ClickHouse 中的基本数据类型解析
发布时间: 2023-12-20 14:34:47 阅读量: 14 订阅数: 13 
## 第一章:ClickHouse 数据类型概述
### 1.1 简介
ClickHouse 是一个面向OLAP场景的开源分布式列式数据库管理系统,在处理大规模数据分析时有着卓越的性能表现。在 ClickHouse 中,数据类型是十分重要的,它直接关系到数据的存储、计算和查询效率。
### 1.2 数据类型分类
ClickHouse 中的数据类型可以分为数值类型、日期和时间类型、字符串类型、枚举与数组类型等。每种数据类型都有其特定的用途和存储特性。
### 1.3 数据类型的作用和影响
不同的数据类型对数据存储空间、计算性能和查询效率都有着不同的影响。合理选择和使用数据类型可以提高系统的整体性能和稳定性。因此,深入理解各种数据类型的特点和使用场景对于高效地使用 ClickHouse 是至关重要的。
当然可以,请查看以下关于【ClickHouse 中的基本数据类型解析】文章的第二章节的Markdown格式内容:
## 第二章:数值类型分析
2.1 整数类型
2.2 浮点类型
2.3 小数类型
### 第三章:日期和时间类型探讨
在 ClickHouse 中,日期和时间类型是非常重要的数据类型,用于存储和处理日期、时间、日期时间等信息。接下来我们将详细探讨这些类型的特点、用法和影响。
#### 3.1 日期类型
日期类型在 ClickHouse 中使用 `Date` 表示,它是一个以固定长度的整数来存储的。日期类型的存储范围是从公元前32767年到公元32000年,精度为一天。我们可以使用日期类型进行日期的计算、比较和运算操作。
```sql
-- 创建日期类型列
CREATE TABLE date_table
(
event_date Date
) ENGINE = MergeTree()
ORDER BY event_date;
-- 插入日期数据
INSERT INTO date_table
VALUES
('2022-12-01'),
('2023-01-15'),
('2023-05-20');
-- 查询日期数据
SELECT *
FROM date_table
ORDER BY event_date;
```
#### 3.2 时间类型
时间类型在 ClickHouse 中使用 `DateTime` 表示,它包含日期和时间,并以固定长度的整数存储。时间类型的存储范围是从公元前32767年到公元32000年,精度为微秒级。我们可以使用时间类型进行时间的计算、比较和运算操作。
```sql
-- 创建时间类型列
CREATE TABLE time_table
(
event_time DateTime
) ENGINE = MergeTree()
ORDER BY event_time;
-- 插入时间数据
INSERT INTO time_table
VALUES
('2022-12-01 12:30:00'),
('2023-01-15 18:45:00'),
('2023-05-20 09:15:00');
-- 查询时间数据
SELECT *
FROM time_table
ORDER BY event_time;
```
#### 3.3 日期时间类型
日期时间类型在 ClickHouse 中由 `DateTime` 表示,它包含日期和时间,并以固定长度的整数存储。日期时间类型的存储范围和精度与时间类型相同。我们可以使用日期时间类型进行日期时间的计算、比较和运算操作。
```sql
-- 创建日期时间类型列
CREATE TABLE datetime_table
(
event_datetime DateTime
) ENGINE = MergeTree()
ORDER BY event_datetime;
-- 插入日期时间数据
INSERT INTO datetime_table
VALUES
('2022-12-01 12:30:00'),
('2023-01-15 18:45:00'),
('2023-05-20 09:15:00');
-- 查询日期时间数据
SELECT *
FROM datetime_table
ORDER BY event_datetime;
```
以上便是关于 ClickHouse 中的日期和时间类型的详细探讨。在实际应用中,合理使用这些类型可以更高效地处理日期时间相关的数据,为数据分析和应用提供更强大的支持。
### 第四章:字符串类型详解
在这一章节中,我们将深入探讨ClickHouse中的字符串类型,包括定长字符串、变长字符串以及字符串的编码和排序。通过本章的学习,读者将能够全面了解ClickHouse中字符串类型的特性和应用场景。接下来,让我们一起开始吧。
#### 4.1 定长字符串
定长字符串在ClickHouse中使用`FixedString(n)`来表示,其中`n`表示字符串的固定长度。这种类型的字符串在长度上有一定的限制,但由于长度固定,可以更加高效地存储和处理数据。在实际应用中,定长字符串适合于长度固定的字段,如身份证号、固定长度的编码等。下面是一个示例:
```sql
-- 创建包含定长字符串的示例表
CREATE TABLE fixed_string_example
(
id UInt32,
name FixedString(10),
age UInt8
) ENGINE = MergeTree() ORDER BY id;
-- 插入数据
INSERT INTO fixed_string_example VALUES (1, 'John ', 25);
INSERT INTO fixed_string_example VALUES (2, 'Alice ', 30);
```
在上述示例中,`name`字段使用了`FixedString(10)`类型,表示名字是一个固定长度为10的字符串。这样设计可以确保存储和检索数据更加高效。
#### 4.2 变长字符串
与定长字符串相对应的是变长字符串,ClickHouse中使用`String`类型来表示变长字符串。这种类型的字符串长度可以在一定范围内变化,更加灵活适用于存储长度不固定的文本数据。下面是一个示例:
```sql
-- 创建包含变长字符串的示例表
CREATE TABLE variable_string_example
(
id UInt32,
content String,
create_time DateTime
) ENGINE = MergeTree() ORDER BY create_time;
-- 插入数据
INSERT INTO variable_string_example VALUES (1, 'This is a variable length string', '2022-01-01 12:00:00');
INSERT INTO variable_string_example VALUES (2, 'Another example', '2022-01-02 15:30:00');
```
在上述示例中,`content`字段使用了`String`类型,可以灵活存储不固定长度的文本数据,适用于各种长度的字符串存储场景。
#### 4.3 字符串的编码和排序
在ClickHouse中,字符串类型的数据可以使用不同的编码方式来存储,以提高存储和查询性能。常用的字符串编码方式包括`UTF-8`、`ASCII`等。另外,字符串的排序方式也是我们需要考虑的问题,不同的排序方式会影响到查询结果的准确性和效率。
```sql
-- 示例表中字符串字段的编码和排序设置
CREATE TABLE string_encoding_example
(
id UInt32,
title String CODEC(ZSTD),
category String CODEC(DICT(8)),
create_date Date
) ENGINE = MergeTree() ORDER BY create_date;
-- 插入数据
INSERT INTO string_encoding_example VALUES (1, 'ClickHouse', 'Database', '2022-01-01');
INSERT INTO string_encoding_example VALUES (2, 'Data', 'Analysis', '2022-01-02');
```
在上述示例中,`title`字段使用了`ZSTD`编码,`category`字段使用了`DICT(8)`编码。通过合理设置编码和排序方式,可以有效提升字符串类型数据存储和查询的性能。
通过本章的学习,读者不仅了解了ClickHouse中字符串类型的基本概念和使用方法,还掌握了字符串类型数据存储和处理的最佳实践。字符串作为最常见的数据类型之一,其重要性不言而喻。在实际工作中,合理地选择和使用字符串类型,可以为数据存储和查询带来显著的效率提升。
### 5. 第五章:枚举与数组类型剖析
在 ClickHouse 中,枚举和数组类型是常用的复合数据类型,用于表示一组有限取值范围内的元素或者一组相同类型的值的集合。本章将详细探讨枚举和数组类型的定义、存储结构及应用场景。
#### 5.1 枚举类型
- **定义与创建枚举类型**
在 ClickHouse 中,可以通过 `Enum` 关键字定义枚举类型。以下是一个创建枚举类型的示例:
```sql
CREATE TYPE WeekdayEnum AS Enum('Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday');
```
- **枚举类型的应用**
枚举类型在数据仓库中经常用于表示一组固定的取值范围,例如星期几、状态等。在数据表中,可以将某一列的数据类型定义为枚举类型,从而限定该列的取值范围,提高数据的规范性和查询效率。
#### 5.2 数组类型
- **定义与创建数组类型**
数组类型用于存储相同类型的多个数值,通过 `Array` 关键字定义数组类型。以下是一个创建数组类型的示例:
```sql
CREATE TYPE IntArray AS Array(Int32);
```
- **数组类型的应用**
数组类型在数据存储和分析中非常常见,例如存储用户的兴趣爱好、商品的标签等。使用数组类型可以将多个数值以一种紧凑的形式存储在单个字段中,避免了数据冗余和复杂的关联查询,提高了数据的存储效率和查询性能。
#### 5.3 复合类型
除了枚举和数组类型外,ClickHouse 还支持复合类型,例如元组(Tuple)、结构体(Nested)等。这些复合类型在处理半结构化数据或者多字段关联查询时非常有用,能够更好地组织和管理数据。
在实际应用中,枚举和数组类型以及复合类型的选择取决于数据的特性和业务需求,合理选择合适的复合类型可以提高数据的存储效率和查询性能。
### 6. 第六章:自定义类型与用户自定义函数(UDF)
在 ClickHouse 中,除了内置的数据类型外,还支持用户自定义类型(UDT)和用户自定义函数(UDF)。这使得用户可以根据自身业务需求来扩展 ClickHouse 的数据类型和函数库。
#### 6.1 自定义类型的定义与使用
用户可以通过`CREATE TYPE`语句来定义自定义类型。例如,我们可以定义一个表示坐标的自定义类型:
```sql
CREATE TYPE Point AS (x Float64, y Float64);
```
定义完成后,就可以在数据表中使用这个自定义类型了:
```sql
CREATE TABLE points (
id UInt32,
location Point
) ENGINE = MergeTree ORDER BY id;
```
在插入数据时,也可以直接使用自定义类型:
```sql
INSERT INTO points VALUES (1, (10.5, 20.7));
```
#### 6.2 用户自定义函数(UDF)的编写与应用
用户可以使用 C++ 或者其他支持 ClickHouse UDF 的语言来编写自定义函数。假设我们需要一个函数来计算两个点之间的距离:
```cpp
#include <cmath>
#include <DB/Common/Exception.h>
using namespace DB;
extern "C"
double distance(const Float64 x1, const Float64 y1, const Float64 x2, const Float64 y2)
{
double dx = x2 - x1;
double dy = y2 - y1;
return std::sqrt(dx * dx + dy * dy);
}
```
然后通过以下 SQL 语句注册这个函数:
```sql
CREATE FUNCTION distance AS 'path/to/distance.so' DLL;
```
最后,我们就可以在 SQL 中使用这个自定义函数了:
```sql
SELECT id, distance(location.x, location.y, 0, 0) AS distance_from_origin FROM points;
```
#### 6.3 总结与展望
自定义类型和用户自定义函数为 ClickHouse 提供了灵活的扩展能力,能够满足更多特定业务场景下的需求。未来,随着 ClickHouse 生态系统的不断丰富,用户自定义类型和函数将发挥出更大的作用。
0
0
相关推荐

专栏简介
本专栏以ClickHouse为主题,深入探讨了这一大数据分析数据库的各个方面。从简介及安装指南、数据导入和导出方法、基本数据类型解析,到查询优化、性能调优、表引擎和数据结构比较,再到数据分区策略优化、数据备份与恢复方法,对象级权限管理和安全性配置指南,以及各种表引擎的详细解析等内容,覆盖了ClickHouse的方方面面。此外,还包括了数据仓库设计最佳实践与范式化、HLL算法在基数统计中的应用、近似计算函数使用案例,以及分布式集群配置和管理指南、数据压缩与存储优化等更加深入的话题。此外,还包括了常用函数详解和应用案例,实时数据处理与流式计算实践,以及和异构数据源集成方法等实际应用。无论是对ClickHouse的初学者还是有经验的用户,都能在本专栏中找到对自己有价值的内容,是一份全面而深入的ClickHouse学习指南。
专栏目录
最低0.47元/天 解锁专栏
15个月+AI工具集
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB圆形Airy光束前沿技术探索:解锁光学与图像处理的未来

# 2.1 Airy函数及其性质
Airy函数是一个特殊函数,由英国天文学家乔治·比德尔·艾里(George Biddell Airy)于1838年首次提出。它在物理学和数学中
【未来人脸识别技术发展趋势及前景展望】: 展望未来人脸识别技术的发展趋势和前景
# 1. 人脸识别技术的历史背景
人脸识别技术作为一种生物特征识别技术,在过去几十年取得了长足的进步。早期的人脸识别技术主要基于几何学模型和传统的图像处理技术,其识别准确率有限,易受到光照、姿态等因素的影响。随着计算机视觉和深度学习技术的发展,人脸识别技术迎来了快速的发展时期。从简单的人脸检测到复杂的人脸特征提取和匹配,人脸识别技术在安防、金融、医疗等领域得到了广泛应用。未来,随着人工智能和生物识别技术的结合,人脸识别技术将呈现更广阔的发展前景。
# 2. 人脸识别技术基本原理
人脸识别技术作为一种生物特征识别技术,基于人脸的独特特征进行身份验证和识别。在本章中,我们将深入探讨人脸识别技
爬虫与云计算:弹性爬取,应对海量数据

# 1. 爬虫技术概述**
爬虫,又称网络蜘蛛,是一种自动化程序,用于从网络上抓取和提取数据。其工作原理是模拟浏览器行为,通过HTTP请求获取网页内容,并
【高级数据可视化技巧】: 动态图表与报告生成
# 1. 认识高级数据可视化技巧
在当今信息爆炸的时代,数据可视化已经成为了信息传达和决策分析的重要工具。学习高级数据可视化技巧,不仅可以让我们的数据更具表现力和吸引力,还可以提升我们在工作中的效率和成果。通过本章的学习,我们将深入了解数据可视化的概念、工作流程以及实际应用场景,从而为我们的数据分析工作提供更多可能性。
在高级数据可视化技巧的学习过程中,首先要明确数据可视化的目标以及选择合适的技巧来实现这些目标。无论是制作动态图表、定制报告生成工具还是实现实时监控,都需要根据需求和场景灵活运用各种技巧和工具。只有深入了解数据可视化的目标和调用技巧,才能在实践中更好地应用这些技术,为数据带来
【人工智能与扩散模型的融合发展趋势】: 探讨人工智能与扩散模型的融合发展趋势

# 1. 人工智能与扩散模型简介
人工智能(Artificial Intelligence,AI)是一种模拟人类智能思维过程的技术,其应用已经深入到各行各业。扩散模型则是一种描述信息、疾病或技术在人群中传播的数学模型。人工智能与扩散模型的融合,为预测疾病传播、社交媒体行为等提供了新的视角和方法。通过人工智能的技术,可以更加准确地预测扩散模型的发展趋势,为各
MATLAB稀疏阵列在自动驾驶中的应用:提升感知和决策能力,打造自动驾驶新未来
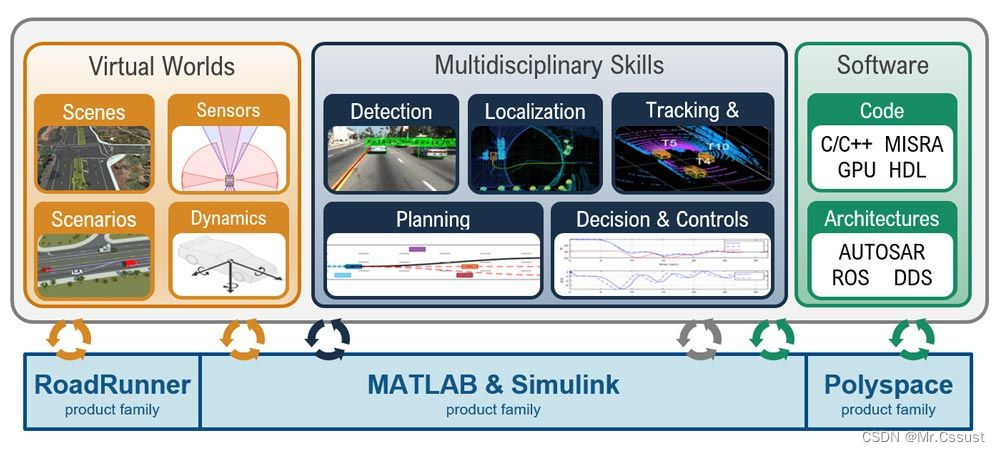
# 1. MATLAB稀疏阵列基础**
MATLAB稀疏阵列是一种专门用于存储和处理稀疏数据的特殊数据结构。稀疏数据是指其中大部分元素为零的矩阵。MATLAB稀疏阵列通过只存储非零元素及其索引来优化存储空间,从而提高计算效率。
MATLAB稀疏阵列的创建和操作涉及以下关键概念:
* **稀疏矩阵格式:**MATLAB支持多种稀疏矩阵格式,包括CSR(压缩行存
【YOLO目标检测中的未来趋势与技术挑战展望】: 展望YOLO目标检测中的未来趋势和技术挑战
# 1. YOLO目标检测简介
目标检测作为计算机视觉领域的重要任务之一,旨在从图像或视频中定位和识别出感兴趣的目标。YOLO(You Only Look Once)作为一种高效的目标检测算法,以其快速且准确的检测能力而闻名。相较于传统的目标检测算法,YOLO将目标检测任务看作一个回归问题,通过将图像划分为网格单元进行预测,实现了实时目标检测的突破。其独特的设计思想和算法架构为目标检测领域带来了革命性的变革,极大地提升了检测的效率和准确性。
在本章中,我们将深入探讨YOLO目标检测算法的原理和工作流程,以及其在目标检测领域的重要意义。通过对YOLO算法的核心思想和特点进行解读,读者将能够全
:YOLO目标检测算法的挑战与机遇:数据质量、计算资源与算法优化,探索未来发展方向
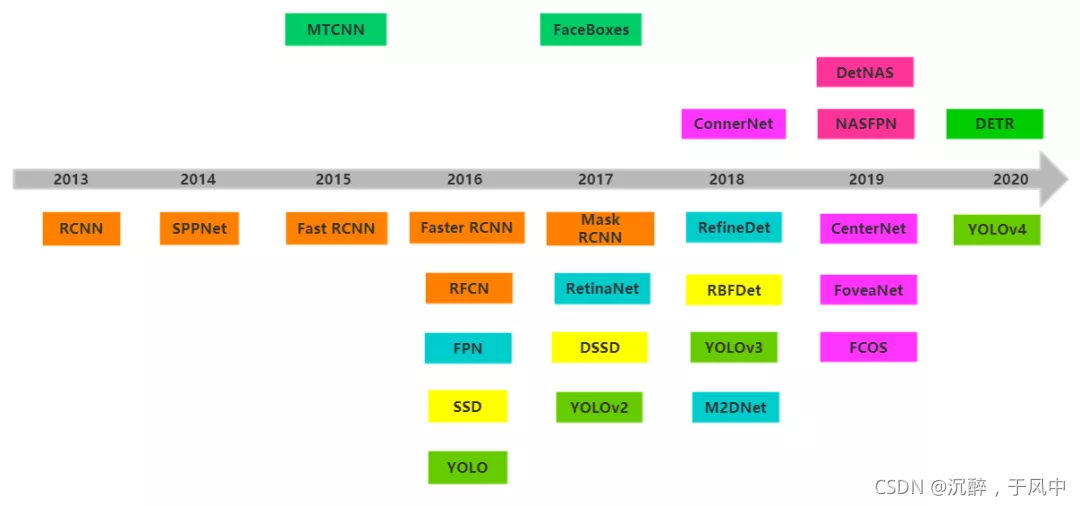
# 1. YOLO目标检测算法简介
YOLO(You Only Look Once)是一种
卡尔曼滤波MATLAB代码在预测建模中的应用:提高预测准确性,把握未来趋势
# 1. 卡尔曼滤波简介**
卡尔曼滤波是一种递归算法,用于估计动态系统的状态,即使存在测量噪声和过程噪声。它由鲁道夫·卡尔曼于1960年提出,自此成为导航、控制和预测等领域广泛应用的一种强大工具。
卡尔曼滤波的基本原理是使用两个方程组:预测方程和更新方程。预测方程预测系统状态在下一个时间步长的值,而更新方程使用测量值来更新预测值。通过迭代应用这两个方程,卡尔曼滤波器可以提供系统状态的连续估计,即使在存在噪声的情况下也是如此。
# 2. 卡尔曼滤波MATLAB代码
### 2.1 代码结构和算法流程
卡尔曼滤波MATLAB代码通常遵循以下结构:
```mermaid
graph L
【未来发展趋势下的车牌识别技术展望和发展方向】: 展望未来发展趋势下的车牌识别技术和发展方向

# 1. 车牌识别技术简介
车牌识别技术是一种通过计算机视觉和深度学习技术,实现对车牌字符信息的自动识别的技术。随着人工智能技术的飞速发展,车牌识别技术在智能交通、安防监控、物流管理等领域得到了广泛应用。通过车牌识别技术,可以实现车辆识别、违章监测、智能停车管理等功能,极大地提升了城市管理和交通运输效率。本章将从基本原理、相关算法和技术应用等方面介绍
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
15个月+AI工具集
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )