




【Oracle 11g SQL进阶】:24小时内打造高效SQL语句的终极实践指南


Oracle Database 11g:SQL 基础 I 电子演示文稿
摘要
本文旨在深入探讨Oracle 11g SQL的高级应用和性能优化技术。首先回顾SQL基础,并对执行计划进行详细解析,强调执行计划的重要性及获取和解读方法。接着探讨SQL语句性能调优技术,包括性能分析工具的应用、索引优化、查询优化技巧等。文章进一步介绍了高级SQL函数的运用,数据加密与安全最佳实践,以及分布式数据处理技术。最后,通过案例分析展示如何在实际业务场景中打造高效SQL语句,涵盖从需求提炼到性能测试的实战演练过程,总结性能调优的经验。本文为数据库管理员和开发人员提供了一套完整的SQL性能优化指南。
关键字
Oracle 11g SQL;执行计划;性能调优;索引优化;数据加密;分布式数据处理;性能测试
参考资源链接:Oracle 11g JDBC驱动jar包下载指南
1. Oracle 11g SQL基础回顾
1.1 Oracle 11g SQL概述
在信息技术飞速发展的今天,数据库管理与SQL语言应用的重要性日益凸显。Oracle 11g作为业界广泛使用的数据库管理系统,其SQL语言的熟练使用是数据库管理员和开发者必备技能之一。回顾基础,是对旧知识的巩固,也是深入理解和掌握高级技术的基石。
1.2 数据操作与查询
Oracle 11g SQL提供了丰富的数据操作语言(DML),允许用户执行数据的插入、更新、删除等操作。此外,数据查询语言(DQL)的掌握,尤其是SELECT语句的灵活运用,对于日常数据库管理与维护至关重要。
1.3 数据定义与控制
在Oracle 11g中,数据定义语言(DDL)和数据控制语言(DCL)也是基础知识点。DDL包括创建、修改和删除表结构的操作;而DCL则涉及权限控制,确保数据的安全性。理解并能够正确使用这些基本语法是管理数据库的前提条件。
通过本章的回顾,读者应能流畅地使用Oracle 11g进行基本的数据库操作,从而为进一步深入学习打下坚实的基础。
2. 深入理解SQL执行计划
2.1 SQL执行计划概览
2.1.1 执行计划的重要性
执行计划是Oracle数据库执行SQL语句时生成的一个内部规划步骤,它描述了如何访问数据、执行操作以及执行顺序。理解执行计划对于数据库管理员和开发者来说至关重要,因为它直接关联到SQL语句的执行效率。一个好的执行计划可以确保查询能够快速、高效地从数据库中检索数据,而一个不良的执行计划则可能导致慢查询、资源浪费甚至系统崩溃。通过分析执行计划,我们能够诊断性能瓶颈,并对查询进行优化。
2.1.2 如何获取执行计划
在Oracle中,可以通过多种方式获取SQL语句的执行计划。最常用的是使用EXPLAIN PLAN语句来生成执行计划的描述。另外,我们还可以使用DBMS_XPLAN.DISPLAY函数来格式化显示执行计划。例如:
- EXPLAIN PLAN FOR
- SELECT * FROM employees;
之后,通过查询PLAN_TABLE来获取具体的执行计划:
- SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY());
在Oracle 12c及更高版本中,可以使用DBMS_SQL.T监督管理ператор功能,它提供了更多的执行计划选项,如自动跟踪。
2.2 执行计划的组成和解读
2.2.1 操作步骤解释
执行计划由一系列的步骤组成,每个步骤对应于查询执行过程中的一次操作。每个步骤都包含了操作类型、对象、访问方法等信息。步骤通常以树状结构表示,其中的节点称为“行源操作符”(row source operation)。例如,“TABLE ACCESS FULL”表示全表扫描,“NESTED LOOP”表示嵌套循环连接等。
要解读执行计划,首先要关注步骤的顺序和类型。顺序通常表示执行计划的逻辑执行顺序,而类型则表明了操作的性质。例如,扫描类型操作(如全表扫描和索引范围扫描)通常表示数据获取方式,而连接类型操作(如嵌套循环、哈希连接)表示如何合并多表数据。
2.2.2 成本估算与评估
每个步骤都会有一个成本估算,这个成本是基于优化器的统计信息以及预估的资源消耗(如CPU时间、I/O操作次数)计算得来。通常,成本越低的步骤意味着更快的执行时间。Oracle优化器使用成本模型来选择最优的执行计划。
成本估算与评估是优化SQL语句的关键部分。通过比较不同执行计划的成本,我们可以确定哪些步骤是最耗时的,从而对这部分进行重点优化。Oracle还提供了DBMS_SPACE包来评估表和索引的存储需求,这对于预估和优化成本非常有用。
2.3 优化执行计划
2.3.1 识别和解决执行计划中的问题
识别执行计划中的问题通常需要对执行计划进行详细分析。如果发现执行计划不合理,例如使用了全表扫描而不是索引扫描,那么可能需要通过添加索引、修改SQL语句或使用优化器提示(HINTS)来解决问题。
在分析执行计划时,需要特别注意以下几个方面:
- 操作类型:确保使用的是最高效的数据访问方式,如在数据分布均匀且数据量不是特别大的情况下,索引范围扫描通常优于全表扫描。
- 连接顺序:连接的顺序会影响查询的效率,选择正确的连接顺序是优化的关键。
- 数据过滤:使用WHERE子句有效地过滤数据可以减少返回的行数,加快查询速度。
2.3.2 使用HINTS进行计划优化
HINTS是Oracle提供的一种机制,允许用户给优化器提供额外的指令来选择特定的执行计划。HINTS可以用来强制使用某种操作类型或连接方法,或者限制优化器在考虑执行计划时的某些选项。例如:
- SELECT /*+ INDEX(e employees_index) */ * FROM employees e;
使用HINTS时需要谨慎,因为不恰当的使用可能会导致性能下降。优化器的自动选择通常是最优的,只有在完全理解了查询的上下文和数据特性时,才应考虑使用HINTS进行干预。
使用HINTS的步骤通常包括:
- 分析当前的执行计划,找到性能瓶颈。
- 根据业务逻辑和数据特性决定使用哪种HINT。
- 修改SQL语句并插入相应的HINT。
- 重新运行查询,验证优化是否有效。
通过对执行计划的深入理解、准确分析和优化,可以使SQL语句的执行更加高效,从而提升整个数据库系统的性能。在下一章节中,我们将探讨如何进一步利用高级SQL技巧和函数来实现复杂的查询和数据处理任务。
3. SQL语句的性能调优技术
性能调优是数据库管理中至关重要的一环。良好的性能调优不仅能够提高数据库系统的响应速度,还能确保系统资源得到合理分配和利用。本章将深入探讨SQL语句的性能调优技术,并将重点放在索引优化策略、查询优化技巧等方面,帮助数据库管理员和开发人员理解和应用性能调优的最佳实践。
3.1 SQL性能调优概述
3.1.1 性能调优的目标和方法
性能调优的主要目标是提高数据处理速度,减少查询响应时间,确保数据一致性和完整性。调优方法包括但不限于:
- 对现有系统进行评估,确定性能瓶颈。
- 利用性能监控工具进行跟踪和诊断。
- 通过查询优化器优化SQL语句。
- 对数据库对象(如索引)进行调优。
3.1.2 性能分析工具介绍
性能分析工具在性能调优过程中扮演了至关重要的角色。它们可以帮助我们:
- 监控系统资源使用情况。
- 分析SQL语句执行效率。
- 提供数据读写、锁竞争等详细统计。
一些常用的性能分析工具包括:
- Oracle Enterprise Manager (OEM)
- SQL Developer的SQL Tuning Advisor
- V$视图系列(如V$SQL、V$SQLAREA)
3.2 索引优化策略
3.2.1 索引类型和选择
在Oracle数据库中,常用的索引类型包括B-tree、位图索引、函数式索引等。选择合适的索引类型对于性能调优至关重要。
- B-tree索引:适用于大多数的数据访问模式。
- 位图索引:特别适合于数据值很少的列,如性别、地区等。
- 函数式索引:适用于对列的值进行函数运算的情况。
选择索引时,需要考虑以下因素:
- 查询的模式和频率。
- 数据的分布特性。
- 数据变更的频率。
3.2.2 索引维护和管理
索引维护对于保持系统的性能至关重要。以下是一些索引维护和管理的策略:
- 定期清理不再使用的索引,以节省空间和维护成本。
- 适时调整索引,考虑重建或者重组索引。
- 监控索引使用情况,使用工具如
DBMS_SPACE.ADVISE_INDEX来获得索引优化建议。
3.3 查询优化技巧
3.3.1 WHERE子句优化
优化WHERE子句可以显著提升查询性能。以下是一些常见的优化技巧:
- 合理使用索引列:索引列在
WHERE子句中的使用可以加快查询速度。 - 避免函数运算在索引列上:对索引列的函数运算会导致索引失效。
- 使用BETWEEN代替多个OR条件:BETWEEN操作符可使SQL优化器更好地优化查询。
3.3.2 JOIN操作优化
优化JOIN操作同样可以提升性能。关键点包括:
- 确定正确的JOIN类型:根据数据分布和查询需求选择合适的JOIN类型,如INNER JOIN、LEFT JOIN等。
- 使用提示(HINTS)引导优化器:在复杂查询中使用Oracle SQL优化器HINTS,如USE_NL, USE_HASH等。
- 减少JOIN列的选择性:选择性高的列可以减少结果集大小,提高查询效率。
3.3.3 子查询和临时表使用策略
处理复杂的查询时,合理利用子查询和临时表是关键:
- 子查询优化:尽可能将相关子查询改写为等价的JOIN查询,或者使用嵌套循环(NESTED LOOP)的方式。
- 临时表的使用:对于需要多次使用或者进行复杂操作的中间数据集,使用临时表可以提高效率。
示例代码块及其分析:
假设我们有以下查询语句:
- SELECT a.column1, b.column2
- FROM table1 a
- JOIN table2 b ON a.id = b.id
- WHERE a.column3 = 'some_value';
在这个查询中,如果table1.column3上有索引,并且我们预计大部分数据行都会被过滤掉,那么我们可以使用USE_HASH提示来强制优化器使用哈希连接,而不是默认的嵌套循环连接:
- SELECT /*+ USE_HASH(a b) */ a.column1, b.column2
- FROM table1 a
- JOIN table2 b ON a.id = b.id
- WHERE a.column3 = 'some_value';
这个提示(HINT)会指导优化器对连接操作进行优化处理,使得当数据量较大时,性能表现更优。在参数说明方面,USE_HASH是一个优化器提示,指示优化器为表a和表b使用哈希连接方法。在参数分析方面,优化器会基于统计信息评估不同连接类型的执行成本,USE_HASH提示可能在某些情况下替代默认的连接策略。
4. 高级SQL技巧和函数应用
4.1 高级SQL函数运用
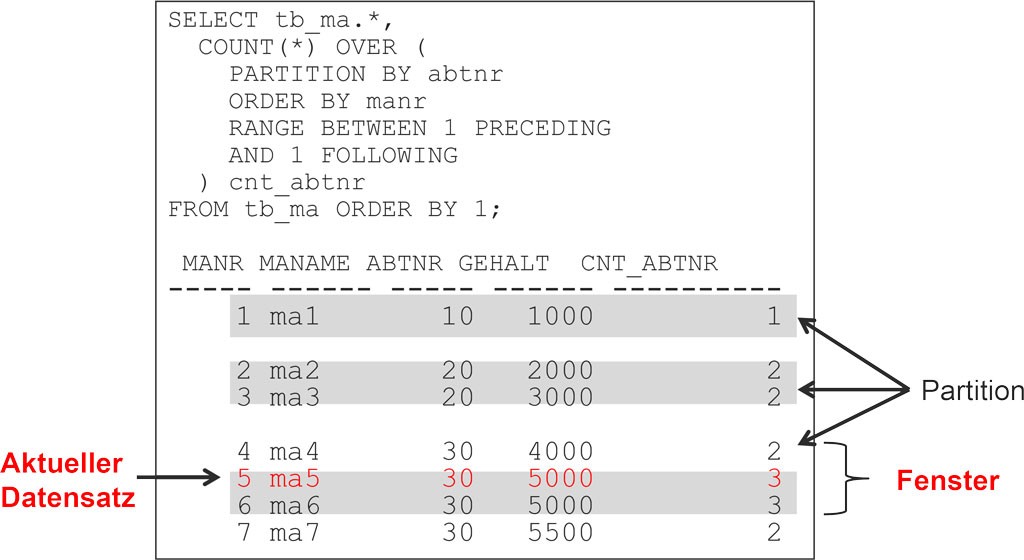
4.1.1 窗口函数的高级应用
窗口函数在数据库查询中提供了强大的数据处理能力,尤其在处理排名、百分比排名和累积求和等场景中表现突出。它们允许我们在一个查询中对子集进行操作,而不影响结果集中的其他行。
语法结构和参数解释:
- SELECT
- column1,
- column2,
- WINDOW_FUNCTION_NAME (expression) OVER ([PARTITION BY column] ORDER BY column [ASC | DESC]) AS alias
- FROM
- table_name;
其中,WINDOW_FUNCTION_NAME 可以是以下窗口函数之一,如ROW_NUMBER()、RANK()、DENSE_RANK()、PERCENT_RANK()、CUME_DIST() 等。
例如,考虑一个销售数据表sales,其中包含日期date、销售人员salesperson和销售额amount。要为每位销售人员按月计算累积销售额,可以使用以下查询:
- SELECT
- date,
- salesperson,
- SUM(amount) OVER (PARTITION BY salesperson ORDER BY date) AS cumulative_sales
- FROM
- sales;
这个查询将返回每个销售人员每天的累积销售额。通过PARTITION BY子句,我们可以将数据分割为每位销售人员的独立组,然后按照日期顺序计算累积总和。
使用场景和注意事项:
窗口函数在报告生成、分析和数据可视化中极为有用。它们能够处理更复杂的业务需求,如基于滚动窗口的平均销售计算。然而,在使用窗口函数时,应当注意内存消耗可能较大,特别是当处理大规模数据集时。此外,窗口函数并不总是优化过的,它们的使用需结合对执行计划的理解。
4.1.2 集合操作与聚合函数
集合操作允许我们从多个数据集中合并、交集和差集结果,而聚合函数如COUNT(), SUM(), AVG(), MAX(), 和MIN()则用于执行各种计算,如计数、求和、平均值、最大值和最小值。
聚合函数的使用:
- SELECT
- COUNT(column_name) AS count_value,
- SUM(column_name) AS sum_value,
- AVG(column_name) AS avg_value,
- MAX(column_name) AS max_value,
- MIN(column_name) AS min_value
- FROM
- table_name;
对于集合操作,考虑有两张表table1和table2,其结构相同,包含字段id和value,我们可以使用UNION将两个查询结果合并:
- SELECT id, value FROM table1
- UNION
- SELECT id, value FROM table2;
注意事项:
聚合函数虽然功能强大,但可能影响查询性能,尤其是当表数据量大或涉及到复杂的子查询时。为了优化性能,使用索引可以加快聚合操作的执行速度。集合操作在没有适当索引的情况下可能导致全表扫描,这在性能上是不利的。因此,在生产环境中使用这些函数时,需考虑到可能产生的性能影响。
4.2 数据加密与安全
4.2.1 数据加密函数介绍
数据安全是数据库管理中不可或缺的一环。Oracle数据库提供了多种加密函数,用于在存储和传输时保护敏感信息,如密码和个人识别信息。
基本加密函数:
ENCRYPT:使用密钥对数据进行加密。DECRYPT:使用密钥对数据进行解密。HASH:生成数据的哈希值,用于比较数据的一致性。
例如,对于敏感的用户密码,我们可以使用DBMS赞赏包提供的Crypt函数来加密存储:
- SELECT
- dbms赞赏.Crypt('myPassword', 'salt') FROM dual;
注意事项:
虽然加密函数提供了数据保护,但加密算法可能会有更新和改进。因此,建议定期检查和更新数据库所使用的加密算法和密钥。数据加密时还需考虑加密与解密的性能开销,特别是在高并发的应用场景下。
4.2.2 安全策略和最佳实践
除了使用加密函数外,还需要制定相应的安全策略来保护数据库系统。
安全策略包括:
- 使用强密码策略,强制进行密码更换周期和复杂性要求。
- 限制用户权限,仅提供必要的最小权限来执行其工作。
- 使用安全协议,如SSL,来保护数据在客户端和服务器之间传输的安全。
- 定期备份数据,并确保备份过程的安全性和完整性。
- 定期审计数据库活动,包括登录尝试、数据访问和修改。
最佳实践:
- 在应用层实现数据验证逻辑,如输入验证、SQL注入防护。
- 定期对数据库进行安全扫描和漏洞评估,以发现潜在的安全问题。
- 对于敏感数据,不仅要存储加密,还要实现数据的脱敏处理,以进一步降低数据泄露的风险。
4.3 分布式数据处理
4.3.1 分布式查询和事务
在大型企业应用中,处理分布式的、跨不同数据库的数据变得越来越常见。Oracle提供了分布式查询和事务处理功能,使得操作跨数据库的数据变得可能。
分布式查询的实现:
- 使用数据库链接(Database Link,DBLink)可以创建从一个数据库到另一个数据库的连接。
- 通过
SELECT ...@DBLINK语法,可以从远程数据库查询数据。 - 使用分布式事务处理,可以确保多个数据库之间的一致性操作。
例如,创建一个到远程数据库的DBLink,并查询远程表:
- CREATE DATABASE LINK remote_link
- CONNECT TO "remote_user" IDENTIFIED BY "password"
- USING 'remote_database';
然后执行分布式查询:
- SELECT *
- FROM remote_table@remote_link;
注意事项:
分布式查询虽然强大,但执行起来可能会有较高的网络开销和延迟。在设计分布式查询时,应当考虑网络拓扑和带宽限制。同时,对分布式事务的管理要使用两阶段提交(2PC),这确保了事务在多个数据库中的原子性,但也带来了性能上的开销。
4.3.2 数据复制技术
数据复制是确保数据可用性和灾难恢复的关键技术之一。Oracle支持多种数据复制方法,包括物化视图、数据卫士(Data Guard)和GoldenGate等。
数据复制方法:
- 物化视图:用于定期从一个数据库中复制数据到另一个数据库。它可以在不同时间点建立数据的快照。
- 数据卫士:提供了数据库级别的物理数据复制,支持高可用性、灾难恢复和读写分离。
- GoldenGate:一种用于实时数据集成和复制的解决方案,适用于异构数据库环境。
例如,创建一个物化视图用于定期更新远程表:
- CREATE MATERIALIZED VIEW remote_view
- BUILD IMMEDIATE
- REFRESH FORCE
- ON DEMAND
- AS
- SELECT *
- FROM remote_table@remote_link;
物化视图在创建时会立即填充数据,并在后续通过REFRESH操作来同步数据更改。
注意事项:
数据复制技术虽然提供了数据的冗余和可用性,但同时也增加了系统的复杂性。管理分布式数据和同步更新要求细致的监控和计划。复制技术可能会导致数据同步的延迟,因此需要根据业务需求合理选择复制的类型和策略。在实施复制技术前,应充分评估和测试以确保数据一致性。
5. 案例分析:打造高效SQL语句的实战演练
5.1 实际业务场景分析
5.1.1 业务场景概述和需求提炼
在实际的业务场景中,我们经常需要处理大量的数据和复杂查询,以支持日常的业务报告和决策制定。比如在一家零售企业中,业务分析师需要根据销售数据来进行销售趋势的预测,这要求我们能够快速地从历史销售记录中提取和聚合数据。
例如,需求可能是:
- 提取过去一年内每个季度,各个产品的销售总额。
- 根据产品类别进行排序。
- 能够快速响应不同时间段的查询请求。
为了提炼出上述需求,我们需要与业务分析师紧密合作,理解其需求背后的细节,比如数据量大小、数据的维度、业务关注的指标等。
5.1.2 数据模型设计和优化
数据模型的设计是实现高效查询的基础。针对上述业务场景,我们可能会设计出包含如下表结构的简单数据模型:
- CREATE TABLE sales_data (
- sales_id NUMBER PRIMARY KEY,
- product_id NUMBER,
- category_id NUMBER,
- sales_date DATE,
- amount NUMBER
- );
优化数据模型可能涉及添加索引、归一化或反范式化等策略。考虑到查询中经常涉及时间序列分析和产品类别统计,我们可能在 sales_date 和 category_id 字段上创建索引,以加速查询:
- CREATE INDEX idx_sales_date ON sales_data(sales_date);
- CREATE INDEX idx_category_id ON sales_data(category_id);
5.2 SQL语句实战打造
5.2.1 从需求到SQL的转换过程
根据业务分析师的需求,我们需要编写一个SQL查询语句,它能快速聚合过去一年每个季度的销售数据。
- SELECT
- EXTRACT(QUARTER FROM sales_date) AS sales_quarter,
- category_id,
- SUM(amount) AS total_sales
- FROM
- sales_data
- WHERE
- sales_date >= ADD_MONTHS(SYSDATE, -12)
- GROUP BY
- EXTRACT(QUARTER FROM sales_date),
- category_id
- ORDER BY
- sales_quarter,
- total_sales DESC;
这条SQL语句通过聚合函数SUM()和EXTRACT()函数来提取季度信息,通过GROUP BY对数据进行分组,并利用WHERE子句来限制时间范围。
5.2.2 SQL性能调优实战
针对上述SQL语句,我们可以进行一些调优操作:
- 确保
sales_date字段上有合适的索引,以加速日期范围的筛选。 - 分析执行计划,判断是否所有索引都得到正确利用,或者是否存在全表扫描。
如果发现执行计划中存在扫描整个表的情况,则可能需要调整查询或进一步优化索引策略。
5.3 性能测试与案例总结
5.3.1 性能测试工具和方法
为了验证SQL语句的性能,我们可以使用如下方法:
- 使用Oracle SQL Developer或任何其他数据库管理工具来执行查询,并监控响应时间。
- 使用Autotrace工具来获取执行计划和统计信息。
- 进行压力测试,模拟多用户并发执行查询,并观察结果。
5.3.2 案例总结和经验分享
在实战演练结束后,总结经验教训是至关重要的。以下是一些可能的经验分享:
- 索引在提升查询性能中的关键作用。
- 怎样通过分析执行计划来识别性能瓶颈。
- 如何对SQL语句进行逐步优化,直至满足业务性能需求。
结合具体的业务需求和测试结果,我们能够不断提炼和改进SQL语句,实现更加高效的查询性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
会员积分制度的秘密:电商案例揭示制度设计的利与弊
【SEP 14.3策略定制】:打造贴身安全策略,防御企业级威胁
【分页调度算法应用秘籍】:数据库系统比较与最佳实践
ABB机器人串口通信秘籍:10个实用技巧助你高效通信
数据库TPS优化实战:索引策略与查询调优
XML安全必学:5个步骤保护你的XML数据传输和存储
【用户界面设计】:威纶通屏与贝加莱PLC数据交互的艺术
【异步编程高级技巧】:实现高效的回调嵌套与错误处理
电机设计中的多物理场耦合仿真


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















