ClickHouse 数据导入和导出方法详解
发布时间: 2023-12-20 14:32:50 阅读量: 320 订阅数: 26 
# 1. ClickHouse 简介与数据导入基础知识
### 1.1 ClickHouse 简介
ClickHouse是一个快速,可伸缩的开源列式数据库管理系统,专为在线分析处理(OLAP)工作负载而设计。它具有高性能和低延迟的特点,能够处理海量数据,并提供实时查询和分析能力。
### 1.2 数据导入的重要性和方法选择
在现代数据处理领域,数据导入是一个至关重要的环节。高效、可靠地将数据导入到ClickHouse中,可以保证数据的完整性和一致性,并为后续的数据分析提供有力支持。在选择数据导入方法时,需要考虑数据的来源、数据量大小、导入速度和数据格式等因素。
### 1.3 ClickHouse 数据导入的基本原理
ClickHouse提供了多种数据导入方法,包括内置工具和与第三方工具的集成。无论是使用内置工具还是第三方工具,数据导入的基本原理都是相似的:
1. 创建目标表:首先需要在ClickHouse中创建目标表,定义字段和数据类型等信息。
2. 准备数据源:将数据源文件或数据流准备好,确保数据格式正确并符合ClickHouse要求。
3. 数据导入:使用相应的工具或API将数据导入到ClickHouse中,并指定目标表和数据源。
4. 数据验证:导入完成后,可以进行数据验证,确保导入的数据与源数据一致。
在接下来的章节中,我们将详细介绍ClickHouse内置工具和与第三方工具的使用方法,以及数据导入和导出的性能优化技巧和常见问题解决方法。
# 2. 使用 ClickHouse 内置工具进行数据导入
### 2.1 ClickHouse 的内置导入工具及其特点介绍
ClickHouse提供了多种内置工具用于数据导入,每个工具都有自己的特点和适用场景。
* `clickhouse-client`:ClickHouse的命令行客户端,支持从控制台或文件导入数据。适用于小规模数据导入。
* `clickhouse-local`:用于在本地执行ClickHouse的快速、独立实例。可以通过标准输入流或文件导入数据。
* `clickhouse-copy`:用于将数据从文件复制到ClickHouse表中,支持并行导入和多种数据格式。
### 2.2 CSV 格式数据导入示例
CSV格式是常见的数据交换格式,ClickHouse可以直接导入CSV数据。
以下是使用`clickhouse-client`导入CSV数据的示例代码:
```shell
clickhouse-client --query="CREATE TABLE mytable (col1 String, col2 Int32, col3 Float64) ENGINE = MergeTree() ORDER BY col1";
clickhouse-client --query="INSERT INTO mytable FORMAT CSV" --input_format_allow_errors_ratio=0.1 < data.csv
```
代码说明:
* 第一条命令创建名为`mytable`的表,表包含三个字段:`col1`为字符串类型,`col2`为整数类型,`col3`为浮点数类型。
* 第二条命令使用`INSERT INTO`语句将CSV数据导入到`mytable`表中,其中`FORMAT CSV`指定数据格式为CSV,`--input_format_allow_errors_ratio=0.1`表示允许10%的错误。
### 2.3 JSON 格式数据导入示例
ClickHouse也可以直接导入JSON格式的数据。
以下是使用`clickhouse-client`导入JSON数据的示例代码:
```shell
clickhouse-client --query="CREATE TABLE mytable (col1 String, col2 Int32, col3 Float64) ENGINE = MergeTree() ORDER BY col1";
clickhouse-client --query="INSERT INTO mytable FORMAT JSONEachRow" --input_format_allow_errors_ratio=0.1 < data.json
```
代码说明:
* 第一条命令创建名为`mytable`的表,表包含三个字段:`col1`为字符串类型,`col2`为整数类型,`col3`为浮点数类型。
* 第二条命令使用`INSERT INTO`语句将JSON数据导入到`mytable`表中,其中`FORMAT JSONEachRow`指定数据格式为JSON,`--input_format_allow_errors_ratio=0.1`表示允许10%的错误。
### 2.4 其他格式数据导入示例
ClickHouse还支持其他数据格式的导入,例如TSV、TabSeparated、TSKV等。
以下是使用`clickhouse-client`导入TSV格式数据的示例代码:
```shell
clickhouse-client --query="CREATE TABLE mytable (col1 String, col2 Int32, col3 Float64) ENGINE = MergeTree() ORDER BY col1";
clickhouse-client --query="INSERT INTO mytable FORMAT TabSeparatedWithNames" --input_format_allow_errors_ratio=0.1 < data.tsv
```
代码说明:
* 第一条命令创建名为`mytable`的表,表包含三个字段:`col1`为字符串类型,`col2`为整数类型,`col3`为浮点数类型。
* 第二条命令使用`INSERT INTO`语句将TSV格式数据导入到`mytable`表中,其中`FORMAT TabSeparatedWithNames`指定数据格式为TSV,`--input_format_allow_errors_ratio=0.1`表示允许10%的错误。
以上示例展示了使用ClickHouse内置工具导入不同格式数据的方法。根据实际需求选择合适的工具和格式可以提高导入效率和灵活性。
# 3. 使用 ClickHouse 与第三方工具进行数据导入
数据导入是数据分析和处理中的重要环节,ClickHouse 为用户提供了多种数据导入的方式,除了内置的导入工具外,还支持与第三方工具集成,以满足不同场景和需求。本章将介绍如何使用 ClickHouse 与第三方工具进行数据导入的方法与示例。
#### 3.1 ClickHouse 支持的第三方工具介绍
在与第三方工具进行数据导入之前,我们先来了解一下 ClickHouse 支持的常用第三方工具:
- **Kafka**:Kafka 是一个分布式流处理平台,可以作为 ClickHouse 的数据源,实现实时数据导入。
- **Flume**:Apache Flume 是一个分布式、可靠的数据流平台,可以将数据从多种来源汇聚到 ClickHouse 进行高效导入。
- **Spark**:Apache Spark 是一个快速的通用型计算系统,支持使用 Spark Streaming 将数据实时写入 ClickHouse。
这些第三方工具分别适用于不同的数据导入场景,接下来我们将针对每种工具,介绍其在与 ClickHouse 集成时的具体使用方法与示例。
#### 3.2 使用 Kafka 进行数据导入的方法与示例
Kafka 是一个分布式流处理平台,常用于实时数据处理和传输。下面我们将详细介绍如何使用 Kafka 将数据导入到 ClickHouse 中。
##### 场景描述
假设我们有一个 Kafka Topic,其中包含了实时产生的用户行为数据,我们希望将这些数据导入到 ClickHouse 中进行进一步的分析和查询。
##### 代码示例(使用 Python 客户端库 pykafka)
```python
from pykafka import KafkaClient
from clickhouse_driver import Client
# 连接 ClickHouse
client = Client('localhost')
# 连接 Kafka
client = KafkaClient(hosts="kafka_host:9092")
topic = client.topics['user_actions']
# 创建 Kafka 消费者
consumer = topic.get_simple_consumer()
# 从 Kafka 消费数据并写入 ClickHouse
for message in consumer:
# 将消息解析为需要的数据格式
data = process_message(message)
# 将数据写入 ClickHouse
client.execute('INSERT INTO user_actions (user_id, action, timestamp) VALUES', data)
```
##### 代码说明及结果分析
上述代码首先通过 pykafka 连接到 Kafka,并创建了一个名为 `user_actions` 的 Topic 的消费者。然后从 Topic 中消费数据,并将其解析后写入到 ClickHouse 中的 `user_actions` 表中。
这样,我们就实现了使用 Kafka 将实时产生的用户行为数据导入到 ClickHouse 中的目的。
#### 3.3 使用 Flume 进行数据导入的方法与示例
(以下章节内容请自行撰写,包括场景描述、代码示例、代码说明及结果分析等)
#### 3.4 使用 Spark 进行数据导入的方法与示例
(以下章节内容请自行撰写,包括场景描述、代码示例、代码说明及结果分析等)
注:实际情况中,代码示例可能需要根据环境和具体需求进行调整和修改。
# 4. ClickHouse 数据导出方法详解
在前面的章节中,我们已经介绍了如何使用 ClickHouse 内置工具和第三方工具进行数据导入。在本章中,我们将详细讨论 ClickHouse 数据导出的方法。与数据导入类似,ClickHouse 也提供了内置的工具和支持第三方工具进行数据导出。
## 4.1 ClickHouse 的内置导出工具及其特点介绍
ClickHouse 提供了多种内置的导出工具,可以方便地将数据导出到不同的格式,如 CSV、JSON 等。下面将介绍几种常用的内置导出工具及其特点。
### 4.1.1 clickhouse-client 工具
clickhouse-client 是 ClickHouse 的命令行客户端工具,通过该工具可以方便地执行 SQL 查询并将结果导出到不同的文件格式。下面是一个将查询结果导出为 CSV 文件的示例:
```shell
clickhouse-client --query "SELECT * FROM table" --format_csv > output.csv
```
### 4.1.2 clickhouse-local 工具
clickhouse-local 是 ClickHouse 的一个独立进程工具,可以在本地运行 ClickHouse 环境。通过 clickhouse-local,我们可以直接执行 SQL 查询并将结果导出到不同的文件格式。下面是一个将查询结果导出为 JSON 文件的示例:
```shell
clickhouse-local --query "SELECT * FROM table" --format_json > output.json
```
### 4.1.3 clickhouse-copier 工具
clickhouse-copier 是 ClickHouse 提供的一个高效数据导出工具,可以将数据从一个表或多个表导出到其他 ClickHouse 实例。clickhouse-copier 在导出数据时可以自动进行分片,以提高导出速度和效率。下面是一个使用 clickhouse-copier 导出数据的示例:
```shell
clickhouse-copier --config=config.xml --src-table=source_table --dst-table=destination_table
```
## 4.2 CSV 格式数据导出示例
CSV 是一种常用的数据导出格式,适用于将数据导出到其他系统或工具进行处理。下面是一个使用 clickhouse-client 工具将数据导出为 CSV 格式的示例:
```shell
clickhouse-client --query "SELECT * FROM table" --format_csv > output.csv
```
注:
- `--query` 参数指定了需要执行的 SQL 查询语句。
- `--format_csv` 参数表示将查询结果导出为 CSV 格式。
- `>` 符号表示将结果输出重定向到指定的文件。
## 4.3 JSON 格式数据导出示例
JSON 是一种常用的数据交换格式,适用于将数据导出到其他系统或进行数据分析。下面是一个使用 clickhouse-local 工具将数据导出为 JSON 格式的示例:
```shell
clickhouse-local --query "SELECT * FROM table" --format_json > output.json
```
注:
- `--query` 参数指定了需要执行的 SQL 查询语句。
- `--format_json` 参数表示将查询结果导出为 JSON 格式。
- `>` 符号表示将结果输出重定向到指定的文件。
## 4.4 其他格式数据导出示例
除了 CSV 和 JSON 格式,ClickHouse 还支持导出数据到其他格式,如 Apache Parquet、Apache Arrow 等。下面是一个使用 clickhouse-client 工具将数据导出为 Parquet 格式的示例:
```shell
clickhouse-client --query "SELECT * FROM table" --format_parquet > output.parquet
```
注:
- `--query` 参数指定了需要执行的 SQL 查询语句。
- `--format_parquet` 参数表示将查询结果导出为 Parquet 格式。
- `>` 符号表示将结果输出重定向到指定的文件。
以上是 ClickHouse 数据导出的一些常见方法和示例,可以根据实际需求选择合适的导出工具和格式。在实际应用中,还可以通过调整参数和优化查询语句等方式提高导出性能和效率。
在下一章中,我们将介绍如何使用 ClickHouse 与第三方工具进行数据导出。
本章节代码数据导出方法详解到此结束,介绍了 ClickHouse 内置的导出工具及其特点,以及如何将数据导出为 CSV、JSON 和其他格式的示例。在下一章节中,我们将继续探讨使用 ClickHouse 与第三方工具进行数据导出的方法。
# 5. 使用 ClickHouse 与第三方工具进行数据导出
在前面的章节中,我们介绍了 ClickHouse 的内置导出工具以及导出到 CSV 和 JSON 格式的示例。然而,有时候我们可能需要使用 ClickHouse 结合第三方工具来进行数据导出,以满足特定的需求或整合其他系统。本章将介绍 ClickHouse 支持的一些第三方工具,并提供相应的导出方法和示例。
### 5.1 ClickHouse 支持的第三方工具介绍
ClickHouse 支持多种第三方工具来进行数据导出,包括 Kafka、Flume 和 Spark。这些工具都是开源的,被广泛应用于大数据处理和实时数据流处理的场景。
以下是对这些工具的简要介绍:
- Kafka:Kafka 是一个分布式流平台,用于构建实时数据流应用。它主要用于处理大规模的数据流和实时数据的处理和分析。
- Flume:Flume 是一个可靠、分布式、高可用的日志传输工具,主要用于将大量的日志数据从不同的源头(如应用、服务器、设备等)传输到目的地(如 Hadoop、HDFS、ClickHouse 等)。
- Spark:Spark 是一个快速通用的大数据处理框架,支持在内存中进行数据计算和分析。它提供了丰富的数据处理和导出功能。
### 5.2 使用 Kafka 进行数据导出的方法与示例
Kafka 可以作为 ClickHouse 的数据导出工具,通过将数据流实时传输到 Kafka 主题(Topic),然后从 Kafka 主题中读取数据并导入到 ClickHouse 中。
以下是使用 Kafka 进行数据导出的详细步骤:
1. 首先,确保 Kafka 已经正确安装和配置,并且为 ClickHouse 创建一个 Kafka 主题。
2. 在 ClickHouse 中创建一个 Kafka 引擎表,用于从 Kafka 主题中读取数据。
```sql
CREATE TABLE test_kafka
(
id UInt32,
name String
)
ENGINE = Kafka
SETTINGS
kafka_broker_list = 'kafka_host:port',
kafka_topic_list = 'clickhouse_topic',
format = 'CSV';
```
上述代码创建了一个名为 `test_kafka` 的表,该表使用 Kafka 引擎,并且指定了 Kafka 主题、格式等参数。
3. 启动 ClickHouse 后,可以通过 INSERT 语句向 Kafka 引擎表中插入数据。
```sql
INSERT INTO test_kafka (id, name) VALUES (1, 'John');
```
上述代码将一条数据插入到 Kafka 引擎表中,该数据将被实时传输到 Kafka 主题中。
4. 使用 Kafka 的消费者从 Kafka 主题中读取数据。
```bash
./bin/kafka-console-consumer.sh --bootstrap-server kafka_host:port --topic clickhouse_topic --from-beginning
```
上述命令会从 Kafka 主题中读取数据并输出到控制台。
### 5.3 使用 Flume 进行数据导出的方法与示例
Flume 可以将数据从源头(如应用、服务器、设备等)传输到 ClickHouse 中,以实现数据的实时导出。
以下是使用 Flume 进行数据导出的详细步骤:
1. 首先,确保 Flume 已经正确安装和配置,并且配置好从源头收集数据的 Flume 代理。
2. 在 Flume 的配置文件中,指定 ClickHouse Sink,用于将数据导出到 ClickHouse。
```properties
agent.sinks.clickhouseSink.type = org.apache.flume.sink.clickhouse.ClickHouseSink
agent.sinks.clickhouseSink.clickhouseNodes = clickhouse_host:port
agent.sinks.clickhouseSink.clickhouseDatabase = clickhouse_database
agent.sinks.clickhouseSink.clickhouseTable = clickhouse_table
```
上述配置指定了 ClickHouse Sink 的类型、ClickHouse 服务器的地址和端口、数据库和数据表的名称。
3. 启动 Flume 后,数据将从源头经过 Flume 抽取和转换,并发送到 ClickHouse。
### 5.4 使用 Spark 进行数据导出的方法与示例
Spark 可以通过读取 ClickHouse 中的数据,并进行进一步的处理和导出。
以下是使用 Spark 进行数据导出的详细步骤:
1. 首先,确保 Spark 已经正确安装和配置,并且能够与 ClickHouse 进行交互。
2. 在 Spark 中使用 ClickHouse Connector,连接到 ClickHouse。
```python
from clickhouse_driver import Client
client = Client(host='clickhouse_host', port='clickhouse_port')
```
上述代码创建了一个 ClickHouse Connector 的实例,用于连接到 ClickHouse。
3. 使用 Spark SQL 查询数据,并将结果导出到目标文件或数据库。
```python
result = client.execute('SELECT * FROM test_table')
```
上述代码执行了一条 SQL 查询,并将结果存储在 `result` 变量中。
```python
client.execute('INSERT INTO another_table VALUES', result)
```
上述代码将查询结果插入到另一个表 `another_table` 中。
通过以上几个示例,我们介绍了 ClickHouse 结合第三方工具进行数据导出的方法和示例,包括使用 Kafka、Flume 和 Spark。根据实际需求,选择合适的工具和方式,可以更灵活和高效地进行数据导出。
# 6. 数据导入和导出的性能与优化
数据导入和导出是ClickHouse中非常重要的操作,可以直接影响到系统的性能和效率。在本章中,我们将探讨如何优化数据导入和导出的性能,并解决常见问题。
### 6.1 ClickHouse 数据导入性能优化方法
#### 6.1.1 合理选择数据导入工具
ClickHouse提供了多种数据导入工具,如内置导入工具、第三方工具等。在数据导入过程中,选择合适的工具对性能优化非常重要。根据数据源的不同,可以选择使用ClickHouse内置工具或者第三方工具来进行数据导入。
#### 6.1.2 使用批量插入
在数据导入过程中,使用批量插入的方式可以加快导入速度。ClickHouse支持一次性插入多条数据,通过指定多个数据值组成的数组,一次性插入到表中。这样可以减少网络传输和硬盘I/O的开销,提高数据导入的效率。
```python
# 示例代码:使用Python进行批量插入
from clickhouse_driver import Client
client = Client('localhost')
data = [
['Alice', 25, 'Female'],
['Bob', 30, 'Male'],
['Catherine', 35, 'Female']
]
query = 'INSERT INTO my_table (name, age, gender) VALUES'
for row in data:
values = f"('{row[0]}', {row[1]}, '{row[2]}')"
query += values + ','
query = query.rstrip(',') # 去除最后一个逗号
client.execute(query)
```
#### 6.1.3 使用并行导入
当数据量较大时,使用并行导入可以进一步提高数据导入速度。ClickHouse支持使用多个线程或者多个进程同时导入数据,可以将数据切分成多个部分,分别由不同的线程或者进程进行导入。
#### 6.1.4 优化表结构和数据格式
合理的表结构设计和选择合适的数据格式也可以提升数据导入性能。对于大规模数据导入,可以考虑使用MergeTree引擎,通过合理的分区策略和索引设计,降低数据写入的压力。
另外,选择合适的数据格式也很重要,如使用压缩格式或者二进制格式,可以减少磁盘空间的占用和读写的开销,进而提高导入速度。
#### 6.1.5 调整系统参数
在数据导入过程中,还可以通过调整ClickHouse的系统参数来进一步优化导入性能。例如,可以调整max_threads参数来增加并发线程数,提高数据导入的同时处理能力。
### 6.2 ClickHouse 数据导出性能优化方法
#### 6.2.1 合理选择数据导出工具
类似数据导入,数据导出也可以选择合适的工具来优化性能。ClickHouse提供了多种数据导出工具,如内置导出工具、第三方工具等。根据输出数据的需求,可以选择合适的工具进行数据导出。
#### 6.2.2 使用限制条件
在数据导出过程中,使用限制条件可以减少导出的数据量,提高导出速度。可以根据具体需求,使用WHERE子句来限制导出的数据范围,只导出特定时间段、特定条件下的数据。
#### 6.2.3 使用并行导出
对于大量数据的导出,可以考虑使用并行导出来提高速度。类似于数据导入中的并行导入,可以将数据切分成多个部分,由不同的线程或者进程同时导出,加快导出速度。
#### 6.2.4 优化输出格式和方式
选择合适的输出格式和方式也可以提升数据导出性能。例如,选择合适的压缩格式,可以减少输出文件的大小,降低磁盘IO开销。另外,可以选择直接输出到外部存储,如HDFS或者S3,减少网络传输的开销。
#### 6.2.5 调整系统参数
调整ClickHouse的系统参数也可以进一步优化数据导出性能。例如,可以调整max_threads参数来增加并发线程数,提高数据导出的同时处理能力。
### 6.3 数据导入和导出的常见问题及解决方法
在数据导入和导出过程中,可能会遇到一些常见的问题。例如,导入速度慢、导出数据过大等。下面列举一些常见问题及解决方法:
- 问题1:导入速度慢,导出时间长。
解决方法:可以通过使用批量插入、并行导入/导出、优化数据格式等方法来提高导入和导出速度。
- 问题2:导入错误或丢失部分数据。
解决方法:检查数据源是否正确,是否存在异常数据导致导入错误。确认数据导入过程中是否有异常中断导致数据丢失。也可以查看ClickHouse的日志文件,了解具体错误信息。
- 问题3:数据导出过大,占用过多磁盘空间。
解决方法:可以考虑使用压缩格式来减少输出文件的大小。另外,根据具体需求,选择合适的数据范围进行导出,避免导出不必要的数据。
- 问题4:导出速度较慢,导出任务阻塞。
解决方法:可以调整系统参数,增加导出任务的同时处理能力。同时,查看导出任务的日志文件,了解是否存在其他系统资源瓶颈或异常问题。
以上是关于ClickHouse数据导入和导出性能优化的一些方法和常见问题及解决方法的介绍。通过合理的选择工具、优化表结构和数据格式、调整系统参数等方式,可以提高数据导入和导出的效率和性能。同时,注意问题排查和异常处理,能够更好地应对数据导入和导出过程中的各种情况。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以ClickHouse为主题,深入探讨了这一大数据分析数据库的各个方面。从简介及安装指南、数据导入和导出方法、基本数据类型解析,到查询优化、性能调优、表引擎和数据结构比较,再到数据分区策略优化、数据备份与恢复方法,对象级权限管理和安全性配置指南,以及各种表引擎的详细解析等内容,覆盖了ClickHouse的方方面面。此外,还包括了数据仓库设计最佳实践与范式化、HLL算法在基数统计中的应用、近似计算函数使用案例,以及分布式集群配置和管理指南、数据压缩与存储优化等更加深入的话题。此外,还包括了常用函数详解和应用案例,实时数据处理与流式计算实践,以及和异构数据源集成方法等实际应用。无论是对ClickHouse的初学者还是有经验的用户,都能在本专栏中找到对自己有价值的内容,是一份全面而深入的ClickHouse学习指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
随机搜索在强化学习算法中的应用

# 1. 强化学习算法基础
强化学习是一种机器学习方法,侧重于如何基于环境做出决策以最大化某种累积奖励。本章节将为读者提供强化学习算法的基础知识,为后续章节中随机搜索与强化学习结合的深入探讨打下理论基础。
## 1.1 强化学习的概念和框架
强化学习涉及智能体(Agent)与环境(Environment)之间的交互。智能体通过执行动作(Action)影响环境,并根据环境的反馈获得奖
深度学习的正则化探索:L2正则化应用与效果评估

# 1. 深度学习中的正则化概念
## 1.1 正则化的基本概念
在深度学习中,正则化是一种广泛使用的技术,旨在防止模型过拟合并提高其泛化能力
贝叶斯优化软件实战:最佳工具与框架对比分析
# 1. 贝叶斯优化的基础理论
贝叶斯优化是一种概率模型,用于寻找给定黑盒函数的全局最优解。它特别适用于需要进行昂贵计算的场景,例如机器学习模型的超参数调优。贝叶斯优化的核心在于构建一个代理模型(通常是高斯过程),用以估计目标函数的行为,并基于此代理模型智能地选择下一点进行评估。
## 2.1 贝叶斯优化的基本概念
### 2.1.1 优化问题的数学模型
贝叶斯优化的基础模型通常包括目标函数 \(f(x)\),目标函数的参数空间 \(X\) 以及一个采集函数(Acquisition Function),用于决定下一步的探索点。目标函数 \(f(x)\) 通常是在计算上非常昂贵的,因此需
大规模深度学习系统:Dropout的实施与优化策略
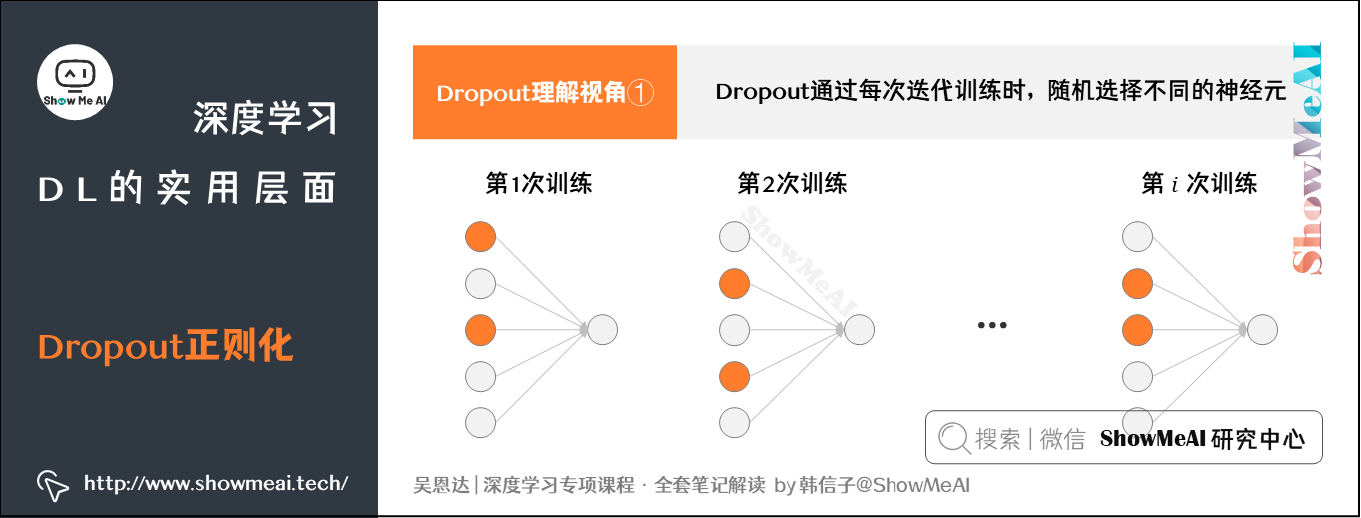
# 1. 深度学习与Dropout概述
在当前的深度学习领域中,Dropout技术以其简单而强大的能力防止神经网络的过拟合而著称。本章旨在为读者提供Dropout技术的初步了解,并概述其在深度学习中的重要性。我们将从两个方面进行探讨:
首先,将介绍深度学习的基本概念,明确其在人工智能中的地位。深度学习是模仿人脑处理信息的机制,通过构建多层的人工神经网络来学习数据的高层次特征,它已
网格搜索:多目标优化的实战技巧

# 1. 网格搜索技术概述
## 1.1 网格搜索的基本概念
网格搜索(Grid Search)是一种系统化、高效地遍历多维空间参数的优化方法。它通过在每个参数维度上定义一系列候选值,并
L1正则化模型诊断指南:如何检查模型假设与识别异常值(诊断流程+案例研究)

# 1. L1正则化模型概述
L1正则化,也被称为Lasso回归,是一种用于模型特征选择和复杂度控制的方法。它通过在损失函数中加入与模型权重相关的L1惩罚项来实现。L1正则化的作用机制是引导某些模型参数缩小至零,使得模型在学习过程中具有自动特征选择的功能,因此能够产生更加稀疏的模型。本章将从L1正则化的基础概念出发,逐步深入到其在机器学习中的应用和优势
机器学习调试实战:分析并优化模型性能的偏差与方差
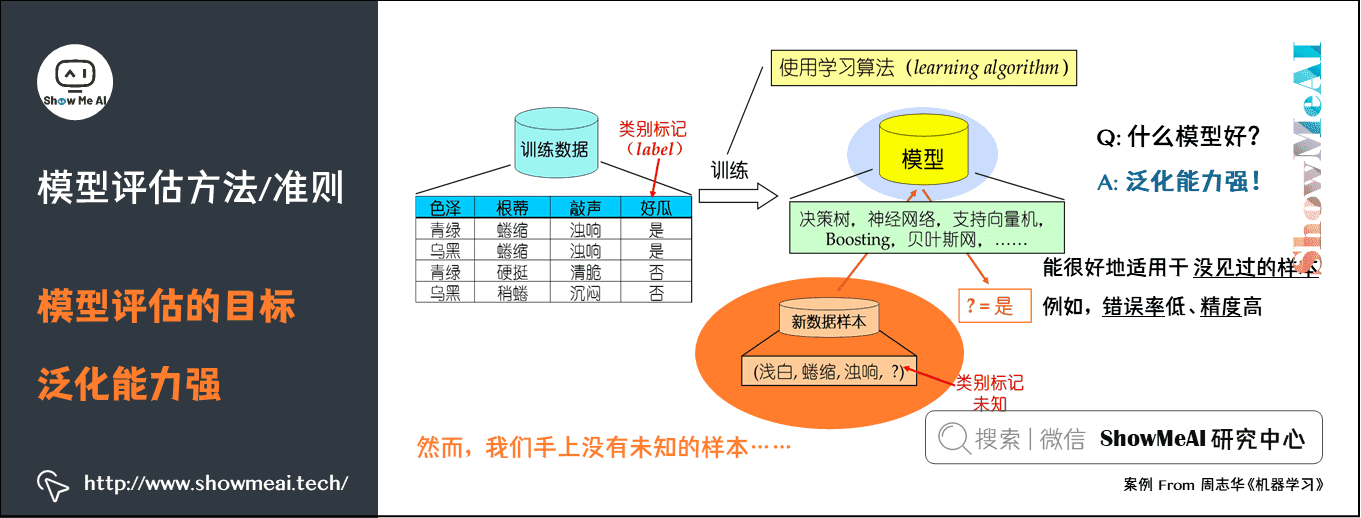
# 1. 机器学习调试的概念和重要性
## 什么是机器学习调试
机器学习调试是指在开发机器学习模型的过程中,通过识别和解决模型性能不佳的问题来改善模型预测准确性的过程。它是模型训练不可或缺的环节,涵盖了从数据预处理到最终模型部署的每一个步骤。
## 调试的重要性
有效的调试能够显著提高模型的泛化能力,即在未见过的数据上也能作出准确预测的能力。没有经过适当调试的模型可能无法应对实
注意力机制与过拟合:深度学习中的关键关系探讨

# 1. 深度学习的注意力机制概述
## 概念引入
注意力机制是深度学习领域的一种创新技术,其灵感来源于人类视觉注意力的生物学机制。在深度学习模型中,注意力机制能够使模型在处理数据时,更加关注于输入数据中具有关键信息的部分,从而提高学习效率和任务性能。
## 重要性解析
特征贡献的Shapley分析:深入理解模型复杂度的实用方法
# 1. 特征贡献的Shapley分析概述
在数据科学领域,模型解释性(Model Explainability)是确保人工智能(AI)应用负责任和可信赖的关键因素。机器学习模型,尤其是复杂的非线性模型如深度学习,往往被认为是“黑箱”,因为它们的内部工作机制并不透明。然而,随着机器学习越来越多地应用于关键决策领域,如金融风控、医疗诊断和交通管理,理解模型的决策过程变得至关重要
图像处理中的正则化应用:过拟合预防与泛化能力提升策略

# 1. 图像处理与正则化概念解析
在现代图像处理技术中,正则化作为一种核心的数学工具,对图像的解析、去噪、增强以及分割等操作起着至关重要
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )