揭秘PHP数据库查询优化秘诀:提升效率10倍
发布时间: 2024-07-28 23:11:02 阅读量: 21 订阅数: 20 

# 1. PHP数据库查询基础**
PHP提供了强大的数据库查询功能,允许开发者从数据库中检索和操作数据。本节将介绍PHP数据库查询的基本概念和操作,包括:
- **连接数据库:**建立与数据库的连接,为查询和操作提供通道。
- **执行查询:**使用`mysqli_query()`或`PDO`等函数执行SQL查询,从数据库中检索数据。
- **获取查询结果:**使用`mysqli_fetch_array()`或`PDOStatement::fetch()`等方法获取查询结果集中的数据。
- **关闭连接:**执行完所有查询操作后,关闭与数据库的连接以释放资源。
# 2. 查询优化理论
### 2.1 索引的原理和类型
#### 2.1.1 索引的创建和管理
**索引的原理**
索引是一种数据结构,它可以加快对数据库表中数据的查询速度。索引通过将表中的数据组织成特定顺序,从而允许数据库快速查找特定值。
**索引的创建**
可以使用 `CREATE INDEX` 语句创建索引。语法如下:
```sql
CREATE INDEX index_name ON table_name (column_name);
```
例如,要为 `users` 表中的 `name` 列创建索引,可以使用以下语句:
```sql
CREATE INDEX idx_name ON users (name);
```
**索引的管理**
可以使用 `ALTER INDEX` 语句管理索引。语法如下:
```sql
ALTER INDEX index_name ON table_name [REBUILD | RENAME TO new_index_name | DROP];
```
例如,要重建 `idx_name` 索引,可以使用以下语句:
```sql
ALTER INDEX idx_name ON users REBUILD;
```
#### 2.1.2 索引的选取和优化
**索引的选取**
选择要创建索引的列时,需要考虑以下因素:
* 查询中经常使用的列
* 数据分布
* 列的基数
**索引的优化**
创建索引后,可以对其进行优化以提高查询性能。优化方法包括:
* 使用覆盖索引:覆盖索引包含查询所需的所有列,从而避免从表中读取数据。
* 使用唯一索引:唯一索引确保列中的值唯一,从而可以快速查找特定值。
* 使用组合索引:组合索引将多个列组合在一起,从而可以快速查找多个值的组合。
### 2.2 查询计划的分析和优化
#### 2.2.1 查询计划的生成和解读
**查询计划**
查询计划是数据库优化器生成的,它描述了数据库如何执行查询。查询计划包含以下信息:
* 表的访问顺序
* 索引的使用
* 连接类型
* 聚合操作
**查询计划的解读**
可以使用 `EXPLAIN` 语句查看查询计划。语法如下:
```sql
EXPLAIN SELECT * FROM table_name WHERE condition;
```
例如,要查看 `users` 表中 `name` 列等于 `John` 的查询计划,可以使用以下语句:
```sql
EXPLAIN SELECT * FROM users WHERE name = 'John';
```
#### 2.2.2 查询计划的优化策略
**查询计划的优化**
根据查询计划,可以采用以下策略优化查询:
* 使用正确的索引:确保查询计划使用正确的索引来查找数据。
* 优化连接:使用正确的连接类型并优化连接顺序。
* 避免不必要的聚合:如果查询不需要聚合,则避免使用聚合函数。
* 使用子查询:将复杂查询分解为更小的子查询,从而提高性能。
# 3.1 索引的应用和优化
#### 3.1.1 索引的合理使用
**合理选择索引列**
索引列的选择应遵循以下原则:
- 频繁查询的列
- 具有较高的基数的列(即取值较多的列)
- 参与连接或排序的列
**避免冗余索引**
冗余索引是指对同一列或组合列创建多个索引,这会增加数据库的维护开销,降低查询性能。
**避免过度索引**
过多的索引会增加数据库的存储开销,并降低插入、更新和删除操作的性能。因此,应根据实际查询需求合理创建索引。
#### 3.1.2 索引的维护和重建
**索引维护**
索引需要定期维护,以确保其有效性和完整性。常见的索引维护操作包括:
- **REBUILD INDEX**:重建索引,重新组织索引结构,提高查询效率。
- **ANALYZE TABLE**:分析表,更新索引统计信息,优化查询计划生成。
**索引重建**
当索引发生碎片或数据量大幅增加时,需要重建索引。重建索引可以提高查询性能,并释放碎片空间。
```sql
ALTER TABLE table_name REBUILD INDEX index_name;
```
### 3.2 查询语句的优化
#### 3.2.1 查询语句的结构和语法
**使用适当的查询类型**
根据查询目的,选择合适的查询类型,如 SELECT、INSERT、UPDATE、DELETE 等。
**优化查询语句语法**
遵守 SQL 语法规则,使用正确的关键字、语法结构和数据类型。
**使用别名**
使用别名可以简化查询语句,提高可读性。
```sql
SELECT id AS user_id, name AS user_name FROM users;
```
#### 3.2.2 查询语句的性能分析
**EXPLAIN 查询计划**
`EXPLAIN` 命令可以显示查询语句的执行计划,帮助分析查询性能。
```sql
EXPLAIN SELECT * FROM users WHERE name LIKE '%John%';
```
**分析执行计划**
执行计划中包含以下关键信息:
- **Type**:查询类型,如 ALL、INDEX、RANGE 等。
- **Rows**:估计返回的行数。
- **Extra**:其他信息,如使用的索引、连接类型等。
**优化查询语句**
根据执行计划,可以优化查询语句,如:
- 使用索引优化查询条件
- 优化连接方式
- 减少返回的行数
# 4. 高级查询优化技术
在本章节中,我们将探讨一些更高级的查询优化技术,这些技术可以进一步提高查询性能。
### 4.1 分区和分表的应用
#### 4.1.1 分区和分表的原理和优势
分区和分表是一种将大型表拆分成更小、更易管理的部分的技术。它可以显著提高查询性能,特别是对于包含大量数据的表。
分区是将表按某个特定列(称为分区键)的值将表划分为多个子集。分表则是将表按多个列的值进行拆分。
分区和分表的优势包括:
- **并行查询:**分区和分表允许并行查询,即同时在多个分区或分表上执行查询。这可以大大减少查询时间。
- **数据隔离:**分区和分表可以将数据隔离到不同的物理存储设备上。这可以提高数据安全性并简化数据管理。
- **可扩展性:**分区和分表允许轻松地添加或删除分区或分表,从而可以随着数据量的增长轻松地扩展数据库。
#### 4.1.2 分区和分表的实现和管理
分区和分表可以在大多数现代数据库系统中实现。实现过程通常涉及以下步骤:
1. **选择分区键:**选择一个具有良好分布且不会经常更改的列作为分区键。
2. **创建分区或分表:**使用数据库命令创建分区或分表。
3. **分配数据:**将数据分配到适当的分区或分表中。
4. **管理分区或分表:**随着数据量的增长,可能需要添加或删除分区或分表。
### 4.2 缓存和复制的应用
#### 4.2.1 缓存的原理和类型
缓存是一种存储经常访问数据的临时存储区域。它可以显著减少数据库查询时间,因为可以从缓存中快速检索数据,而无需访问数据库。
缓存有两种主要类型:
- **内存缓存:**存储在计算机内存中的缓存,访问速度极快。
- **磁盘缓存:**存储在磁盘上的缓存,访问速度较慢,但容量更大。
#### 4.2.2 缓存的配置和管理
缓存的配置和管理对于优化性能至关重要。需要考虑以下因素:
- **缓存大小:**缓存大小应足够大以容纳经常访问的数据,但又不能太大以至于影响性能。
- **缓存策略:**缓存策略决定了数据在缓存中的存储和替换方式。
- **缓存刷新:**缓存应定期刷新以确保数据是最新的。
### 4.3 NoSQL数据库的应用
#### 4.3.1 NoSQL数据库的特性和优势
NoSQL数据库是一种非关系型数据库,它不遵循传统的SQL模型。NoSQL数据库通常具有以下特性:
- **可扩展性:**NoSQL数据库可以轻松地扩展以处理大量数据。
- **灵活性:**NoSQL数据库可以存储各种类型的数据,包括文档、键值对和图形。
- **高性能:**NoSQL数据库通常比关系型数据库具有更高的性能。
#### 4.3.2 NoSQL数据库的选取和使用
选择和使用NoSQL数据库时需要考虑以下因素:
- **数据模型:**NoSQL数据库有不同的数据模型,包括文档、键值对和图形。选择最适合应用程序数据模型的数据库。
- **性能要求:**评估应用程序的性能要求,并选择能够满足这些要求的NoSQL数据库。
- **可扩展性:**考虑应用程序的可扩展性需求,并选择能够随着数据量的增长而轻松扩展的NoSQL数据库。
# 5.1 数据库性能分析工具
### 5.1.1 常用的数据库性能分析工具
数据库性能分析工具可以帮助我们深入了解数据库的运行状况,找出性能瓶颈并进行优化。常用的数据库性能分析工具包括:
- **MySQL Performance Schema**:MySQL 内置的性能分析工具,可以收集有关数据库操作、资源使用和等待事件的详细数据。
- **pt-query-digest**:一款流行的 MySQL 性能分析工具,可以分析慢查询日志并提供优化建议。
- **pg_stat_statements**:PostgreSQL 内置的性能分析工具,可以收集有关查询执行统计信息的数据。
- **New Relic APM**:一个全栈性能监控工具,可以分析数据库查询性能并提供优化建议。
- **Datadog APM**:另一个全栈性能监控工具,提供数据库性能分析功能,包括查询跟踪和慢查询检测。
### 5.1.2 性能分析的步骤和技巧
数据库性能分析通常涉及以下步骤:
1. **收集数据**:使用性能分析工具收集有关数据库操作、资源使用和等待事件的数据。
2. **分析数据**:识别性能瓶颈,例如慢查询、资源争用或等待事件。
3. **确定根本原因**:分析慢查询日志、执行计划或其他相关信息,以确定导致性能问题的根本原因。
4. **制定优化计划**:根据分析结果,制定优化计划,包括索引优化、查询优化或架构调整。
5. **实施优化**:实施优化计划并监控其影响。
**性能分析技巧:**
- **基准测试**:在优化之前,对数据库进行基准测试以建立性能基线。
- **使用慢查询日志**:启用慢查询日志以捕获执行时间超过阈值的查询。
- **分析执行计划**:使用 EXPLAIN 或 EXPLAIN ANALYZE 语句分析查询的执行计划,以了解其执行方式。
- **识别等待事件**:分析等待事件数据以确定数据库中资源争用的来源。
- **使用性能分析工具**:利用数据库性能分析工具自动化数据收集、分析和优化建议。
# 6. 数据库优化最佳实践
### 6.1 数据库设计原则
**6.1.1 数据模型的规范化**
规范化是数据库设计中的一项重要原则,旨在消除数据冗余和异常,确保数据的一致性和完整性。规范化分为多个级别,每个级别都有其特定的规则和约束。
* **第一范式(1NF):**每个属性(字段)都不可再分,并且与主键完全依赖。
* **第二范式(2NF):**除了满足 1NF 外,每个非主键属性都完全依赖于主键。
* **第三范式(3NF):**除了满足 2NF 外,每个非主键属性都不依赖于其他非主键属性。
**6.1.2 数据表的结构和关系**
数据表的结构和关系对数据库性能有很大影响。以下是一些最佳实践:
* **选择合适的表类型:**根据数据的特征选择合适的表类型,如 InnoDB、MyISAM 等。
* **定义主键和外键:**主键用于唯一标识表中的每条记录,外键用于建立表之间的关系。
* **使用适当的数据类型:**根据数据的范围和格式选择适当的数据类型,如 INT、VARCHAR、DATETIME 等。
* **避免冗余:**不要在多个表中存储相同的数据,这会增加维护成本和数据不一致的风险。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏为 PHP 数据库操作的全面指南,涵盖从基础连接到高级优化技术。通过一系列深入的文章,您将掌握数据库连接加速、查询优化、批量插入、更新策略、事务处理、备份和恢复、性能调优、索引优化、设计原则、关系建模、正则表达式查询、分页查询、缓存技术、连接池管理、异常处理、日志记录和数据库迁移等方面的技巧。本专栏旨在帮助您提升 PHP 数据库操作技能,提高效率,保障数据安全,并为您的应用程序构建高效可靠的数据架构。
专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
R语言数据处理高级技巧:reshape2包与dplyr的协同效果
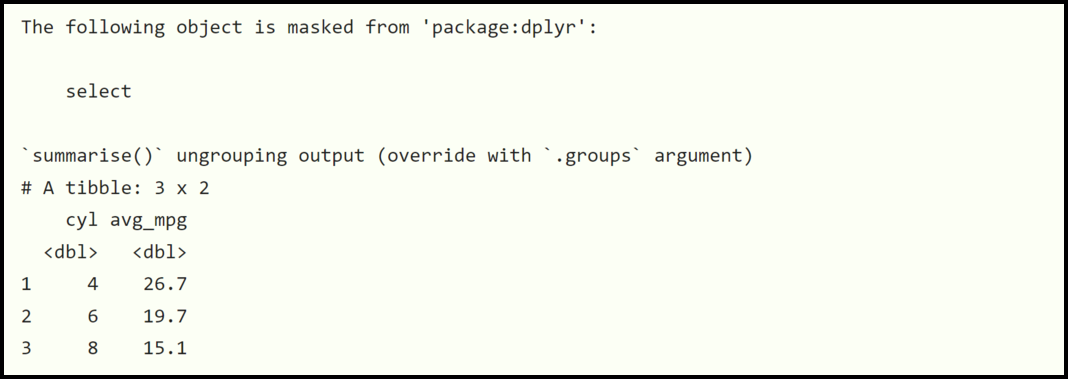
# 1. R语言数据处理概述
在数据分析和科学研究中,数据处理是一个关键的步骤,它涉及到数据的清洗、转换和重塑等多个方面。R语言凭借其强大的统计功能和包生态,成为数据处理领域的佼佼者。本章我们将从基础开始,介绍R语言数据处理的基本概念、方法以及最佳实践,为后续章节中具体的数据处理技巧和案例打下坚实的基础。我们将探讨如何利用R语言强大的包和
机器学习数据准备:R语言DWwR包的应用教程

# 1. 机器学习数据准备概述
在机器学习项目的生命周期中,数据准备阶段的重要性不言而喻。机器学习模型的性能在很大程度上取决于数据的质量与相关性。本章节将从数据准备的基础知识谈起,为读者揭示这一过程中的关键步骤和最佳实践。
## 1.1 数据准备的重要性
数据准备是机器学习的第一步,也是至关重要的一步。在这一阶
R语言数据透视表创建与应用:dplyr包在数据可视化中的角色

# 1. dplyr包与数据透视表基础
在数据分析领域,dplyr包是R语言中最流行的工具之一,它提供了一系列易于理解和使用的函数,用于数据的清洗、转换、操作和汇总。数据透视表是数据分析中的一个重要工具,它允许用户从不同角度汇总数据,快速生成各种统计报表。
数据透视表能够将长格式数据(记录式数据)转换为宽格式数据(分析表形式),从而便于进行
【R语言caret包多分类处理】:One-vs-Rest与One-vs-One策略的实施指南
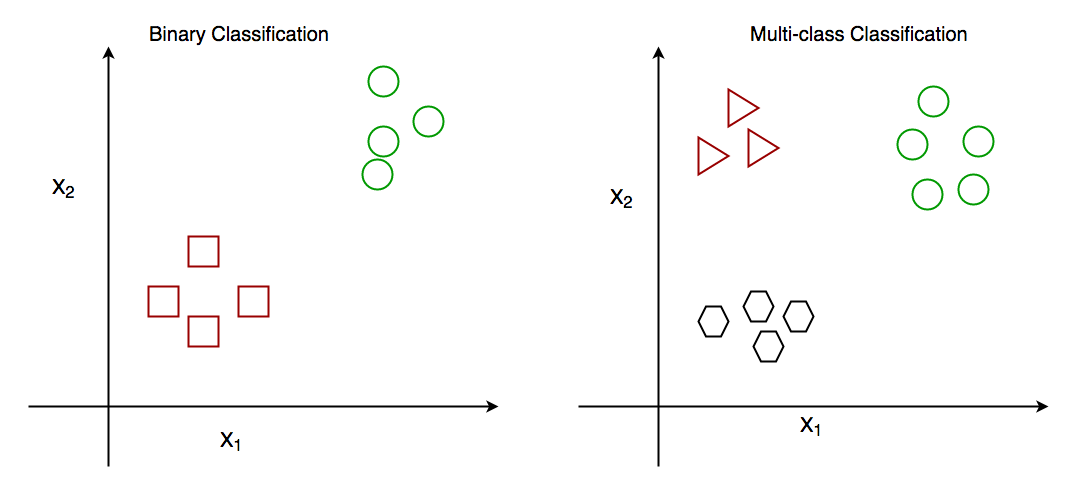
# 1. R语言与caret包基础概述
R语言作为统计编程领域的重要工具,拥有强大的数据处理和可视化能力,特别适合于数据分析和机器学习任务。本章节首先介绍R语言的基本语法和特点,重点强调其在统计建模和数据挖掘方面的能力。
## 1.1 R语言简介
R语言是一种解释型、交互式的高级统计分析语言。它的核心优势在于丰富的统计包
R语言复杂数据管道构建:plyr包的进阶应用指南

# 1. R语言与数据管道简介
在数据分析的世界中,数据管道的概念对于理解和操作数据流至关重要。数据管道可以被看作是数据从输入到输出的转换过程,其中每个步骤都对数据进行了一定的处理和转换。R语言,作为一种广泛使用的统计计算和图形工具,完美支持了数据管道的设计和实现。
R语言中的数据管道通常通过特定的函数来实现
【R语言数据包mlr的深度学习入门】:构建神经网络模型的创新途径

# 1. R语言和mlr包的简介
## 简述R语言
R语言是一种用于统计分析和图形表示的编程语言,广泛应用于数据分析、机器学习、数据挖掘等领域。由于其灵活性和强大的社区支持,R已经成为数据科学家和统计学家不可或缺的工具之一。
## mlr包的引入
mlr是R语言中的一个高性能的机器学习包,它提供了一个统一的接口来使用各种机器学习算法。这极大地简化了模型的选择、训练
【R语言Capet包集成挑战】:解决数据包兼容性问题与优化集成流程
# 1. R语言Capet包集成概述
随着数据分析需求的日益增长,R语言作为数据分析领域的重要工具,不断地演化和扩展其生态系统。Capet包作为R语言的一个新兴扩展,极大地增强了R在数据处理和分析方面的能力。本章将对Capet包的基本概念、功能特点以及它在R语言集成中的作用进行概述,帮助读者初步理解Capet包及其在
从数据到洞察:R语言文本挖掘与stringr包的终极指南

# 1. 文本挖掘与R语言概述
文本挖掘是从大量文本数据中提取有用信息和知识的过程。借助文本挖掘,我们可以揭示隐藏在文本数据背后的信息结构,这对于理解用户行为、市场趋势和社交网络情绪等至关重要。R语言是一个广泛应用于统计分析和数据科学的语言,它在文本挖掘领域也展现出强大的功能。R语言拥有众多的包,能够帮助数据科学
【formatR包错误处理】:解决常见问题,确保数据分析顺畅

# 1. formatR包概述与错误类型
在R语言的数据分析生态系统中,formatR包是不可或缺的一部分,它主要负责改善R代码的外观和结构,进而提升代码的可读性和整洁度。本章节首先对formatR包进行一个基础的概述,然后详细解析在使用formatR包时常见的错误类型,为后续章节的深
时间数据统一:R语言lubridate包在格式化中的应用

# 1. 时间数据处理的挑战与需求
在数据分析、数据挖掘、以及商业智能领域,时间数据处理是一个常见而复杂的任务。时间数据通常包含日期、时间、时区等多个维度,这使得准确、高效地处理时间数据显得尤为重要。当前,时间数据处理面临的主要挑战包括但不限于:不同时间格式的解析、时区的准确转换、时间序列的计算、以及时间数据的准确可视化展示。
为应对这些挑战,数据处理工作需要满足以下需求:
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )