Python与雪花代码的完美结合:解锁数据分析新境界
发布时间: 2024-06-19 18:16:30 阅读量: 94 订阅数: 34 

Python和数据分析

# 1. Python与雪花代码简介
Python是一种流行的高级编程语言,以其易用性、灵活性以及广泛的库而闻名。雪花代码是一个云数据仓库,提供快速、可扩展和安全的存储和处理数据的能力。
Python与雪花代码的结合为数据科学家、分析师和开发人员提供了强大的工具,用于从数据中获取见解。通过使用Python的强大数据处理和分析功能以及雪花代码的云计算能力,用户可以高效地执行复杂的数据任务。
# 2. Python与雪花代码的数据连接
### 2.1 Python连接雪花代码
#### 2.1.1 使用Snowflake Connector for Python
**安装:**
```
pip install snowflake-connector-python
```
**连接:**
```python
import snowflake.connector
# 创建连接对象
conn = snowflake.connector.connect(
user='<your_username>',
password='<your_password>',
account='<your_account_name>',
database='<your_database_name>',
schema='<your_schema_name>',
warehouse='<your_warehouse_name>'
)
```
**参数说明:**
* `user`: 雪花代码用户名
* `password`: 雪花代码密码
* `account`: 雪花代码账户名称
* `database`: 要连接的数据库名称
* `schema`: 要连接的模式名称
* `warehouse`: 要使用的仓库名称
#### 2.1.2 使用SQLAlchemy连接雪花代码
**安装:**
```
pip install sqlalchemy-snowflake
```
**连接:**
```python
from sqlalchemy import create_engine
# 创建引擎对象
engine = create_engine(
"snowflake://<your_username>:<your_password>@<your_account_name>/<your_database_name>",
connect_args={
"warehouse": "<your_warehouse_name>",
"schema": "<your_schema_name>"
}
)
```
**参数说明:**
* `user`: 雪花代码用户名
* `password`: 雪花代码密码
* `account`: 雪花代码账户名称
* `database`: 要连接的数据库名称
* `warehouse`: 要使用的仓库名称
* `schema`: 要连接的模式名称
### 2.2 雪花代码数据类型与Python数据类型的映射
#### 2.2.1 基本数据类型
| 雪花代码数据类型 | Python数据类型 |
|---|---|
| TEXT | str |
| INTEGER | int |
| FLOAT | float |
| DATE | datetime.date |
| TIME | datetime.time |
| TIMESTAMP | datetime.datetime |
#### 2.2.2 复杂数据类型
| 雪花代码数据类型 | Python数据类型 |
|---|---|
| ARRAY | list |
| OBJECT | dict |
# 3. Python与雪花代码的数据操作
### 3.1 数据查询和检索
#### 3.1.1 使用Python执行SQL查询
使用Python连接到雪花代码后,可以使用`cursor.execute()`方法执行SQL查询。查询结果将存储在游标对象中,可以逐行迭代或使用`fetchall()`方法一次性获取所有结果。
```python
import snowflake.connector
# 创建一个连接
conn = snowflake.connector.connect(
user='<username>',
password='<password>',
account='<account_name>',
database='<database_name>',
schema='<schema_name>'
)
# 创建一个游标
cur = conn.cursor()
# 执行一个查询
cur.execute("SELECT * FROM my_table")
# 获取查询结果
results = cur.fetchall()
# 遍历结果
for row in results:
print(row)
```
#### 3.1.2 处理查询结果
查询结果是一个元组列表,其中每个元组代表一行。可以使用索引或属性访问元组中的列值。
```python
# 获取第一行
first_row = results[0]
# 使用索引访问列值
print(first_row[0]) # 输出第一列的值
# 使用属性访问列值
print(first_row.column_name) # 输出名为"column_name"的列的值
```
### 3.2 数据插入、更新和删除
#### 3.2.1 使用Python插入数据
可以使用`cursor.execute()`方法执行`INSERT`语句来插入数据。`VALUES`子句可以是元组、列表或字典。
```python
# 插入一行数据
cur.execute("INSERT INTO my_table (name, age) VALUES ('John', 30)")
# 插入多行数据
data = [('Jane', 25), ('Tom', 35)]
cur.executemany("INSERT INTO my_table (name, age) VALUES (?, ?)", data)
```
#### 3.2.2 使用Python更新数据
可以使用`cursor.execute()`方法执行`UPDATE`语句来更新数据。`SET`子句可以是元组、列表或字典。
```python
# 更新一行数据
cur.execute("UPDATE my_table SET age = 31 WHERE name = 'John'")
# 更新多行数据
data = [('Jane', 26), ('Tom', 36)]
cur.executemany("UPDATE my_table SET age = ? WHERE name = ?", data)
```
#### 3.2.3 使用Python删除数据
可以使用`cursor.execute()`方法执行`DELETE`语句来删除数据。`WHERE`子句可以是元组、列表或字典。
```python
# 删除一行数据
cur.execute("DELETE FROM my_table WHERE name = 'John'")
# 删除多行数据
data = [('Jane', 25), ('Tom', 35)]
cur.executemany("DELETE FROM my_table WHERE name = ?", data)
```
# 4. Python与雪花代码的数据分析
### 4.1 使用Python进行数据分析
#### 4.1.1 使用Pandas进行数据分析
Pandas是一个功能强大的Python库,用于数据操作和分析。它提供了各种工具来处理数据框和时间序列,包括数据过滤、聚合、排序和可视化。
要使用Pandas连接到雪花代码,可以使用`snowflake.connector`包中的`connect`函数。该函数接受以下参数:
```python
def connect(user, password, account, database, schema, warehouse, role=None, session_parameters=None):
```
* **user:**雪花代码用户名
* **password:**雪花代码密码
* **account:**雪花代码账户名
* **database:**雪花代码数据库名
* **schema:**雪花代码模式名
* **warehouse:**雪花代码仓库名
* **role:**雪花代码角色名(可选)
* **session_parameters:**雪花代码会话参数(可选)
连接成功后,可以使用Pandas的`read_sql`函数从雪花代码中读取数据:
```python
import pandas as pd
# 连接到雪花代码
conn = snowflake.connector.connect(
user="username",
password="password",
account="account_name",
database="database_name",
schema="schema_name",
warehouse="warehouse_name",
)
# 从雪花代码读取数据
df = pd.read_sql("SELECT * FROM table_name", conn)
```
Pandas提供了各种方法来处理数据框,包括:
* **数据过滤:**使用`query`或`filter`方法
* **数据聚合:**使用`groupby`和`agg`方法
* **数据排序:**使用`sort_values`方法
* **数据可视化:**使用`plot`方法
#### 4.1.2 使用NumPy进行数值计算
NumPy是一个Python库,用于科学计算。它提供了各种工具来处理多维数组,包括矩阵运算、线性代数和傅里叶变换。
要使用NumPy连接到雪花代码,可以使用`snowflake.connector`包中的`connect`函数。该函数接受以下参数:
```python
def connect(user, password, account, database, schema, warehouse, role=None, session_parameters=None):
```
* **user:**雪花代码用户名
* **password:**雪花代码密码
* **account:**雪花代码账户名
* **database:**雪花代码数据库名
* **schema:**雪花代码模式名
* **warehouse:**雪花代码仓库名
* **role:**雪花代码角色名(可选)
* **session_parameters:**雪花代码会话参数(可选)
连接成功后,可以使用NumPy的`loadtxt`函数从雪花代码中读取数据:
```python
import numpy as np
# 连接到雪花代码
conn = snowflake.connector.connect(
user="username",
password="password",
account="account_name",
database="database_name",
schema="schema_name",
warehouse="warehouse_name",
)
# 从雪花代码读取数据
data = np.loadtxt("SELECT * FROM table_name", conn)
```
NumPy提供了各种方法来处理多维数组,包括:
* **矩阵运算:**使用`dot`和`linalg`模块
* **线性代数:**使用`linalg`模块
* **傅里叶变换:**使用`fft`模块
### 4.2 使用Snowflake代码的分析功能
#### 4.2.1 使用Snowflake代码的内置分析函数
雪花代码提供了一系列内置分析函数,用于执行各种数据分析任务,包括聚合、过滤和排序。这些函数可以在SQL查询中使用,也可以在Python脚本中使用。
以下是一些常用的雪花代码内置分析函数:
| 函数 | 描述 |
|---|---|
| SUM | 计算一列中值的总和 |
| AVG | 计算一列中值的平均值 |
| MIN | 计算一列中值的最小值 |
| MAX | 计算一列中值的最小值 |
| COUNT | 计算一列中非空值的个数 |
| GROUP BY | 根据一列或多列对数据进行分组 |
| ORDER BY | 根据一列或多列对数据进行排序 |
| FILTER | 根据条件过滤数据 |
#### 4.2.2 使用Snowflake代码的自定义函数
除了内置分析函数之外,雪花代码还允许用户创建自己的自定义函数。这些函数可以用于执行更复杂的数据分析任务,例如机器学习算法或文本分析。
要创建自定义函数,可以使用以下语法:
```sql
CREATE FUNCTION function_name (
argument1 data_type,
argument2 data_type,
...
)
RETURNS data_type
AS
-- 函数代码
```
自定义函数可以在SQL查询中或Python脚本中使用。
以下是一个使用Python脚本调用雪花代码自定义函数的示例:
```python
import snowflake.connector
# 连接到雪花代码
conn = snowflake.connector.connect(
user="username",
password="password",
account="account_name",
database="database_name",
schema="schema_name",
warehouse="warehouse_name",
)
# 调用自定义函数
cursor = conn.cursor()
cursor.execute("SELECT my_function(argument1, argument2) FROM table_name")
results = cursor.fetchall()
# 处理结果
for row in results:
print(row)
```
# 5. Python与雪花代码的机器学习
### 5.1 使用Python进行机器学习
**5.1.1 使用Scikit-learn进行机器学习**
Scikit-learn是Python中一个流行的机器学习库,它提供了各种机器学习算法和工具。要使用Scikit-learn进行机器学习,可以使用以下步骤:
1. 导入Scikit-learn库:
```python
import sklearn
```
2. 加载数据:
```python
data = pd.read_csv('data.csv')
```
3. 准备数据:
```python
# 处理缺失值
data = data.fillna(data.mean())
# 标准化数据
data = (data - data.mean()) / data.std()
```
4. 划分训练集和测试集:
```python
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2)
```
5. 选择和训练模型:
```python
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
```
6. 评估模型:
```python
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, model.predict(X_test))
print(accuracy)
```
**5.1.2 使用TensorFlow进行机器学习**
TensorFlow是Google开发的一个开源机器学习库,它提供了构建和训练复杂机器学习模型的工具。要使用TensorFlow进行机器学习,可以使用以下步骤:
1. 导入TensorFlow库:
```python
import tensorflow as tf
```
2. 加载数据:
```python
data = tf.data.experimental.make_csv_dataset('data.csv')
```
3. 准备数据:
```python
data = data.batch(32)
```
4. 构建模型:
```python
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
```
5. 训练模型:
```python
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(data, epochs=10)
```
6. 评估模型:
```python
loss, accuracy = model.evaluate(data)
print(loss, accuracy)
```
### 5.2 使用Snowflake代码的机器学习功能
**5.2.1 使用Snowflake代码的ML服务**
Snowflake代码提供了ML服务,它允许用户在Snowflake代码平台上训练和部署机器学习模型。要使用ML服务,可以使用以下步骤:
1. 创建一个ML服务:
```sql
CREATE ML SERVICE my_ml_service
```
2. 训练一个模型:
```sql
TRAIN MODEL my_model
ON my_data
USING my_algorithm
```
3. 部署模型:
```sql
DEPLOY MODEL my_model
```
4. 使用模型进行预测:
```sql
SELECT my_model.predict(my_data)
```
**5.2.2 使用Snowflake代码的ML模型**
Snowflake代码还提供了ML模型,它允许用户在Snowflake代码查询中使用预训练的机器学习模型。要使用ML模型,可以使用以下步骤:
1. 创建一个ML模型:
```sql
CREATE ML MODEL my_ml_model
```
2. 加载模型:
```sql
LOAD MODEL my_ml_model
FROM 'gs://my-bucket/my-model.pkl'
```
3. 使用模型进行预测:
```sql
SELECT my_ml_model.predict(my_data)
```
# 6. Python与雪花代码的应用场景
### 6.1 数据分析和可视化
#### 6.1.1 使用Python和雪花代码构建数据仪表板
**步骤:**
1. 使用Snowflake Connector for Python连接到雪花代码。
2. 使用Pandas读取数据并创建DataFrame。
3. 使用Plotly或Dash等库创建交互式数据仪表板。
4. 将仪表板部署到Web服务器或云平台。
**示例代码:**
```python
import snowflake.connector
import pandas as pd
import plotly.express as px
# 连接到雪花代码
conn = snowflake.connector.connect(
user="username",
password="password",
account="account",
database="database",
schema="schema"
)
# 查询数据
query = "SELECT * FROM table_name"
df = pd.read_sql(query, conn)
# 创建仪表板
fig = px.bar(df, x="column_name", y="value_name")
fig.show(renderer="iframe")
```
#### 6.1.2 使用Python和雪花代码进行数据可视化
**步骤:**
1. 使用Snowflake Connector for Python连接到雪花代码。
2. 使用Pandas读取数据并创建DataFrame。
3. 使用Matplotlib或Seaborn等库创建静态数据可视化。
4. 保存可视化结果为图像或PDF文件。
**示例代码:**
```python
import snowflake.connector
import pandas as pd
import matplotlib.pyplot as plt
# 连接到雪花代码
conn = snowflake.connector.connect(
user="username",
password="password",
account="account",
database="database",
schema="schema"
)
# 查询数据
query = "SELECT * FROM table_name"
df = pd.read_sql(query, conn)
# 创建可视化
plt.plot(df["column_name"], df["value_name"])
plt.xlabel("Column Name")
plt.ylabel("Value Name")
plt.title("Data Visualization")
plt.show()
```
### 6.2 机器学习和预测分析
#### 6.2.1 使用Python和雪花代码构建机器学习模型
**步骤:**
1. 使用Snowflake Connector for Python连接到雪花代码。
2. 使用Pandas读取数据并创建DataFrame。
3. 使用Scikit-learn或TensorFlow等库构建机器学习模型。
4. 使用雪花代码的ML服务部署模型。
**示例代码:**
```python
import snowflake.connector
import pandas as pd
from sklearn.linear_model import LinearRegression
# 连接到雪花代码
conn = snowflake.connector.connect(
user="username",
password="password",
account="account",
database="database",
schema="schema"
)
# 查询数据
query = "SELECT * FROM table_name"
df = pd.read_sql(query, conn)
# 创建模型
model = LinearRegression()
model.fit(df[["feature_name"]], df["target_name"])
# 部署模型
model_name = "my_model"
model_definition = model.to_json()
conn.cursor().execute(f"CREATE OR REPLACE MODEL {model_name} AS {model_definition}")
```
#### 6.2.2 使用Python和雪花代码进行预测分析
**步骤:**
1. 使用Snowflake Connector for Python连接到雪花代码。
2. 使用Pandas读取数据并创建DataFrame。
3. 使用雪花代码的ML服务调用已部署的模型进行预测。
4. 分析预测结果并采取相应行动。
**示例代码:**
```python
import snowflake.connector
import pandas as pd
# 连接到雪花代码
conn = snowflake.connector.connect(
user="username",
password="password",
account="account",
database="database",
schema="schema"
)
# 查询数据
query = "SELECT * FROM table_name"
df = pd.read_sql(query, conn)
# 调用模型
model_name = "my_model"
predictions = conn.cursor().execute(f"SELECT PREDICT({model_name}, {df.to_json()})").fetchall()
# 分析预测结果
for prediction in predictions:
print(prediction)
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到雪花代码 Python 专栏,一个专门探索雪花代码 Python 强大功能的宝库。从入门秘籍到高级技巧,我们的文章将指导您从零基础到实战应用。了解如何利用 Python API 提升数据操作,掌握最佳实践以提高代码效率,并避免常见的错误陷阱。深入了解 Python 在雪花代码数据仓库中的应用,探索数据处理和分析用例。掌握性能优化秘籍,提升查询速度和资源利用率。使用 Python 库创建交互式图表和仪表盘,实现数据可视化。扩展数据处理能力,了解 Python 与其他语言的集成。自动化数据处理和分析工作流,探索雪花代码 Python 数据管道。利用 Python 库进行预测建模和数据挖掘,深入了解机器学习。确保数据质量和合规性,了解数据治理。保护数据和应用程序免受威胁,掌握安全实践。探索高级功能和最佳实践,掌握雪花代码 Python 的精髓。了解真实世界中的应用场景,通过案例研究获得宝贵见解。评估优势和劣势,与其他云数据仓库进行比较。提升您的技能并获得行业认可,了解认证指南。解决常见问题并保持应用程序正常运行,掌握故障排除技巧。识别和解决瓶颈以提高效率,掌握性能调优秘诀。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
EMMC5.0 vs SSD:性能对比分析与最佳选择指南

# 摘要
本文介绍了嵌入式多媒体卡(EMMC)与固态驱动器(SSD)的技术细节,包括它们的工作原理、架构以及性能特点。通过比较EMMC5.0与SSD的读写速度、耐久度、可靠性和成本效益,本文分析了两种存储技术在不同应用场景中的表现,如消费电子和企业级应用。基
【GRADE软件数据校验】:专家分享确保结果准确性的5大绝招

# 摘要
GRADE软件的数据校验对于保证数据质量与准确性至关重要。本文首先强调了GRADE软件数据校验的重要性,并详细解析了其校验机制,包括数据完整性的基础理论、校验的目的和必要性,以及校验功能的概览和校验算法的选择。接下来,文章探讨了GRADE软件数据校验的实践技巧,涵盖配置和优化校验参数、解决校验过程中的常见问题,以及校验自动化与集成。此外,高级应用
PN532 NFC标签读写技术全攻略:快速上手指南
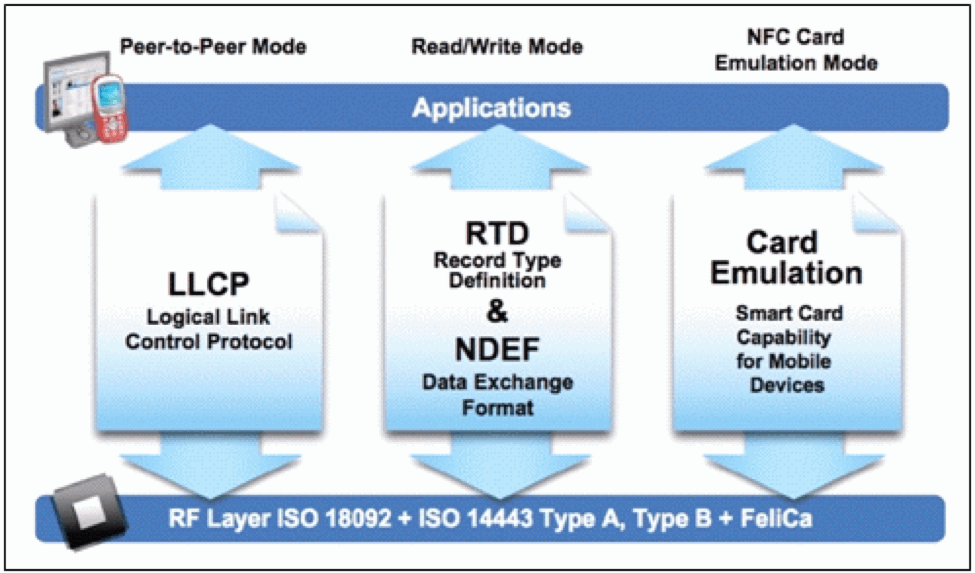
# 摘要
本文全面介绍了PN532 NFC标签读写技术,包括其基础理论、开发实践以及高级应用与技巧。首先概述了NFC技术的基本原理和PN532模块的技术特点,随后深入探讨了NFC标签读写的理论限制,如读写距离、功率要求、数据传输速率和安全性考量。在开发实践部分,本文详细说明了PN532模块与常见开发板的硬件连接、软件编程,以及在门禁控制系统和智能家居中的应用案例。此外,本文还探讨了NFC标签数据
Adblock Plus过滤规则深度剖析:提升网络安全的必备技巧

# 摘要
Adblock Plus作为一款流行的浏览器扩展程序,其强大的过滤规则功能是其核心特性之一。本文首先概述了Adblock Plus过滤规则的基本概念和语法,随后
WinPcap数据包过滤器深度解析:精确控制网络数据流

# 摘要
WinPcap作为网络数据包捕获库,广泛应用于网络分析和安全领域。本文介绍了WinPcap的基础知识,探讨了数据包过滤技术的理论基础及其过滤表达式语法,分析了过滤器的类型和配置策略。通过对WinPcap过滤器的深入配置和优化,以及探讨其在网络安全、网络性能分析和自定义协议分析中的应用,展
【整合JWT与OAuth2.0】:发挥两种协议的最大优势

# 摘要
本文对身份验证与授权领域的关键技术进行了全面探讨。首先介绍了JWT(JSON Web Tokens)的原理、结构及其在身份验证中的工作机制和安全性考量。随后,详细解析了OAuth2.0的授权流程、角色与令牌类型,并探讨了其在不同应用场景中的实际应用。进一步,文章深入探讨了JWT与OAuth2.0整合的动机、优势、实施方法以及实际案例。最后,针对整
【QCA Wi-Fi安全机制剖析】:源代码级别的数据加密与验证深入解析
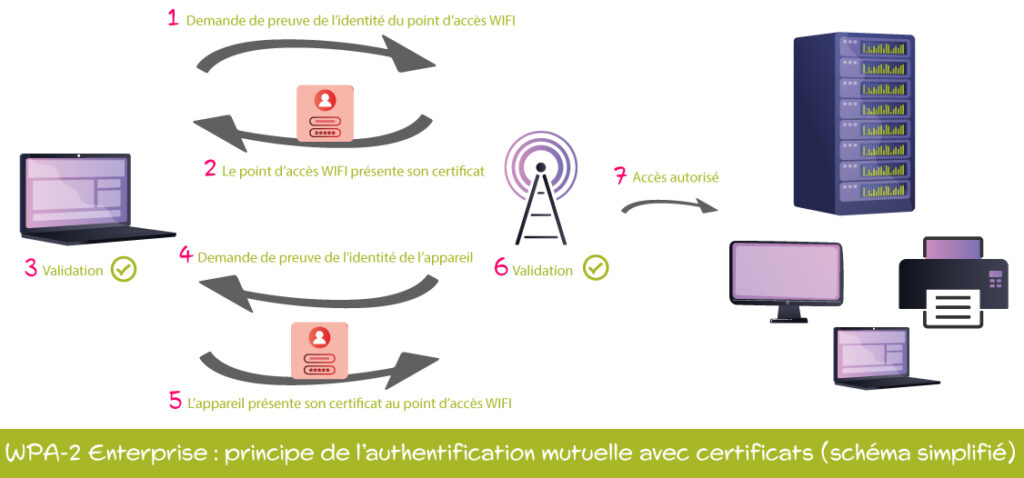
# 摘要
本文综述了QCA Wi-Fi安全机制的关键组成部分,包括数据加密、用户验证、授权协议以及网络安全监控技术。文中详细探讨了各种加密算法(如WEP, WPA, WPA2, WPA3)和密钥管理策略的工作原理及其在QCA平台上的实现。此外,分析了用户验证和授权协议(如EAP认证方法、MAC地址过滤、802.1X)如何保障Wi-Fi网络的安全性,
PNOZ继电器与其他安全设备的集成指南

# 摘要
本文对PNOZ继电器进行了全面的概述,详细介绍了其基础应用、与其他安全设备的集成实践以及高级应用。文章首先探讨了PNOZ继电器的原理、功能、安装和接线方法,进而分析了与传感器、PLC和HMI的集成方式。接着,本文深入讨论了PNOZ继电器在故障诊断处理、安全配置管理中的应用,以及在工业自动化和汽车制造等领域的实际案例。最后,文章展望了PN
Altium函数自定义指南:根据项目需求定制个性化功能

# 摘要
本文旨在全面介绍Altium函数自定义的技术细节及其应用。首先概述了Altium函数自定义的重要性及其理论基础,包括函数的概念及其与项目需求的关系。接着详细探讨了设计原则,强调了代码的可读性、性能优化和安全性。实践中,本文提供了自定义步骤和高级技巧,涵盖了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )