params["net_resolution"] = "320x240"
params["alpha_pose"] = 0.6
params["scale_gap"] = 0.3
params["scale_number"] = 1
params["render_threshold"] = 0.05
op.configure(params)
op.start()
# 读取图像
image = cv2.imread("image.jpg")
# 预处理图像
image = cv2.resize(image, (320, 240))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 人体姿态估计
# 5. YOLOv5与其他目标检测算法对比
### 5.1 速度与精度权衡
YOLOv5以其速度和精度之间的出色平衡而著称。在速度方面,YOLOv5在实时目标检测任务中表现出色,每秒可以处理大量帧。在精度方面,YOLOv5也取得了令人印象深刻的结果,在COCO数据集上实现了46.0%的AP。
为了实现速度和精度的平衡,YOLOv5采用了以下策略:
- **轻量级网络结构:**YOLOv5的网络结构相对较轻,这有助于降低计算成本并提高推理速度。
- **高效的卷积层:**YOLOv5使用深度可分离卷积和移动卷积等高效卷积层,以减少计算量。
- **FPN和PAN:**YOLOv5采用特征金字塔网络(FPN)和路径聚合网络(PAN)来融合不同尺度的特征,这有助于提高精度。
### 5.2 不同应用场景下的选择
YOLOv5是一款通用目标检测算法,适用于各种应用场景。以下是YOLOv5在不同场景下的表现:
| 应用场景 | 优势 |
|---|---|
| 实时目标检测 | 高速度、低延迟 |
| 图像分类 | 高精度 |
| 视频分析 | 实时处理、高吞吐量 |
| 自动驾驶 | 高精度、鲁棒性 |
| 医疗影像 | 高精度、可解释性 |
### 5.3 未来发展趋势
YOLOv5仍在不断发展,未来有望在以下方面取得进展:
- **更高的精度:**通过采用新的网络结构和训练技术,提高YOLOv5的检测精度。
- **更快的速度:**通过优化推理引擎和部署策略,进一步提高YOLOv5的推理速度。
- **更广泛的应用:**探索YOLOv5在更多应用场景中的潜力,例如异常检测、人脸识别和医疗诊断。
# 6. YOLOv5项目实践**
**6.1 自定义数据集准备**
1. **收集数据:**收集与目标检测任务相关的图像和标注数据。
2. **数据预处理:**调整图像大小、转换格式、应用数据增强技术(如旋转、翻转、裁剪)。
3. **标注数据:**使用标注工具(如LabelImg、VGG Image Annotator)对图像中的目标进行标注,包括边界框和类别。
4. **数据分割:**将数据集分割为训练集、验证集和测试集,以评估模型性能。
**6.2 模型训练与评估**
1. **模型选择:**选择合适的YOLOv5模型,如YOLOv5s、YOLOv5m或YOLOv5l,根据精度和速度要求进行权衡。
2. **训练配置:**设置训练参数,包括学习率、批次大小、训练轮数和优化器。
3. **训练过程:**使用训练框架(如PyTorch、TensorFlow)训练模型,并通过训练损失和验证精度监控训练进度。
4. **模型评估:**在测试集上评估模型性能,使用指标如平均精度(mAP)、召回率和准确率。
**6.3 实时目标检测系统构建**
1. **模型部署:**将训练好的模型部署到推理引擎(如TensorFlow Lite、ONNX Runtime)中。
2. **视频流获取:**获取视频流,可以来自摄像头、视频文件或网络流。
3. **目标检测:**使用推理引擎对视频帧进行目标检测,并输出边界框和类别信息。
4. **可视化结果:**将检测结果可视化,在视频帧上绘制边界框和标签。
5. **系统集成:**将目标检测系统集成到应用中,如安全监控、自动驾驶或机器人视觉。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《YOLO识别游戏》专栏深入探讨了YOLOv5目标检测算法在游戏领域的应用,从零基础到精通,全面解析算法原理和实现。专栏涵盖了YOLOv5在游戏中的性能调优、与其他算法的对比、部署和集成、数据预处理和增强、后处理和可视化、实时推理和优化、多目标检测、小目标检测、遮挡目标检测、运动目标检测、低光照目标检测和实时目标跟踪等关键技术。通过一系列实战指南和深入分析,该专栏旨在帮助开发者和游戏爱好者快速掌握YOLOv5在游戏中的应用,赋能游戏体验,打造沉浸式游戏世界。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
打印机维护必修课:彻底清除爱普生R230废墨,提升打印质量!
# 摘要
本文旨在详细介绍爱普生R230打印机废墨清除的过程,包括废墨产生的原因、废墨清除对打印质量的重要性以及废墨系统结构的原理。文章首先阐述了废墨清除的理论基础,解释了废墨产生的过程及其对打印效果的影响,并强调了及时清除废墨的必要性。随后,介绍了在废墨清除过程中需要准备的工具和材料,提供了详细的操作步骤和安全指南。最后,讨论了清除废墨时可能遇到的常见问题及相应的解决方案,并分享了一些提升打印质量的高级技巧和建议,为用户提供全面的废墨处理指导和打印质量提升方法。
# 关键字
废墨清除;打印质量;打印机维护;安全操作;颜色管理;打印纸选择
参考资源链接:[爱普生R230打印机废墨清零方法图
【大数据生态构建】:Talend与Hadoop的无缝集成指南

# 摘要
随着信息技术的迅速发展,大数据生态正变得日益复杂并受到广泛关注。本文首先概述了大数据生态的组成和Talend与Hadoop的基本知识。接着,深入探讨了Talend与Hadoop的集成原理,包括技术基础和连接器的应用。在实践案例分析中,本文展示了如何利
【Quectel-CM驱动优化】:彻底解决4G连接问题,提升网络体验

# 摘要
本文详细介绍了Quectel-CM驱动在连接性问题分析和性能优化方面的工作。首先概述了Quectel-CM驱动的基本情况和连接问题,然后深入探讨了网络驱动性能优化的理论基础,包括网络协议栈工作原理和驱动架构解析。文章接着通
【Java代码审计效率工具箱】:静态分析工具的正确打开方式

# 摘要
本文探讨了Java代码审计的重要性,并着重分析了静态代码分析的理论基础及其实践应用。首先,文章强调了静态代码分析在提高软件质量和安全性方面的作用,并介绍了其基本原理,包括词法分析、语法分析、数据流分析和控制流分析。其次,文章讨论了静态代码分析工具的选取、安装以及优化配置的实践过程,同时强调了在不同场景下,如开源项目和企业级代码审计中应用静态分析工具的策略。文章最后展望了静态代码分析工具的未来发展趋势,特别
深入理解K-means:提升聚类质量的算法参数优化秘籍
# 摘要
K-means算法作为数据挖掘和模式识别中的一种重要聚类技术,因其简单高效而广泛应用于多个领域。本文首先介绍了K-means算法的基础原理,然后深入探讨了参数选择和初始化方法对算法性能的影响。针对实践应用,本文提出了数据预处理、聚类过程优化以及结果评估的方法和技巧。文章继续探索了K-means算法的高级优化技术和高维数据聚类的挑战,并通过实际案例分析,展示了算法在不同领域的应用效果。最后,本文分析了K-means算法的性能,并讨论了优化策略和未来的发展方向,旨在提升算法在大数据环境下的适用性和效果。
# 关键字
K-means算法;参数选择;距离度量;数据预处理;聚类优化;性能调优
【GP脚本新手速成】:一步步打造高效GP Systems Scripting Language脚本
# 摘要
本文旨在全面介绍GP Systems Scripting Language,简称为GP脚本,这是一种专门为数据处理和系统管理设计的脚本语言。文章首先介绍了GP脚本的基本语法和结构,阐述了其元素组成、变量和数据类型、以及控制流语句。随后,文章深入探讨了GP脚本操作数据库的能力,包括连接、查询、结果集处理和事务管理。本文还涉及了函数定义、模块化编程的优势,以及GP脚本在数据处理、系统监控、日志分析、网络通信以及自动化备份和恢复方面的实践应用案例。此外,文章提供了高级脚本编程技术、性能优化、调试技巧,以及安全性实践。最后,针对GP脚本在项目开发中的应用,文中给出了项目需求分析、脚本开发、集
【降噪耳机设计全攻略】:从零到专家,打造完美音质与降噪效果的私密秘籍

# 摘要
随着技术的不断进步和用户对高音质体验的需求增长,降噪耳机设计已成为一个重要的研究领域。本文首先概述了降噪耳机的设计要点,然后介绍了声学基础与噪声控制理论,阐述了声音的物理特性和噪声对听觉的影
【MIPI D-PHY调试与测试】:提升验证流程效率的终极指南

# 摘要
本文系统地介绍了MIPI D-PHY技术的基础知识、调试工具、测试设备及其配置,以及MIPI D-PHY协议的分析与测试。通过对调试流程和性能优化的详解,以及自动化测试框架的构建和测试案例的高级分析,本文旨在为开发者和测试工程师提供全面的指导。文章不仅深入探讨了信号完整性和误码率测试的重要性,还详细说明了调试过程中的问题诊断
SAP BASIS升级专家:平滑升级新系统的策略

# 摘要
SAP BASIS升级是确保企业ERP系统稳定运行和功能适应性的重要环节。本文从平滑升级的理论基础出发,深入探讨了SAP BASIS升级的基本概念、目的和步骤,以及系统兼容性和业务连续性的关键因素。文中详细描述了升级前的准备、监控管理、功能模块升级、数据库迁移与优化等实践操作,并强调了系统测试、验证升级效果和性能调优的重要性。通过案例研究,本文分析了实际项目中
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )