使用Python的Pandas库读取Excel数据
发布时间: 2023-12-08 14:11:52 阅读量: 116 订阅数: 35 

python pandas 读取excel数据
# 1. 第一章 简介
## 1.1 什么是Pandas库
Pandas是一个强大的数据处理和分析工具,基于Python语言开发而成。它提供了高效的数据结构,如DataFrame和Series,以及丰富的数据处理和分析功能,可以帮助我们轻松地读取、处理、分析和可视化各种类型的数据。
## 1.2 Python中读取Excel数据的需求
在数据分析和处理的过程中,我们经常需要读取Excel文件中的数据。传统的方法是使用Python的内置库csv进行读取,但是这种方法对于复杂的Excel文件或者需要进行数据处理的情况效果较差。
## 1.3 为什么选择Pandas库
Pandas库提供了强大的功能来处理Excel数据,它能够高效地读取Excel文件,并提供了丰富的数据处理和分析方法。与传统的方法相比,使用Pandas库可以更方便地处理复杂的数据结构,节省时间和精力。
在接下来的章节中,我们将介绍如何安装和设置Pandas库,以及如何使用Pandas库来读取、处理和分析Excel数据。同时,我们还会介绍Pandas库的优势,与其他Python库进行对比,并提供实践示例和案例分析,以帮助读者更好地理解和使用Pandas库。
# 2. 安装和设置
在本节中,我们将介绍如何安装Python以及Pandas库,并设置好工作环境,以便后续能够顺利读取和处理Excel数据。
### 2.1 安装Python和Pandas库
首先,我们需要确保已经在计算机上安装了Python。可以通过[Python官方网站](https://www.python.org/downloads/)下载最新版本的Python,并根据提示完成安装过程。
安装完成后,我们可以通过命令行来安装Pandas库,只需要在命令行中输入以下命令即可:
```bash
pip install pandas
```
### 2.2 导入Pandas库
安装完成后,我们需要在Python代码中导入Pandas库,以便后续能够使用Pandas的各种功能。在Python文件中,可以使用以下代码导入Pandas库:
```python
import pandas as pd
```
### 2.3 设置工作环境
在开始读取Excel数据之前,我们需要设置好工作环境,确保能够顺利找到并读取Excel文件。在Python中,可以使用以下代码设置工作环境:
```python
# 设置Excel文件路径
excel_file_path = "path_to_your_excel_file.xlsx"
# 切换工作目录到Excel文件所在的目录
import os
os.chdir(os.path.dirname(excel_file_path))
```
以上是安装Python和Pandas库,并设置工作环境的基本步骤,接下来将会介绍如何使用Pandas库来读取Excel数据。
# 3. 读取Excel数据
在进行数据分析和处理之前,我们首先需要将Excel中的数据读取到Python中。使用Pandas库可以轻松地实现这一功能。
#### 3.1 打开Excel文件
要读取Excel文件,首先需要打开它。可以使用Pandas库提供的`read_excel()`函数来打开一个Excel文件。以下是一个打开Excel文件的示例代码:
```python
import pandas as pd
# 使用文件路径打开Excel文件
df = pd.read_excel('path/to/your/excel/file.xlsx')
# 或者使用URL打开Excel文件
df = pd.read_excel('https://example.com/your/excel/file.xlsx')
# 或者使用指定的sheet_name打开Excel文件
df = pd.read_excel('path/to/your/excel/file.xlsx', sheet_name='Sheet1')
```
上面的代码中,我们使用`read_excel()`函数打开了一个Excel文件,并将数据存储在一个名为`df`的DataFrame对象中。可以通过传递文件路径、URL或指定的工作表名称来打开Excel文件。
#### 3.2 读取整个工作表
一旦打开了Excel文件,接下来我们可以读取整个工作表中的数据。可以使用`df.head()`语句来查看前几行的数据,或使用`df.tail()`语句来查看后几行的数据。以下是一个示例代码:
```python
# 查看前5行数据
print(df.head())
# 查看后5行数据
print(df.tail())
```
上面的代码中,我们使用了`head()`函数和`tail()`函数来查看数据的前5行和后5行。
#### 3.3 选择特定的工作表
如果Excel文件中包含多个工作表,我们需要选择特定的工作表进行读取。可以通过在`read_excel()`函数中传递`sheet_name`参数来选择工作表。以下是一个示例代码:
```python
# 读取名为"Sheet2"的工作表
df = pd.read_excel('path/to/your/excel/file.xlsx', sheet_name='Sheet2')
```
上面的代码中,我们通过将`sheet_name`参数设置为`'Sheet2'`来选择名为"Sheet2"的工作表进行读取。
#### 3.4 读取特定的行和列
在某些情况下,我们可能只需要读取Excel工作表中的特定行或列的数据。可以使用`pd.DataFrame`对象的切片操作来实现这一功能。以下是一个示例代码:
```python
# 读取第2行至第5行的数据
rows = df[1:5]
# 读取第2列和第3列的数据
columns = df[['Column2', 'Column3']]
```
上面的代码中,我们使用切片操作`[1:5]`来选择第2行至第5行的数据,并使用`[['Column2', 'Column3']]`来选择第2列和第3列的数据。
#### 3.5 处理合并单元格
在Excel中,有时会使用合并单元格的方式来显示更复杂的数据结构。在读取这样的Excel文件时,需要注意处理合并单元格的情况。使用Pandas库的`read_excel()`函数可以自动处理合并单元格的情况。
以上就是使用Pandas库读取Excel数据的基本步骤和方法。通过这些方法,我们可以将Excel中的数据导入到Python中,为后续的数据处理和分析做准备。下一章节将介绍如何对读取的Excel数据进行处理和清洗。
# 4. 数据处理和清洗
在数据处理和清洗这一部分,我们将介绍如何使用Pandas库对Excel中的数据进行清洗和处理。主要包括处理缺失值、数据类型转换、数据筛选和过滤、列名和索引处理、数据排序和重排等内容。
### 4.1 处理缺失值
缺失值是指数据表中的空白单元格或者NA(Not Available)值,对于这些缺失值的处理在数据分析中尤为重要。Pandas提供了多种方法来处理缺失值,比如删除含有缺失值的行或列、填充缺失值等。下面是一些常用的处理方法示例:
#### 删除含有缺失值的行或列:
```python
# 删除含有缺失值的行
new_df = df.dropna(axis=0)
# 删除含有缺失值的列
new_df = df.dropna(axis=1)
```
#### 填充缺失值:
```python
# 使用指定值填充缺失值
new_df = df.fillna(value=0)
# 使用前一行的数值填充缺失值
new_df = df.fillna(method='ffill')
# 使用后一行的数值填充缺失值
new_df = df.fillna(method='bfill')
```
### 4.2 数据类型转换
在读取Excel数据后,有时候需要对数据进行类型转换,比如将字符串转换为数字,日期字符串转换为日期类型等。Pandas提供了`astype`函数来进行数据类型转换:
```python
# 将列转换为特定数据类型
df['Column'] = df['Column'].astype('int')
df['Date'] = pd.to_datetime(df['Date'])
```
### 4.3 数据筛选和过滤
Pandas提供了强大的数据筛选和过滤功能,可以根据设定的条件来筛选数据。
```python
# 根据条件筛选数据
filtered_data = df[df['Column'] > 100]
```
### 4.4 列名和索引处理
处理列名和索引是数据处理中的常见需求,Pandas提供了丰富的功能来满足这些需求。
```python
# 重命名列名
df.rename(columns={'old_name': 'new_name'}, inplace=True)
# 设置新的索引
df.set_index('Column', inplace=True)
```
### 4.5 数据排序和重排
对数据进行排序和重排可以让数据更加整洁和易于分析,Pandas提供了`sort_values`和`reindex`等方法来完成这些操作。
```python
# 根据指定列进行排序
df.sort_values(by='Column', ascending=False, inplace=True)
# 重新设置索引顺序
new_index = ['A', 'B', 'C', 'D', 'E']
df.reindex(new_index)
```
在实际数据处理中,以上提到的这些方法经常会被使用到,能够帮助我们高效地清洗和处理Excel中的数据。
# 5. 数据分析和统计
在这一章节中,我们将介绍如何使用Pandas库进行数据分析和统计操作。Pandas提供了丰富的函数和工具,能够帮助我们进行数据的整理、分析和可视化展示。
#### 5.1 基本统计分析
Pandas库提供了丰富的统计分析函数,可以帮助我们快速进行数据的统计计算。比如,我们可以使用`describe`函数来生成数据的统计摘要,包括计数、均值、标准差、最小值、25%分位数、中位数、75%分位数、最大值等信息。
```python
# 生成数据的统计摘要
summary = df.describe()
print(summary)
```
除了`describe`函数之外,Pandas还提供了各种统计函数,比如`sum`、`mean`、`median`、`std`等,可以帮助我们进行常见的统计计算。
#### 5.2 数据可视化
Pandas库整合了Matplotlib库,能够轻松实现数据的可视化展示。我们可以直接调用DataFrame的`plot`函数,绘制折线图、柱状图、散点图等各种图表,方便直观地展示数据的分布和趋势。
```python
# 绘制折线图
df.plot(x='date', y='value', kind='line')
plt.show()
```
通过数据可视化,我们可以更直观地理解数据的特征和规律,对数据进行更深入的分析和解读。
#### 5.3 数据聚合和分组
在实际的数据分析中,我们经常需要对数据进行聚合和分组计算。Pandas提供了`groupby`函数,能够方便地实现按照指定的列进行数据分组,并对每个分组进行统计计算。
```python
# 按照分类列进行分组,并计算每组的均值
grouped = df.groupby('category')
mean_value = grouped['value'].mean()
print(mean_value)
```
利用数据聚合和分组功能,我们可以更深入地挖掘数据的特征,发现数据中隐藏的规律和趋势。
#### 5.4 数据透视表
数据透视表是数据分析中常用的工具,能够对数据进行多维度的分析和汇总。Pandas提供了`pivot_table`函数,能够方便地实现数据透视表的构建和分析。
```python
# 创建数据透视表
pivot = df.pivot_table(index='date', columns='category', values='value', aggfunc=np.mean)
print(pivot)
```
通过数据透视表,我们可以将复杂的数据关系进行多维度的展示和分析,更全面地理解数据的特征和规律。
在本章节中,我们介绍了Pandas库在数据分析和统计方面的应用,包括基本统计分析、数据可视化、数据聚合和分组以及数据透视表的使用。这些功能能够帮助我们更深入地理解和挖掘数据,为实际问题的解决提供有力的支持。
# 6. 结论和拓展
在本篇文章中,我们详细介绍了如何使用Pandas库来读取、处理和分析Excel数据。通过本文的学习,我们可以得出以下结论和拓展:
#### 6.1 使用Pandas读取Excel数据的优势
- Pandas库具有强大的数据处理和分析能力,能够帮助用户高效地处理Excel数据。
- 通过Pandas库,可以轻松地实现数据清洗、筛选、统计分析和可视化,极大地提高了数据处理的效率和准确性。
- Pandas库提供了丰富的API和功能,可以满足各种复杂的数据处理需求,使得数据分析工作变得更加灵活和便捷。
#### 6.2 其他Python库与Pandas的对比
- 虽然Pandas库在数据处理方面非常强大,但在特定场景下,也可以结合其他Python库进行数据分析,比如NumPy、Matplotlib、Scikit-learn等,以实现更多复杂的数据处理和机器学习任务。
#### 6.3 更多Pandas高级功能介绍
- 除了本文介绍的基本功能外,Pandas库还有许多高级功能,比如时间序列分析、多层索引、透视表等,读者可以进一步学习和掌握这些高级功能,以应对更加复杂的数据处理任务。
#### 6.4 实践示例和案例分析
- 通过实际的案例分析和示例演练,读者可以更好地掌握Pandas库的使用方法,并且了解如何将Pandas应用于实际的数据处理和分析项目中。
#### 6.5 总结和展望
- 通过本文的学习,相信读者已经对Pandas库在Excel数据处理方面的强大功能有了初步了解。在未来的学习和工作中,可以进一步深入学习Pandas库,探索其更多高级功能,并将其运用到实际的数据处理项目中,达到数据分析的更高效和精确。
以上就是本文关于Pandas库在读取Excel数据方面的结论和拓展内容,希望能够为读者提供一些参考和帮助。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在探索Python在Excel数据处理中的丰富功能和技巧。文章内容涵盖了从初步认识Python的Excel读取功能,到使用Pandas库读取Excel数据,再到数据筛选、透视分析、统计分析、图表绘制等各个方面。此外,还介绍了Python处理Excel中的日期、时间、缺失值、异常值等数据的技巧,以及数据的合并、拆分、清洗、格式化等操作。关联分析、文本处理、与数据库的交互等进阶主题也得到了涵盖。最后,还探讨了Python实现Excel数据的可视化展示和开发自动化报表系统的应用。总之,本专栏全面地介绍了Python在Excel数据处理中的应用,为读者提供了丰富的知识和技能,让他们能更加灵活高效地处理Excel数据。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
无线通信的黄金法则:CSMA_CA与CSMA_CD的比较及实战应用

# 摘要
本文系统地探讨了无线通信中两种重要的载波侦听与冲突解决机制:CSMA/CA(载波侦听多路访问/碰撞避免)和CSMA/CD(载波侦听多路访问/碰撞检测)。文中首先介绍了CSMA的基本原理及这两种协议的工作流程和优劣势,并通过对比分析,深入探讨了它们在不同网络类型中的适用性。文章进一步通
Go语言实战提升秘籍:Web开发入门到精通

# 摘要
Go语言因其简洁、高效以及强大的并发处理能力,在Web开发领域得到了广泛应用。本文从基础概念到高级技巧,全面介绍了Go语言Web开发的核心技术和实践方法。文章首先回顾了Go语言的基础知识,然后深入解析了Go语言的Web开发框架和并发模型。接下来,文章探讨了Go语言Web开发实践基础,包括RES
【监控与维护】:确保CentOS 7 NTP服务的时钟同步稳定性
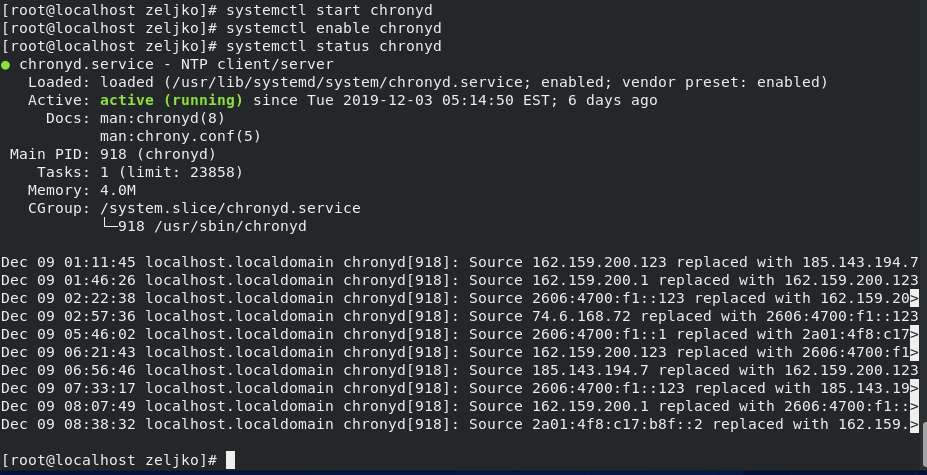
# 摘要
本文详细介绍了NTP(Network Time Protocol)服务的基本概念、作用以及在CentOS 7系统上的安装、配置和高级管理方法。文章首先概述了NTP服务的重要性及其对时间同步的作用,随后深入介绍了在CentOS 7上NTP服务的安装步骤、配置指南、启动验证,以及如何选择合适的时间服务器和进行性能优化。同时,本文还探讨了NTP服务在大规模环境中的应用,包括集
【5G网络故障诊断】:SCG辅站变更成功率优化案例全解析
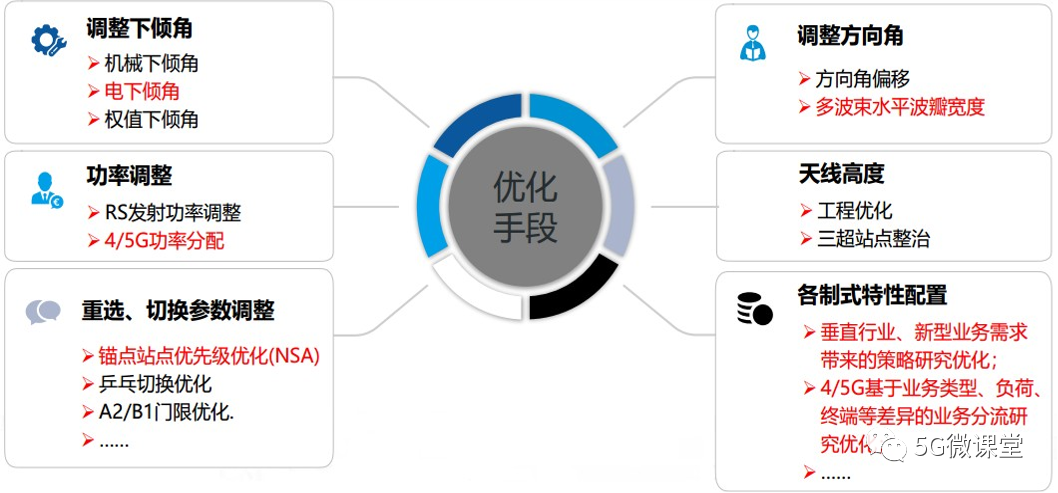
# 摘要
随着5G网络的广泛应用,SCG辅站作为重要组成部分,其变更成功率直接影响网络性能和用户体验。本文首先概述了5G网络及SCG辅站的理论基础,探讨了SCG辅站变更的技术原理、触发条件、流程以及影响成功率的因素,包括无线环境、核心网设备性能、用户设备兼容性等。随后,文章着重分析了SCG辅站变更成功率优化实践,包括数据分析评估、策略制定实施以及效果验证。此外,本文还介绍了5
PWSCF环境变量设置秘籍:系统识别PWSCF的关键配置

# 摘要
本文全面阐述了PWSCF环境变量的基础概念、设置方法、高级配置技巧以及实践应用案例。首先介绍了PWSCF环境变量的基本作用和配置的重要性。随后,详细讲解了用户级与系统级环境变量的配置方法,包括命令行和配置文件的使用,以及环境变量的验证和故障排查。接着,探讨了环境变量的高级配
掌握STM32:JTAG与SWD调试接口深度对比与选择指南

# 摘要
随着嵌入式系统的发展,调试接口作为硬件与软件沟通的重要桥梁,其重要性日益凸显。本文首先概述了调试接口的定义及其在开发过程中的关键作用。随后,分别详细分析了JTAG与SWD两种常见调试接口的工作原理、硬件实现以及软件调试流程。在此基础上,本文对比了JTAG与SWD接口在性能、硬件资源消耗和应用场景上的差异,并提出了针对STM32微控制器的调试接口选型建议。最后,本文探讨
ACARS社区交流:打造爱好者网络

# 摘要
ACARS社区作为一个专注于ACARS技术的交流平台,旨在促进相关技术的传播和应用。本文首先介绍了ACARS社区的概述与理念,阐述了其存在的意义和目标。随后,详细解析了ACARS的技术基础,包括系统架构、通信协议、消息格式、数据传输机制以及系统的安全性和认证流程。接着,本文具体说明了ACARS社区的搭
Paho MQTT消息传递机制详解:保证消息送达的关键因素
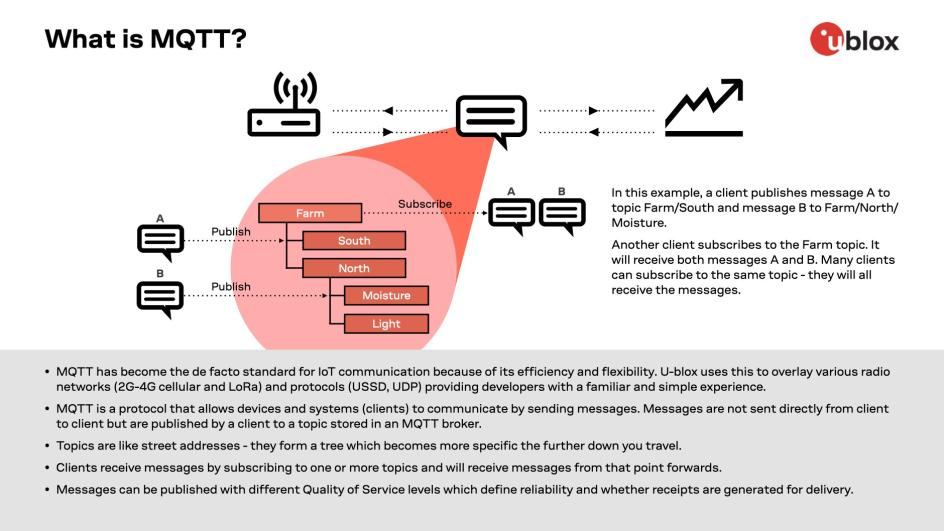
# 摘要
本文深入探讨了MQTT消息传递协议的核心概念、基础机制以及保证消息送达的关键因素。通过对MQTT的工作模式、QoS等级、连接和会话管理的解析,阐述了MQTT协议的高效消息传递能力。进一步分析了Paho MQTT客户端的性能优化、安全机制、故障排查和监控策略,并结合实践案例,如物联网应用和企业级集成,详细介绍了P
保护你的数据:揭秘微软文件共享协议的安全隐患及防护措施{安全篇

# 摘要
本文对微软文件共享协议进行了全面的探讨,从理论基础到安全漏洞,再到防御措施和实战演练,揭示了协议的工作原理、存在的安全威胁以及有效的防御技术。通过对安全漏洞实例的深入分析和对具体防御措施的讨论,本文提出了一个系统化的框架,旨在帮助IT专业人士理解和保护文件共享环境,确保网络数据的安全和完整性。最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )