xml SAX终极指南:如何构建高效XML解析器
发布时间: 2024-10-05 08:42:00 阅读量: 43 订阅数: 25 
# 1. XML和SAX解析基础
在当今的信息技术世界中,可扩展标记语言(XML)一直是数据交换和存储的关键格式之一。它提供了一种灵活的方式来组织和表示数据,这使得它在多个行业得到了广泛的应用。为了从XML文档中提取信息,解析技术是必不可少的工具。在此过程中,SAX(Simple API for XML)解析器扮演了一个极为重要的角色,因其事件驱动模型而闻名。本章将为你介绍XML的基本概念以及SAX解析器的基础知识,为深入理解和使用SAX解析技术打下坚实的基础。
## 1.1 XML简介
可扩展标记语言(XML)是一种用于存储和传输数据的标记语言。与HTML不同,XML不预定义任何标签,开发者可以创建自己的标签和属性来描述数据。它支持复杂的层次结构,适合用来表示复杂信息。这种灵活性让XML成为了一种在不同系统和平台间交换数据的理想格式。
## 1.2 XML的结构
XML文档由元素、属性、文本、注释、处理指令和实体组成。每个元素由起始标签、内容和结束标签组成。例如:
```xml
<book>
<title>Effective XML</title>
<author>Elliotte Rusty Harold</author>
</book>
```
这里的 `<book>`, `<title>`, `<author>` 是起始标签,`</book>`, `</title>`, `</author>` 是对应的结束标签。`Effective XML` 和 `Elliotte Rusty Harold` 则是这些元素的内容。
## 1.3 SAX解析器简介
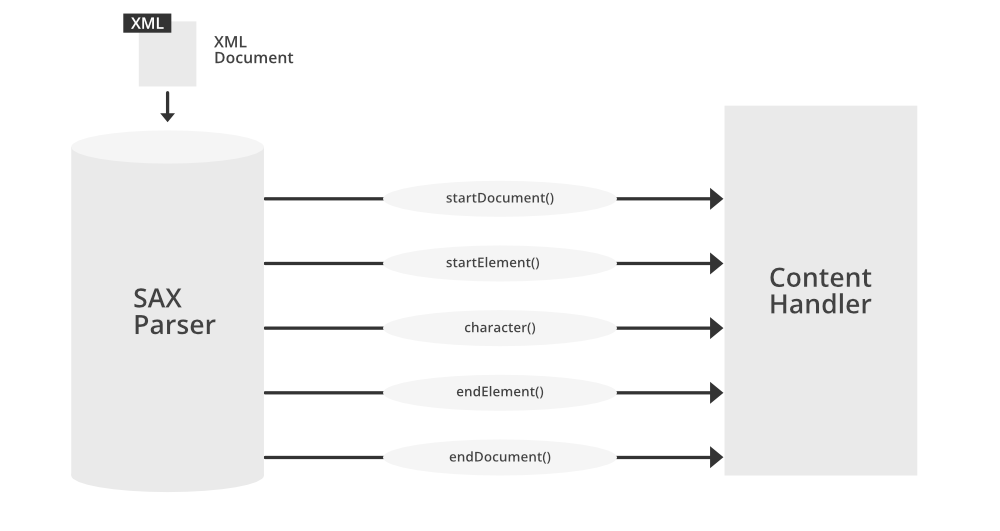
SAX解析器是用于处理XML文档的一种简单、快速、事件驱动的方法。SAX通过触发一系列事件,如开始标签、结束标签、字符数据等,来实现对XML文档的解析。开发者需要实现事件处理器(Handler)接口,从而在这些事件发生时作出响应。SAX的这种模式特别适合于处理大型XML文档,因为它不需要将整个文档加载到内存中。
SAX解析器的工作原理和它如何利用事件驱动模型在接下来的章节中进行更详细的探讨。
# 2. SAX解析器的工作原理
## 2.1 SAX解析器的内部机制
### 2.1.1 事件驱动模型解析
SAX解析器采用事件驱动模型进行XML文档的解析,这一模型的核心在于将解析过程视为一系列事件的序列。每当解析器读取XML文档中的标签、文本或其他元素时,就会触发相应类型的事件。这些事件被组织在一定的顺序中,形成一个事件流,应用程序可以监听这些事件并作出相应的处理。
事件驱动模型的优点在于其效率和低内存占用,因为它不需要加载整个文档到内存中,从而可以处理大型的XML文件。同时,事件驱动模型允许开发者在解析过程中实时响应事件,实现灵活的解析逻辑。
### 2.1.2 Handler接口的作用和实现
为了处理这些事件,SAX定义了一组Handler接口,主要包括`ContentHandler`、`ErrorHandler`、`DTDHandler`和`EntityResolver`等。应用程序通过实现这些接口来监听并响应相应的事件。
- `ContentHandler`:用于接收文档内容事件,如元素开始、结束标签和字符数据的事件。
- `ErrorHandler`:用于接收文档解析错误事件。
- `DTDHandler`:用于接收文档类型定义(DTD)事件。
- `EntityResolver`:用于解析外部实体,提供自定义的输入源。
以`ContentHandler`为例,当解析器遇到文档的开始和结束标签时,会调用`startElement`和`endElement`方法。对于字符数据,`characters`方法会被调用。通过这些方法,开发者可以获取当前解析到的内容,并执行相应的逻辑。
```java
public class MyContentHandler extends DefaultHandler {
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
// 当遇到一个开始标签时,执行的代码
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
// 当遇到一个结束标签时,执行的代码
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
// 当遇到字符数据时,执行的代码
}
}
```
通过实现这些接口,开发者可以构建出复杂的事件处理逻辑,满足各种特定的XML解析需求。
## 2.2 SAX解析器的配置与初始化
### 2.2.1 SAXParserFactory的使用
SAX解析器的配置与初始化是从创建一个`SAXParserFactory`实例开始的。这个工厂类提供了获取`SAXParser`实例的方法,`SAXParser`是一个包装器,用于实际执行XML文档的解析操作。
```java
SAXParserFactory factory = SAXParserFactory.newInstance();
factory.setFeature("***", true);
SAXParser saxParser = factory.newSAXParser();
```
在这段代码中,`setFeature`方法用于设置解析器的特性,例如启用对命名空间前缀的支持。这些特性可以影响解析器的行为,如是否支持命名空间等。
### 2.2.2 XMLReader的配置
一旦获得了`SAXParser`实例,通常会通过它获取一个`XMLReader`对象进行更细致的配置。`XMLReader`是实际进行解析操作的组件,它提供了一系列设置方法,允许用户配置错误处理、命名空间支持、实体解析等。
```java
XMLReader reader = saxParser.getXMLReader();
reader.setContentHandler(new MyContentHandler());
reader.setErrorHandler(new MyErrorHandler());
reader.parse("file.xml");
```
这段代码展示了如何将自定义的`ContentHandler`和`ErrorHandler`绑定到`XMLReader`上,并开始解析指定的XML文件。
## 2.3 SAX解析中的核心组件
### 2.3.1 ContentHandler接口详解
`ContentHandler`接口是SAX解析中最为核心的组件之一,它定义了一系列方法来处理XML文档的内容事件。通过实现`ContentHandler`接口,开发者可以捕捉到XML文档中所有重要的内容结构。
```java
public interface ContentHandler {
void startDocument() throws SAXException;
void endDocument() throws SAXException;
void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException;
void endElement(String uri, String localName, String qName) throws SAXException;
void characters(char[] ch, int start, int length) throws SAXException;
// 其他方法略...
}
```
这些方法分别对应文档开始、文档结束、元素开始标签、元素结束标签和字符数据的事件。实现这些方法,可以使得开发者能够在文档被解析的同时,即时处理文档内容。
### 2.3.2 ErrorHandler接口及其应用
与`ContentHandler`并重的另一个接口是`ErrorHandler`,它定义了三个方法来处理解析错误:
```java
public interface ErrorHandler {
void warning(SAXParseException exception) throws SAXException;
void error(SAXParseException exception) throws SAXException;
void fatalError(SAXParseException exception) throws SAXException;
}
```
- `warning`方法用于处理潜在的、非致命的解析警告。
- `error`方法用于处理解析错误,可能解析器能够从错误中恢复继续解析。
- `fatalError`方法用于处理致命错误,解析器遇到此类错误将立即停止解析。
通过实现`ErrorHandler`接口,开发者可以对解析过程中可能遇到的错误进行有效的控制和响应,例如记录错误日志、向用户报告错误,或者执行一些清理工作。
以上,第二章详细介绍了SAX解析器的工作原理,包括其内部机制、配置与初始化步骤,以及核心组件的使用和作用。接下来,我们将在第三章深入探讨SAX解析实践技巧,进一步揭示如何在实际开发中应用这些知识。
# 3. SAX解析实践技巧
在探讨了SAX解析器的工作原理之后,我们进入更为实际的操作层面。在这一章节中,我们将深入探讨如何通过SAX解析器进行高效的XML解析,包括解析过程中的策略优化、错误处理和异常管理、性能优化与调优等技巧。
## 高效解析XML的策略
### 缓存和状态管理
在处理大型XML文档时,SAX解析器通常需要跟踪大量的数据状态信息。为了提高解析效率,我们可以利用缓存来保存那些经常访问的数据,从而减少对XML文档的重复读取和解析。
例如,我们可以设置一个简单的缓存策略来存储已经解析过的元素,这样当下次遇到相同的元素时,可以直接从缓存中获取数据,避免重复解析。在Java中,可以使用`ConcurrentHashMap`这样的线程安全的哈希表来实现这样的缓存。
```java
import java.util.concurrent.ConcurrentHashMap;
public class XMLCache {
private ConcurrentHashMap<String, Object> cache;
public XMLCache() {
cache = new ConcurrentHashMap<>();
}
public void put(String key, Object value) {
cache.put(key, value);
}
public Object get(String key) {
return cache.get(key);
}
}
```
通过使用上述的缓存,我们可以在解析过程中减少不必要的资源消耗,提高整体的处理速度。
### 事件过滤和拦截
在SAX解析过程中,我们可能会遇到大量不需要的元素和属性,这些无关信息会降低解析效率。因此,实现一个事件过滤机制是一个明智的选择,通过过滤掉不需要的事件,可以显著提高性能。
可以通过扩展`DefaultHandler`类并重写相应的方法来实现事件过滤。例如,只关心特定标签的开始和结束事件,我们可以重写`startElement`和`endElement`方法,忽略其他事件:
```java
import org.xml.sax.helpers.DefaultHandler;
public class FilteredHandler extends DefaultHandler {
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if (!"interestedElement".equals(localName)) return; // 只处理感兴趣的元素
// 处理感兴趣的元素开始事件
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if (!"interestedElement".equals(localName)) return; // 只处理感兴趣的元素结束事件
// 处理感兴趣的元素结束事件
}
}
```
## 错误处理和异常管理
### 解析错误的捕获
在处理XML文档时,可能会遇到格式错误或不规范的文档结构,这些都可能导致解析失败。为了确保程序的健壮性,应当对解析过程中的错误进行有效的捕获和处理。
SAX解析器提供了一个`ErrorHandler`接口,允许开发者自定义错误处理逻辑。通过实现这个接口,我们可以针对不同的错误类型(如警告、错误、严重错误)给出相应的处理策略:
```java
import org.xml.sax.ErrorHandler;
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
public class CustomErrorHandler implements ErrorHandler {
@Override
public void warning(SAXParseException e) throws SAXException {
// 处理警告信息
}
@Override
public void error(SAXParseException e) throws SAXException {
// 处理错误信息
}
@Override
public void fatalError(SAXParseException e) throws SAXException {
// 处理严重错误,通常会导致解析立即终止
}
}
```
通过上述方式,我们可以捕获并处理解析过程中的各种异常情况,确保程序能够优雅地处理各种错误。
### 异常处理的最佳实践
异常处理不仅包括错误的捕获,还应当包括如何合理地使用异常机制,以避免程序在遇到错误时直接崩溃。最佳实践包括:
- 避免捕获太宽泛的异常(如`Exception`),而应该尽可能地捕获更具体的异常类型,以提供更精确的错误处理逻辑。
- 通常不建议在处理器(如`ContentHandler`)中抛出异常,因为这可能导致解析器中断。应当使用`ErrorHandler`来处理异常情况。
- 在异常处理逻辑中记录详细的错误日志,包括错误信息、发生错误的文件和位置,以及可能的话,包含堆栈跟踪信息。
## 性能优化与调优
### 性能分析工具
对于任何性能优化工作,首要步骤都是找到性能瓶颈。这通常需要利用性能分析工具来实现,例如Java中的JProfiler、VisualVM等,这些工具可以帮助我们识别出程序中的热点代码和性能瓶颈。
在使用这些工具时,应当关注以下几个方面:
- XML解析器读取和处理XML文档的时间开销。
- 哪些元素或属性的处理消耗了较多的时间。
- 内存使用情况,特别是缓存是否导致内存溢出。
### SAX解析器的性能调优
为了进一步提高SAX解析的性能,可以尝试以下策略:
- 精简事件处理器:在实现自定义的事件处理器时,尽量减少不必要的操作。例如,在`startElement`和`endElement`方法中,避免执行复杂的逻辑,仅进行必要的状态更新或记录。
- 使用异步解析:当处理大型文件且不依赖于同步读取时,可以考虑使用异步I/O进行解析。这样可以避免因等待磁盘I/O而阻塞主线程,从而提高解析效率。
- 调整解析器参数:不同的SAX解析器实现可能允许用户调整各种参数来优化性能。例如,调整缓冲区大小,可以减少磁盘I/O次数,提升解析速度。
```java
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.XMLReaderFactory;
public class SAXParserTuning {
public static void main(String[] args) throws Exception {
XMLReader parser = XMLReaderFactory.createXMLReader();
// 可以在这里设置解析器参数,例如:
// parser.setProperty("***", 10000);
parser.setContentHandler(new MyContentHandler());
// 解析XML文档
}
}
```
通过实践上述优化策略,可以有效提高SAX解析的性能,并使得应用程序能够更加高效地处理XML数据。
# 4. SAX在实际项目中的应用
## 4.1 大规模XML文件的处理
在处理大量数据时,内存管理和处理效率变得至关重要。SAX解析器由于其流式处理的特性,可以在读取XML文件的同时进行解析处理,而不需要先将整个文件加载到内存中。这种处理方式特别适合于大规模的XML文件。
### 4.1.1 流式处理技术
流式处理技术是一种边读边处理的方式,可以在文件被完全读取之前就开始解析工作。这种技术对于处理那些文件尺寸可能超过内存限制的大型文件尤其有用。
```java
import org.xml.sax.XMLReader;
import org.xml.sax.InputSource;
import org.xml.sax.helpers.XMLReaderFactory;
import org.xml.sax.helpers.DefaultHandler;
public class StreamXMLProcessor {
public static void main(String[] args) throws Exception {
XMLReader reader = XMLReaderFactory.createXMLReader();
DefaultHandler handler = new MyCustomHandler();
reader.setContentHandler(handler);
reader.setErrorHandler(handler);
// 打开文件或流
InputStream is = new FileInputStream("large_file.xml");
InputSource inputSource = new InputSource(is);
reader.parse(inputSource);
is.close();
}
}
```
在上面的Java代码中,`XMLReader` 被用来设置自定义的处理器 `DefaultHandler`,然后开始解析文件。由于使用了流式技术,文件被逐步读取,因而可以处理非常大的文件。
### 4.1.2 分块解析策略
分块解析策略将大型文件分成小块进行处理,每处理完一块就释放掉,这样可以有效管理内存使用。在SAX中实现分块处理的关键是合理地定义何时开始和结束一个块,这通常依赖于XML文件的结构。
```java
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.InputSource;
public class ChunkedXMLProcessor extends DefaultHandler {
private static final int CHUNK_SIZE = 1024 * 1024; // 1MB chunk size
public void parseChunk(InputSource source) throws Exception {
XMLReader reader = XMLReaderFactory.createXMLReader();
reader.setContentHandler(this);
reader.setErrorHandler(this);
reader.parse(source);
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
// Process characters only if they belong to the current chunk
}
// other overrides...
}
```
上面的代码展示了如何创建一个简单的分块解析器。通过在处理器中添加逻辑来判断当前解析的文本是否属于当前分块,我们可以有效地处理整个文件而不必一次性加载整个文件到内存中。
## 4.2 结合其他技术的混合解析
SAX虽然强大,但在某些场景下可能需要与其他解析技术结合使用以达到最佳效果。例如,SAX可以与DOM结合来提供更灵活的访问方式。
### 4.2.1 SAX与DOM的对比和结合
SAX和DOM是两种常用的XML解析技术,它们各有优势和劣势。SAX是一种基于事件的解析模型,它适用于读取大型文件;而DOM则将整个文档加载到内存中,适合于需要随机访问文档的场合。
结合SAX和DOM的优点,开发者可以在使用SAX进行初步的流式读取和处理时,对于某些需要随机访问的部分使用DOM加载到内存。这样结合使用,可以在保证解析效率的同时,也提供了对文档的灵活访问。
### 4.2.2 SAX在Web服务中的应用
在Web服务中,经常需要将XML格式的数据作为服务间的通信语言。SAX的高效处理能力使其成为处理这类数据的理想选择。在Web服务中使用SAX进行XML解析,可以加快请求的处理速度,从而提高整个服务的响应性能。
```java
import org.xml.sax.XMLReader;
import org.xml.sax.InputSource;
import org.xml.sax.helpers.XMLReaderFactory;
public class WebServiceXMLParser {
public void parseRequest(InputSource request) throws Exception {
XMLReader reader = XMLReaderFactory.createXMLReader();
// 定义内容处理器
Handler handler = new MyRequestHandler();
reader.setContentHandler(handler);
reader.setErrorHandler(handler);
// 开始解析请求
reader.parse(request);
}
}
```
在Web服务的上下文中,通过使用SAX解析器,可以在接收到XML格式的请求后立即开始处理,而无需等待整个请求完整加载,这可以显著提升服务的处理效率。
## 4.3 实际案例分析
### 4.3.1 行业案例研究
在一些行业应用中,SAX解析器处理的效率优势明显。例如,在金融行业,需要处理大量的交易数据,这些数据通常以XML格式传输。使用SAX可以在数据到达时即时进行处理,这对于减少延迟和提高处理速度至关重要。
### 4.3.2 解析器在数据交换中的作用
在数据交换场景中,需要处理多种不同来源的数据。SAX可以作为数据交换中的一种基础工具,因为它能够快速地读取和处理结构化数据,这使得它在各种数据集成解决方案中都是一个重要的组成部分。
例如,在构建企业服务总线(Enterprise Service Bus, ESB)时,需要实时地处理来自不同系统的XML消息。SAX可以在ESB中充当消息处理和路由的引擎,以确保消息能够快速高效地传递。
| 优点 | 缺点 |
|------------|----------------|
| 高效的内存使用 | 缺乏对整个文档结构的随机访问 |
| 流式处理能力 | 需要更多的代码来处理XML的结构 |
| 处理大型文档的能力 | 复杂的错误处理和调试过程 |
通过实际案例分析,可以发现SAX在处理大量结构化数据和实时数据处理场景中的优势。同时,也可以根据实际需求将SAX与其他解析技术结合,以达到最佳的处理效果。
# 5. SAX解析器的高级特性和扩展
## 5.1 高级事件处理
### 5.1.1 事件聚合与预处理
在处理复杂的XML文档时,单个事件往往不足以提供足够的上下文信息。事件聚合是指将多个相关的事件合并处理,以获得更完整的数据视图。通过预处理,开发者可以聚合诸如开始标签和结束标签这样的事件,以更有效地构建文档模型或执行特定的业务逻辑。
```java
// 示例:聚合事件
class AggregateContentHandler extends DefaultHandler {
private StringBuilder currentElementValue = new StringBuilder();
private List<String> collectedData = new ArrayList<>();
public void startElement(String uri, String localName, String qName, Attributes attributes) {
if (qName.equals("dataElement")) {
currentElementValue.setLength(0); // 清空StringBuilder,开始收集新元素数据
}
}
public void characters(char[] ch, int start, int length) {
currentElementValue.append(ch, start, length);
}
public void endElement(String uri, String localName, String qName) {
if (qName.equals("dataElement")) {
collectedData.add(currentElementValue.toString());
}
}
}
```
在上述代码中,当遇到`dataElement`开始标签时,我们清空`StringBuilder`以准备收集数据,然后在字符事件中将数据追加到`StringBuilder`。当遇到`dataElement`结束标签时,我们把收集到的数据添加到`collectedData`列表中。
### 5.1.2 命名空间的处理
XML命名空间是区分元素或属性名称的机制,它在具有大量元素和属性的XML文档中显得尤为重要。SAX解析器允许开发者在解析XML时识别和处理命名空间。
```java
// 示例:处理命名空间
class NamespaceHandler extends DefaultHandler {
public void startElement(String uri, String localName, String qName, Attributes attributes) {
if (qName.equals("prefix:localElement")) {
// 当元素的qName包含命名空间前缀时,uri将不为空
String elementNamespaceURI = uri;
// 其他处理逻辑...
}
}
}
```
在SAX中,如果元素使用了命名空间前缀,`uri`参数将包含与该前缀关联的命名空间URI。开发者可以根据此信息处理命名空间冲突或正确地引用元素。
## 5.2 自定义解析行为
### 5.2.1 创建自定义的ContentHandler
在SAX解析器中,开发者可以通过扩展`ContentHandler`接口来创建自定义的解析行为。自定义的`ContentHandler`可以精确地控制解析过程中的每个事件,以满足特定的业务需求。
```java
// 示例:自定义ContentHandler
class CustomContentHandler extends DefaultHandler {
private boolean inInterestingElement = false;
public void startElement(String uri, String localName, String qName, Attributes attributes) {
if (qName.equals("interestingElement")) {
inInterestingElement = true;
// 开始处理感兴趣的元素
}
}
public void endElement(String uri, String localName, String qName) {
if (inInterestingElement && qName.equals("interestingElement")) {
inInterestingElement = false;
// 结束处理感兴趣的元素
}
}
public void characters(char[] ch, int start, int length) {
if (inInterestingElement) {
String data = new String(ch, start, length).trim();
// 处理感兴趣的元素内的文本内容
}
}
}
```
在上述自定义`ContentHandler`中,我们添加了对感兴趣的元素的处理逻辑。当解析器遇到这样的元素时,它将执行特定的操作,例如收集或处理元素内的数据。
### 5.2.2 事件监听器的深入定制
SAX解析模型允许开发者定义事件监听器来处理特定的XML解析事件。这些监听器可以根据需要被插入解析管道中,以便在特定事件发生时执行回调。
```java
// 示例:自定义事件监听器
class MyEventListener implements EntityResolver, DTDHandler, ErrorHandler {
public InputSource resolveEntity(String publicId, String systemId) {
// 自定义实体解析逻辑
return null;
}
public void notationDecl(String name, String publicId, String systemId) {
// 处理符号声明事件
}
public void error(SAXParseException spe) {
// 处理解析错误
}
}
```
通过实现`EntityResolver`、`DTDHandler`和`ErrorHandler`接口,开发者可以对XML文档的解析过程进行更细致的控制,包括实体解析、符号声明处理,以及错误处理。
## 5.3 SAX解析器的未来发展
### 5.3.1 新兴XML技术与SAX的关系
随着XML技术的发展,许多新兴技术如JSON、YAML等得到了广泛的应用。尽管SAX是针对XML设计的,但其事件驱动模型对于处理其他标记语言同样具有启发性。一些库已经开始支持类似SAX的解析器来处理这些新格式。
### 5.3.2 社区和标准对SAX的影响
SAX解析器作为XML解析的基础构件之一,一直受到社区和标准组织的支持。社区通过不断提供各种扩展和优化,使得SAX能够适应新的需求和挑战。而标准组织在发布新的XML标准时,也会考虑与现有SAX解析器的兼容性。
SAX解析器的高级特性和扩展为XML处理提供了更加灵活和强大的机制。通过高级事件处理、自定义解析行为以及对新兴XML技术的适应,SAX解析器依旧在复杂的XML数据处理场景中发挥着重要作用。社区的持续支持和标准组织的合理引导,共同保证了SAX解析器在XML解析领域的未来地位。
# 6. 总结与展望
在前面的章节中,我们深入探讨了SAX解析器的基础知识、工作原理、实践技巧以及它在实际项目中的应用,并对其高级特性和扩展进行了分析。接下来,我们将对SAX解析器的优劣进行总结,并展望XML解析技术的未来。
## 6.1 SAX解析器的优劣总结
### 6.1.1 SAX的优势与局限性
**优势**:
- **内存效率**:SAX采用事件驱动模型,不需要加载整个XML文档到内存中,特别适合解析大型文件。
- **速度**:由于其流式处理方式,SAX解析速度通常比DOM快。
- **灵活性**:开发者可以通过实现Handler接口来控制解析过程,自定义解析行为。
- **多线程支持**:由于其非阻塞的特性,SAX解析可以在多线程环境中更容易地并行处理。
**局限性**:
- **编程复杂度**:需要编写更多的代码来处理事件回调,对于初学者来说可能不够直观。
- **错误恢复困难**:错误处理较为困难,一旦发生错误,往往需要从头开始或回溯到错误点。
- **API不直观**:相比其他解析技术,SAX的API可能显得不那么直观易用。
- **无回溯能力**:SAX解析器是单向的,一旦解析过去就不能回头,这可能限制了某些需求的实现。
### 6.1.2 SAX与其他解析技术的比较
- **与DOM解析的比较**:DOM在处理小型XML文档时具有优势,因为它提供了完整的文档树视图,方便随机访问和修改。SAX则更适合于只需要遍历一次的大文件解析。
- **与StAX解析的比较**:StAX解析器(即XML Pull Parser)提供了类似于SAX的流式解析,但是它是基于拉取模型的,允许开发者控制读取速度,这为某些复杂的解析场景提供了更好的控制。
- **与XPath解析的比较**:XPath解析器允许开发者使用路径表达式直接查询XML文档,而无需完整解析文档。这为特定查询操作提供了便利,但SAX更适合于全面的数据处理。
## 6.2 对XML解析的未来展望
### 6.2.1 新兴技术趋势预测
随着数据量的日益增长和实时处理需求的提升,XML解析技术也面临着新的挑战和机遇:
- **云原生技术**:解析器需要适应云环境,能够高效地处理分布式存储的XML数据。
- **大数据技术**:结合大数据技术,如Hadoop或Spark,进行大规模XML数据的分布式处理。
- **实时处理**:随着实时数据处理需求的增加,解析器可能需要集成流处理框架,以支持更快的响应速度。
### 6.2.2 XML在数据处理中的未来地位
尽管JSON在Web API和轻量级数据交换中占有一席之地,XML在某些行业和应用中仍然是不可或缺的数据格式:
- **企业级应用**:在金融、医疗和政府等领域,XML因其严格的数据定义和良好的数据封装能力,仍然作为数据交换的标准格式。
- **复杂的文档处理**:XML在处理复杂和结构化程度高的文档方面具有优势,例如,法律文件、学术论文和技术文档。
- **标准化与集成**:XML作为标准化技术的基础,在企业系统集成和跨平台数据交换方面发挥着关键作用。
随着技术的不断发展,XML和其解析技术SAX仍将在数据处理领域中占有一席之地,但其使用方式和相关工具可能需要适应新的技术和架构需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 库 xml.sax.saxutils,提供了一系列全面的指南,帮助读者掌握 XML SAX(简单 API for XML)及其辅助工具。从入门基础到高级技巧,专栏涵盖了构建高效 XML 解析器、自定义事件处理类、优化解析性能、处理大型 XML 和使用多线程提高性能等各个方面。此外,还提供了与 Python 3 的集成、数据绑定以及应对 XML 文档类型定义 (DTD) 的策略。通过深入的代码示例和实战演练,本专栏旨在帮助读者提升 XML 处理效率,并为构建复杂的 XML 解析解决方案提供宝贵的见解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【交互特征的影响】:分类问题中的深入探讨,如何正确应用交互特征

# 1. 交互特征在分类问题中的重要性
在当今的机器学习领域,分类问题一直占据着核心地位。理解并有效利用数据中的交互特征对于提高分类模型的性能至关重要。本章将介绍交互特征在分类问题中的基础重要性,以及为什么它们在现代数据科学中变得越来越不可或缺。
## 1.1 交互特征在模型性能中的作用
交互特征能够捕捉到数据中的非线性关系,这对于模型理解和预测复杂模式至关重要。例如
【特征选择工具箱】:R语言中的特征选择库全面解析

# 1. 特征选择在机器学习中的重要性
在机器学习和数据分析的实践中,数据集往往包含大量的特征,而这些特征对于最终模型的性能有着直接的影响。特征选择就是从原始特征中挑选出最有用的特征,以提升模型的预测能力和可解释性,同时减少计算资源的消耗。特征选择不仅能够帮助我
有限数据下的训练集构建:6大实战技巧

# 1. 训练集构建的理论基础
## 训练集构建的重要性
在机器学习和数据分析中,训练集的构建是模型开发的关键阶段之一。一个质量高的训练集,可以使得机器学习模型更加准确地学习数据的内在规律,从而提高其泛化能力。正确的训练集构建方法,能有效地提取有用信息,并且降低过拟合和欠拟合的风险。
## 基本概念介绍
训练集的构建涉及到几个核心概念,包括数据集、特征、标签等。数据集是指一组数据的集合;特征是数据
【时间序列分析】:如何在金融数据中提取关键特征以提升预测准确性

# 1. 时间序列分析基础
在数据分析和金融预测中,时间序列分析是一种关键的工具。时间序列是按时间顺序排列的数据点,可以反映出某
【特征工程稀缺技巧】:标签平滑与标签编码的比较及选择指南
# 1. 特征工程简介
## 1.1 特征工程的基本概念
特征工程是机器学习中一个核心的步骤,它涉及从原始数据中选取、构造或转换出有助于模型学习的特征。优秀的特征工程能够显著提升模型性能,降低过拟合风险,并有助于在有限的数据集上提炼出有意义的信号。
## 1.2 特征工程的重要性
在数据驱动的机器学习项目中,特征工程的重要性仅次于数据收集。数据预处理、特征选择、特征转换等环节都直接影响模型训练的效率和效果。特征工程通过提高特征与目标变量的关联性来提升模型的预测准确性。
## 1.3 特征工程的工作流程
特征工程通常包括以下步骤:
- 数据探索与分析,理解数据的分布和特征间的关系。
- 特
p值在机器学习中的角色:理论与实践的结合

# 1. p值在统计假设检验中的作用
## 1.1 统计假设检验简介
统计假设检验是数据分析中的核心概念之一,旨在通过观察数据来评估关于总体参数的假设是否成立。在假设检验中,p值扮演着决定性的角色。p值是指在原
【PCA算法优化】:减少计算复杂度,提升处理速度的关键技术

# 1. PCA算法简介及原理
## 1.1 PCA算法定义
主成分分析(PCA)是一种数学技术,它使用正交变换来将一组可能相关的变量转换成一组线性不相关的变量,这些新变量被称为主成分。
## 1.2 应用场景概述
PCA广泛应用于图像处理、降维、模式识别和数据压缩等领域。它通过减少数据的维度,帮助去除冗余信息,同时尽可能保
自然语言处理中的独热编码:应用技巧与优化方法
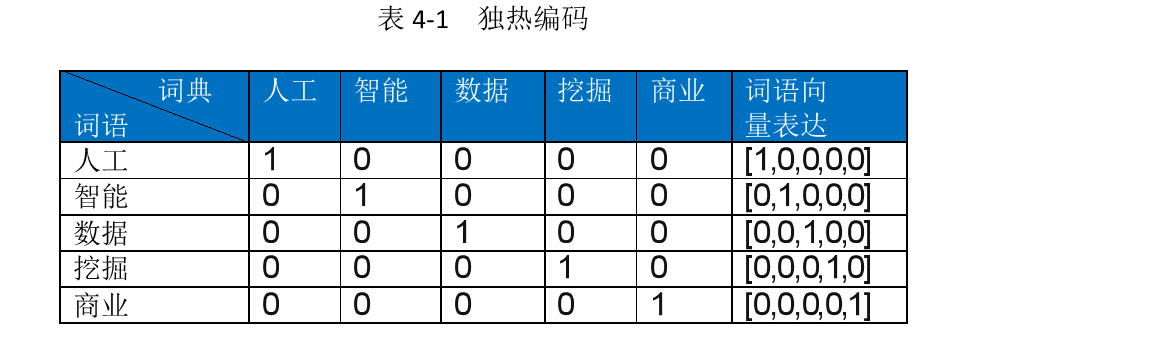
# 1. 自然语言处理与独热编码概述
自然语言处理(NLP)是计算机科学与人工智能领域中的一个关键分支,它让计算机能够理解、解释和操作人类语言。为了将自然语言数据有效转换为机器可处理的形式,独热编码(One-Hot Encoding)成为一种广泛应用的技术。
## 1.1 NLP中的数据表示
在NLP中,数据通常是以文本形式出现的。为了将这些文本数据转换为适合机器学习模型的格式,我们需要将单词、短语或句子等元
【复杂数据的置信区间工具】:计算与解读的实用技巧
# 1. 置信区间的概念和意义
置信区间是统计学中一个核心概念,它代表着在一定置信水平下,参数可能存在的区间范围。它是估计总体参数的一种方式,通过样本来推断总体,从而允许在统计推断中存在一定的不确定性。理解置信区间的概念和意义,可以帮助我们更好地进行数据解释、预测和决策,从而在科研、市场调研、实验分析等多个领域发挥作用。在本章中,我们将深入探讨置信区间的定义、其在现实世界中的重要性以及如何合理地解释置信区间。我们将逐步揭开这个统计学概念的神秘面纱,为后续章节中具体计算方法和实际应用打下坚实的理论基础。
# 2. 置信区间的计算方法
## 2.1 置信区间的理论基础
### 2.1.1
大样本理论在假设检验中的应用:中心极限定理的力量与实践

# 1. 中心极限定理的理论基础
## 1.1 概率论的开篇
概率论是数学的一个分支,它研究随机事件及其发生的可能性。中心极限定理是概率论中最重要的定理之一,它描述了在一定条件下,大量独立随机变量之和(或平均值)的分布趋向于正态分布的性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )