XML解析不再难:利用xml SAX处理复杂结构的技巧
发布时间: 2024-10-05 08:46:07 阅读量: 11 订阅数: 15 
# 1. XML和SAX解析器简介
## XML简介
XML(eXtensible Markup Language)是一种标记语言,用于存储和传输数据。其设计目标是简单性、可读性和通用性,使其可以使用在Web以及任何需要交换信息的应用程序中。XML以文本形式存储数据,它与HTML不同,不是用来显示数据的,而是用来传输数据,为数据提供结构信息。
## SAX解析器简介
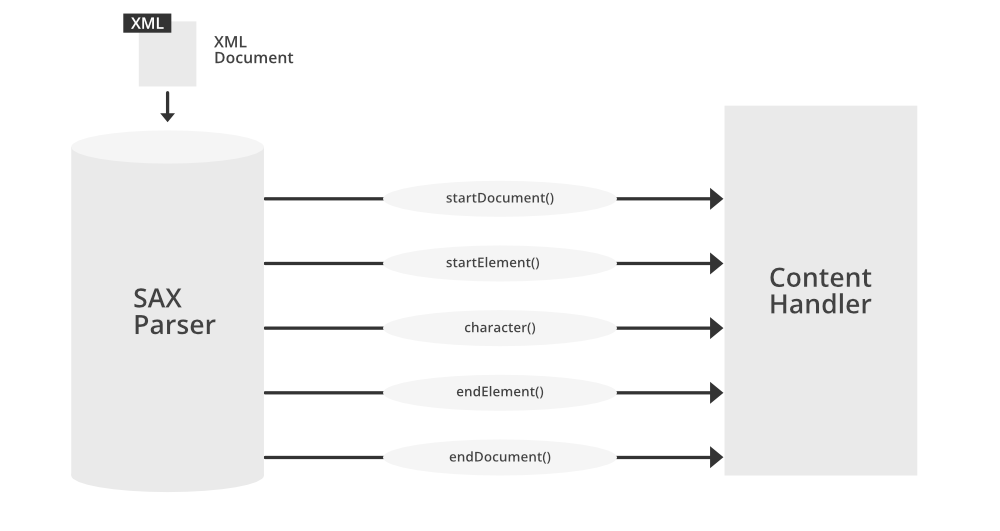
SAX(Simple API for XML)解析器是一种基于事件的解析方法,它在解析XML文件时会触发一系列事件,如开始元素、结束元素、字符数据等。开发者可以创建事件处理器,以响应这些事件。与DOM(Document Object Model)解析器不同,SAX不需要将整个XML文件加载到内存中,因而特别适合处理大型XML文件。
## SAX的优势
SAX解析器的主要优势在于它的高效性和内存使用上的经济性。由于SAX是一种流式解析器,它在解析XML文件时逐个读取文档中的元素,这就意味着对于大型文件,SAX能够节省大量内存资源。此外,SAX的解析速度快,特别适合于只需要一次读取数据的应用场景。
# 2. SAX解析器的工作原理和优势
### SAX的工作原理
#### 事件驱动模型解析
SAX(Simple API for XML)解析器是一种基于事件驱动模型的解析器,它在解析XML文档时不需要将整个文档加载到内存中。SAX的工作原理是通过读取XML文件中的内容,并触发一系列预定义的事件,这些事件随后被事件处理器(通常是一个实现了特定接口的对象)所捕获和处理。每个事件代表了XML文档中的一个结构元素,例如开始标签、结束标签和文本内容等。
当SAX解析器在读取XML文档时,它会创建一系列的事件对象,这些对象代表了文档中的结构信息。事件处理器根据这些事件对象提供的信息来执行相应的逻辑处理。因此,SAX解析器是被设计为“边读边解析”,处理流中的数据,而不需要等待整个文档解析完成。
下面是一个简单的例子,演示了SAX解析器如何处理一个简单的XML文档:
```java
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.*;
public class SaxDemo {
public static void main(String[] args) {
SAXParserFactory factory = SAXParserFactory.newInstance();
try {
SAXParser saxParser = factory.newSAXParser();
saxParser.parse("example.xml", new MyHandler());
} catch (Exception e) {
e.printStackTrace();
}
}
}
class MyHandler extends DefaultHandler {
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println("Start element :" + qName);
}
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println("End element :" + qName);
}
public void characters(char ch[], int start, int length) throws SAXException {
System.out.println("Characters :" + new String(ch, start, length));
}
}
```
在这个例子中,`MyHandler`类继承自`DefaultHandler`,重写了`startElement`、`endElement`和`characters`方法来分别处理XML文档的开始标签、结束标签和文本内容事件。当解析器读取到对应事件时,就会调用相应的方法。
#### 解析过程的内部机制
SAX解析器在内部维护了一个事件队列。在解析XML的过程中,解析器会逐个读取并分析XML文档的节点。每当遇到一个新的节点时,解析器就会生成一个事件,并将事件对象放入队列中。事件处理器会在事件队列中取得下一个事件,并根据事件类型进行相应的处理。
解析器的内部机制可以分为几个步骤:
1. **初始化解析器**:创建`SAXParser`对象,并设置合适的属性。
2. **开始解析**:调用`parse`方法开始解析XML文档。
3. **事件触发**:当解析器读取到XML文档中的节点时,会触发相应的事件。
4. **事件处理**:事件处理器根据触发的事件类型来处理数据,例如读取标签内容,处理属性等。
5. **完成解析**:当XML文档中的所有节点都处理完毕,事件处理结束,解析过程完成。
解析过程中,解析器会使用词法分析器(Tokenizer)来逐个分析XML文档内容。词法分析器会识别出不同类型的节点,如开始标签、结束标签、文本内容等,并将这些信息封装成事件对象。
解析器在内部通过状态机的方式工作,每个事件的触发都会改变解析器的状态。例如,当解析器处于“解析元素”状态时,遇到结束标签事件,解析器将状态切换为“解析完成”。
### SAX与DOM解析器的对比
#### 性能对比
在性能方面,SAX解析器通常优于DOM(Document Object Model)解析器。SAX解析器采用的是基于流的处理方式,它不需要构建整个文档的树形结构,因此对内存的需求较低。相反,DOM解析器需要构建完整的文档对象模型,这意味着需要将整个XML文档加载到内存中,消耗更多的内存资源。
SAX解析器在处理大型XML文件时,由于其事件驱动的特性,能够逐步处理文档,允许应用程序边读边处理数据,这对于处理大型文件尤其有利。而DOM解析器则在处理大型文件时可能会遇到内存不足的问题。
#### 使用场景分析
选择使用SAX或DOM解析器取决于具体的应用场景:
- **SAX解析器**:适用于大型XML文件的快速处理,或者当只需要读取XML文件的一部分数据时。因为SAX是边读边处理,不需要等待整个文件处理完成,所以特别适合流式处理或者事件驱动的编程模型。
- **DOM解析器**:适用于需要频繁访问和修改XML文件内容的场景。DOM解析器会将XML文档完整地加载到内存中,并构建为树状结构,允许用户方便地访问任何部分的文档结构。
### SAX解析器的优势
#### 内存效率
SAX解析器的主要优势之一是内存效率。由于SAX不需要加载整个XML文档到内存,因此在处理大型或复杂的XML文件时,它的内存使用量通常远低于DOM解析器。SAX适用于那些数据量大、实时性要求高的场景,比如网络爬虫、大规模数据导入等。
#### 处理大型XML文件的能力
处理大型XML文件时,SAX的优势尤为明显。在内存资源有限的情况下,SAX能够有效地进行流式处理,使得应用程序能够处理那些对内存要求很高的文件。SAX的另一个优势是,它能够立即处理解析过程中遇到的数据,这对于需要即时响应的系统尤为重要。
此外,SAX解析器在遇到错误的XML格式时能够提供更好的错误处理和恢复能力,这是因为SAX在解析过程中逐步读取和处理数据,能够更快地识别和处理错误。
```mermaid
graph LR;
A[开始解析XML] --> B[创建SAXParser对象];
B --> C[调用parse方法];
C --> D{等待下一个事件};
D -->|遇到标签| E[触发startElement事件];
D -->|遇到结束标签| F[触发endElement事件];
D -->|遇到文本| G[触发characters事件];
E --> H[处理器处理开始标签];
F --> I[处理器处理结束标签];
G --> J[处理器处理文本内容];
H --> D;
I --> D;
J --> D;
D -->|解析结束| K[完成解析];
```
此流程图展示了SAX解析过程的基本逻辑。每个事件都由事件处理器处理,处理完毕后,解析器继续等待下一个事件。这种方式保证了解析过程对内存的需求保持在一个较低的水平,同时允许应用程序逐个处理事件,而不是等待整个文件解析完成。
总体而言,SAX解析器由于其高效的内存使用和流式处理能力,在处理大型XML文件时提供了显著的优势。这使得SAX成为许多需要处理大量数据的应用程序的首选解析技术。
# 3. 基础XML结构解析技巧
## 3.1 理解XML文档结构
XML(Extensible Markup Language)是一种标记语言,用于存储和传输数据。它与HTML(HyperText Markup Language)不同,HTML主要用于展示数据,而XML则专注于数据的描述。在解析XML文档时,首先需要了解其基本结构,这包括元素、标签、属性等。
### 3.1.1 元素和标签
在XML中,元素是构成文档的最基本单位,可以包含其他元素、文本内容、属性等。每个元素都由一对标签(tag)来标识,开始标签和结束标签通常以尖括号`< >`表示,开始标签内可以包含属性。
```xml
<elementName attribute1="value1" attribute2="value2">Content</elementName>
```
上述示例展示了一个包含属性的元素。`elementName`是元素名称,`attribute1`和`attribute2`是属性,它们都有对应的值`value1`和`value2`。
### 3.1.2 属性的处理
属性提供了元素的附加信息,它们总是出现在开始标签内,以`name="value"`的形式存在。一个元素可以有零个或多个属性,但同一个元素内不能有多个同名属性。
处理XML属性时,要确保属性值被正确地转义,以避免数据被错误解析。例如,属性值中不能包含未转义的`<`或`>`字符,因为它们会被解析器误认为是XML结构的一部分。
## 3.2 SAX事件处理基础
SAX解析器采用事件驱动模型来解析XML文档。当解析器在文档中遇到特定的节点时,它会触发一系列的事件,例如开始标签、结束标签和文本节点事件。这些事件会被应用程序捕获并处理。
### 3.2.1 开始标签和结束标签事件
开始标签事件和结束标签事件分别对应XML元素的开始和结束。这些事件通过`startElement`和`endElement`方法触发,应用程序可以通过这些方法获取元素名称和属性信息。
```java
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
// 处理开始标签事件
// uri: 命名空间URI
// localName: 不包含前缀的本地名称
// qName: 可能包含前缀的限定名
// attributes: 属性列表
}
public void endElement(String uri, Str
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 库 xml.sax.saxutils,提供了一系列全面的指南,帮助读者掌握 XML SAX(简单 API for XML)及其辅助工具。从入门基础到高级技巧,专栏涵盖了构建高效 XML 解析器、自定义事件处理类、优化解析性能、处理大型 XML 和使用多线程提高性能等各个方面。此外,还提供了与 Python 3 的集成、数据绑定以及应对 XML 文档类型定义 (DTD) 的策略。通过深入的代码示例和实战演练,本专栏旨在帮助读者提升 XML 处理效率,并为构建复杂的 XML 解析解决方案提供宝贵的见解。
专栏目录
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
C++性能调优:纯虚函数的影响与优化秘籍

# 1. C++性能调优概述
在当今软件开发领域,随着技术的发展和用户需求的日益提高,开发者对程序性能的要求也越来越严格。C++
【Java Lambda表达式与Optional类】:处理null值的最佳实践

# 1. Java Lambda表达式简介
Java Lambda表达式是Java 8引入的一个非常重要的特性,它使得Java语言拥有了函数式编程的能力。Lambda表达式可以看做是匿名函数的一种表达方式,它允许我们将行为作为参数传递给方法,或者作为值赋给变量。Lambda表达式的核心优势在于简化代码,提高开发效率和可读性。
让我们以一个简单的例子开始,来看La
C++模板编程中的虚函数挑战与应用策略

# 1. C++模板编程基础
在现代C++开发中,模板编程是构建灵活、可重用代码的关键技术之一。本章将探讨C++模板编程的基础知识,为理解后续章节中的复杂概念打下坚实的基础。
## 1.1 模板的基本概念
模板是C++中的泛型编程工具,它允许程序员编写与数据类型无关的代码。模板分为两种主要形式:函数模板和类模板。函数模板可以对不同数据类型执行相同的操作,而类模板则可以创建出具有通用行为的对象。例如:
```cp
【Go数组深入剖析】:编译器优化与数组内部表示揭秘
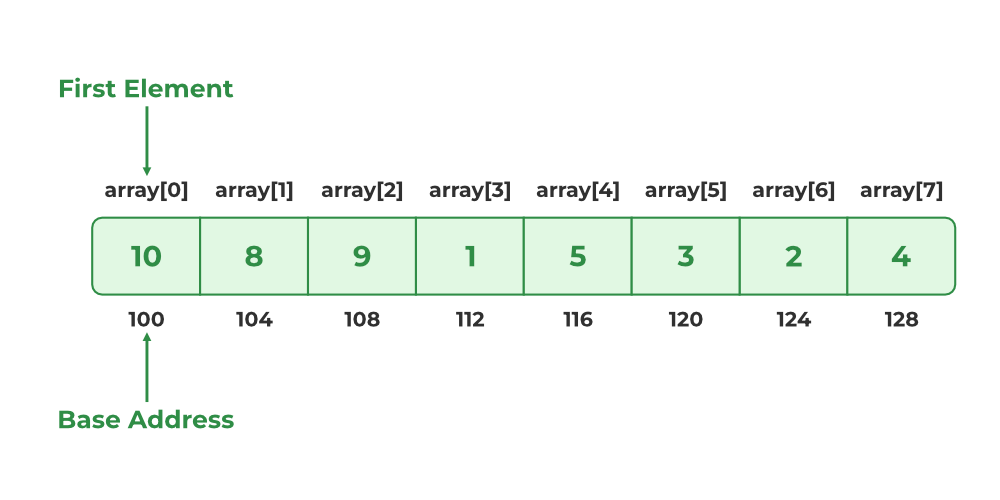
# 1. Go数组的基础概念和特性
## 1.1 Go数组的定义和声明
Go语言中的数组是一种数据结构,用于存储一系列的相同类型的数据。数组的长度是固定的,在声明时必须指定。Go的数组声明语法简单明了,形式如下:
```go
var arrayName [size]type
```
其中`arrayName`是数组的名称,`size`是数组的长度
Go模块生命周期管理:构建可持续演进的代码库
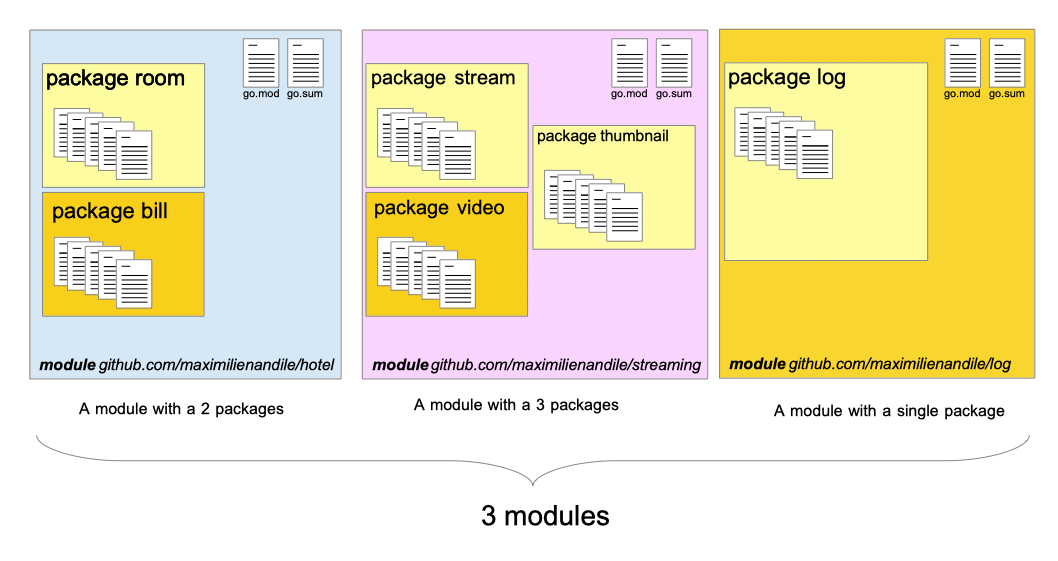
# 1. Go模块生命周期的理论基础
## 1.1 Go模块的定义及其重要性
Go模块是Go语言编写的代码和构建配置文件的集合,它为Go开发者提供了一种更加清晰和可管理的方式来组织项目。理解模块化的概念对于掌握Go语言项目管理至关重要,因为它涉及到版本控制、依赖管理、构建和部署等各个方面。
## 1.2 Go模块生命周期的各阶段
一个Go模块从创建开始,到最终发布,会经历初始化、依赖管理、构建与测试、升级与维护
C++多重继承与二义性:彻底避免的策略与实践指南

# 1. C++多重继承概念解析
C++作为一种支持面向对象编程的语言,允许程序员通过继承机制来复用代码。在这些继承机制中,多重继承(Multiple Inheritance)是C++特有的一种继承方式,指的是一个类同时继承自两个或两个以上的父类。多重继承使得一个类可以获取多个父类的属性和方法,从而提高代码复用率,但同时也带来了命名冲突和二义性的问题。
当我们讨论
Go语言错误记录与报告:日志记录的10大最佳方式
# 1. Go语言日志记录概述
在软件开发中,日志记录是一个不可或缺的组成部分,它帮助开发者理解程序运行状态,诊断问题,并进行后期分析。Go语言作为现代编程语言,内置了强大的日志记录支持,允许开发者通过简单易用的API记录关键信息。本文将探讨Go语言中日志记录的基础知识,为读者提供一个坚实的理解基础,以便更好地利用日志记录优化应用性能和排错。
## 1.1
C#扩展方法与方法组转换:委托关系的深入理解

# 1. C#扩展方法与方法组转换概述
## 1.1 概念介绍
扩展方法是C#语言中的一种特性,它允许开发者为现有类型添加新的方法,而无需修改类型的源代码或创建新的派生类型。这一特性极大地增强了C#的
【C#异步高并发系统设计】:在高并发中优化设计和实践策略
# 1. C#异步高并发系统概述
在当今IT领域,系统的响应速度与处理能力对用户体验至关重要。特别是在高并发场景下,系统设计和实现的优化能够显著提升性能。C#作为微软推出的一种面向对象、类型安全的编程语言,不仅在同步编程领域有着广泛的应用,更在异步编程与高并发处理方面展现出强大的能力。本章将概括性地介绍异步高并发系统的基本概念,为读者深入学习C#异步编程和高并发系统设计打下坚实的基础。
## 1.1 什么是高并发系统?
高并发系统是指在特定时间内能够处理大量并发请求的系统。这类系统广泛应用于大型网站、在线游戏、金融服务等领域。为了提高系统的吞吐量和响应速度,系统需要合理地设计并发模型和处理
【避免Java Stream API陷阱】:深入理解并纠正常见误解

# 1. Java Stream API概述
Java Stream API是Java 8引入的一个强大工具,它允许我们以声明式的方式处理数据集合。本章将为读者概述Stream API的基础知识,为理解后续章节打下基础。
## 1.1 什么是Stream API
Stream API提供了一种高效且易于理解的数据处理方式。利用Stream,我们可以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
1024大促
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )