【R语言探索性数据分析】:chinesemisc包在中文环境下的应用与策略
发布时间: 2024-11-06 21:45:21 阅读量: 17 订阅数: 25 

R语言数据分析案例:探索性数据分析(EDA)在房地产价格预测中的应用.pdf

# 1. R语言探索性数据分析简介
在数据分析领域,探索性数据分析(Exploratory Data Analysis,简称EDA)是理解数据本质和探索数据背后故事的基石。本章将为您介绍如何在R语言的环境中运用探索性数据分析的基本概念和技巧。R语言凭借其强大的统计分析功能和图形表现力,在学术界和业界广泛应用于数据分析。
## 1.1 探索性数据分析的定义与重要性
探索性数据分析是一种对数据集进行快速浏览、总结、可视化的过程,旨在发现数据的主要特征、异常值、数据趋势和模式。此步骤对于后续的模型建立和决策支持至关重要。
## 1.2 R语言在数据分析中的优势
R语言具备丰富的数据处理和可视化包,如ggplot2、dplyr、tidyr等,这使得它成为处理各种复杂数据集的理想工具。通过R,数据分析师能够快速实现数据的导入、清洗、转换、建模和可视化。
## 1.3 实际案例中的探索性数据分析步骤
1. **数据导入与初步探索**:确定数据来源,使用readr、haven等包导入数据。
2. **数据清洗与预处理**:通过dplyr包进行数据清洗,保证数据质量。
3. **统计描述与图形绘制**:使用summary函数进行数据统计描述,用ggplot2包进行可视化。
4. **异常值检测与数据变换**:分析异常值,运用适当的方法进行数据变换。
```r
# 示例代码:导入数据并进行描述性统计
library(readr)
library(ggplot2)
data <- read_csv("path_to_your_data.csv")
summary(data)
ggplot(data, aes(x=variable)) + geom_histogram()
```
通过本章的介绍,您将掌握R语言进行探索性数据分析的基本框架和关键步骤,为后续章节深入学习特定的数据分析工具和方法奠定基础。
# 2. chinesemisc包的基本使用
## 2.1 chinesemisc包的安装与加载
### 2.1.1 安装chinesemisc包的系统要求
在安装chinesemisc包之前,了解其系统要求是非常重要的。R语言的用户需要确保系统中安装了最新版本的R,通常为3.6.x或更高版本。此外,考虑到chinesemisc包涉及中文字符处理和数据可视化,建议操作系统支持UTF-8编码,以保证中文字符的正确显示。
此外,chinesemisc包在开发过程中可能会依赖其他辅助包。确保网络连接稳定,以便下载这些依赖包,也是系统要求的一部分。例如,在安装chinesemisc时,可能会需要依赖于如`jiebaR`、`ggplot2`等包。在安装前,可以使用以下R命令,检查系统是否满足要求:
```R
# 检查R版本是否满足最低要求
version[['version.string']]
# 检查已安装的包
installed.packages()
```
### 2.1.2 chinesemisc包的加载方法
成功安装chinesemisc包后,可以通过`library()`函数来加载它。加载时无需任何特定参数,但可以使用`requireNamespace()`函数预先检查该包是否已安装:
```R
# 检查chinesemisc包是否存在,并尝试加载它
if (requireNamespace("chinesemisc", quietly = TRUE)) {
library(chinesemisc)
} else {
install.packages("chinesemisc")
library(chinesemisc)
}
```
一旦包被成功加载,用户就可以访问chinesemisc中的函数和数据集来处理中文数据了。
## 2.2 chinesemisc包的核心功能介绍
### 2.2.1 中文字符处理
chinesemisc包提供了丰富的中文字符处理功能,使得在R环境中处理中文文本变得简单高效。这些功能包括但不限于:
- 字符串的编码转换(如GB2312、GBK、UTF-8等)
- 中文标点符号的清洗
- 中文空白字符的处理
例如,为了将字符串从GBK编码转换为UTF-8编码,可以使用以下代码:
```R
# 假定strGBK是一个GBK编码的字符串
strGBK <- "你好,世界!"
# 转换编码
strUTF8 <- iconv(strGBK, "GBK", "UTF-8")
# 输出转换后的字符串,应显示为正确的中文字符
print(strUTF8)
```
### 2.2.2 中文分词工具的集成
分词是中文文本处理的一个基础步骤,chinesemisc包集成了多个中文分词工具,如`jiebaR`,方便用户根据需求选择最合适的分词方法。分词功能的使用示例如下:
```R
# 加载chinesemisc包
library(chinesemisc)
# 创建分词器,这里以jieba分词为例
segmentor <- jiebaR::worker(byeseg = FALSE)
# 使用分词器分词
corpus <- segmentor$segment("我爱北京天安门")
print(corpus)
```
### 2.2.3 中文文本的预处理和清洗
在文本分析之前,通常需要对中文文本进行预处理和清洗。chinesemisc包为用户提供了一系列的预处理函数,如:
- 去除停用词(常用词、无意义词等)
- 词干提取(词根还原)
- 词性标注
例如,以下代码展示了如何去除中文文本中的常见停用词:
```R
# 示例文本
text <- "这是一个示例文本,用于展示如何在R中进行中文文本的预处理。"
# 加载chinesemisc包
library(chinesemisc)
# 获取预定义的停用词列表
stopwords <- chinesemisc::get_stopwords()
# 清洗文本,去除停用词
clean_text <- clean_text(text, stopwords = stopwords)
# 输出清洗后的文本
print(clean_text)
```
## 2.3 chinesemisc包的数据可视化
### 2.3.1 中文环境下的图形绘制
数据可视化是数据分析中的重要组成部分。chinesemisc包不仅支持基础图形的绘制,还提供了对中文字符绘制的支持,使得图形元素更加友好地展示中文信息。使用ggplot2包结合chinesemisc包,可以绘制包含中文的统计图形:
```R
# 加载必要的包
library(chinesemisc)
library(ggplot2)
# 使用ggplot绘制图形,并添加中文标签
ggplot(data = iris, aes(x = Species, y = Sepal.Length)) +
geom_boxplot() +
labs(title = "鸢尾花种类与其萼片长度关系图",
x = "种类",
y = "萼片长度(cm)") +
theme_minimal()
```
### 2.3.2 图形元素的中文化定制
对于更高级的图形定制,chinesemisc包也提供了相应的功能。用户可以自定义字体、调整图形元素大小,甚至添加中文注释和标签,以适应中文环境下的展示需求。例如,调整图表中的中文标签字体可以这样实现:
```R
# 绘制基本图形
p <- ggplot(data = mtcars, aes(x = wt, y = mpg)) +
geom_point() +
labs(title = "汽车重量与油耗的关系")
# 设置中文字体(需要根据系统实际情况调整字体路径)
p + theme(text = element_text(family = "SimSun"))
```
在本节中,我们探讨了chinesemisc包的安装与加载方法,核心功能的介绍,以及数据可视化方面的应用。通过安装chinesemisc包,用户可以轻松处理中文字符和进行中文文本分析。接下来的章节中,我们将深入介绍chinesemisc包在文本分析和数据可视化中的具体应用。
# 3. chinesemisc包在文本分析中的应用
在探索性数据分析中,文本数据往往是最为丰富但也是最复杂的来源之一。本章节将深入探讨如何利用chinesemisc包在文本分析中的应用,特别是在中文文本数据处理方面。我们将从中文文本数据的准备与导入开始,逐步深入到中文文本的基本统计分析,以及高级分析技术的运用。
## 3.1 中文文本数据的准备与导入
中文文本数据的准备与导入是文本分析的第一步,也是至关重要的一步。准备数据需要处理原始文本,将它们转化为可分析的格式,然后导入到R环境中进行后续的处理和分析。
### 3.1.1 导入本地和网络中文文本数据
在R中导入本地和网络中文文本数据可以通过多种方法实现。我们可以使用chinesemisc包中的函数来简化这一过程。
#### 代码块示例:
```R
# 安装并加载chinesemisc包
if (!require(chinesemisc)) {
install.packages("chinesemisc")
library(chinesemisc)
}
# 从本地文件导入数据
local_text <- readLines("path/to/local/file.txt", encoding = "UTF-8")
# 从网络上导入数据
url <- "***"
remote_text <- readLines(url, encoding
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 R 语言中 chinesemisc 数据包的全面使用。涵盖了 10 大应用技巧,从中文数据处理到统计建模和机器学习。专栏还提供了中文环境下的探索性数据分析、社交媒体分析、信息检索、地理信息数据分析等高级应用指南。通过深入浅出的讲解和丰富的案例,本专栏旨在帮助 R 语言用户充分掌握 chinesemisc 数据包,提升中文数据处理和分析能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
紧急揭秘!防止Canvas转换中透明区域变色的5大技巧

# 摘要
Canvas作为Web图形API,广泛应用于现代网页设计与交互中。本文从Canvas转换技术的基本概念入手,深入探讨了在渲染过程中透明区域变色的理论基础和实践解决方案。文章详细解析了透明度和颜色模型,渲染流程以及浏览器渲染差异,并针对性地提供了预防透明区域变色的技巧。通过对Canvas上下文优化
超越MFCC:BFCC在声学特征提取中的崛起

# 摘要
声学特征提取是语音和音频处理领域的核心,对于提升识别准确率和系统的鲁棒性至关重要。本文首先介绍了声学特征提取的原理及应用,着重探讨
Flutter自定义验证码输入框实战:提升用户体验的开发与优化

# 摘要
本文详细介绍了在Flutter框架中实现验证码输入框的设计与开发流程。首先,文章探讨了验证码输入框在移动应用中的基本实现,随后深入到前端设计理论,强调了用户体验的重
光盘刻录软件大PK:10个最佳工具,找到你的专属刻录伙伴
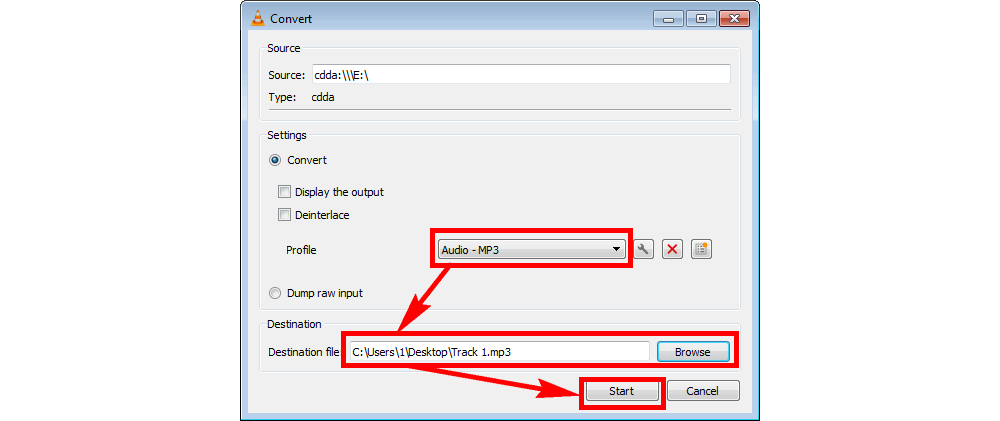
# 摘要
本文全面介绍了光盘刻录技术,从技术概述到具体软件选择标准,再到实战对比和进阶优化技巧,最终探讨了在不同应用场景下的应用以及未来发展趋势。在选择光盘刻录软件时,本文强调了功能性、用户体验、性能与稳定性的重要性。此外,本文还提供了光盘刻录的速度优化、数据安全保护及刻录后验证的方法,并探讨了在音频光盘制作、数据备份归档以及多媒体项目中的应用实例。最后,文章展望了光盘刻录技术的创
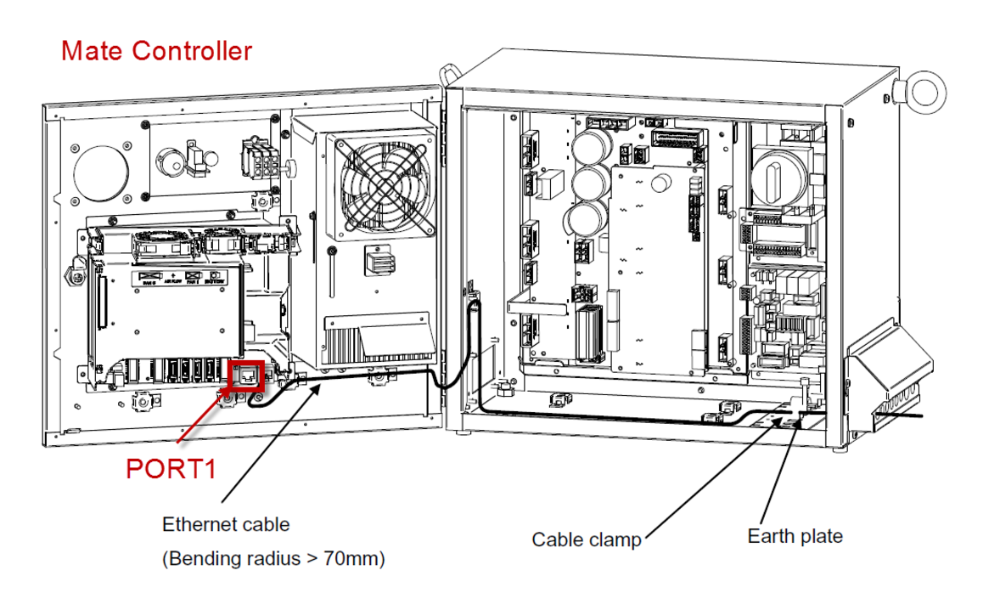
【FANUC机器人接线实战教程】:一步步教你完成Process IO接线的全过程
# 摘要
本文系统地介绍了FANUC机器人接线的基础知识、操作指南以及故障诊断与解决策略。首先,章节一和章节二深入讲解了Process IO接线原理,包括其优势、硬件组成、电气接线基础和信号类型。随后,在第三章中,提供了详细的接线操作指南,从准备工作到实际操作步骤,再到安全操作规程与测试,内容全面而细致。第四章则聚焦于故障诊断与解决,提供了一系列常见问题的分析、故障排查步骤与技巧,以及维护和预防措施
ENVI高光谱分析入门:3步掌握波谱识别的关键技巧

# 摘要
本文全面介绍了ENVI高光谱分析软件的基础操作和高级功能应用。第一章对ENVI软件进行了简介,第二章详细讲解了ENVI用户界面、数据导入预处理、图像显示与分析基础。第三章讨论了波谱识别的关键步骤,包括波谱特征提取、监督与非监督分类以及分类结果的评估与优化。第四章探讨了高级波谱分析技术、大数据环境下的高光谱处理以及ENVI脚本
ISA88.01批量控制核心指南:掌握制造业自动化控制的7大关键点

# 摘要
本文详细介绍了ISA88.01批量控制标准的理论基础和实际应用。首先,概述了ISA88.01标准的结构与组件,包括基本架构、核心组件如过程模块(PM)、单元模块(UM)
【均匀线阵方向图优化手册】:提升天线性能的15个实战技巧
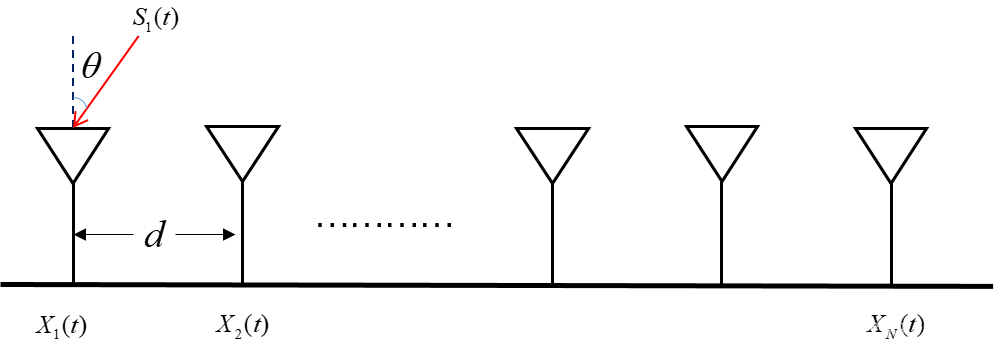
# 摘要
本文系统地介绍了均匀线阵天线的基础知识、方向图优化理论基础、优化实践技巧、系统集成与测试流程,以及创新应用。文章首先概述了均匀线阵天线的基本概念和方向图的重要性,然后
STM32F407 USB通信全解:USB设备开发与调试的捷径

# 摘要
本论文深入探讨了STM32F407微控制器在USB通信领域的应用,涵盖了从基础理论到高级应用的全方位知识体系。文章首先对USB通信协议进行了详细解析,并针对STM32F407的USB硬件接口特性进行了介绍。随后,详细阐述了USB设备固件开发流程和数据流管理,以及USB通信接口编程的具体实现。进一步地,针对USB调试技术和故障诊断、性能优化进行了系统性分析。在高级应用部分,重点介绍了USB主
车载网络诊断新趋势:SAE-J1939-73在现代汽车中的应用
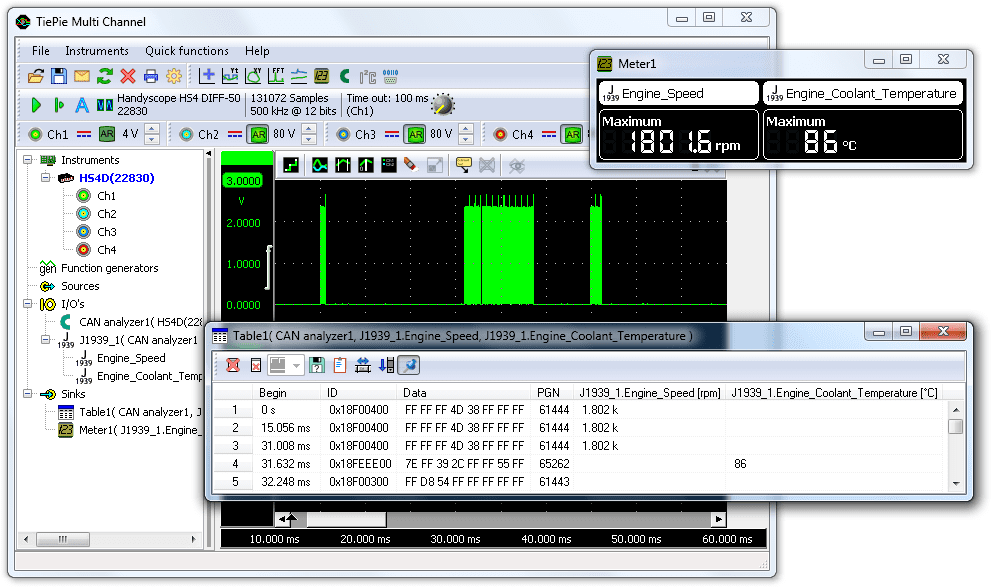
# 摘要
随着汽车电子技术的发展,车载网络诊断技术变得日益重要。本文首先概述了车载网络技术的演进和SAE-J1939标准及其子标准SAE-J1939-73的角色。接着深入探讨了SAE-J1939-73标准的理论基础,包括数据链路层扩展、数据结构、传输机制及诊断功能。文章分析了SAE-J1939-73在现代汽车诊断中的实际应用,车载网络诊断工具和设备,以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )