机器学习算法与应用实例
发布时间: 2023-12-27 02:40:12 阅读量: 28 订阅数: 30 
# 章节一:机器学习算法概述
## 1.1 机器学习的基本概念和分类
机器学习是一门研究如何使计算机系统利用经验改善性能的科学。它通过构建和训练模型,使计算机系统能够从数据中学习并做出预测或者决策。根据学习方式和任务类型的不同,机器学习可以分为监督学习、无监督学习、强化学习等种类。
- 监督学习:通过已知输入和输出的样本数据,训练出一个模型,使其能够对未知数据做出合理的预测。常见算法包括线性回归、逻辑回归、支持向量机等。
- 无监督学习:模型只能利用输入数据进行学习,无法利用已有的标记信息。主要任务包括聚类、降维、关联规则挖掘等。常见算法有K均值聚类、主成分分析、Apriori算法等。
- 强化学习:模型从环境中接收奖励信号,通过试错来学习取得最大化长期利益的行为策略。典型算法有Q学习、深度强化学习等。
## 1.2 监督学习、无监督学习和强化学习的概念
### 监督学习
监督学习是机器学习的一种范式,通过已知输入和输出的样本数据,训练出一个模型,使其能够对未知数据做出合理的预测。
### 无监督学习
无监督学习是指利用输入数据进行学习,无法利用已有的标记信息。主要任务包括聚类、降维、关联规则挖掘等。
### 强化学习
强化学习是模型从环境中接收奖励信号,通过试错来学习取得最大化长期利益的行为策略。
## 1.3 机器学习算法的发展历程
机器学习的发展可以概括为从传统的符号主义学习(基于规则和逻辑)向连接主义学习(基于神经网络和统计学习)再到深度学习的发展历程。在大数据和计算能力不断提升的背景下,机器学习算法逐步走向复杂、高效和智能化的发展道路。
## 章节二:监督学习算法
### 2.1 线性回归算法及其应用实例
线性回归是一种基本的监督学习算法,用于预测连续型变量的取值。它通过拟合数据点与自变量之间的线性关系来进行预测,是许多其他机器学习算法的基础。在实际应用中,线性回归被广泛应用于经济学、金融学、生物学等领域。
```python
# Python代码示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 生成随机数据
np.random.seed(0)
X = np.random.rand(100, 1)
y = 2 + 3 * X + np.random.rand(100, 1)
# 使用线性回归拟合数据
model = LinearRegression().fit(X, y)
# 绘制拟合曲线
plt.scatter(X, y, color='b')
plt.plot(X, model.predict(X), color='r')
plt.show()
```
**代码说明:**
- 通过`numpy`生成随机数据X和y
- 使用`LinearRegression`模型拟合数据
- 使用`matplotlib`绘制散点图和拟合曲线
**结果说明:**
上述代码中,我们通过线性回归模型拟合了一组随机生成的数据,并绘制出了拟合曲线。可以看到,拟合曲线较好地适配了数据点,展示了线性回归的预测能力。
### 2.2 决策树算法及其在分类和回归中的应用
决策树是一种常见的监督学习算法,可用于分类和回归任务。它通过构建树状结构来对数据进行预测,易于理解和解释,在实际应用中具有广泛的适用性。
```java
// Java代码示例
import java.util.*;
import weka.classifiers.trees.J48;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;
public class DecisionTreeExample {
public static void main(String[] args) throws Exception {
// 加载数据集
DataSource source = new DataSource("iris.arff");
Instances data = source.getDataSet();
if (data.classIndex() == -1) {
data.setClassIndex(data.numAttributes() - 1);
}
// 构建决策树模型
J48 tree = new J48();
tree.buildClassifier(data);
System.out.println(tree);
}
}
```
**代码说明:**
- 使用Weka库载入鸢尾花数据集
- 构建J48决策树模型并训练数据
- 输出构建好的决策树模型
**结果说明:**
上述Java代码中,我们使用Weka库加载了鸢尾花数据集,并构建了J48决策树模型进行训练。最终输出了构建好的决策树模型,展示了决策树在分类问题中的应用实例。
### 2.3 支持向量机算法原理与实践案例
支持向量机(SVM)是一种常见的监督学习算法,用于分类和回归分析。它通过寻找一个最优超平面来进行分类,具有较强的泛化能力和鲁棒性,在实践中被广泛应用于文本分类、图像识别等领域。
```go
// Go代码示例
package main
import (
"fmt"
"github.com/sjwhitworth/golearn/base"
"github.com/sjwhitworth/golearn/evaluation"
"github.com/sjwhitworth/golearn/svm"
)
func main() {
// 载入数据集
rawData, err := base.ParseCSVToInstances("iris.csv", true)
if err != nil {
fmt.Println(err)
return
}
// 初始化一个新的SVC模型
cls := svm.NewSVC(svm.RBFKernel, 0.1, 1e-3)
// 使用交叉验证评估模型
cfs, _ := evaluation.GenerateCrossFoldValidationConfusionMatrices(rawData, cls, 5)
// 输出评估结果
mean, variance := evaluation.GetCrossValidatedMetric(cfs, evaluation.GetAccuracy)
fmt.Printf("Accuracy\n%.2f (+/- %.2f)\n", mean, variance)
}
```
**代码说明:**
- 使用golearn库载入鸢尾花数据集
- 初始化一个新的SVC模型并进行交叉验证评估
- 输出模型的准确率评估结果
**结果说明:**
以上Go语言代码中,我们使用golearn库载入了鸢尾花数据集,并初始化了一个新的SVC(支持向量分类)模型进行交叉验证评估,最终输出了模型的准确率评估结果,展示了支持向量机算法在实践中的应用案例。
### 章节三:无监督学习算法
#### 3.1 聚类算法概述及K均值聚类应用实例
聚类是一种无监督学

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏《testlink》涵盖了丰富多彩的技术主题,囊括了HTTP协议、网站性能优化、数据库索引设计、Python数据可视化、RESTful API、React框架、Node.js异步编程、Docker容器技术、Git分支管理、前端性能优化、机器学习算法、正则表达式、AWS云计算服务、移动应用UI_UX设计、Linux系统优化、微服务架构、Kubernetes容器编排、JavaScript设计模式以及大数据处理等领域。通过深入浅出的文章,读者将深入了解这些关键技术的基本原理、优化策略、应用实例以及最佳实践,助力他们在技术道路上不断前行。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Zorin OS Python环境搭建】:开发者入门与实战手册

# 1. Zorin OS概述及Python简介
## Zorin OS概述
Zorin OS 是一种基于Linux的开源操作系统,设计之初就以用户体验为中心,旨在为用户提供一个界面友好、功能全面的操作环境,尤其是让那些从Windows或Mac OS转过来的新用户能快速上手。它利用了最新的技术来保证系统运行的稳定性和速度,并且对安全
【高级存储解决方案】:在VMware Workstation Player中配置共享存储的最佳实践

# 1. 高级存储解决方案概述
在当今的企业IT环境中,数据的存储、管理和保护是核心需求。随着技术的进步,传统存储解决方案已不能完全满足现代化数据中心的严格要求。因此,企业正在寻求更加高级的存储解决方案来提高效率、降低成本,并确保数据的高可用性。本章将简要介绍高级存储解决方案的概念、关键特性和它们对企业IT战略的重要性。
## 1.1 存储
【数据分析师必备】:TagSoup将HTML转换为结构化数据的技巧
# 1. HTML与结构化数据基础
## 1.1 HTML与结构化数据概述
HTML(超文本标记语言)是构建网页内容的标准标记语言。随着Web的发展,HTML已从简单的文档展示发展为包含丰富结构化信息的复杂文档格式。结构化数据是指以一种可预测且便于处理的格式来组织信息,如使用标签和属性将内容分类、标记和赋予意义。这种数据格式化有助于搜索引擎更好地理解网页内容,为用户
【大数据处理】:结合Hadoop_Spark轻松处理海量Excel数据
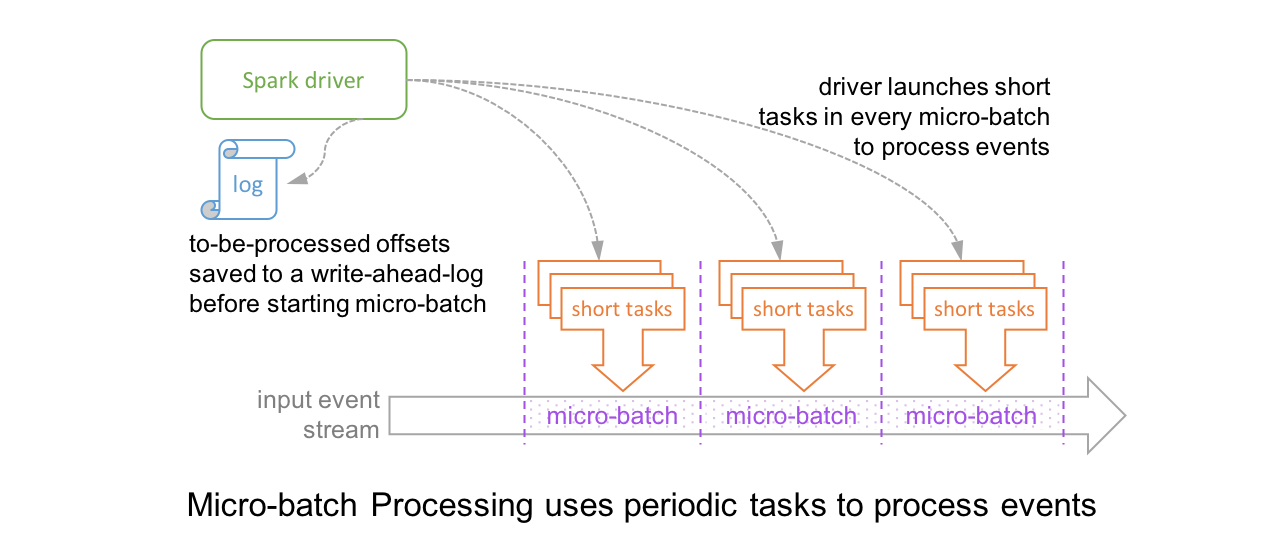
# 1. 大数据与分布式计算基础
## 1.1 大数据时代的来临
随着信息技术的快速发展,数据量呈爆炸式增长。大数据不再只是一个时髦的概念,而是变成了每个企业与组织无法忽视的现实。它在商业决策、服务个性化、产品优化等多个方面发挥着巨大作用。
## 1.2 分布式计算的必要性
面对如此庞大且复杂的数据,传统单机计算已无法有效处理。分布式计算作为一种能够将任务分散到多台计算机上并行处
【性能基准测试】:Apache POI与其他库的效能对比

# 1. 性能基准测试的理论基础
性能基准测试是衡量软件或硬件系统性能的关键活动。它通过定义一系列标准测试用例,按照特定的测试方法在相同的环境下执行,以量化地评估系统的性能表现。本章将介绍性能基准测试的基本理论,包括测试的定义、重要性、以及其在实际应用中的作用。
## 1.1 性能基准测试的定义
性能基准测试是一种评估技术,旨在通过一系列
跨平台【Java Excel库比较】:寻找最适合你项目的工具,一步到位

# 1. Java操作Excel的必要性和基本原理
在现代企业中,数据处理是一项基础而重要的工作。Excel由于其易用性和灵活性,被广泛地应用在数据管理和分析领域。Java作为一款企业级编程语言,其在操作Excel方面的需求也日益增加。从简单的数据导出到复杂的报表生成,Java操作Ex
Ubuntu桌面环境个性化定制指南:打造独特用户体验

# 1. Ubuntu桌面环境介绍与个性化概念
## 简介 Ubuntu 桌面
Ubuntu 桌面环境是基于 GNOME Shell 的一个开源项目,提供一个稳定而直观的操作界面。它利用 Unity 桌面作为默认的窗口管理器,旨在为用户提供快速、高效的工作体验。Ubuntu 的桌面环境不仅功能丰富,还支持广泛的个性化选项,让每个用户都能根据
【Linux Mint Cinnamon性能监控实战】:实时监控系统性能的秘诀

# 1. Linux Mint Cinnamon系统概述
## 1.1 Linux Mint Cinnamon的起源
Linux Mint Cinnamon是一个流行的桌面发行版,它是基于Ubuntu或Debian的Linux系统,专为提供现代、优雅而又轻量级的用户体验而设计。Cinnamon界面注重简洁性和用户体验,通过直观的菜单和窗口管理器,为用户提供高效的工作环境。
#
Linux Mint 22用户账户管理
# 1. Linux Mint 22用户账户管理概述
Linux Mint 22,作为Linux社区中一个流行的发行版,以其用户友好的特性获得了广泛的认可。本章将简要介绍Linux Mint 22用户账户管理的基础知识,为读者在后续章节深入学习用户账户的创建、管理、安全策略和故障排除等高级主题打下坚实的基础。用户账户管理不仅仅是系统管理员的日常工作之一,也是确保Linux Mint 22系统安全和资源访问控制的关键组成
【PDF库在Web应用中的集成】:将PDF处理功能嵌入Java EE应用,Web开发者的福音

# 1. PDF库在Web应用中的重要性
随着数字化时代的到来,Web应用已经成为了日常工作中不可
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )