NLP初探:自然语言处理的基础知识
发布时间: 2024-01-17 19:54:14 阅读量: 37 订阅数: 22 

自然语言处理基础
# 1. 自然语言处理(NLP)概述
## 1.1 什么是自然语言处理?
自然语言处理(Natural Language Processing,NLP)是一门融合了计算机科学、人工智能和语言学等多学科知识的交叉领域。其主要目标是使计算机能够理解、解释、处理和生成人类语言的能力。NLP技术可以帮助计算机理解和处理文本、语音和图像等人类自然语言数据,实现人机交互、信息提取、情感分析等应用。
## 1.2 自然语言处理的应用领域
自然语言处理技术在各个领域有着广泛的应用,包括但不限于:
- 机器翻译:将一种自然语言翻译成另一种自然语言的技术,如将中文翻译成英文。
- 文本分类:将文本划分为不同的类别,如垃圾邮件识别、新闻分类等。
- 信息抽取:从非结构化的文本中抽取出结构化的信息,如实体识别、事件抽取等。
- 问答系统:让计算机能够回答用户提出的自然语言问题,如智能助手、知识图谱问答等。
- 情感分析:分析文本中的情感倾向,如情感分类、舆情监控等。
自然语言处理在互联网、金融、医疗、教育等领域都有着重要的应用,随着人工智能技术的发展,其应用范围还在不断拓展和深化。
# 2. 自然语言处理的基础理论
自然语言处理(NLP)涉及多种基础理论,包括语言模型、词法分析和句法分析。在这一章节中,我们将深入探讨这些理论的基本概念和原理。
### 2.1 语言模型
语言模型是自然语言处理中的基础理论之一,用于描述语言的概率结构。其核心思想是通过建模来预测一段文本序列出现的概率。常见的语言模型包括n-gram模型、神经语言模型等。我们将详细介绍这些模型的原理和应用。
### 2.2 词法分析
词法分析是NLP中的重要理论,用于将文本分割成有意义的词汇单元。这包括词语的识别、词干提取和词义消歧等过程。我们将介绍词法分析的基本算法和常见工具,以及在实际应用中的一些注意事项。
### 2.3 句法分析
句法分析是自然语言处理中的另一个关键理论,旨在理解句子结构和语法关系。它涉及到句子成分的标注、句法结构的分析和语法关系的建模。我们将探讨句法分析的常见方法和算法,并通过实例演示其在句子解析中的应用。
希望这些内容可以为您对自然语言处理的基础理论有更深入的了解。
# 3. 文本预处理和特征提取
在自然语言处理(NLP)中,文本预处理和特征提取是非常重要的步骤。通过预处理文本,我们可以清理并规范化数据,使其适合后续的分析和建模。而特征提取则是将原始文本转化为计算机可以理解的向量表示,以便进行算法和模型的训练和应用。
本章将介绍文本预处理和特征提取的常见方法和技术。
### 3.1 文本清洗
文本清洗是文本预处理的第一步。它包括去除文本中的噪声和无用的信息,例如标点符号、特殊字符、HTML 标签、停用词等。清洗文本可以使之更加干净、规范和易于处理。
以下是一些常见的文本清洗操作:
- 去除标点符号和特殊字符:使用正则表达式或相关方法去除文本中的标点符号和特殊字符。
- 转换为小写:将文本中的大写字母转换为小写,以便对文本进行统一处理。
- 去除停用词:停用词是指在文本中频繁出现但并不携带太多信息的词语,例如“的”、“是”、“在”等。可以借助停用词列表,将这些词语从文本中去除。
- 标准化:对于某些特殊的文本数据,例如日期、时间、数字等,可以将其转换为特定的格式。例如将日期统一为yyyy-MM-dd的形式。
### 3.2 分词和词袋模型
分词是将连续的文本拆分为单个的词语或标记的过程。在英文中,可以以空格作为分隔符进行拆分。而中文分词则需要借助专门的分词工具,例如结巴分词、哈工大LTP等。
分词后,文本可以表示为一个词语序列。为了能够在计算机上处理文本数据,通常采用词袋模型(Bag of Words)来表示文本。词袋模型将每个文本看作一个词语的集合,并以向量的形式表示。向量的每个维度表示一个词语,而向量的值表示该词语在文本中的出现次数或权重。
### 3.3 文本特征提取方法
在NLP中,除了词袋模型,还有许多其他的文本特征提取方法。
- TF-IDF:TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征表示方法。它考虑单词在文本中的频率和在整个语料库中的重要性。TF-IDF通过计算词语的TF(词频)和IDF(逆文档频率)值,生成表示每个文本的向量。
- Word2Vec:Word2Vec是一种基于神经网络的词嵌入(Word Embedding)方法。它将每个词语表示为一个低维的实数向量,通过训练模型学习到词语之间的语义关系。
- GloVe:GloVe(Global Vectors for Word Representation)也是一种词嵌入方法。它利用全局信息和局部上下文之间的关系,将单词表示为实数向量。
以上是文本预处理和特征提取的介绍,这些步骤都是NLP任务中的基础,能够为后续的文本分析和建模提供有用的数据表示。
代码实例:
```python
import re
def clean_text(text):
# 去除标点符号和特殊字符
text = re.sub(r'[^\w\s]', '', text)
# 转换为小写
text = text.lower()
# 去除停用词
stopwords = ["is", "the", "of", "and"]
text = " ".join([word for word in text.split() if word not in stopwords])
return text
# 示例文本
text = "Hello, World! This is a sample text."
cleaned_text = clean_text(text)
print(cleaned_text)
```
上述代码演示了一个简单的文本清洗函数。它使用正则表达式去除文本中的标点符号和特殊字符,转换为小写,并去除了停用词。通过调用该函数,可以将原始文本清洗为干净的文本数据。
# 4. NLP中的常见算法和技术
自然语言处理(NLP)领域涵盖了多种常见算法和技术,这些方法对文本数据的处理和分析起着关键作用。本章将介绍NLP中的一些常见算法和技术,包括词嵌入、文本分类和情感分析,以及命名实体识别(NER)和实体链接。
#### 4.1 词嵌入(Word Embedding)
词嵌入是NLP中的一种常见技术,它将单词映射到实数域向量空间中。通过词嵌入技术,可以将单词表示为实数向量,使得单词在向量空间中的位置能够捕捉到单词之间的语义关系。Word2Vec和GloVe是两种常用的词嵌入模型,它们可以将单词转换为密集向量,并且使得语义相近的单词在向量空间中距离较近。
```python
# Python代码示例:使用Word2Vec进行词嵌入
from gensim.models import Word2Vec
sentences = [["NLP", "is", "fun"], ["NLP", "involves", "language", "processing"]]
model = Word2Vec(sentences, min_count=1)
```
#### 4.2 文本分类和情感分析
文本分类是NLP中的一项重要任务,它可以帮助将文本数据划分到不同的类别中。而情感分析则是文本分类的一种特殊形式,它旨在识别文本中的情感倾向,如正面情绪、负面情绪或中性情绪。常见的文本分类和情感分析方法包括朴素贝叶斯分类器、支持向量机(SVM)以及深度学习模型如卷积神经网络(CNN)和循环神经网络(RNN)。
```java
// Java代码示例:使用朴素贝叶斯分类器进行文本分类
import org.apache.spark.ml.classification.NaiveBayes;
import org.apache.spark.ml.classification.NaiveBayesModel;
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator;
// Load training data
Dataset<Row> data = spark.read().format("libsvm").load("data/mllib/sample_libsvm_data.txt");
// Split the data into train and test
Dataset<Row>[] splits = data.randomSplit(new double[]{0.6, 0.4}, 1234L);
Dataset<Row> train = splits[0];
Dataset<Row> test = splits[1];
// Train a NaiveBayes model
NaiveBayes nb = new NaiveBayes();
NaiveBayesModel model = nb.fit(train);
// Select example rows to display.
Dataset<Row> predictions = model.transform(test);
predictions.show();
```
#### 4.3 命名实体识别(NER)和实体链接
命名实体识别(NER)是NLP中的一项重要任务,它旨在识别文本中出现的具有特定意义的实体,如人名、地名、组织名等。实体链接则是将NER得到的实体链接到知识库中的实体,实现文本和知识库中实体的关联。常见的NER技术包括基于规则的方法、基于统计的方法以及深度学习方法,如BiLSTM-CRF模型。
```python
# Python代码示例:使用spaCy进行命名实体识别
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for ent in doc.ents:
print(ent.text, ent.label_)
```
以上是NLP中的一些常见算法和技术,它们在文本处理和分析中发挥着重要作用,为NLP应用提供了强大的支持。在实际应用中,根据具体的任务需求和数据特点,可以选择合适的算法和技术来处理文本数据。
# 5. NLP中的深度学习方法
在自然语言处理(NLP)中,深度学习方法已经成为了最常用的技术之一。深度学习通过多层神经网络的构建和训练,能够从文本数据中提取有用的特征,并进行各种任务,如文本分类、情感分析等。本章将详细介绍几种常见的深度学习方法在NLP中的应用。
### 5.1 循环神经网络(RNN)
循环神经网络(Recurrent Neural Network,简称RNN)可以处理序列数据,非常适合于处理文本数据。RNN的核心思想是通过隐藏层的状态传递信息,使得网络能够对序列中的上下文进行建模。RNN在NLP中的应用包括语言建模、机器翻译和文本生成等任务。
以下是使用Python和Keras库构建一个简单的RNN模型的代码示例:
```python
import numpy as np
from keras.models import Sequential
from keras.layers import Embedding, LSTM, Dense
# 构建模型
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=embed_dim, input_length=max_length))
model.add(LSTM(units=hidden_units))
model.add(Dense(units=num_classes, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, batch_size=batch_size, epochs=num_epochs, validation_data=(X_val, y_val))
```
在上述示例中,我们首先导入了必要的库,然后构建了一个包含嵌入层(Embedding)、长短时记忆网络层(LSTM)和全连接层(Dense)的模型。在编译模型后,我们可以使用`fit()`函数进行模型的训练。
### 5.2 长短时记忆网络(LSTM)
长短时记忆网络(Long Short-Term Memory,简称LSTM)是RNN的一种变体,用于解决传统RNN在处理长期依赖关系时的问题。LSTM通过引入记忆单元和门控机制,能够有效地捕捉文本中的长期依赖关系。在NLP中,LSTM广泛应用于情感分析、命名实体识别等任务。
以下是使用Python和Keras库构建一个简单的LSTM模型的代码示例:
```python
import numpy as np
from keras.models import Sequential
from keras.layers import Embedding, LSTM, Dense
# 构建模型
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=embed_dim, input_length=max_length))
model.add(LSTM(units=hidden_units))
model.add(Dense(units=num_classes, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, batch_size=batch_size, epochs=num_epochs, validation_data=(X_val, y_val))
```
在上述示例中,我们通过使用`LSTM()`函数添加了一个LSTM层,其他部分和RNN模型的构建相似。
### 5.3 注意力机制(Attention Mechanism)
注意力机制(Attention Mechanism)是一种用于处理序列数据的机制,能够在每个时间步骤上给予不同的权重,从而使网络能够更加关注有意义的信息。注意力机制在翻译任务、问答系统等NLP任务中取得了很好的效果。
以下是使用Python和Keras库构建一个带有注意力机制的模型的代码示例:
```python
import numpy as np
from keras.models import Sequential
from keras.layers import Embedding, LSTM, Dense, Attention
# 构建模型
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=embed_dim, input_length=max_length))
model.add(LSTM(units=hidden_units, return_sequences=True))
model.add(Attention())
model.add(Dense(units=num_classes, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, batch_size=batch_size, epochs=num_epochs, validation_data=(X_val, y_val))
```
上述示例中,我们通过使用`Attention()`函数将注意力机制添加到了模型中。
以上是NLP中常见的几种深度学习方法的简要介绍和代码示例。这些方法在NLP任务中展现了强大的能力,随着深度学习的不断进步,我们可以期待更多创新的深度学习方法在NLP领域的应用。
# 6. NLP的挑战和未来发展趋势
自然语言处理(NLP)作为人工智能的重要分支,面临着许多挑战和局限性。本章将详细探讨这些挑战,并展望NLP的未来发展趋势。
### 6.1 NLP的挑战与局限性
尽管NLP在许多领域都取得了巨大的进展,但仍然存在一些挑战和局限性。
1. **语义理解和推理**:NLP目前主要集中在对语言表面意义的理解和分析上,而对于更深层次的语义理解和推理仍然存在挑战。例如,对于多义词和歧义语句的准确理解,以及对上下文和常识的充分利用,仍然是一个难点。
2. **数据稀缺**:NLP模型的训练通常需要大量的标注数据,但在某些领域(如医疗和法律)中,由于数据的敏感性和隐私问题,很难获得足够的标注数据。这导致了模型性能的限制。
3. **多语言处理**:NLP在不同语言之间的应用也面临一些挑战。每种语言都有其独特的语法、词汇和文化背景,因此需要针对不同语言设计和训练模型。同时,跨语言之间的信息传递和翻译也是一个挑战。
4. **认知偏差和不平等**:NLP模型的训练数据通常来自于各种来源,包括互联网和大众媒体。然而,这些数据往往存在认知偏差和不平等的问题,可能导致模型对于某些群体或话题的偏见。
### 6.2 基于深度学习的NLP未来发展趋势
随着深度学习在NLP领域的应用不断进步,我们可以看到以下几个未来发展趋势:
1. **预训练模型的兴起**:预训练模型(如BERT、GPT)通过无监督学习从大规模文本数据中学习通用语言表示,成为许多NLP任务的重要基础。未来的发展将更加关注基于预训练模型的迁移学习和领域自适应。
2. **多模态信息处理**:NLP不再局限于文本数据,越来越多的任务需要同时处理文本、图像、语音等多模态信息。未来的发展将更加关注如何有效地融合多种信息来源,提高整体的模型性能。
3. **更强大的语义表示学习**:随着对语义理解的要求越来越高,未来的发展将更加注重如何设计更强大的语义表示学习模型,以提升对语义信息的表达能力。
4. **增强对话系统的能力**:对话系统是NLP中的一个重要应用领域,未来的发展将更加关注如何构建更智能、更具交互性的对话系统,使其能够真正理解用户意图并提供有价值的回复。
### 6.3 NLP与人工智能的融合与展望
NLP作为人工智能的重要组成部分,与其他人工智能技术的融合将会产生更广泛的应用和更强大的功能。未来,NLP与以下技术的融合将迎来新的发展:
- **知识图谱与推理**:将NLP与知识图谱相结合,可以进行更精准的语义理解和推理,从而实现更智能的问答系统和知识管理系统。
- **计算机视觉**:将NLP与计算机视觉相结合,可以实现更强大的图像和视频理解能力,例如图像描述生成、图像问答等。
- **增强学习**:将NLP与增强学习相结合,可以实现更智能的对话代理和智能问答系统,能够快速学习和优化策略。
总的来说,NLP作为一门快速发展的领域,未来将与其他人工智能技术相互融合,不断推动人工智能的发展和应用。我们可以期待NLP在语义理解、对话系统和智能问答等方面取得更大的突破。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在探讨自然语言处理(NLP)领域中与文本生成相关的各种技术与应用。首先介绍了NLP的基础知识,包括语言模型的发展历程从n-gram到深度学习的演进。随后深入探讨了文本生成技术的综述,涵盖了机器创作、自动写作、基于规则的文本重写等方面,以及自动文本摘要的算法和应用。专栏还探讨了注意力机制、生成对抗网络(GAN)、Transformer模型、BERT模型等革命性的文本生成架构,并分析了神经图灵机、序列到序列模型、迁移学习等在文本生成任务中的应用效果。此外,还关注了情感分析、版权保护、样本多样性等与文本生成相关的挑战与解决方案,以及知识图谱与文本生成的结合和长文本生成技术的探索。通过本专栏的阅读,读者将能够深入了解文本生成技术的前沿研究和实际应用,以及面临的挑战和未来发展趋势。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CTS模型:从基础到高级,构建地表模拟的全过程详解

# 摘要
本文对CTS模型进行了全面介绍,从基础理论到实践操作再到高级应用进行了深入探讨。CTS模型作为一种重要的地表模拟工具,在地理信息系统(GIS)中有着广泛的应用。本文详细阐述了CTS模型的定义、组成、数学基础和关键算法,并对模型的建立、参数设定、迭代和收敛性分析等实践操作进行了具体说明。通过对实地调查数据和遥感数据的收集与处理,本文展示了模型在构建地表模拟时的步
【升级前必看】:Python 3.9.20的兼容性检查清单

# 摘要
Python 3.9.20版本的发布带来了多方面的更新,包括语法和标准库的改动以及对第三方库兼容性的挑战。本文旨在概述Python 3.9.20的版本特点,深入探讨其与既有代码的兼容性问题,并提供相应的测试策略和案例分析。文章还关注在兼容性升级过程中如何处理不兼容问题,并给出升级后的注意事项。最后,
【Phoenix WinNonlin数据可视化】:结果展示的最佳实践和技巧

# 摘要
本文旨在全面介绍Phoenix WinNonlin软件在数据可视化方面的应用,概念与界面功能概览,以及数据可视化技术的深入探讨。通过章节内容对软件界面的核心组件、功能操作流程进行解析,强调了数据图表化和高级数据处理技巧的重要性。实践案例分析
【Allegro脚本编程:自动化设计的终极指南】

# 摘要
Allegro脚本作为一种强大的自动化工具,广泛应用于电子设计自动化领域。本文从脚本的基础知识讲起,深入探讨了其语法、高级特性以及在实践中的具体应用,包括自动化流程设计、数据管理、交互式脚本编写。随后,文章详细介绍了脚本优化与调试技巧,以提升执行效率和故障处理能力。最后,文章探索了Allegro脚本在PCB设计自动化、IC封装设计等不同领域的
AnyLogic工作流与决策模拟:精通业务流程设计只需72小时
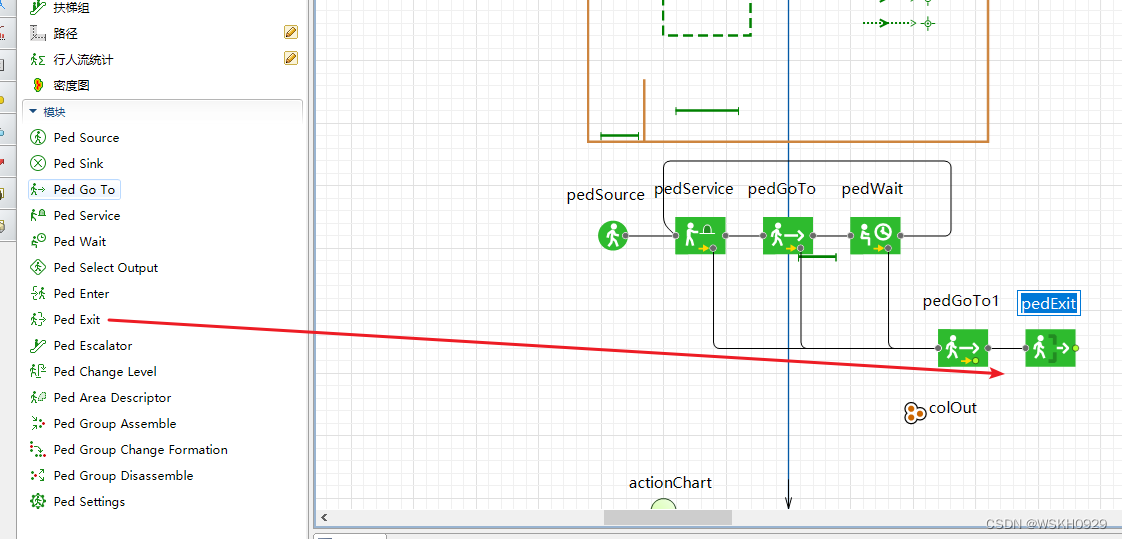
# 摘要
本文全面概述了业务流程模拟与决策分析的理论与实践,特别聚焦于AnyLogic软件的应用。首先,对AnyLogic的基础知识和界面布局进行了介绍,并探讨了创建新模拟项目的步骤。接着,文章深入探讨了业务流程模拟的理论基础和建模技术,以及如何通过流程图和模拟分析来支持决策。此外,还详细讲解了面向对象模拟方法在AnyLogic中的实现,构建高级决策模型的技巧,以及仿真实验的设计与结果分析。最后,文章探讨了AnyLogi
【网络性能调优实战】:ifconfig在加速Linux网络中的10大应用
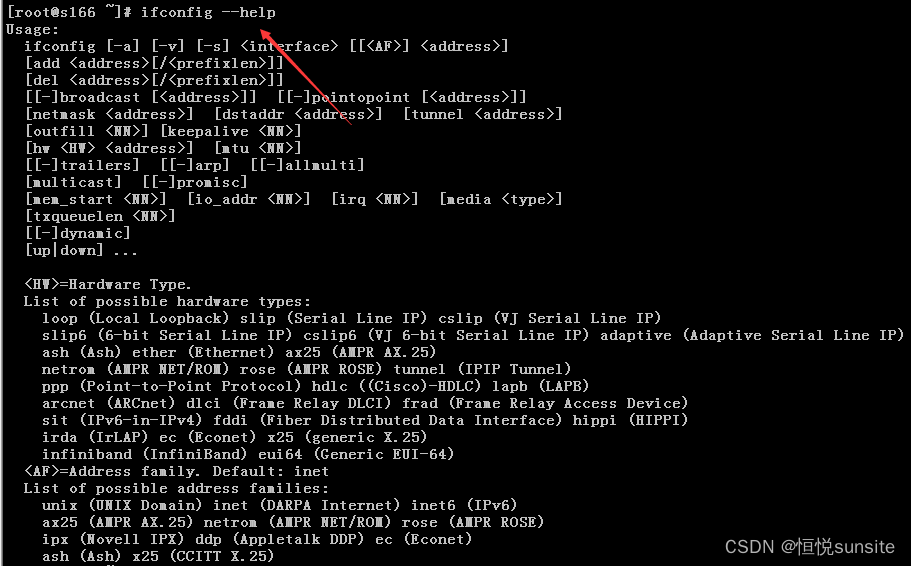
# 摘要
本文全面介绍了网络性能调优的基础知识,并着重探讨了Linux系统中广泛使用的网络配置工具ifconfig在性能加速和优化配置中的关键应用。通过对网络接口参数的优化、流量控制与速率调整以及网络故障的诊断与监控,本文提供了一系列实用的ifconfig应用技巧。进一步,本文讨论了ifconfig的高级应用,包括虚拟网络接口配置、多网络环境性能优化和安全性能提升。最后,本文比较了i
CMW500-LTE自动化测试脚本编写:从零基础到实战,提升测试效率

# 摘要
随着移动通信技术的快速发展,CMW500-LTE作为一款先进的测试设备,在无线通信领域占据重要地位。本文系统性地介绍了CMW500-LTE的自动化测试方法,涵盖了测试概述、基础理论、实践操作、性能优化、实战案例以及未来展望。通过对CMW500-LTE设备和接口的介绍,自动化测试环境的搭建,测试脚本编写理论与实践的深入
S4 ABAP编程数据处理

# 摘要
本文对S4 ABAP编程进行了全面的介绍和分析,从基础的数据定义与类型到数据操作与处理,再到数据集成与分析,以及实际应用和性能调优。特别指出S4 ABAP在供应链管理和财务流程中数据处理的重要性,并提供了性能瓶颈诊断和错误处理的策略。文章还探讨了面向对象编程在ABAP中的应用和S4 ABAP的未来创新技术趋势,强调了HANA数据库和云平台对AB
【BK2433高级定时器应用宝典】:定时器配置与应用手到擒来

# 摘要
定时器技术是嵌入式系统和实时操作系统中的核心组件,本文首先介绍了定时器的基础配置和高级配置策略,包括精确度设置、中断管理以及节能模式的实现。随后,文中详细探讨了定时器在嵌入式系统中的应用场景,如实时操作系统中的多任务调度集成
Eclipse MS5145扫码枪维护必修课:预防常见问题
# 摘要
Eclipse MS5145扫码枪作为一款广泛使用的条码读取设备,在日常使用和维护中需要特别关注其性能和可靠性。本文系统地概述了Eclipse MS5145扫码枪的维护基础,并深入探讨了其硬件组成部分及其工作原理,包括传感器、光源、解码引擎,以及条码扫描和数据传输机制。同时,本文详细介绍了日常维护流程、故障诊断与预防措施,以及如何实施高级维护技术如性能测试
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )