Scrapy框架的性能优化与扩展技巧
发布时间: 2024-02-15 11:12:05 阅读量: 12 订阅数: 13 
# 1. Scrapy框架概述
## 1.1 简介Scrapy框架
Scrapy是一个使用Python编写的开源网络爬虫框架,可用于快速高效地抓取并处理大量互联网数据。它提供了简洁而强大的工具和API,使开发者能够轻松构建自己的爬虫应用。
## 1.2 Scrapy框架优势分析
Scrapy具有以下几个明显的优势:
- 高效性能:Scrapy采用异步的网络请求方式,能够快速地并发请求多个网页,提高爬取效率。
- 丰富的扩展性:Scrapy提供了中间件和自定义扩展组件的机制,使开发者能够根据需求灵活地进行功能扩展。
- 稳定可靠:Scrapy框架内置了重试、错误处理、请求过滤等机制,可以保证爬虫的稳定运行。
- 方便的数据处理:Scrapy支持XPath和CSS选择器等多种数据提取方式,能够方便地对爬取到的数据进行处理和解析。
## 1.3 Scrapy框架的基本组件
Scrapy框架主要包含以下几个基本组件:
- Spiders(爬虫):定义了如何抓取特定网站的信息,包括起始URL、如何跟进链接以及如何抽取数据等。
- Item Pipelines(管道):负责处理从爬虫中抽取出的数据,进行后续的处理、过滤、存储等操作。
- Downloader(下载器):负责发出和处理网页的下载请求,将下载下来的网页内容返回给爬虫。
- Scheduler(调度器):维护着一个待爬取URL的队列,并负责在合适的时机将URL交给下载器进行下载。
- Middleware(中间件):对Scrapy的请求和响应进行预处理和后处理,提供额外的功能扩展。
以上是Scrapy框架概述部分的内容,后续章节将详细介绍性能优化和扩展技巧等内容。
# 2. 性能优化基础知识
在使用Scrapy框架进行Web抓取任务时,性能优化是一个重要的考虑因素。本章将介绍一些性能优化的基础知识,包括网页抓取性能分析、数据处理性能优化以及网络请求处理性能优化。
### 2.1 网页抓取性能分析
对于一个高效的Web抓取任务,我们需要从以下几个方面进行性能分析,并通过优化来提升性能:
1. **网络延迟**:网络延迟是指从发送请求到接收到响应所需的时间。可以通过减少网络请求次数、使用CDN等方式来降低延迟。
2. **数据传输量**:数据传输量越大,抓取速度越慢。可以通过压缩传输的数据、减少不必要的请求和资源加载来减少传输量。
3. **资源加载时间**:网页中的各个资源(图片、样式表、脚本等)加载时间也会影响抓取速度。可以通过对资源进行拼接、合并和缓存等方式来减少加载时间。
### 2.2 数据处理性能优化
Scrapy框架在抓取过程中会涉及到大量的数据处理操作,如数据解析、筛选和存储等。以下是一些提升数据处理性能的优化技巧:
1. **选择合适的解析器**:对于HTML解析,可以选择高性能的解析器,如lxml或BeautifulSoup,以提升解析速度。
2. **使用多线程或异步处理**:对于耗时的数据处理操作,可以使用多线程或异步处理来提升效率。可以借助Python的concurrent.futures库或使用异步框架如asyncio来实现。
3. **使用缓存**:对于重复的数据处理操作,可以使用缓存来避免重复计算,提升性能。可以使用内存缓存如Redis或使用持久化缓存如Memcached。
### 2.3 网络请求处理性能优化
Scrapy框架的核心功能之一是发起网络请求并处理响应。以下是一些提升网络请求处理性能的优化技巧:
1. **并发请求**:可以通过设置并发数来同时发起多个请求,以提高抓取速度。可以通过调整Scrapy框架的并发数配置来实现。
2. **下载延迟控制**:合理调整下载延迟时间,避免对网站造成过大的压力,同时也可以提高抓取速度。可以使用Scrapy框架中的DOWNLOAD_DELAY配置项进行控制。
3. **使用代理IP**:对于一些反爬虫策略较强的网站,可以通过使用代理IP来绕过限制,提高抓取成功率。
总结:通过对网络延迟、数据处理性能和网络请求处理性能的优化,可以显著提高Scrapy框架的抓取性能。在实际应用中,需要综合考虑并针对具体抓取任务进行性能优化,以达到更高效的抓取效果。
# 3. Scrapy框架的性能优化技巧
Scrapy框架在进行网页抓取的过程中,可以通过一些技巧来提高性能,从而更加高效地完成数据获取任务。本章将介绍一些常见的Scrapy框架性能优化技巧。
#### 3.1 并发请求优化
在进行大规模数据爬取时,提升并发请求的能力可以大大加快数据抓取速度。下面是一些优化并发请求的方法:
1. 调整`CONCURRENT_REQUESTS`参数:`CONCURRENT_REQUESTS`参数控制同时进行的请求数量,默认为16。可以根据服务器的性能和网络情况将其调整为较大的值,增加并发能力。
```python
# settings.py
CONCURRENT_REQUESTS = 32
```
2. 使用异步方式发送请求:Scrapy提供了`asyncio`和`twisted`等方式来实现异步网络请求,可以极大地提高并发能力。
```python
# items.py
import scrapy
class MySpider(scrapy.Spider):
name = "my_spider"
start_urls = [
"http://www.example.com/page1",
"http://www.example.com/page2",
"http://www.e
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 VIP年卡限时特惠
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"Scrapy框架核心原理实战解析"为主题,深入探讨了Scrapy框架的核心组件及其原理,并结合实际案例展示了如何使用Scrapy框架进行数据抓取和处理。从Scrapy框架的初探和基本概念开始,逐步展开到爬虫中间件、Downloader Middleware、Pipeline等核心原理的解析和实践。此外,还介绍了Scrapy框架的分布式爬虫实现原理、与Selenium集成、日志处理与调试技巧、与Docker容器技术结合实践等内容。同时,特别关注Scrapy框架在大数据处理、与Elasticsearch的高效集成、机器学习数据采集以及自然语言处理中的应用。通过本专栏的学习,读者将深入了解Scrapy框架的核心原理,并掌握其在实际项目中的应用技巧和解决方案。
专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB符号数组:解析符号表达式,探索数学计算新维度

# 1. MATLAB 符号数组简介**
MATLAB 符号数组是一种强大的工具,用于处理符号表达式和执行符号计算。符号数组中的元素可以是符
MATLAB求平均值在社会科学研究中的作用:理解平均值在社会科学数据分析中的意义

# 1. 平均值在社会科学中的作用
平均值是社会科学研究中广泛使用的一种统计指标,它可以提供数据集的中心趋势信息。在社会科学中,平均值通常用于描述人口特
深入了解MATLAB开根号的最新研究和应用:获取开根号领域的最新动态

# 1. MATLAB开根号的理论基础
开根号运算在数学和科学计算中无处不在。在MATLAB中,开根号可以通过多种函数实现,包括`sqrt()`和`nthroot()`。`sqrt()`函数用于计算正实数的平方根,而`nt
MATLAB字符串拼接与财务建模:在财务建模中使用字符串拼接,提升分析效率

# 1. MATLAB 字符串拼接基础**
字符串拼接是 MATLAB 中一项基本操作,用于将多个字符串连接成一个字符串。它在财务建模中有着广泛的应用,例如财务数据的拼接、财务公式的表示以及财务建模的自动化。
MATLAB 中有几种字符串拼接方法,包括 `+` 运算符、`strcat` 函数和 `sprintf` 函数。`+` 运算符是最简单的拼接
MATLAB柱状图在信号处理中的应用:可视化信号特征和频谱分析

# 1. MATLAB柱状图概述**
MATLAB柱状图是一种图形化工具,用于可视化数据中不同类别或组的分布情况。它通过绘制垂直条形来表示每个类别或组中的数据值。柱状图在信号处理中广泛用于可视化信号特征和进行频谱分析。
柱状图的优点在于其简单易懂,能够直观地展示数据分布。在信号处理中,柱状图可以帮助工程师识别信号中的模式、趋势和异常情况,从而为信号分析和处理提供有价值的见解。
# 2. 柱状图在信号处理中的应用
柱状图在信号处理
MATLAB在图像处理中的应用:图像增强、目标检测和人脸识别
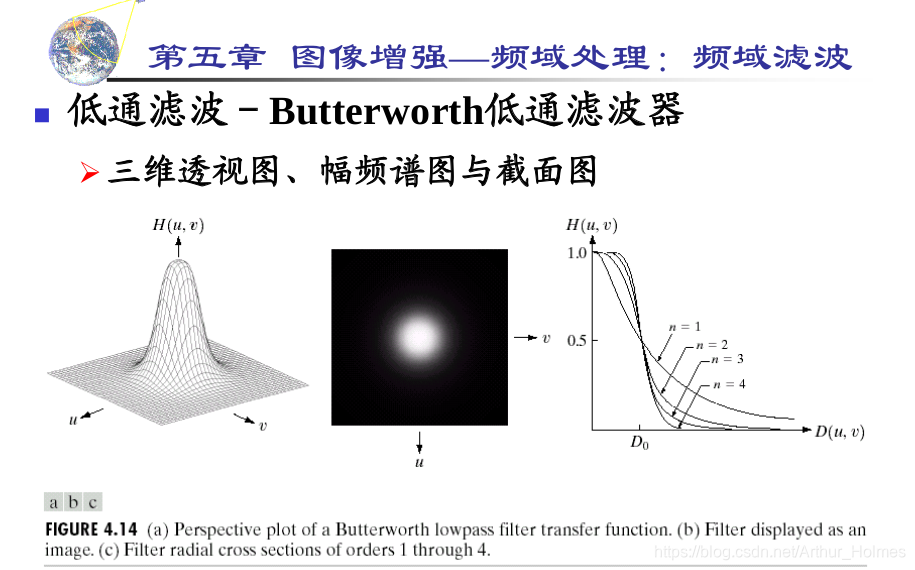
# 1. MATLAB图像处理概述
MATLAB是一个强大的技术计算平台,广泛应用于图像处理领域。它提供了一系列内置函数和工具箱,使工程师
图像处理中的求和妙用:探索MATLAB求和在图像处理中的应用

# 1. 图像处理简介**
图像处理是利用计算机对图像进行各种操作,以改善图像质量或提取有用信息的技术。图像处理在各个领域都有广泛的应用,例如医学成像、遥感、工业检测和计算机视觉。
图像由像素组成,每个像素都有一个值,表示该像素的颜色或亮度。图像处理操作通常涉及对这些像素值进行数学运算,以达到增强、分
MATLAB散点图:使用散点图进行信号处理的5个步骤
# 1. MATLAB散点图简介
散点图是一种用于可视化两个变量之间关系的图表。它由一系列数据点组成,每个数据点代表一个数据对(x,y)。散点图可以揭示数据中的模式和趋势,并帮助研究人员和分析师理解变量之间的关系。
在MATLAB中,可以使用`scatter`函数绘制散点图。`scatter`函数接受两个向量作为输入:x向量和y向量。这些向量必须具有相同长度,并且每个元素对(x,y)表示一个数据点。例如,以下代码绘制
MATLAB平方根硬件加速探索:提升计算性能,拓展算法应用领域

# 1. MATLAB 平方根计算基础**
MATLAB 提供了 `sqrt()` 函数用于计算平方根。该函数接受一个实数或复数作为输入,并返回其平方根。`sqrt()` 函数在 MATLAB 中广泛用于各种科学和工程应用中,例如信号处理、图像处理和数值计算。
**代码块:**
```matlab
% 计算实数的平方根
x = 4;
sqrt_x = sqrt(x);
%
NoSQL数据库实战:MongoDB、Redis、Cassandra深入剖析
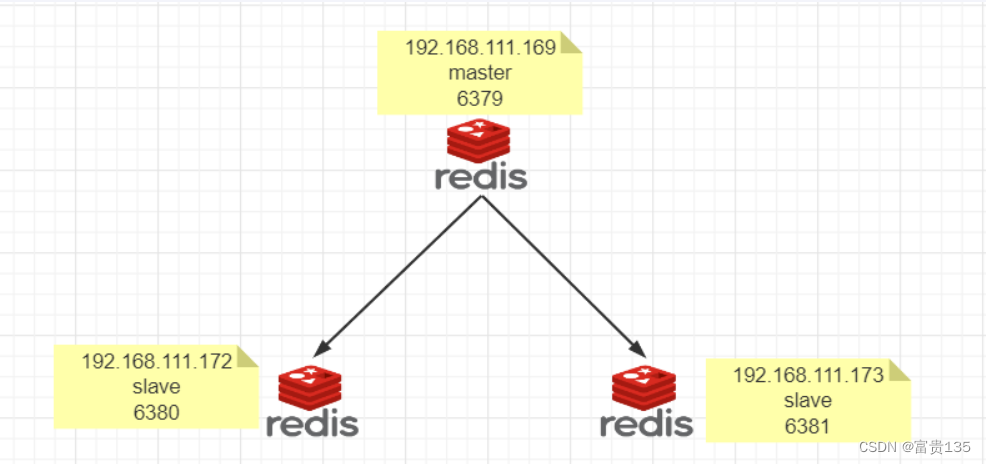
# 1. NoSQL数据库概述
**1.1 NoSQL数据库的定义**
NoSQL(Not Only SQL)数据库是一种非关系型数据库,它不遵循传统的SQL(结构化查询语言)范式。NoSQL数据库旨在处理大规模、非结构化或半结构化数据,并提供高可用性、可扩展性和灵活性。
**1.2 NoSQL数据库的类型**
NoSQL数据库根据其数据模型和存储方式分为以下
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )