CUDA版本优化宝典:Ubuntu 20.04上的最佳选择
发布时间: 2024-11-29 22:44:48 阅读量: 18 订阅数: 31 

参考资源链接:[Ubuntu20.04 NVIDIA 显卡驱动与 CUDA、cudnn 安装指南](https://wenku.csdn.net/doc/3n29mzafk8?spm=1055.2635.3001.10343)
# 1. CUDA简介及在Ubuntu 20.04上的安装
## 1.1 CUDA简介
CUDA(Compute Unified Device Architecture)是由NVIDIA推出的一种通用并行计算架构。它允许开发者使用NVIDIA的GPU(图形处理单元)进行通用计算,即所谓的GPGPU(General-Purpose computing on Graphics Processing Units)。CUDA为开发者提供了一种相对直观的方式来利用GPU的并行处理能力,显著加速复杂的计算密集型任务,如科学计算、图像处理和深度学习等领域。
## 1.2 CUDA的核心优势
CUDA的核心优势在于其并行计算能力。GPU含有大量的核心,能够同时处理成千上万个小任务。相较于CPU的串行处理模式,GPU的并行处理能力使得在处理大规模数据集时具有显著的性能提升。此外,CUDA还提供了丰富的库和工具,支持快速开发和优化性能。
## 1.3 在Ubuntu 20.04上安装CUDA
在Ubuntu 20.04系统上安装CUDA涉及几个主要步骤,包括添加CUDA官方仓库、导入GPG密钥、安装CUDA驱动和Toolkit等。以下是安装的详细步骤:
1. 更新系统的包列表:
```bash
sudo apt update
```
2. 添加CUDA官方仓库的GPG密钥:
```bash
sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/3bf863cc.pub
```
3. 将CUDA仓库添加到系统的软件源列表:
```bash
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
sudo add-apt-repository "deb http://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/${distribution} /"
```
4. 安装CUDA驱动和Toolkit:
```bash
sudo apt update
sudo apt install nvidia-cuda-toolkit
```
5. 验证安装是否成功,可以通过查询CUDA版本来实现:
```bash
nvcc --version
```
安装完成后,你可以在终端看到CUDA编译器的版本信息,表明CUDA已经在你的Ubuntu系统中成功安装并配置完毕。接下来,你可以开始探索CUDA编程和性能优化之旅了。
# 2. CUDA编程基础
## 2.1 CUDA的内存模型
### 2.1.1 全局内存和共享内存
CUDA的内存模型对并行计算的性能有着直接的影响。全局内存是设备上所有线程都可以访问的内存区域,其容量大但访问延迟高。而共享内存是位于每个线程块内的小容量内存,它速度快但访问范围受限。在CUDA编程中,合理利用共享内存可以显著提升性能。
```c
// 示例代码:使用共享内存进行矩阵乘法
__global__ void MatrixMultiplyShared(float *A, float *B, float *C, int width) {
__shared__ float As[16][16]; // 假设线程块大小为16x16
__shared__ float Bs[16][16];
// 索引计算逻辑
int bx = blockIdx.x, by = blockIdx.y;
int tx = threadIdx.x, ty = threadIdx.y;
// 加载数据到共享内存
As[ty][tx] = A[width * (by * 16 + ty) + bx * 16 + tx];
Bs[ty][tx] = B[width * (ty * 16 + bx) + tx * 16 + by];
// 同步操作,确保数据加载完成
__syncthreads();
float sum = 0.0f;
for (int k = 0; k < width; ++k)
sum += As[ty][k] * Bs[k][tx];
C[width * (by * 16 + ty) + bx * 16 + tx] = sum;
// 同步操作,确保计算完成
__syncthreads();
}
```
在上述代码中,每个线程块计算矩阵乘法的一个子矩阵结果。通过使用共享内存,我们避免了多次从全局内存中加载重复数据,减少了全局内存访问次数,从而提高了计算效率。
### 2.1.2 寄存器和常量内存
寄存器是GPU上最快的内存类型,但数量有限。在编写CUDA代码时,应尽量将频繁访问的变量放在寄存器中。常量内存则用于存储只读数据,如查找表、常数等,可以被线程块内所有线程共享。其性能虽然不如共享内存,但由于访问局部性较好,可以提供比全局内存更高的访问速率。
```c
__constant__ float constArray[256]; // 常量内存的声明
__global__ void UseConstantMemory(float *in, float *out) {
int idx = threadIdx.x;
out[idx] = constArray[idx] + in[idx]; // 同时访问常量内存和全局内存
}
```
在上述代码中,我们使用了常量内存来存储`constArray`数组。在GPU执行时,由于`constArray`是只读数据,GPU会尽量优化内存访问,减少延迟。
## 2.2 CUDA编程范式
### 2.2.1 线程层次结构和执行配置
CUDA编程中,线程层次结构是由网格(grid)、块(block)和线程(thread)组成的。每个线程都有自己的索引和全局ID,通过这些ID可以确定该线程在全局任务中的位置。执行配置则是通过`<<< >>>`运算符指定的,在运行时控制线程的组织方式。
```c
__global__ void VectorAdd(float *A, float *B, float *C, int numElements) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements) {
C[i] = A[i] + B[i];
}
}
int main() {
// 分配和初始化主机内存
// ...
// 分配设备内存
// ...
// 执行配置参数:网格和块的大小
int blockSize = 256;
int numBlocks = (numElements + blockSize - 1) / blockSize;
VectorAdd<<<numBlocks, blockSize>>>(d_A, d_B, d_C, numElements);
// 复制结果回主机内存
// ...
// 释放设备内存
// ...
return 0;
}
```
在上述示例中,我们定义了一个核函数`VectorAdd`,它将两个向量相加。通过执行配置`VectorAdd<<<numBlocks, blockSize>>>(...)`,我们定义了线程块和网格的大小,以及如何将这些线程映射到CUDA设备上。
### 2.2.2 内存管理与数据传输
CUDA中的内存管理是高性能计算的关键。CUDA提供了多种内存类型,包括全局内存、共享内存、常量内存、纹理内存等。数据传输指的是在GPU的全局内存与主机内存之间传输数据的过程。正确管理内存传输和内存分配是优化CUDA程序性能的重要方面。
```c
cudaError_t result = cudaMalloc((void**)&d_A, size);
if (result != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
return -1;
}
cudaError_t result2 = cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
if (result2 != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
cudaFree(d_A);
return -1;
}
```
在这段代码中,首先使用`cudaMalloc`为设备内存分配空间。然后,使用`cudaMemcpy`将数据从主机内存传输到设备内存。在数据使用完毕后,还需要使用`cudaFree`释放设备内存以避免内存泄漏。
## 2.3 CUDA开发工具和调试技巧
### 2.3.1 使用NVIDIA Visual Profiler进行性能分析
NVIDIA Visual Profiler(nvvp)是一个强大的性能分析工具,它可以展示GPU上CUDA程序的执行时间,以及线程的执行情况。通过分析执行时间的瓶颈和线程的活跃度,开发者可以针对性能瓶颈进行优化。
### 2.3.2 常见CUDA编程错误及调试策略
CUDA程序的调试比传统CPU程序复杂,常见的错误类型包括内存访问违规、线程索引越界、资源泄漏等。NVIDIA提供了一套调试工具,包括cuda-memcheck和Nsight,可以帮助开发者定位和解决这些常见问题。
通过这些工具,开发者可以检查运行时错误,如数组越界、未初始化的内存读取等。这些工具通常提供详细的报告和堆栈跟踪,从而帮助开发者识别和修正代码中的错误。
在下一章节中,我们将深入探讨CUDA性能优化实践,从计算密度、内存访问模式、异步和流式内存传输等方面进行详细的分析与实践案例介绍。
# 3. CUDA性能优化实践
## 3.1 优化计算密度和并行度
### 3.1.1 线程块的大小与性能
在CUDA编程中,选择合适的线程块(block)大小对性能至关重要。线程块的大小直接影响到硬件资源的利用效率和程序的并行度。一般来说,每个线程块应该能够完全被一个流处理器(SM)调度,这样可以最大化利用GPU的计算资源。如果线程块太大,可能会导致资源的竞争,而太小则可能无法充分利用GPU的计算能力。
例如,假设有一个特定的GPU拥有80个SM,每个SM可同时运行一个线程块,那么理想的线程块大小应该是该GPU可以完全调度的最大线程数除以SM的数量。然而,实际情况可能更复杂,需要结合具体的计算任务和内存访问模式来调整线程块的大小。
```cuda
__global__ void kernel(int *data) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
// kernel logic here
}
int main() {
int *data;
// allocate and initialize data
int blockSize = 256; // example block size
int gridSize = (total_number_of_threads + blockSize - 1) / blockSize;
kernel<<<gridSize, blockSize>>>(data);
// rest of the code
}
```
### 3.1.2 使用合作组提高性能
合作组(warp)是CUDA中的一个概念,指的是在同一SM上并行执行的一组线程。在大多数情况下,32个线程组成一个合作组,它们同时在同一个指令下执行。合理利用合作组可以提升性能,因为合作组内的线程可以有效地进行指令级并行(IL

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在为 Ubuntu 20.04 用户提供全面的显卡驱动和 CUDA 安装指南。从显卡驱动安装的逐步说明到 CUDA 的必要配置,再到故障排除和优化技巧,本专栏涵盖了所有方面。
专栏标题和内部文章标题清楚地概述了每个主题,包括:
* 显卡驱动安装的终极指南
* CUDA 安装前的必要配置
* 兼容性问题的解决方案
* CUDA 一步安装秘籍
* 显卡驱动故障全解析
* CUDA 版本优化宝典
* CUDA 与 TensorFlow 的完美融合
* 显卡驱动故障排查与优化
* CUDA 开发环境搭建全攻略
* 显卡驱动与 CUDA 环境维护之道
* CUDA 编程环境搭建详解
* CUDA 应用性能的终极分析
* 显卡驱动快速诊断
* CUDA 兼容框架安装
* 显卡驱动兼容性测试
本专栏旨在帮助 Ubuntu 20.04 用户轻松安装和优化其显卡驱动和 CUDA 环境,以获得最佳图形性能和计算效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Quartus II USB Blaster驱动更新】:一步到位的故障排除流程
# 摘要
本文全面阐述了Quartus II USB Blaster驱动更新的各个方面。首先概述了驱动更新的必要性和应用场景,接着深入探讨了驱动的工作原理和与FPGA开发板的交互流程,以
ACIS SAT文件在逆向工程中的应用:从实体到模型的转换秘籍
# 摘要
本论文首先概述了ACIS SAT文件的结构和逆向工程的基础理论,随后深入探讨了ACIS文件的解析技术及其在三维模型重建中的应用。通过分析实体扫描技术、点云数据处理和三角面片优化,详细介绍了从ACIS数据到三维模型转换的实践操作。最后,论文探讨了逆向工程在实践中遇到的挑战,并展望了其技术发展趋势,包括技术革新、知识产权保护的平衡以及逆向工程在新兴领域的潜力。
# 关键字
ACIS SAT文件;逆向工程;点云数据;三维模型重建;技术挑战;发展前景
参考资源链接:[ACIS SAT文件格式详解:文本与二进制解析](https://wenku.csdn.net/doc/371wihxiz
GSM手机射频指标与用户感知:实现最佳性能与体验的平衡艺术
# 摘要
GSM技术作为移动通信领域的基础,其射频指标对用户感知有着重要影响。本文首先概述了GSM技术背景与射频指标,然后深入探讨了射频指标如何影响用户体验,包括信号强度、频段选择以及干扰和多径效应。接着,文章通过定性和定量方法评估了用户感知,并详细介绍了优化GSM手机射频性能的实践策略。此外,本文还分享了优化成功与失败的案例研究,强调了实践经验的重要性。最后,文章展望了未来技术发展趋势以及对用户体验提升和研究方
【C语言高阶应用】:sum函数在数据结构优化中的独门秘籍
# 摘要
本文全面探讨了sum函数在不同类型数据结构中的应用、优化及性能提升。通过对sum函数在数组、链表、树结构以及图数据结构中的运用进行详细阐述,揭示了其在基础数据操作、内存优化和复杂算法中的核心作用。特别地,本文分析了如何通过sum函数进行内存管理和结构优化,以提高数据处理的效率和速度。文章总结了当前sum函数应用的趋势,并对未来数据结构优化的潜在方向和
【SYSWELD材料模型精确应用】:确保仿真准确性的关键步骤

# 摘要
SYSWELD材料模型是广泛应用于结构仿真中的重要工具,它通过理论基础、精确设置、实践应用及高级挑战的深入分析,为工程师提供了一套系统的方法论,以确保仿真结果的准确性和可靠性。本文首先概述了材料模型的基本概念及其在仿真中的作用,然后详细讨论了材料模型参数的来源、分类以及对仿真结果的影响。文章进一步探讨了材料属性的精确输入、校准
【Fluent UDF精通指南】:掌握核心技巧,优化性能
# 摘要
本文深入探讨了Fluent UDF(User-Defined Functions)的使用和编程技巧,旨在为CFD(计算流体动力学)工程师和研究人员提供全面的指导。文章首先介绍了Fluent UDF的基本概念、安装流程和编程基础,包括数据类型、变量、函数、宏定义以及调试方法。接着,本文深入讲解了内存管理、并行计算技巧和性能优化,通过案例研究展示了如何实现自定义边界条件和源项。此外,文章还介绍了Fluent UDF在工程应用中的实际操作,例如多相流、化学反应模型和热管理。最后,本文分享了实战技巧和最佳实践,包括代码组织、模块化、性能调优,并强调了社区资源的重要性以及终身学习的价值。
#
软件测试工具高效使用技巧:朱少民版课后习题的实战应用

# 摘要
本文全面探讨了软件测试工具的选型、测试用例的设计与管理、自动化测试工具的应用、缺陷管理与跟踪、测试数据管理与模拟工具以及测试报
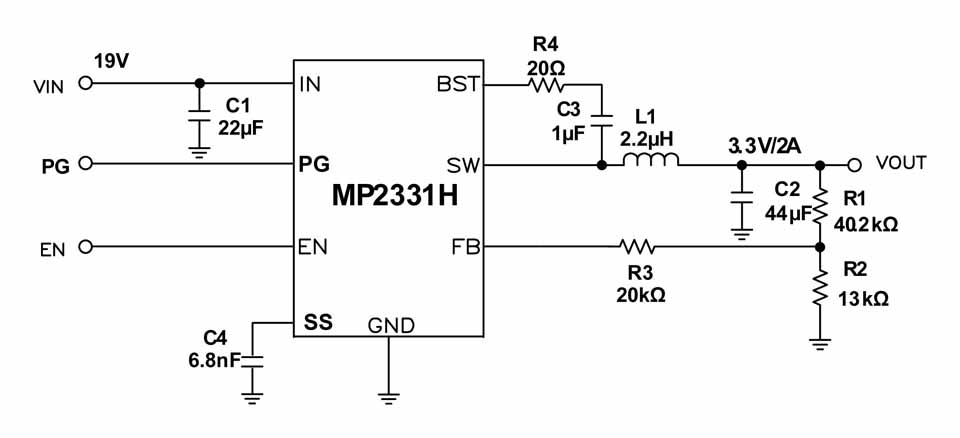
【开关电源必修课】:MP2359工作原理与应用全解析
# 摘要
本文全面介绍了MP2359芯片的特性、工作原理、应用电路设计、调试优化技巧以及系统集成与应用实例。首先概述MP2359芯片的基本情况,随后详细阐述了其内部结构、工作模式和保护机制。文章接着深入探讨了MP2359在降压和升压转换器中的电路设计方法,并提供了实际设计案例。第四章专注于调试与优化技巧,包括效率提升、稳定性问题的调试以及PCB布局的指导原则。第五章讨论了MP2359在不同系统中的集成和创新应用,并分享了
【对位贴合技术难关攻克】:海康机器视觉案例深度剖析

# 摘要
本文首先概述了对位贴合技术及其在机器视觉领域的基础。随后,详细分析了实现对位贴合所需的关键技术点,并探讨了海康机器视觉在其中的应用和优势。针对技术难点,本文提出了精准定位、提高效率和适应复杂环境的解决方案。通过实践案例研究,展示了海康机器视觉在实际生产中的应用成效,并对其技术实现和效益进行了评估。最后,文章展望了对位贴合技术的未来发展趋势,重点介绍了海康机器视觉的创新突破与长远规
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )