




揭秘雪花代码Python入门秘籍:从零基础到实战应用

1. Python基础
Python是一种高级编程语言,以其易于学习、可读性强和广泛的库而闻名。本章将介绍Python的基础知识,包括数据类型、变量、流程控制和函数。
1.1 数据类型和变量
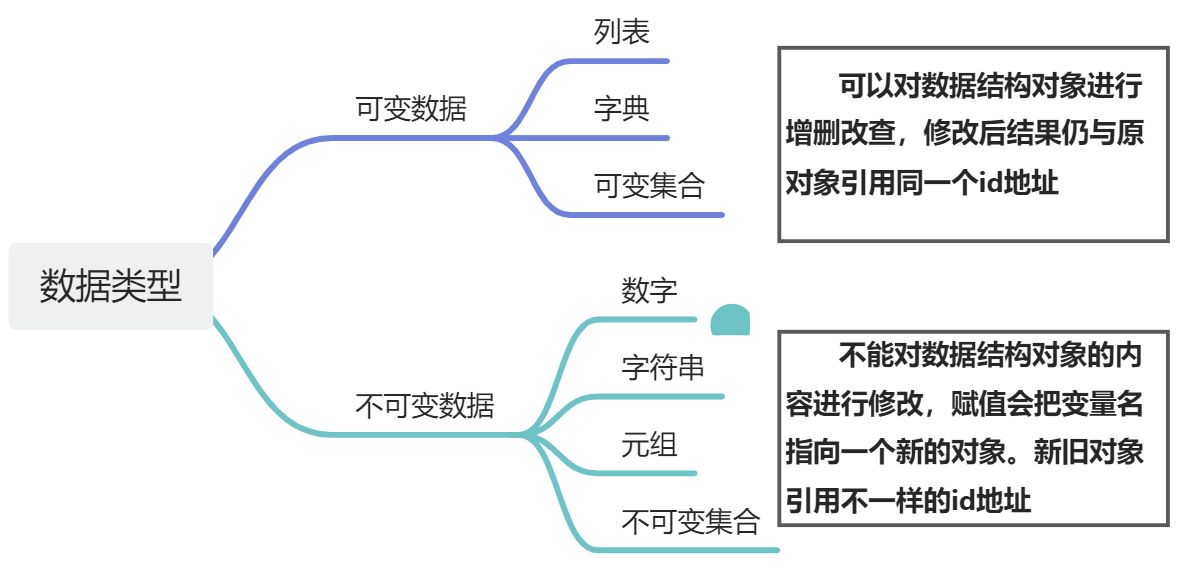
Python支持多种数据类型,包括数字(整数和浮点数)、字符串、布尔值、列表和元组。变量用于存储数据,并使用赋值运算符(=)来分配值。例如:
- # 定义一个整数变量
- age = 30
- # 定义一个字符串变量
- name = "John Doe"
2. Python编程技巧
2.1 数据类型和变量
2.1.1 数据类型概述
Python是一种动态类型语言,这意味着变量的数据类型在运行时确定。Python支持多种数据类型,包括:
- 整数(int):表示整数,如 10、-20
- 浮点数(float):表示浮点数,如 3.14、-12.5
- 字符串(str):表示文本数据,如 “Hello World”、‘Python’
- 布尔值(bool):表示真或假,如 True、False
- 列表(list):表示有序集合,元素可以是任何数据类型,如 [1, 2.5, “Python”]
- 元组(tuple):表示不可变有序集合,元素可以是任何数据类型,如 (1, 2.5, “Python”)
- 字典(dict):表示键值对集合,键必须是唯一的,值可以是任何数据类型,如 {“name”: “John”, “age”: 30}
2.1.2 变量的定义和赋值
变量用于存储数据,通过赋值运算符(=)定义和赋值变量。语法如下:
- variable_name = value
例如:
- name = "John"
- age = 30
2.2 流程控制
流程控制语句用于控制程序的执行流。
2.2.1 条件语句
条件语句用于根据条件执行不同的代码块。语法如下:
- if condition:
- # 代码块 1
- elif condition:
- # 代码块 2
- else:
- # 代码块 3
例如:
- age = 18
- if age >= 18:
- print("成年人")
- elif age >= 13:
- print("青少年")
- else:
- print("儿童")
2.2.2 循环语句
循环语句用于重复执行代码块。Python支持两种循环语句:
- **for循环:**用于遍历序列中的元素。语法如下:
- for item in sequence:
- # 代码块
- **while循环:**用于当条件为真时重复执行代码块。语法如下:
- while condition:
- # 代码块
2.2.3 函数和参数传递
函数是可重用的代码块,可以接收参数并返回结果。语法如下:
- def function_name(parameters):
- # 代码块
- return result
函数可以调用其他函数,并通过参数传递数据。参数传递有两种方式:
- **按值传递:**函数接收变量的副本,对副本的修改不会影响原始变量。
- **按引用传递:**函数接收变量的引用,对副本的修改会影响原始变量。
2.3 面向对象编程
面向对象编程(OOP)是一种编程范式,它将程序组织成对象。
2.3.1 类和对象
类是对象的蓝图,它定义了对象的属性和方法。对象是类的实例,它拥有类的属性和方法。语法如下:
- class ClassName:
- # 属性和方法
例如:
- class Person:
- def __init__(self, name, age):
- self.name = name
- self.age = age
- def get_name(self):
- return self.name
- def get_age(self):
- return self.age
2.3.2 继承和多态
继承允许一个类从另一个类(称为父类)继承属性和方法。多态允许对象以不同的方式响应相同的操作。
3. Python实践应用**
3.1 文件操作
3.1.1 文件的读写
代码块:
- # 打开一个文件,'w'表示写入模式
- with open('example.txt', 'w') as f:
- f.write('Hello, world!')
逻辑分析:
open()函数打开一个文件,第一个参数是文件名,第二个参数是模式。'w'模式表示以写入模式打开文件,如果文件不存在则创建,如果存在则清空并重写。with语句是一个上下文管理器,确保在代码块执行完毕后自动关闭文件。f.write()方法将字符串写入文件。
代码块:
- # 打开一个文件,'r'表示读取模式
- with open('example.txt', 'r') as f:
- data = f.read()
逻辑分析:
'r'模式表示以读取模式打开文件,如果文件不存在则会报错。f.read()方法读取文件中的所有内容并返回一个字符串。
3.1.2 文件的权限和属性
表格:文件权限
| 权限 | 描述 |
|---|---|
r |
可读 |
w |
可写 |
x |
可执行 |
+ |
添加权限 |
代码块:
- # 获取文件的权限
- import os
- permissions = os.stat('example.txt').st_mode
- # 检查文件是否可读
- if permissions & os.R_OK:
- print('File is readable')
逻辑分析:
os.stat()函数获取文件的状态信息,返回一个stat对象。st_mode属性包含文件的权限信息。os.R_OK是一个常量,表示可读权限。&运算符用于检查文件权限是否包含可读权限。
3.2 网络编程
3.2.1 网络编程基础
Mermaid流程图:
逻辑分析:
- 网络编程涉及客户端和服务器之间的通信。
- 客户端向服务器发送请求,服务器处理请求并返回响应。
3.2.2 Socket编程实例
代码块:

逻辑分析:
socket.socket()函数创建一个套接字,第一个参数指定地址族(AF_INET表示 IPv4),第二个参数指定套接字类型(SOCK_STREAM表示 TCP)。sock.bind()方法将套接字绑定到一个地址和端口。sock.listen()方法将套接字设置为监听模式,等待连接。sock.accept()方法接受一个连接,返回一个连接对象和客户端地址。conn.recv()方法从连接中接收数据。conn.send()方法向连接中发送数据。conn.close()方法关闭连接。
3.3 数据库编程
3.3.1 数据库连接和操作
代码块:
逻辑分析:
mysql.connector.connect()函数连接到数据库,参数包括主机、用户名、密码和数据库名。cursor()方法创建一个游标,用于执行查询和获取结果。execute()方法执行一个查询,第一个参数是查询语句。fetchall()方法获取查询的所有结果,返回一个元组列表。close()方法关闭游标和连接。
3.3.2 SQL语句的执行和结果处理
代码块:
- # 插入一条记录
- cursor.execute('INSERT INTO users (name, email) VALUES (%s, %s)', ('John Doe', 'john.doe@example.com'))
- # 更新一条记录
- cursor.execute('UPDATE users SET name = %s WHERE id = %s', ('Jane Doe', 1))
- # 删除一条记录
- cursor.execute('DELETE FROM users WHERE id = %s', (2,))
逻辑分析:
execute()方法还可以执行插入、更新和删除语句。- 第一个参数是 SQL 语句,其中
%s占位符表示要插入或更新的值。 - 第二个参数是一个元组,包含要插入或更新的值。
close()方法关闭游标和连接。
4. Python进阶应用
4.1 正则表达式
4.1.1 正则表达式语法和元字符
正则表达式(Regular Expression,简称Regex)是一种强大的文本匹配模式,用于查找、匹配、替换或分割字符串。正则表达式语法由特殊字符和元字符组成,其中特殊字符具有特定含义,元字符用于匹配特定字符或模式。
特殊字符:
^:匹配字符串开头$:匹配字符串结尾.:匹配任意单个字符*:匹配前一个字符0次或多次+:匹配前一个字符1次或多次?:匹配前一个字符0次或1次|:匹配多个模式中的一个
元字符:
\d:匹配数字\w:匹配字母、数字或下划线\s:匹配空白字符(空格、制表符、换行符等)\b:匹配单词边界[ ]:匹配方括号内的任意字符[^ ]:匹配方括号内外的任意字符
4.1.2 正则表达式的匹配和替换
使用正则表达式匹配字符串时,可以使用re.match()函数。如果匹配成功,则返回一个Match对象,否则返回None。
- import re
- pattern = r"^[a-zA-Z0-9]{6,12}$"
- string = "Hello123"
- match = re.match(pattern, string)
- if match:
- print("匹配成功")
- else:
- print("匹配失败")
使用正则表达式替换字符串时,可以使用re.sub()函数。该函数将匹配到的子字符串替换为指定的字符串。
- pattern = r"^[a-zA-Z0-9]{6,12}$"
- string = "Hello123"
- new_string = re.sub(pattern, "NewString", string)
- print(new_string) # 输出:NewString
4.2 数据分析和可视化
4.2.1 数据分析库和工具
Python提供了丰富的库和工具用于数据分析,包括:
- **NumPy:**科学计算库,提供数组和矩阵操作
- **Pandas:**数据操作和分析库,提供数据框和时间序列操作
- **Scikit-learn:**机器学习库,提供各种机器学习算法和模型
4.2.2 数据可视化技术
数据可视化可以帮助我们直观地理解数据,Python提供了多种数据可视化库,包括:
- **Matplotlib:**用于创建各种类型的图表和图形
- **Seaborn:**基于Matplotlib的高级数据可视化库
- **Plotly:**用于创建交互式和动态图表
4.3 机器学习
4.3.1 机器学习简介
机器学习是一种人工智能技术,它使计算机能够从数据中学习,而无需明确编程。机器学习算法可以识别数据中的模式和规律,并根据这些模式做出预测或决策。
4.3.2 机器学习算法和模型
Python提供了丰富的机器学习算法和模型,包括:
- **监督学习:**使用标记数据训练模型,例如线性回归、逻辑回归、决策树
- **无监督学习:**使用未标记数据训练模型,例如聚类、降维
- **强化学习:**通过与环境交互学习,例如Q学习、深度强化学习
5. Python项目实战
5.1 数据爬取和处理项目
目标:
本项目旨在指导你使用Python从各种在线来源爬取和处理数据。
步骤:
- **选择数据源:**确定你想要爬取数据的网站或API。
- **分析网站结构:**使用浏览器开发人员工具或第三方库(如BeautifulSoup)分析网站结构。
- **编写爬虫:**使用Requests库或Selenium库编写爬虫来提取数据。
- **处理数据:**使用Pandas库或NumPy库清理、转换和分析数据。
- **存储数据:**将数据存储在CSV文件、数据库或其他合适的位置。
代码示例:
- import requests
- from bs4 import BeautifulSoup
- # 从网站提取 HTML
- url = 'https://example.com'
- response = requests.get(url)
- html = response.text
- # 使用 BeautifulSoup 解析 HTML
- soup = BeautifulSoup(html, 'html.parser')
- # 提取所需数据
- titles = [title.text for title in soup.find_all('h1')]
逻辑分析:
这段代码使用Requests库从指定URL获取HTML。然后使用BeautifulSoup库解析HTML并提取所需的数据,例如标题。
5.2 网络自动化项目
目标:
本项目旨在展示如何使用Python自动化网络任务,例如测试网站、监控网络服务和配置网络设备。
步骤:
- **选择自动化工具:**使用Selenium库或Requests库等自动化工具。
- **编写自动化脚本:**编写脚本来模拟用户交互或执行网络操作。
- **部署自动化脚本:**将脚本部署到服务器或云平台。
- **监控自动化任务:**设置监控系统来跟踪自动化任务的执行和结果。
代码示例:
- from selenium import webdriver
- # 创建 Selenium WebDriver
- driver = webdriver.Chrome()
- # 访问网站
- driver.get('https://example.com')
- # 查找并点击按钮
- button = driver.find_element_by_id('submit-button')
- button.click()
逻辑分析:
这段代码使用Selenium WebDriver创建了一个Chrome浏览器实例。然后它访问指定URL并找到具有特定ID的按钮。最后,它点击该按钮。
5.3 机器学习项目
目标:
本项目旨在指导你使用Python构建和训练机器学习模型。
步骤:
- **选择数据集:**选择一个适合你的机器学习任务的数据集。
- **准备数据:**使用Pandas库或NumPy库准备数据,包括清理、转换和特征工程。
- **选择机器学习算法:**选择合适的机器学习算法,例如线性回归、决策树或支持向量机。
- **训练模型:**使用Scikit-learn库训练机器学习模型。
- **评估模型:**使用交叉验证或其他评估技术评估模型的性能。
代码示例:
- from sklearn.linear_model import LinearRegression
- # 准备数据
- X = ... # 特征数据
- y = ... # 目标数据
- # 创建线性回归模型
- model = LinearRegression()
- # 训练模型
- model.fit(X, y)
- # 预测新数据
- new_data = ...
- predictions = model.predict(new_data)
逻辑分析:
这段代码使用Scikit-learn库创建了一个线性回归模型。然后它使用训练数据训练模型。最后,它使用新数据预测目标值。
6. Python开发最佳实践
6.1 代码风格和规范
遵循一致的代码风格和规范对于提高代码的可读性、可维护性和可协作性至关重要。雪花代码提供了以下最佳实践:
- **遵循PEP 8指南:**PEP 8是Python社区制定的代码风格指南,定义了缩进、命名约定和文档字符串等方面。
- **使用代码格式化工具:**Black、autopep8等工具可以自动格式化代码,确保一致性。
- **使用类型提示:**使用类型提示(如mypy)可以提高代码的可读性和可维护性,并帮助识别潜在的错误。
- **编写清晰的文档字符串:**每个函数和类都应该有清晰的文档字符串,描述其目的、参数和返回值。
6.2 单元测试和调试
单元测试是验证代码正确性的重要工具。雪花代码提供了以下最佳实践:
- **编写单元测试:**使用单元测试框架(如unittest、pytest)编写单元测试,以验证代码的各个部分。
- **使用断言:**使用断言(如assertEqual、assertTrue)来验证测试的预期结果。
- **使用调试器:**使用调试器(如pdb)来逐步执行代码并检查变量的值,以帮助识别错误。
- **使用日志记录:**使用日志记录(如logging)来记录错误和调试信息,以帮助诊断问题。
6.3 性能优化和可扩展性
优化代码的性能和可扩展性对于确保其在生产环境中的稳定性和效率至关重要。雪花代码提供了以下最佳实践:
- **使用性能分析工具:**使用性能分析工具(如cProfile、line_profiler)来识别性能瓶颈。
- **优化数据结构:**选择合适的的数据结构(如列表、字典、集合)来优化代码的性能。
- **使用缓存:**使用缓存机制来存储经常访问的数据,以减少数据库查询和网络调用的次数。
- **考虑并发性:**使用多线程或多进程来提高代码的并发性,以处理多个请求或任务。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点
Cygwin系统监控指南:性能监控与资源管理的7大要点
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南
【精准测试】:确保分层数据流图准确性的完整测试方法
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
【T-Box能源管理】:智能化节电解决方案详解
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















