机器学习赋能:OpenCV视频读取与保存,视频处理智能化,迈向未来
发布时间: 2024-08-14 07:57:30 阅读量: 27 订阅数: 44 

IQVIA:智“健”未来:人工智能与机器学习赋能中国医疗健康行业

# 1. 机器学习赋能视频处理
随着机器学习技术的不断发展,其在视频处理领域发挥着越来越重要的作用。机器学习赋能视频处理,使其能够实现智能化、自动化,从而极大地提高视频处理的效率和准确性。
机器学习算法可以从海量视频数据中学习视频内容的特征和模式,从而实现视频分析、理解、目标检测、动作识别等复杂任务。通过利用机器学习技术,视频处理系统可以自动识别视频中的对象、动作和事件,并对其进行分类、分割和跟踪。
此外,机器学习还可以在视频处理中优化视频质量、增强视频效果。例如,机器学习算法可以自动调整视频亮度、对比度和色彩平衡,去除视频中的噪声和伪影,从而提升视频的视觉体验。
# 2. OpenCV视频读取与保存
### 2.1 OpenCV概述
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,它提供了一系列用于图像处理、视频分析和机器学习的函数和算法。OpenCV被广泛应用于各种领域,包括:
- 图像处理
- 视频分析
- 机器学习
- 计算机视觉
- 人工智能
### 2.2 视频读取与保存的原理
视频本质上是一系列按顺序排列的图像帧。视频读取的过程涉及到从视频文件中提取这些帧,而视频保存的过程则涉及到将这些帧写入视频文件。
OpenCV提供了多种函数来读取和保存视频,这些函数利用了FFmpeg库。FFmpeg是一个强大的多媒体框架,它支持各种视频编解码器和容器格式。
### 2.3 OpenCV视频读取与保存的API
OpenCV提供了以下主要函数用于视频读取和保存:
- **VideoCapture:**用于打开和读取视频文件。
- **VideoWriter:**用于创建和写入视频文件。
**2.3.1 视频读取**
```python
import cv2
# 打开视频文件
cap = cv2.VideoCapture("video.mp4")
# 逐帧读取视频
while cap.isOpened():
# 读取下一帧
ret, frame = cap.read()
# 如果读取成功,则显示帧
if ret:
cv2.imshow("Frame", frame)
cv2.waitKey(1)
# 如果读取失败,则退出循环
else:
break
# 释放视频捕获器
cap.release()
```
**逻辑分析:**
- `cv2.VideoCapture("video.mp4")`:打开名为"video.mp4"的视频文件。
- `while cap.isOpened()`:循环读取视频帧,直到视频文件结束。
- `ret, frame = cap.read()`:读取下一帧。`ret`为布尔值,指示读取是否成功。`frame`为读取的帧。
- `if ret:`:如果读取成功,则显示帧。
- `cv2.imshow("Frame", frame)`:显示帧。
- `cv2.waitKey(1)`:等待1毫秒,以便用户查看帧。
- `cap.release()`:释放视频捕获器。
**2.3.2 视频保存**
```python
import cv2
# 创建视频写入器
writer = cv2.VideoWriter("output.mp4", cv2.VideoWriter_fourcc(*"mp4v"), 30, (640, 480))
# 逐帧写入视频
for i in range(100):
# 生成帧
frame = np.zeros((480, 640, 3), np.uint8)
# 写入帧
writer.write(frame)
# 释放视频写入器
writer.release()
```
**逻辑分析:**
- `cv2.VideoWriter("output.mp4", cv2.VideoWriter_fourcc(*"mp4v"), 30, (640, 480))`:创建视频写入器。第一个参数指定输出视频文件的名称,第二个参数指定视频编解码器(在这种情况下为"mp4v"),第三个参数指定帧率,第四个参数指定帧大小。
- `for i in range(100)`:循环生成和写入100帧。
- `frame = np.zeros((480, 640, 3), np.uint8)`:生成一个黑色帧。
- `writer.write(frame)`:将帧写入视

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《OpenCV视频读取与保存:从入门到精通的视频处理技巧》专栏深入剖析了OpenCV视频处理技术,从基础到高级,循序渐进地讲解了视频读取、保存、性能优化、常见问题解决、自动化、图像处理、深度学习、弹性可扩展、敏捷高效、高效流程、安全可靠、稳定高效、运行状况洞察和故障排除等各个方面。本专栏旨在帮助读者快速掌握视频处理核心技术,提升处理效率,解锁更多视频处理的可能性,引领创新,打造高效、安全、稳定的视频处理解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Unity C# Mathf.Abs() 函数性能成本深度剖析

# 摘要
本论文全面介绍 Mathf.Abs() 函数的定义、应用及内部实现机制,并重点分析了其性能特性。通过探讨 Mathf.Abs() 在不同场景下的性能成本,我们提供了量化的性能分析,揭示了在高频调用情况下可能出现的性能瓶颈。接着,本文探讨了多种避免性能损耗的策略,包括代码优化技巧和寻找替代方案。最后,结合复杂系统的应用实例,本文展示了 Mathf.Abs() 的实际应用效果,并对未来函数的改进与优化方向提供了展望。本研究旨在帮助开发者更深入理解
深度剖析LGO:高级用户如何优化作业流程与数据管理

# 摘要
本文全面介绍LGO系统及其在作业流程优化中的应用。首先概述了LGO的基本概念和作业流程基础,然后深入分析了LGO在作业流程优化中的理论和实践应用,包括自动化、监控及日志记录。文中还探讨了LGO在数据管理方面的能力,阐述了高级数据挖掘、数据安全与备份,以及数据库集成与优化的策略。在跨部门协作方面,讨论了LGO如何提
MTK工程模式下的代码优化:提升系统响应速度的高效方法

# 摘要
本文针对MTK工程模式下的代码优化进行了全面的研究和实践探讨。首先概述了代码优化的基本理论基础,接着详细分析了系统响应速度优化的必要性和实施方法,包括性能评估、资源消耗最小化、系统架构调整、编译器优化技术等。随后,本文深入到具体的代码优化策略,探讨了数据处理、内存管理和多线程并发优化的实践方法。文章进一步研究了MTK工程模式下的代码调试与性能分析技巧,包括调试工具的使用、性能分
个性化DEWESoftV7.0界面

# 摘要
DEWESoft V7.0作为一款先进的数据采集与分析软件,其界面定制功能极大地提升了用户体验和工作效率。本文首先概述了DEWESoft V7.0的基本界面和定制基础,随后详细介绍了界面元素的类型、功能、布局定制以及主题与样式的自定义。文章进一步探讨了高级定制技术,包括脚本编程的应用、插件开发与界面扩展、以及界面的维护与管理策略。通过实践案例分析,本文展现了定制界面在实际工作中的应用,并分享了成功案例
【DELL PowerEdge T30 硬盘故障应对大揭秘】:数据安全与恢复技巧

# 摘要
本文全面分析了DELL PowerEdge T30服务器硬件及其硬盘基础知识,深入探讨了硬盘故障的理论、诊断方法、数据安全与备份技术,以及高级技术应对策略。通过对硬盘结构、故障
KeeLoq算法漏洞与防护:安全专家的实战分析(专业性、权威性)

# 摘要
KeeLoq算法是用于无线遥控加密的常见加密技术,本文详细概述了KeeLoq算法及其漏洞,深入分析了其工作原理、安全性评估、漏洞发现与分析,以及修复策略和防护措施。通过对KeeLoq算法的数学模型、密钥管理机制以及理论与实际应用中的安全挑战的探讨,揭示了导致漏洞的关键因素。同时,本文提出了相应的修复方案和防护措施,包括系统升级、密钥管理强化,以及安全最佳实践的建议,并展望了算法未来改进的方向和在新兴技术中的应用。通过案
【OS单站性能调优】:从客户反馈到系统优化的全过程攻略

# 摘要
性能调优是确保系统稳定运行和提升用户体验的关键环节。本文首先概述了性能调优的重要性和基础概念,强调了性能监控和数据分析对于识别和解决系统瓶颈的作用。随后,深入探讨了系统级优化策略,包括操作系统内核参数、网络性能以及系统服务和进程的调整。在应用性能调优实践中,本文介绍了性能测试方法和代码级性能优化的技巧,同时分析了数据库性能调优的重要性。最后,
【Unix gcc编译器全攻略】:最佳实践+常见问题一网打尽

# 摘要
本文深入介绍Unix环境下的gcc编译器,覆盖基础使用、核心功能、项目最佳实践、高级特性、常见问题解决以及未来展望等多方面内容。首先,介绍了gcc编译器的基本概念、安装与配置,并详解了其编译流程和优化技术。随后,探讨了在多文件项目中的编译管理、跨平台编译策略以及调试工具的使用技巧。文章进一步分析gcc对现代C++标准的支持、内建函数以及警告和诊断机制。最后,本文讨论了
【如何预防潜在故障】:深入解析系统故障模式与影响分析(FMEA)
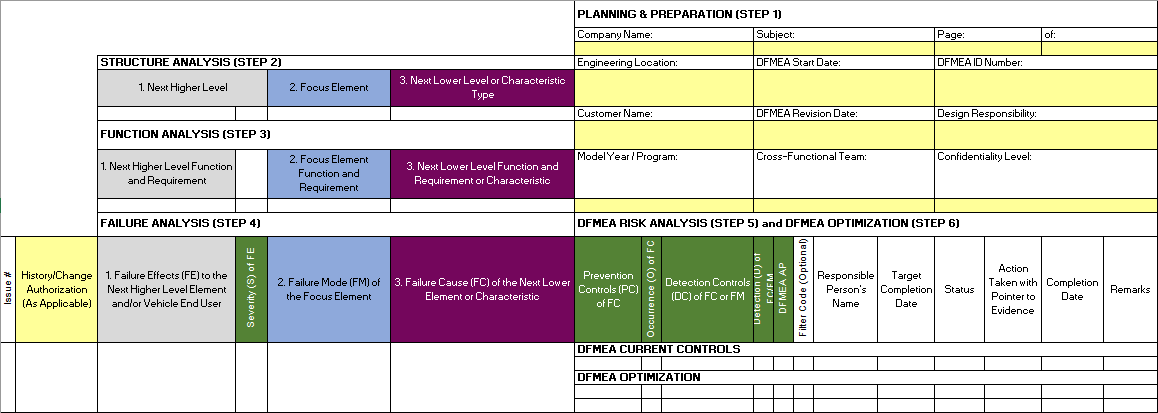
# 摘要
故障模式与影响分析(FMEA)是一种系统性、预防性的质量和可靠性工具,用于识别产品或过程中可能出现的故障模式、原因和影响,并评估其严重性。本文系统介绍了FMEA的理论基础、应用流程以及其在实践操作和预防性维护中的应用。通过分析FMEA的种类和方法论,包括设计FMEA(DFMEA)和过程FMEA(PFMEA),文章深入阐述了建立FMEA团队、进行故障树分析(FTA)和案例研究的实
架构设计与性能优化:字节跳动的QUIC协议应用案例

# 摘要
QUIC协议作为下一代互联网传输协议,旨在解决现有TCP协议中存在的问题,特别是在延迟敏感型应用中的性能瓶颈。本文首先概述了QUIC协议及其网络性能理论基础,深入分析了网络延迟、吞吐量、多路复用与连接迁移等关键性能指标,并探讨了QUIC协议的安全特性。接着,通过字节跳动的QUIC协议实践应用案例,本文讨论了部署与集成过程中的技术挑战和性能优化实例。进一步,从架
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )