Scrapy框架核心组件解析
发布时间: 2024-02-15 10:48:33 阅读量: 54 订阅数: 44 

scrapy框架学习
# 1. Scrapy框架概述
## 1.1 什么是Scrapy框架
Scrapy 是一个用于爬取网站并从中提取结构化数据的应用框架。它可以应用在包括数据挖掘、信息处理或存储历史数据等一系列的应用中。Scrapy 使用了 Twisted 这个异步网络库来处理网络通信。因此,它可以非常快速且高效地爬取网站。
## 1.2 Scrapy框架的核心功能
Scrapy 框架主要有以下核心功能:
- 具有良好的数据抓取性能,支持多线程异步抓取。
- 提供了强大的数据提取能力,支持多种选择器,如 XPath、CSS 选择器等。
- 支持数据处理和存储,可以将数据保存到文件、数据库或者搜索引擎中。
- 可以通过中间件机制实现自定义的扩展功能,如User-Agent切换、IP代理等。
- 提供了命令行和 Web 服务两种方式来查看、分析抓取结果。
- 支持爬虫之间的协作,可以编写分布式爬虫。
## 1.3 Scrapy框架的应用场景
Scrapy 框架可以被广泛应用于以下场景:
- 抓取需要登录后才能访问的网页数据,如需要进行模拟登录、cookie处理等。
- 抓取大规模数据,例如搜索引擎包含的网页数据。
- 在大规模数据集上对爬取的数据进行分析和挖掘。
- 构建包含爬虫监控、定时运行等功能的数据采集系统。
以上就是对 Scrapy 框架概述的内容,接下来我们将详细解析 Scrapy 框架的核心组件。
# 2. Scrapy框架的核心组件
在Scrapy框架中,有许多核心组件用于实现高效的Web爬虫功能。下面将逐一介绍这些组件的作用以及使用方法。
### 2.1 Spider(爬虫)
Spider是Scrapy框架中最重要的组件之一,用于定义爬取网页和提取数据的规则。Spider主要包括以下几个方面的功能:
- 网页请求:Spider负责向目标网站发送HTTP请求,并接收响应。
- 数据提取:Spider使用XPath、CSS选择器等方法从HTML文档中提取需要的数据。
- 数据处理:Spider对提取的数据进行清洗、过滤、格式化等处理。
- 跟进链接:Spider根据提取的链接,继续发送请求爬取更多的页面。
Spider的使用方法如下所示:
```python
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://www.example.com']
def parse(self, response):
# 数据提取逻辑
pass
```
上述代码定义了一个名为`MySpider`的Spider类,该类继承自Scrapy框架提供的`scrapy.Spider`类。其中,`name`属性表示Spider的名称,`start_urls`属性定义了Spider需要爬取的初始URL列表。`parse`方法则用于处理响应数据和提取数据的逻辑。
### 2.2 Item
Item是Scrapy框架中用于存储爬取到的数据的容器。通过定义Item类和声明字段,可以方便地将提取的数据存储起来,以备后续处理或保存到数据库等操作。
下面是一个示例Item的定义:
```python
import scrapy
class MyItem(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field()
```
上述代码定义了一个名为`MyItem`的Item类,其中包含了`title`和`content`两个字段。在Spider中提取到数据后,可以通过创建`MyItem`的实例,并将提取到的数据赋值给对应的字段。
### 2.3 Selector
Selector是Scrapy框架中用于提取数据的工具类。通过Selector,可以使用XPath、CSS选择器等方式轻松地从HTML文档中提取需要的数据。
下面是一个使用Selector提取数据的示例:
```python
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://www.example.com']
def parse(self, response):
sel = scrapy.Selector(response)
title = sel.css('h1::text').get()
content = sel.xpath('//div[@class="content"]/p/text()').getall()
```
上述代码中,`sel = scrapy.Selector(response)`创建了一个Selector对象,接着可以使用`css`方法或`xpath`方法来提取数据。`sel.css('h1::text').get()`通过CSS选择器提取页面中`<h1>`标签的文本内容,而`sel.xpath('//div[@class="content"]/p/text()').getall()`则使用XPath表达式提取class属性为`content`的`<div>`标签下所有的`<p>`标签的文本内容。
### 2.4 Pipeline
Pipeline是Scrapy框架中用于处理爬取到的数据的组件。通过自定义Pipeline,可以对数据进行清洗、格式化、持久化等操作。
下面是一个使用Pipeline处理数据的示例:
```python
class MyPipeline(object):
def process_item(self, item, spider):
# 数据处理逻辑
return item
```
上述代码定义了一个名为`MyPipeline`的Pipeline类,其中的`process_item`方法会在爬虫爬取到数据后被调用。在`process_item`方法中,可以对提取到的数据进行任意的处理和操作,并最后返回处理后的数据。
### 2.5 Downloader
Downloader是Scrapy框架中负责下载网页并处理网络请求的组件。下载器实现了请求的发送和响应的处理,并负责处理请求重试、代理设置等功能。
Scrapy框架内置了多个下载器中间件,可选择性地进行下载器设置和功能扩展。使用Downloader中间件,可以实现HTTP请求的过滤、修改、重定向等操作。
### 2.6 Middleware
Middleware是Scrapy框架中用于处理请求和响应的插件组件。通过编写Middleware,可以实现请求前的预处理、请求后的处理、错误处理、代理设置等功能。
Scrapy框架内置了多个Middleware组件,可用于对请求和响应进行全局的处理和修改。
以上就是Scrapy框架的核心组件的介绍。掌握这些组件的使用方法和功能特点,可以更好地利用Scrapy框架构建强大的Web爬虫应用。
# 3. Spider(爬虫)详解
Spider(爬虫)是Scrapy框架中的核心组件之一,它负责从指定的网站中提取数据,并将数据交给Pipeline进行后续处理。在本章节中,我们将详细解析Spider的作用、特点以及使用方法,并介绍爬虫规则配置、爬虫的运行与调试方法。
##### 3.1 Spider的作用及特点
Spider的作用是指定要爬取的网站、页面以及相应的解析规则,并将提取到的数据下载到本地或其他数据存储介质中。Spider的特点如下:
- 可以高效、自动化地抓取网页数据。
- 支持多线程,实现并发请求。
- 支持异步请求和处理。
- 支持自定义的请求头和代理设置。
##### 3.2 Spider的使用方法
在Scrapy框架中,Spider的使用方法主要包括以下几个步骤:
###### 3.2.1 创建Spider类
首先,我们需要创建一个继承自`scrapy.Spider`的Spider类,并定义一些必要的属性和方法。例如,我们可以定义Spider的name属性、起始URLs、请求头等。
```python
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://example.com']
def parse(self, response):
# 解析网页数据的方法
pass
```
###### 3.2.2 解析网页数据
在Spider类中,我们需要定义一个`parse`方法,用于解析网页数据。在该方法中,可以使用Selector等工具提取所需的数据,并将数据交给Pipeline进行后续处理。
```python
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://example.com']
def parse(self, response):
# 解析网页数据的方法
data = response.css('.class-name::text').get()
yield {'data': data}
```
###### 3.2.3 爬虫规则配置
Spider的运行需要配置一些爬虫规则,包括允许的域名、起始URLs、解析规则等。可以通过在Spider类中定义相应的属性进行配置。
```python
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
def parse(self, response):
# 解析网页数据的方法
data = response.css('.class-name::text').get()
yield {'data': data}
```
###### 3.2.4 爬虫的运行与调试
最后,我们需要运行和调试Spider。Scrapy提供了命令行工具`scrapy crawl`用于启动Spider。
```shell
$ scrapy crawl myspider
```
在调试Spider时,可以使用Scrapy的Shell命令`scrapy shell`来获取网页数据并进行交互式调试。
```shell
$ scrapy shell 'http://example.com'
```
##### 3.3 总结
Spider是Scrapy框架中非常重要的组件之一,它负责从指定的网站中提取数据,并将数据交给Pipeline进行后续处理。在本章节中,我们详细解析了Spider的作用、特点以及使用方法,并介绍了爬虫规则配置、爬虫的运行与调试方法。通过学习本章节的内容,你将能够熟练掌握Spider的使用技巧,并能够编写出高效、灵活的爬虫程序。
# 4. Item的定义与使用
在Scrapy框架中,Item是用来定义爬取数据的结构化信息的容器。它类似于一个字典,可以用来存储爬取到的数据,并且提供了便捷的方式用于数据的提取和处理。
### 4.1 什么是Item
Item可以看作是一种数据模型,用来定义爬取数据的结构化信息。在爬虫中,我们往往会定义一些字段来存储特定页面需要提取的数据,比如文章标题、作者、发布时间等。Item就是用来帮助我们组织和提取这些数据的工具。
### 4.2 Item的定义与声明
在Scrapy框架中,我们可以通过简单的Python类来定义一个Item,这个Item类需要继承自scrapy中的Item类,并且定义需要提取的字段。下面是一个示例:
```python
import scrapy
class MyItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
publish_date = scrapy.Field()
```
上面的代码定义了一个名为MyItem的Item类,里面包含了title、author和publish_date三个字段。
### 4.3 Item的使用与数据提取
在Spider中,当我们发起请求并获取到页面内容后,就可以使用定义好的Item类来提取数据。通过填充Item的字段,我们可以将需要的数据从页面中提取出来,并在后续的Pipeline中进行处理和存储。
以下是一个简单的示例,演示了如何在Spider中使用定义好的Item类:
```python
import scrapy
from myproject.items import MyItem
class MySpider(scrapy.Spider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = ['http://www.example.com']
def parse(self, response):
item = MyItem()
item['title'] = response.xpath('//title/text()').get()
item['author'] = response.xpath('//author/text()').get()
item['publish_date'] = response.xpath('//publish_date/text()').get()
yield item
```
在上面的示例中,我们首先导入了定义好的MyItem类,然后在parse方法中使用XPath表达式从页面中提取数据,并填充到Item的字段中。最后通过yield语句将Item传递到Pipeline中进行后续处理。
通过Item的定义与使用,我们可以更加便捷地提取和存储爬取到的数据,实现数据的结构化和清洗处理。
# 5. Pipeline与数据处理
在Scrapy框架中,Pipeline是一个非常重要的组件,它负责处理爬虫提取的数据并进行清洗、处理以及存储。本章将详细介绍Pipeline的作用与原理,并讨论如何实现数据清洗与存储。
### 5.1 Pipeline的作用与原理
Pipeline的主要作用是对爬虫从网页中提取的数据进行后续处理操作,例如数据清洗、去重、格式转换、存储到数据库等。Pipeline采用了管道的设计思想,使得数据处理可以按照一定的顺序进行。
在Scrapy框架中,Pipeline是通过编写Python类来实现的,每个类代表一个数据处理流程。当爬虫提取到数据后,会依次经过多个Pipeline类的处理,最终得到处理后的数据。
实现Pipeline需要定义下列方法:
- `open_spider(self, spider)`:在爬虫开始执行时调用,用于初始化一些资源。
- `close_spider(self, spider)`:在爬虫结束执行时调用,用于释放资源。
- `process_item(self, item, spider)`:用于处理每个Item对象,可以对数据进行清洗、验证、存储等操作。
### 5.2 数据清洗与处理
数据清洗是爬虫中常用的操作之一,通过对爬取到的数据进行清洗,可以去除多余的空格、HTML标签、特殊字符等,使得数据更加规范。
下面是一个简单的示例,展示了如何使用Pipeline进行数据清洗的操作:
```python
import re
class DataCleanPipeline(object):
def process_item(self, item, spider):
# 清除字符串中的空格
item['name'] = item['name'].strip()
# 去除HTML标签
item['content'] = re.sub('<.*?>', '', item['content'])
return item
```
在上述代码中,`DataCleanPipeline`是一个自定义的Pipeline类,它会对爬虫提取到的`name`和`content`字段进行清洗操作。`strip()`函数用于去除首尾的空格,`re.sub()`函数用于去除HTML标签。
### 5.3 存储数据到不同的数据存储介质
除了数据清洗,Pipeline还可以将爬虫提取到的数据存储到不同的数据存储介质中,例如数据库、文件、NoSQL数据库等。
下面是一个将数据存储到MySQL数据库的示例:
```python
import pymysql
class MySQLPipeline(object):
def open_spider(self, spider):
self.conn = pymysql.connect(host='localhost', user='root', password='123456', db='scrapy_db')
self.cursor = self.conn.cursor()
def close_spider(self, spider):
self.conn.close()
def process_item(self, item, spider):
insert_sql = "INSERT INTO mytable (name, content) VALUES (%s, %s)"
self.cursor.execute(insert_sql, (item['name'], item['content']))
self.conn.commit()
return item
```
在上述代码中,`MySQLPipeline`是一个自定义的Pipeline类,它利用pymysql库连接MySQL数据库,并在`process_item`方法中执行INSERT语句将数据存储到数据库中。
这只是一个简单的示例,实际情况中,还可以根据需求将数据存储到其他类型的数据库或文件中。
总结:
通过以上介绍,我们了解到了Pipeline在Scrapy框架中的作用与原理,以及如何进行数据清洗与存储。
Pipeline的灵活性使得我们可以根据实际需求,对爬取到的数据进行各种处理操作,从而提高数据的质量和可用性。因此,在编写Scrapy爬虫时,我们应该充分利用Pipeline来处理数据,以获得更好的效果。
# 6. Downloader与Middleware
在Scrapy框架中,Downloader和Middleware是两个重要的组件,它们共同完成了网页的下载和处理过程。本章将详细介绍Downloader的工作原理和Middleware的作用与使用,还会探讨如何利用Downloader及Middleware来提升爬虫的效率。
## 6.1 Downloader的工作原理
Downloader是Scrapy框架中负责下载网页的组件。当Spider向Downloader发送一个请求时,Downloader会根据请求的URL使用合适的下载器进行下载,然后将下载好的网页返回给Spider进行解析和数据提取。
Scrapy框架内置了多个下载器,其中最常用的是基于Twisted异步网络框架实现的HttpDownloader。该下载器使用了异步非阻塞的方式,可以高效地处理多个并发请求。
以下是一个简单的示例代码,演示了如何使用Scrapy框架的HttpDownloader进行网页下载:
```python
import scrapy
class MySpider(scrapy.Spider):
name = 'my_spider'
start_urls = ['http://www.example.com']
def parse(self, response):
# 处理下载好的网页,提取数据等操作
pass
if __name__ == "__main__":
from scrapy.crawler import CrawlerProcess
process = CrawlerProcess({
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'DOWNLOADER_MIDDLEWARES': {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'myproject.middlewares.MyCustomDownloaderMiddleware': 543,
},
})
process.crawl(MySpider)
process.start()
```
在上述代码中,通过设置`DOWNLOADER_MIDDLEWARES`参数来指定Downloader中间件,可以在下载网页的过程中进行一些额外的操作,比如修改User-Agent、设置代理等。
## 6.2 Middleware的作用与使用
Middleware是Scrapy框架中用来处理Downloader与Spider之间的请求和响应的组件。它可以修改传入Downloader的请求和传出Spider的响应,还可以对请求和响应进行过滤、拦截和修改等操作。
Scrapy框架中内置了多个Middleware,如RobotstxtMiddleware、HttpErrorMiddleware等,它们可以在Downloader和Spider之间执行一些通用的操作。此外,Scrapy还允许用户自定义Middleware,以满足特定的需求。
以下是一个自定义Middleware的示例代码,展示了如何在请求中添加自定义的Header:
```python
from scrapy import signals
class MyCustomDownloaderMiddleware:
def process_request(self, request, spider):
request.headers['Authorization'] = 'Bearer mytoken'
return None
if __name__ == "__main__":
from scrapy.crawler import CrawlerProcess
process = CrawlerProcess({
'USER_AGENT': 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'DOWNLOADER_MIDDLEWARES': {
'myproject.middlewares.MyCustomDownloaderMiddleware': 543,
},
})
process.crawl(MySpider)
process.start()
```
在上述代码中,自定义的Middleware会为每个请求添加一个自定义的Header,可以根据需要自行修改其他请求属性。
## 6.3 Middleware的自定义与扩展
除了使用内置的Middleware外,Scrapy还允许用户自定义和扩展Middleware,以满足更复杂的需求。
用户可以通过编写一个类,继承自Scrapy的Middleware类,并实现相应的方法来自定义Middleware。以下是一个简单的示例代码,展示了如何自定义一个Middleware:
```python
from scrapy import signals
class MyCustomMiddleware:
def process_request(self, request, spider):
# 在发送给Downloader之前对请求进行处理
return None
def process_response(self, request, response, spider):
# 在从Downloader返回到Spider之前对响应进行处理
return response
def process_exception(self, request, exception, spider):
# 处理请求过程中发生的异常
pass
```
在上述代码中,通过实现`process_request`、`process_response`和`process_exception`等方法,可以对请求和响应进行一些额外的处理。其中,`process_request`方法在将请求发送给Downloader之前被调用,`process_response`方法在从Downloader返回到Spider之前被调用,`process_exception`方法在请求过程中发生异常时被调用。
## 6.4 如何利用Downloader及Middleware提升爬虫效率
通过合理配置Downloader及Middleware,可以极大地提升爬虫的效率和稳定性。
在使用Downloader时,可以设置并发请求数、下载超时时间等参数,以充分利用网络资源,提高下载效率。此外,可以使用下载器中间件来实现一些高级功能,如自动重试、请求过滤等。
而在使用Middleware时,可以根据具体需求编写自定义的Middleware,以满足特定的处理需求。比如,可以编写一个Middleware来判断请求是否需要被拦截、对响应进行解密等操作,从而提高数据提取和处理的效率。
总之,Downloader和Middleware是Scrapy框架中非常重要的组件,通过充分利用它们的功能,可以使得爬虫更高效、更灵活,适应不同的需求和场景。
本章介绍了Downloader的工作原理和Middleware的作用与使用,以及如何自定义和扩展Middleware。接下来的章节将继续讲解其他核心组件,敬请期待!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"Scrapy框架核心原理实战解析"为主题,深入探讨了Scrapy框架的核心组件及其原理,并结合实际案例展示了如何使用Scrapy框架进行数据抓取和处理。从Scrapy框架的初探和基本概念开始,逐步展开到爬虫中间件、Downloader Middleware、Pipeline等核心原理的解析和实践。此外,还介绍了Scrapy框架的分布式爬虫实现原理、与Selenium集成、日志处理与调试技巧、与Docker容器技术结合实践等内容。同时,特别关注Scrapy框架在大数据处理、与Elasticsearch的高效集成、机器学习数据采集以及自然语言处理中的应用。通过本专栏的学习,读者将深入了解Scrapy框架的核心原理,并掌握其在实际项目中的应用技巧和解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
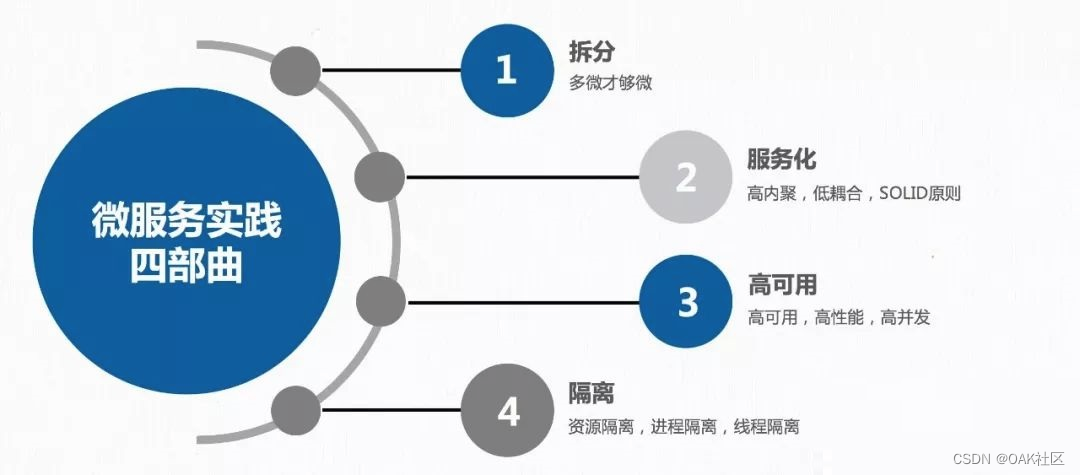
构建可扩展的微服务架构:系统架构设计从零开始的必备技巧
# 摘要
微服务架构作为一种现代化的分布式系统设计方法,已成为构建大规模软件应用的主流选择。本文首先概述了微服务架构的基本概念及其设计原则,随后探讨了微服务的典型设计模式和部署策略,包括服务发现、通信模式、熔断容错机制、容器化技术、CI/CD流程以及蓝绿部署等。在技术栈选择与实践方面,重点讨论了不同编程语言和框架下的微服务实现,以及关系型和NoSQL数据库在微服务环境中的应用。此外,本文还着重于微服务监控、日志记录和故障处理的最佳实践,并对微服
NYASM最新功能大揭秘:彻底释放你的开发潜力
# 摘要
NYASM是一个功能强大的汇编语言工具,支持多种高级编程特性并具备良好的模块化编程支持。本文首先对NYASM的安装配置进行了概述,并介绍了其基础与进阶语法。接着,本文探讨了NYASM在系统编程、嵌入式开发以及安全领域的多种应用场景。文章还分享了NYASM的高级编程技巧、性能调优方法以及最佳实践,并对调试和测试进行了深入讨论。最后,本文展望了NYASM的未来发展方向,强调了其与现代技
【ACC自适应巡航软件功能规范】:揭秘设计理念与实现路径,引领行业新标准

# 摘要
自适应巡航控制(ACC)系统作为先进的驾驶辅助系统之一,其设计理念在于提高行车安全性和驾驶舒适性。本文从ACC系统的概述出发,详细探讨了其设计理念与框架,包括系统的设计目标、原则、创新要点及系统架构。关键技术如传感器融合和算法优化也被着重解析。通过介绍ACC软件的功能模块开发、测试验证和人机交互设计,本文详述了系统的实现
ICCAP调优初探:提效IC分析的六大技巧

# 摘要
ICCAP(Image Correlation for Camera Pose)是一种用于估计相机位姿和场景结构的先进算法,广泛应用于计算机视觉领域。本文首先概述了ICCAP的基础知识和分析挑战,深入探讨了ICCAP调优理论,包括其分析框架的工作原理、主要组件、性能瓶颈分析,以及有效的调优策略。随后,本文介绍了ICCAP调优实践中的代码优化、系统资源管理优化和数据处理与存储优化
LinkHome APP与iMaster NCE-FAN V100R022C10协同工作原理:深度解析与实践

# 摘要
本文首先介绍了LinkHome APP与iMaster NCE-FAN V100R022C10的基本概念及其核心功能和原理,强调了协同工作在云边协同架构中的作用,包括网络自动化与设备发现机制。接下来,本文通过实践案例探讨了LinkHome APP与iMaster NCE-FAN V100R022C1
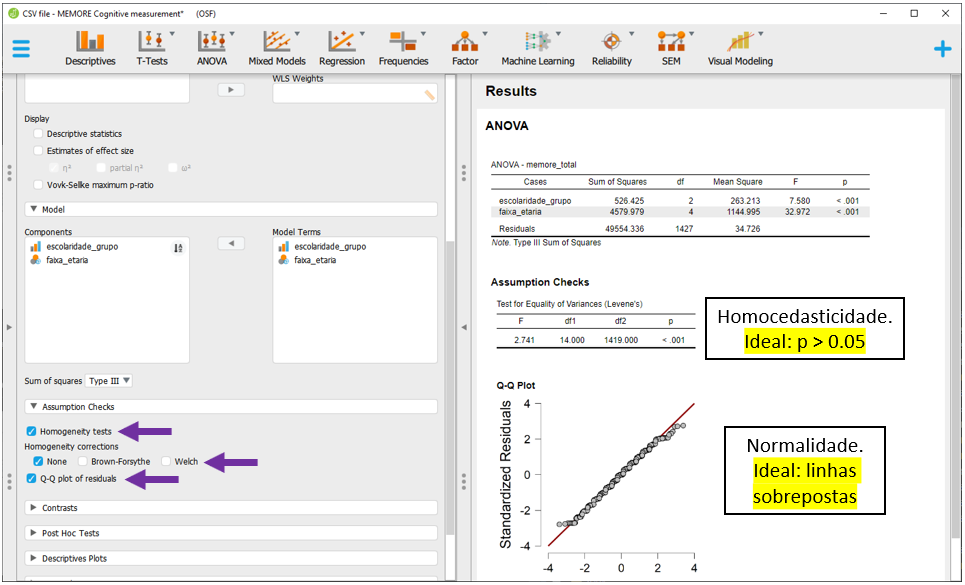
紧急掌握:单因子方差分析在Minitab中的高级应用及案例分析
# 摘要
本文详细介绍了单因子方差分析的理论基础、在Minitab软件中的操作流程以及实际案例应用。首先概述了单因子方差分析的概念和原理,并探讨了F检验及其统计假设。随后,文章转向Minitab界面的基础操作,包括数据导入、管理和描述性统计分析。第三章深入解释了方差分析表的解读,包括平方和的计算和平均值差异的多重比较。第四章和第五章分别讲述了如何在Minitab中执行单因子方
全球定位系统(GPS)精确原理与应用:专家级指南

# 摘要
本文对全球定位系统(GPS)的历史、技术原理、应用领域以及挑战和发展方向进行了全面综述。从GPS的历史和技术概述开始,详细探讨了其工作原理,包括卫星信号构成、定位的数学模型、信号增强技术等。文章进一步分析了GPS在航海导航、航空运输、军事应用以及民用技术等不同领域的具体应用,并讨论了当前面临的信号干扰、安全问题及新技术融合的挑战。最后,文
AutoCAD VBA交互设计秘籍:5个技巧打造极致用户体验
# 摘要
本论文系统介绍了AutoCAD VBA交互设计的入门知识、界面定制技巧、自动化操作以及高级实践案例,旨在帮助设计者和开发者提升工作效率与交互体验。文章从基本的VBA用户界面设置出发,深入探讨了表单和控件的应用,强调了优化用户交互体验的重要性。随后,文章转向自动化操作,阐述了对象模型的理解和自动化脚本的编写。第三部分展示了如何应用ActiveX Automation进行高级交互设计,以及如何定制更复杂的用户界面元素,以及解决方案设计过程中的用户反馈收集和应用。最后一章重点介绍了VBA在AutoCAD中的性能优化、调试方法和交互设计的维护更新策略。通过这些内容,论文提供了全面的指南,以应
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )