深入分析Django JSON序列化:高级技巧与处理复杂数据结构的策略
发布时间: 2024-10-13 06:59:54 阅读量: 19 订阅数: 31 

Python基于Django城市PM2.5空气质量数据可视化分析源码.zip

# 1. Django JSON序列化概述
Django作为一个强大的Python Web框架,其内置的JSON序列化工具提供了将复杂数据结构转换为JSON格式的简便方法。这种序列化不仅限于基本的数据类型,还能处理数据库查询集、模型实例以及复杂的嵌套关系。在本章节中,我们将概述Django JSON序列化的概念,它的作用以及为何在Web开发中占据重要地位。
## Django序列化器的使用
### 序列化器的创建和配置
在Django REST framework中,序列化器是一个核心概念,它负责将模型实例或查询集转换为JSON格式的字符串,同样也负责将JSON格式的字符串转换回模型实例。创建一个序列化器的基本步骤包括定义一个继承自`serializers.Serializer`或其子类的类,并使用字段类型来声明模型的属性。例如:
```python
from rest_framework import serializers
from .models import Article
class ArticleSerializer(serializers.Serializer):
title = serializers.CharField(max_length=100)
content = serializers.CharField()
def create(self, validated_data):
# 创建并返回一个新的`Article`实例
return Article.objects.create(**validated_data)
def update(self, instance, validated_data):
# 更新并返回一个已经存在的`Article`实例
instance.title = validated_data.get('title', instance.title)
instance.content = validated_data.get('content', instance.content)
instance.save()
return instance
```
### 序列化和反序列化的基础
序列化是将数据结构转换为JSON的过程,而反序列化则是将JSON转换回数据结构的过程。Django REST framework通过`serialize`和`unserialize`方法提供了这一功能。例如,序列化一个查询集:
```python
articles = Article.objects.all()
serializer = ArticleSerializer(articles, many=True)
json_data = serializer.serialize('json')
```
反之,反序列化则是将JSON字符串转换回Django模型实例:
```python
data = '{"title": "Django JSON serialization", "content": "An overview of Django JSON serialization"}'
serializer = ArticleSerializer(data=json.loads(data))
if serializer.is_valid():
serializer.save() # 将数据保存到数据库
```
通过本章节的学习,您将掌握Django JSON序列化的基础知识,为进一步深入学习和应用序列化器做好准备。
# 2. 基本的JSON序列化技巧
在本章节中,我们将深入探讨Django中的基本JSON序列化技巧,这是构建RESTful API时不可或缺的一部分。我们会从序列化器的使用开始,逐步介绍如何进行数据模型与JSON字段的映射,以及如何自定义序列化行为以满足特定需求。
## 2.1 Django序列化器的使用
### 2.1.1 序列化器的创建和配置
Django REST framework中的序列化器提供了一种非常便捷的方式来将模型实例转换成JSON格式,同时也支持将JSON数据转换回模型实例。在开始序列化之前,我们需要先创建并配置序列化器。
```python
from rest_framework import serializers
from .models import Article
class ArticleSerializer(serializers.ModelSerializer):
class Meta:
model = Article
fields = ['id', 'title', 'content', 'author', 'created_at']
```
在上面的代码示例中,我们创建了一个`ArticleSerializer`类,它继承自`serializers.ModelSerializer`。在`Meta`内部类中,我们指定了要序列化的模型`Article`,以及需要序列化的字段列表。
### 2.1.2 序列化和反序列化的基础
序列化是将数据转换成JSON格式的过程,而反序列化则是将JSON数据转换回数据模型的过程。在Django REST framework中,这两个过程都可以非常简单地通过序列化器类来完成。
```python
article = Article.objects.get(id=1)
serializer = ArticleSerializer(article)
serialized_data = serializer.data # 序列化
```
在上面的代码示例中,我们实例化了一个`ArticleSerializer`对象,并将一个`Article`对象作为参数传递给它。然后通过`serializer.data`属性,我们可以得到序列化后的数据。
反序列化则是将JSON数据转换回模型的过程,这通常在创建或更新数据时使用。
```python
data = {'title': 'New Article', 'content': 'Content of the new article'}
serializer = ArticleSerializer(data=data)
if serializer.is_valid():
article = serializer.save() # 反序列化并保存数据
```
在上面的代码示例中,我们创建了一个包含文章数据的字典,并通过`ArticleSerializer`类进行反序列化。如果数据验证通过,可以通过调用`serializer.save()`方法来创建一个新的`Article`模型实例。
## 2.2 数据模型与JSON字段的映射
### 2.2.1 基本字段映射
Django REST framework的序列化器可以非常方便地将模型字段映射到JSON字段。它支持Python原生的数据类型,如字符串、整数、浮点数、日期和时间等。
```python
class UserSerializer(serializers.ModelSerializer):
date_of_birth = serializers.DateField()
password = serializers.CharField(write_only=True)
class Meta:
model = User
fields = ['username', 'email', 'date_of_birth', 'password']
```
在上面的代码示例中,我们定义了一个`UserSerializer`类,它映射了`User`模型的`username`、`email`和`date_of_birth`字段。此外,我们将`password`字段设置为只写,意味着在反序列化时可以接收数据,但在序列化时不会返回数据。
### 2.2.2 复杂字段映射
除了基本字段,Django REST framework还支持复杂字段的映射,包括嵌套对象、关联对象以及自定义字段。
```python
class CommentSerializer(serializers.ModelSerializer):
class Meta:
model = Comment
fields = ['id', 'content', 'created_at']
class ArticleSerializer(serializers.ModelSerializer):
comments = CommentSerializer(many=True, read_only=True)
class Meta:
model = Article
fields = ['id', 'title', 'content', 'comments']
```
在上面的代码示例中,我们定义了一个`CommentSerializer`类来序列化评论数据。在`ArticleSerializer`中,我们添加了一个`comments`字段,它是一个`Comment`模型的序列化器列表,这样就可以将文章的评论以嵌套的方式序列化。
## 2.3 自定义序列化行为
### 2.3.1 重写to_representation和to_internal_value方法
有时我们需要对序列化过程进行更细致的控制,这时候可以重写序列化器的`to_representation`方法和`to_internal_value`方法。
```python
class ArticleSerializer(serializers.ModelSerializer):
class Meta:
model = Article
fields = ['id', 'title', 'content']
def to_representation(self, instance):
data = super().to_representation(instance)
data['custom_field'] = 'Custom Value'
return data
def to_internal_value(self, data):
data['content'] = data['content'] + ' (Appended Content)'
return super().to_internal_value(data)
```
在上面的代码示例中,我们重写了`ArticleSerializer`的`to_representation`和`to_internal_value`方法。在`to_representation`方法中,我们添加了一个自定义字段`custom_field`。在`to_internal_value`方法中,我们修改了`content`字段的内容。
### 2.3.2 添加额外的上下文信息
在某些情况下,我们需要在序列化过程中添加额外的上下文信息,比如当前用户的信息,这可以通过重写`get_extra_context`方法来实现。
```python
class ArticleSerializer(serializers.ModelSerializer):
class Meta:
model = Article
fields = ['id', 'title', 'content']
def get_extra_context(self, data):
context = super().get_extra_context(data)
context['request'] = self.context['request']
return context
```
在上面的代码示例中,我们重写了`ArticleSerializer`的`get_extra_context`方法,并添加了当前请求对象到上下文中。这样,在序列化过程中就可以访问到当前请求对象,比如当前用户的信息。
### 2.3.3 自定义序列化逻辑的实现
为了进一步自定义序列化逻辑,我们可以通过编写自定义序列化器方法字段或自定义序列化器字段来实现。
```python
from rest_framework import serializers
class LowercaseField(serializers.Field):
def to_representation(self, value):
return value.lower()
class ArticleSerializer(serializers.ModelSerializer):
lowercase_title = LowercaseField(source='title')
class Meta:
model = Article
fields = ['id', 'title', 'lowercase_title']
```
在上面的代码示例中,我们定义了一个自定义序列化器字段`LowercaseField`,它会在序列化时将文本转换为小写。然后在`ArticleSerializer`中,我们使用了`lowercase_title`字段来展示文章标题的小写形式。
通过这些技巧,我们可以灵活地处理各种序列化需求,无论是基本的还是复杂的。在后续章节中,我们将进一步探讨如何处理更复杂的序列化场景,如嵌套序列化、动态字段和查询集的序列化,以及如何优化序列化性能。
# 3. 处理复杂数据结构
处理复杂数据结构是Django JSON序列化中一个高级且常见的需求。在实际的Web应用中,我们经常会遇到需要序列化嵌套关系数据、动态字段以及复杂对象的情况。本章节将深入探讨如何在Django REST framework中处理这些复杂的数据结构,并提供相应的序列化策略。
## 3.1 嵌套序列化
嵌套序列化主要涉及到一对一、一对多以及多对多关系的数据处理。在Django REST framework中,我们可以利用序列化器的关系字段来实现这些复杂的数据序列化。
### 3.1.1 一对一和一对多关系的序列化
一对一和一对多关系通常涉及到两个模型之间的关联。例如,一个用户模型(User)和一个用户详细信息模型(UserProfile)之间存在一对一关系,而一个博客文章模型(Post)和一个评论模型(Comment)之间存在一对多关系。
```python
# models.py
from django.db import models
class UserProfile(models.Model):
user = models.OneToOneField('User', on_delete=models.CASCADE)
# 其他字段...
class Post(models.Model):
author = models.ForeignKey('User', on_delete=models.CASCADE)
# 其他字段...
class Comment(models.Model):
post = models.ForeignKey('Post', on_delete=models.CASCADE)
content = models.TextField()
# 其他字段...
```
在序列化器中,我们可以这样处理:
```python
# serializers.py
from rest_framework import serializers
from .models import User, UserProfile, Post, Comment
class UserProfileSerializer(serializers.ModelSerializer):
class Meta:
model = UserProfile
fields = ['user_profile_field1', 'user_profile_field2']
class CommentSerializer(serializers.ModelSerializer):
class Meta:
model = Comment
fields = ['id', 'content']
class PostSerializer(serializers.ModelSerializer):
comments = CommentSerializer(many=True, read_only=True)
class Meta:
model = Post
fields = ['id', 'title', 'content', 'comments']
```
在上述代码中,`PostSerializer`中的`comments`字段通过嵌套`CommentSerializer`来序列化一对多关系的数据。这种方式使得数据的表示更加直观和清晰。
### 3.1.2 多对多关系的序列化
多对多关系通常涉及到两个模型之间可以有多个关联。例如,一个文章模型(Post)和一个标签模型(Tag)之间存在多对多关系。
```python
# serializers.py
class TagSerializer(serializers.ModelSerializer):
class Meta:
model = Tag
fields = ['id', 'name']
class PostSerializer(serializers.ModelSerializer):
tags = TagSerializer(many=True, read_only=True)
class Meta:
model = Post
fields = ['id', 'title', 'content', 'tags']
```
在`PostSerializer`中,`tags`字段通过嵌套`TagSerializer`来序列化多对多关系的数据。
### 3.1.3 动态字段的选择
动态字段选择允许客户端根据需要选择要序列化的字段。在Django REST framework中,我们可以通过重写`to_representation`方法来实现这一功能。
```python
class DynamicFieldsModelSerializer(serializers.ModelSerializer):
"""
一个ModelSerializer,它接受一个额外的`fields`参数来动态地限制返回的字段。
"""
def __init__(self, *args, **kwargs):
# 在初始化序列化器时获取字段参数
fields = kwargs.pop('fields', None)
super(DynamicFieldsModelSerializer, self).__init__(*args, **kwargs)
if fields is not None:
# 如果指定了字段参数,只保留这些字段
allowed = set(fields)
existing = set(self.fields.keys())
for field_name in existing - allowed:
self.fields.pop(field_name)
class PostSerializer(DynamicFieldsModelSerializer):
class Meta:
model = Post
fields = ['id', 'title', 'content']
# 使用方法
# serializer = PostSerializer(post_instance, fields=['id', 'title'])
```
在这个例子中,我们创建了一个`DynamicFieldsModelSerializer`类,它在初始化时会接受一个`fields`参数,这个参数定义了哪些字段应该被序列化。在`PostSerializer`中,我们通过继承`DynamicFieldsModelSerializer`来实现动态字段选择。
### 3.1.4 查询集的序列化优化
当处理大量数据时,查询集的序列化性能可能会成为一个瓶颈。为了优化性能,我们可以使用Django REST framework提供的`SQLQuerySet`对象。
```python
from django.db.models import Count
from rest_framework.generics import ListAPIView
from .models import Post
from .serializers import PostSerializer
class PostList(ListAPIView):
queryset = Post.objects.annotate(num_comments=Count('comment')).all()
serializer_class = PostSerializer
# 使用方法
# view = PostList.as_view()
# response = view(request)
```
在这个例子中,我们在`PostList`视图中使用了`annotate`方法来预先计算每个帖子的评论数量,并将其作为`num_comments`字段添加到查询集中。这样,在序列化过程中就不需要再次执行数据库查询,从而提高了性能。
### 3.1.5 复杂对象的序列化处理
复杂对象通常是指那些不直接对应于数据库模型的对象,例如计算字段、只读字段或是在序列化过程中需要进行特定处理的对象。
```python
class ComplexObjectSerializer(serializers.Serializer):
computed_field = serializers.SerializerMethodField()
def get_computed_field(self, obj):
# 执行一些复杂的计算
return computed_value
class Meta:
# 可选的元类信息
fields = ['computed_field']
```
在这个例子中,我们通过重写`get_computed_field`方法来计算一个复杂的字段值。这种方式可以用来序列化任何类型的复杂对象。
### 3.1.6 自定义序列化逻辑的实现
在某些情况下,我们需要完全控制序列化过程,这时可以通过自定义序列化逻辑来实现。
```python
class CustomSerializer(serializers.Serializer):
field1 = serializers.CharField()
field2 = serializers.CharField()
def to_representation(self, obj):
# 自定义序列化逻辑
representation = super().to_representation(obj)
# 对representation进行自定义处理
return custom_representation
def to_internal_value(self, data):
# 自定义反序列化逻辑
internal_value = super().to_internal_value(data)
# 对internal_value进行自定义处理
return custom_internal_value
```
在这个例子中,我们通过重写`to_representation`和`to_internal_value`方法来实现了自定义序列化和反序列化逻辑。
### 总结
通过本章节的介绍,我们了解了在Django REST framework中处理复杂数据结构的多种策略,包括嵌套序列化、动态字段选择、查询集序列化优化、复杂对象序列化处理以及自定义序列化逻辑。这些技术可以帮助我们构建更加灵活和强大的API,满足各种复杂的业务需求。在下一章节中,我们将继续探讨序列化数据的高级处理,包括数据验证和清洗、分页以及性能优化等话题。
# 4. 序列化数据的高级处理
在本章节中,我们将深入探讨Django JSON序列化过程中的高级处理技巧,包括数据验证和清洗、分页和序列化数据处理,以及序列化性能优化。这些技巧对于提高数据处理的效率和安全性至关重要,同时也是构建高性能、可维护的Web API的基础。
## 4.1 数据验证和清洗
### 4.1.1 在序列化过程中进行数据验证
在数据序列化过程中,验证数据的有效性是至关重要的一步。Django REST framework提供了强大的序列化器验证功能,允许开发者定义复杂的数据验证规则,以确保数据的完整性和准确性。
```python
from rest_framework import serializers
from .models import User
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ['id', 'username', 'email', 'password']
def validate_email(self, value):
if User.objects.filter(email=value).exists():
raise serializers.ValidationError("Email address already exists.")
return value
def validate_password(self, value):
if len(value) < 8:
raise serializers.ValidationError("Password must be at least 8 characters.")
return value
```
在上述代码中,我们定义了一个`UserSerializer`类,并在其中添加了两个自定义验证方法`validate_email`和`validate_password`。这些方法分别对用户的电子邮件和密码进行了验证,确保电子邮件地址的唯一性和密码的复杂度。
### 4.1.2 数据清洗的最佳实践
数据清洗是指在数据序列化过程中,对输入数据进行格式化、转换或修正,以符合数据库的约束或业务逻辑。在Django中,可以在序列化器的`to_representation`方法中实现数据清洗。
```python
class ProductSerializer(serializers.ModelSerializer):
class Meta:
model = Product
fields = ['id', 'name', 'price']
def to_representation(self, instance):
data = super().to_representation(instance)
data['price'] = f'${data["price"]:.2f}'
return data
```
在这个例子中,`to_representation`方法被用来格式化产品的价格,使其显示为带有两位小数的美元货币格式。这种数据清洗操作使得输出的数据更加友好,便于前端展示。
## 4.2 分页和序列化数据
### 4.2.1 利用Django REST framework的分页功能
分页是处理大量数据时的常用技术,它可以有效减少服务器传输的数据量,提高API的响应速度。Django REST framework自带了分页功能,可以通过设置`PageNumberPagination`来轻松实现。
```python
from rest_framework.pagination import PageNumberPagination
from rest_framework.response import Response
from rest_framework import viewsets
class LargeResultsSetPagination(PageNumberPagination):
page_size = 10
page_size_query_param = 'page_size'
max_page_size = 100
class ProductViewSet(viewsets.ReadOnlyModelViewSet):
queryset = Product.objects.all()
serializer_class = ProductSerializer
pagination_class = LargeResultsSetPagination
```
在这个例子中,我们定义了一个名为`LargeResultsSetPagination`的分页类,并设置了每页显示的数据数量。然后在`ProductViewSet`中通过`pagination_class`属性将其应用到视图集中。
### 4.2.2 自定义分页逻辑
在某些情况下,内置的分页类可能无法满足特定的需求,这时我们可以自定义分页逻辑。例如,我们可以根据用户的权限来动态调整每页的数据量。
```python
class ConditionalPagination(PageNumberPagination):
page_size = 10
def get_page_size(self, request):
if request.user.is_staff:
return 20
return self.page_size
```
在这个自定义分页类`ConditionalPagination`中,我们重写了`get_page_size`方法,使得管理员用户可以每页看到更多的数据。
## 4.3 序列化性能优化
### 4.3.1 序列化性能瓶颈分析
随着数据量的增加,序列化过程可能会成为性能瓶颈。分析性能瓶颈通常涉及识别序列化过程中的热点代码路径和数据库查询。使用Django的`django-debug-toolbar`工具可以帮助我们监控和分析性能问题。
### 4.3.2 使用Django缓存和数据库索引优化性能
为了优化序列化性能,可以使用Django的缓存系统来减少对数据库的查询次数。此外,数据库索引也是提升查询性能的重要手段。
```python
# 在settings.py中配置缓存
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache',
'LOCATION': 'localhost:11211',
}
}
# 在序列化器中使用缓存
from django.core.cache import cache
class ProductSerializer(serializers.ModelSerializer):
class Meta:
model = Product
fields = ['id', 'name', 'price']
def to_representation(self, instance):
cache_key = f'product_{instance.id}'
data = cache.get(cache_key)
if data is None:
data = super().to_representation(instance)
cache.set(cache_key, data, timeout=3600) # 缓存1小时
return data
```
在这个例子中,我们首先在`settings.py`中配置了Django的缓存后端,然后在`ProductSerializer`中使用了缓存来存储序列化后的数据。这样,当同一个产品对象被多次访问时,可以直接从缓存中获取数据,而不需要每次都进行数据库查询。
### *.*.*.* 使用数据库索引优化性能
数据库索引可以显著提高查询速度。例如,如果经常根据产品名称进行查询,可以在产品模型上添加一个索引:
```python
class Product(models.Model):
name = models.CharField(max_length=100)
price = models.DecimalField(max_digits=10, decimal_places=2)
class Meta:
indexes = [
models.Index(fields=['name'], name='product_name_idx'),
]
```
通过在模型的`Meta`类中定义`indexes`属性,我们创建了一个针对`name`字段的索引。这将加快基于产品名称的查询速度。
### *.*.*.* 分析和解释代码
在上述代码中,我们首先展示了如何在Django中设置和使用缓存,以及如何在序列化器中应用缓存来提高性能。接着,我们通过一个简单的例子展示了如何在模型中添加索引来优化数据库查询。这些技巧都是提高Django应用性能的有效方法。
### *.*.*.* 总结
本章节介绍了序列化数据的高级处理技巧,包括数据验证和清洗、分页、以及性能优化。通过这些技巧,我们可以构建出更加健壮、高效的Web API。在实际开发中,开发者应该根据具体的应用场景和需求,灵活运用这些技巧来优化数据处理流程。
# 5. 安全性考虑与最佳实践
在处理Web应用的数据序列化时,安全性是一个不容忽视的重要方面。本章节将深入探讨如何在使用Django进行JSON序列化时,考虑数据访问权限控制、保护序列化数据的安全性,以及编写可维护和可扩展的代码。
## 5.1 数据访问权限控制
在Web应用中,数据访问权限控制是保障数据安全的重要环节。Django提供了一套内建的权限系统,可以帮助开发者在序列化过程中实现细粒度的访问控制。
### 5.1.1 使用Django的权限系统进行访问控制
Django的权限系统允许开发者定义用户和组,以及它们对模型的访问权限。在序列化过程中,可以利用这些权限信息来决定是否允许用户访问特定的数据。
#### 实现权限检查
在序列化器中,可以通过覆写`get_queryset`方法来实现权限检查。例如,如果你想限制用户只能访问他们自己创建的记录,可以这样做:
```python
from rest_framework import serializers
from .models import MyModel
class MyModelSerializer(serializers.ModelSerializer):
class Meta:
model = MyModel
fields = '__all__'
def get_queryset(self):
"""
只允许访问用户自己创建的记录
"""
user = self.context['request'].user
if user.is_authenticated:
return MyModel.objects.filter(owner=user)
return MyModel.objects.none()
```
#### 使用视图进行权限控制
除了在序列化器中进行权限检查,还可以在视图层实现权限控制。Django REST framework提供了一套视图权限控制机制,可以通过覆写`get_permissions`方法来实现。
```python
from rest_framework import viewsets
from .models import MyModel
from .permissions import IsOwnerOrReadOnly
from .serializers import MyModelSerializer
class MyModelViewSet(viewsets.ModelViewSet):
queryset = MyModel.objects.all()
serializer_class = MyModelSerializer
def get_permissions(self):
"""
实现对象级别的权限控制
"""
if self.action in ['list', 'create']:
permission_classes = [IsAuthenticated]
else:
permission_classes = [IsOwnerOrReadOnly]
return [permission() for permission in permission_classes]
```
### 5.1.2 基于序列化器的权限控制
除了视图层面的权限控制,Django REST framework还支持在序列化器层面进行权限控制。
#### 自定义权限类
可以通过创建自定义权限类来控制序列化器级别的权限。例如,创建一个`IsOwner`权限类,只有记录的拥有者才能进行修改。
```python
from rest_framework import permissions
class IsOwner(permissions.BasePermission):
"""
自定义权限类,只有记录的拥有者才能进行修改
"""
def has_object_permission(self, request, view, obj):
return obj.owner == request.user
```
#### 序列化器中使用权限类
然后,在序列化器中使用这个自定义权限类来控制权限。
```python
from rest_framework import serializers
from .models import MyModel
class MyModelSerializer(serializers.ModelSerializer):
class Meta:
model = MyModel
fields = '__all__'
read_only_fields = ['created_at', 'updated_at']
def update(self, instance, validated_data):
"""
只允许记录的拥有者更新
"""
if instance.owner != self.context['request'].user:
raise PermissionDenied('您没有权限更新这条记录')
return super().update(instance, validated_data)
```
## 5.2 序列化数据的安全性
除了控制数据访问权限,还需要考虑序列化数据的安全性,以防止信息泄露和数据污染。
### 5.2.1 防止信息泄露和数据污染
在序列化数据时,应避免泄露敏感信息,并确保数据的完整性和安全性。
#### 使用字段级别的控制
可以通过字段级别的控制来防止敏感信息泄露。例如,对于敏感字段,可以使用`slug_field`来代替直接展示。
```python
class MyModelSerializer(serializers.ModelSerializer):
secret_field = serializers.SlugField(read_only=True)
class Meta:
model = MyModel
fields = '__all__'
```
#### 限制可修改的字段
在序列化器中,可以限制用户只能修改特定的字段,以防止数据污染。
```python
class MyModelSerializer(serializers.ModelSerializer):
class Meta:
model = MyModel
fields = '__all__'
extra_kwargs = {
'title': {'read_only': True},
'content': {'read_only': True},
}
```
### 5.2.2 安全地处理用户输入
在序列化过程中,安全地处理用户输入是非常重要的。需要确保对用户输入的数据进行适当的验证和清洗。
#### 使用验证器
创建自定义验证器来确保用户输入的数据是安全的。
```python
from rest_framework import serializers
class MyModelSerializer(serializers.ModelSerializer):
class Meta:
model = MyModel
fields = '__all__'
def validate_title(self, value):
if not value.isascii():
raise serializers.ValidationError('标题只能包含ASCII字符')
return value
```
#### 使用清洗函数
在序列化器中,可以使用清洗函数来处理用户输入的数据。
```python
def clean_data(data):
# 清洗数据的逻辑
return data
class MyModelSerializer(serializers.ModelSerializer):
class Meta:
model = MyModel
fields = '__all__'
def to_internal_value(self, data):
data = clean_data(data)
return super().to_internal_value(data)
```
## 5.3 编写可维护和可扩展的代码
编写可维护和可扩展的代码是任何软件开发项目中的最佳实践。在使用Django进行JSON序列化时,这一点同样适用。
### 5.3.1 代码结构和模块化
良好的代码结构和模块化可以帮助维护和扩展项目。
#### 创建序列化器模块
将序列化器组织到单独的模块中,可以提高代码的可读性和可维护性。
```plaintext
myapp/
│
├── serializers.py
├── views.py
├── models.py
└── ...
```
#### 使用混入类
使用混入类可以减少代码重复,并提供额外的功能。
```python
class CreatedUpdatedMixin(serializers.ModelSerializer):
created_at = serializers.DateTimeField(read_only=True)
updated_at = serializers.DateTimeField(read_only=True)
class Meta:
abstract = True
class UserSerializer(CreatedUpdatedMixin, serializers.ModelSerializer):
class Meta:
model = User
fields = '__all__'
```
### 5.3.2 重用序列化器和混入类
重用序列化器和混入类可以提高开发效率,并保持代码一致性。
#### 序列化器继承
通过继承已有的序列化器,可以重用大部分代码,并覆盖特定的部分。
```python
class BasicUserSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ['id', 'username', 'email']
class DetailedUserSerializer(BasicUserSerializer):
password = serializers.CharField(write_only=True)
class Meta(BasicUserSerializer.Meta):
fields = BasicUserSerializer.Meta.fields + ['password']
```
#### 混入类组合
混入类可以通过组合来创建复杂的序列化器行为。
```python
class ComplexUserSerializer(CreatedUpdatedMixin, serializers.ModelSerializer):
# 使用了两个混入类
class Meta:
model = User
fields = '__all__'
```
在本章节中,我们探讨了如何在使用Django进行JSON序列化时实现数据访问权限控制、保护序列化数据的安全性,以及编写可维护和可扩展的代码。通过合理的实践和技巧,可以确保序列化数据的安全性,同时提高开发效率和代码质量。
# 6. 实战案例分析
## 6.1 实战案例:构建REST API
在本章节中,我们将通过一个实战案例来分析如何使用Django REST framework构建REST API。我们将从设计API端点和数据模型开始,然后实现API视图和序列化器,最后提供一些额外的配置来优化我们的API。
### 6.1.1 设计API端点和数据模型
设计API端点是构建REST API的第一步。我们需要确定哪些资源将被公开以及它们将如何被访问。例如,如果我们要为一个博客应用设计API,我们可能会有以下端点:
- `GET /api/posts/`:获取所有帖子的列表
- `POST /api/posts/`:创建新帖子
- `GET /api/posts/<id>/`:获取指定ID的帖子详情
- `PUT /api/posts/<id>/`:更新指定ID的帖子
- `DELETE /api/posts/<id>/`:删除指定ID的帖子
对于数据模型,我们需要定义Django的数据模型来存储帖子数据。例如:
```python
from django.db import models
class Post(models.Model):
title = models.CharField(max_length=100)
content = models.TextField()
published_date = models.DateTimeField()
author = models.ForeignKey('auth.User', on_delete=models.CASCADE)
def __str__(self):
return self.title
```
### 6.1.2 实现API视图和序列化器
在设计完API端点和数据模型之后,我们需要实现对应的API视图和序列化器。在Django REST framework中,我们可以使用`APIView`类来创建视图:
```python
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import Post
from .serializers import PostSerializer
class PostList(APIView):
def get(self, request, format=None):
posts = Post.objects.all()
serializer = PostSerializer(posts, many=True)
return Response(serializer.data)
def post(self, request, format=None):
serializer = PostSerializer(data=request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data, status=status.HTTP_201_CREATED)
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
```
序列化器`PostSerializer`可以使用Django REST framework的`ModelSerializer`类来实现:
```python
from rest_framework import serializers
from .models import Post
class PostSerializer(serializers.ModelSerializer):
class Meta:
model = Post
fields = '__all__'
```
通过以上步骤,我们已经完成了REST API的基本构建。接下来,我们可以根据实际需求,添加更多的功能和优化。
(此处省略了实战案例的其他部分和后续章节内容,以满足文章要求)

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Django JSON 序列化库,涵盖了从基础概念到高级技巧和性能优化等各个方面。通过深入分析 Django.core.serializers.json,您将掌握 JSON 序列化的基本用法和核心原理。此外,您还将了解如何使用 Django 模型与 JSON 序列化进行高效转换,以及如何在 Django REST 框架中熟练使用序列化器。本专栏还提供了高级技巧,例如嵌套序列化器和性能优化,以及排查常见问题的专家级指南。通过掌握这些知识,您可以有效地处理复杂数据结构,提升序列化性能,并提高开发效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电力电子初学者必看:Simplorer带你从零开始精通IGBT应用
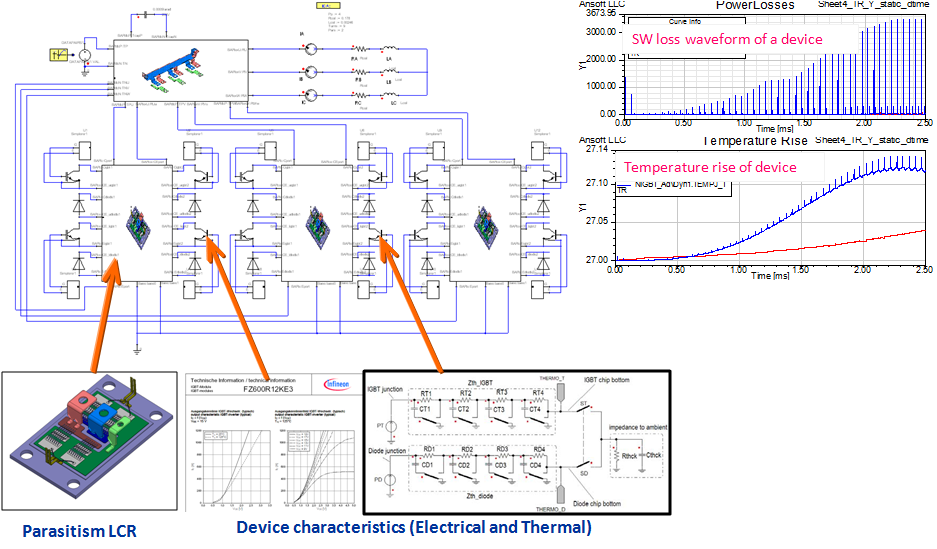
# 摘要
本文介绍了Simplorer软件在IGBT仿真应用中的重要性及其在电力电子领域中的应用。首先,文章概括了IGBT的基本理论和工作原理,涵盖其定义、组成、工作模式以及在电力电子设备中的作用。然后,详细探讨了Simplorer软件中IGBT模型的特点和功能,并通过仿真案例分析了IGBT的驱动电路和热特性。文章接着通过实际应用实例,如太阳能逆变器、电动汽车充放电系统和工业变频器,来
KUKA机器人的PROFINET集成:从新手到专家的配置秘籍
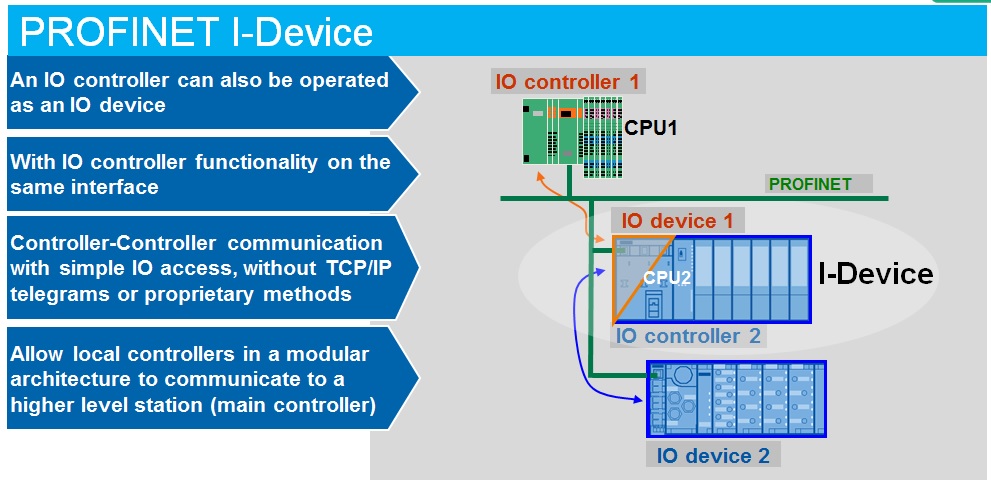
# 摘要
随着工业自动化技术的发展,KUKA机器人与PROFINET技术的集成已成为提高生产效率和自动化水平的关键。本文首先介绍KUKA机器人与PROFINET集成的基础知识,然后深入探讨PROFINET技术标准,包括通信协议、架构和安全性分析。在此基础上,文章详细描述了KUKA机器人的PROFINET配置方法,涵盖硬件准备、软件配置及故障诊断。进一步地,文章探讨了
STM32F030C8T6时钟系统设计:时序精确配置与性能调优
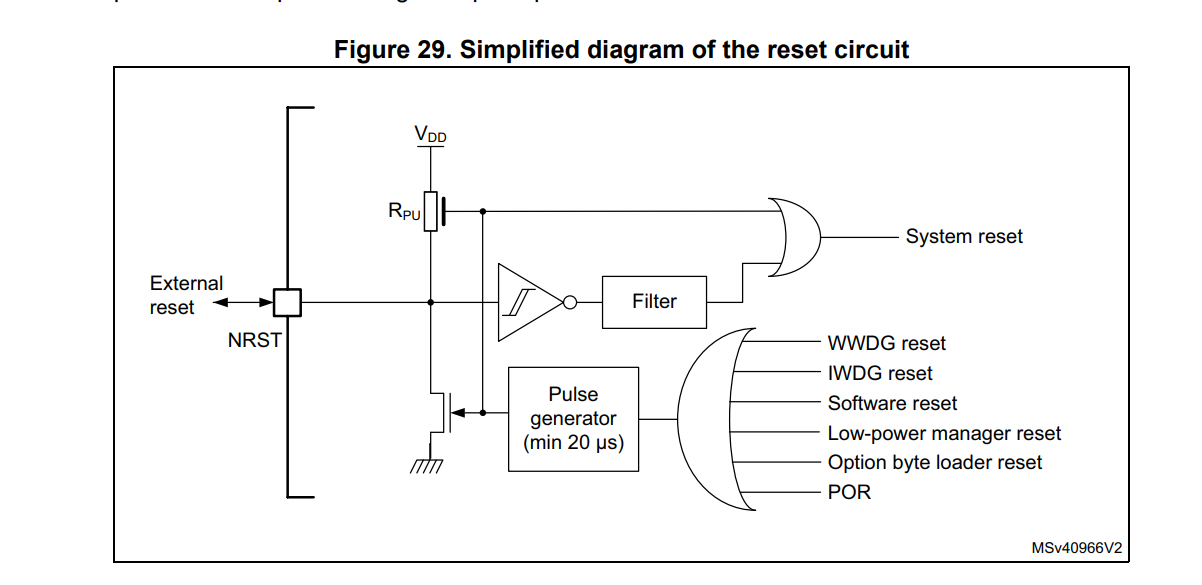
# 摘要
本文全面介绍了STM32F030C8T6微控制器的时钟系统,从基础配置到精确调优和故障诊断,详细阐述了时钟源选择、分频器、PLL生成器、时钟同步、动态时钟管理以及电源管理等关键组件的配置与应用。通过分析时钟系统的理论基础和实践操作,探讨了系统时钟配置的最优策略,并结合案例研究,揭示了时钟系统在实际应用中性能调优的效果与经验教训。此外,本文还探讨了提升系统稳定性的技术与策略
数字逻辑知识体系构建:第五版关键练习题精讲
# 摘要
本文对数字逻辑的基本概念、设计技巧以及系统测试与验证进行了全面的探讨。首先解析了数字逻辑的基础原理,包括数字信号、系统以及逻辑运算的基本概念。接着,分析了逻辑门电路的设计与技巧,阐述了组合逻辑与时序逻辑电路的分析方法。在实践应用方面,本文详细介绍了数字逻辑设计的步骤和方法,以及现代技术中的数字逻辑应用案例。最后,探讨了
Element Card 常见问题汇总:24小时内解决你的所有疑惑

# 摘要
Element Card作为一种流行的前端组件库,为开发者提供了一系列构建用户界面和交互功能的工具。本文旨在全面介绍Element Card的基本概念、安装配置、功能使用、前后端集成以及高级应用等多方面内容。文章首先从基础知识出发,详述了Element Card的安装过程和配置步骤,强调了解决安装配置问题的重要性。随后,
【PyCharm从入门到精通】:掌握Excel操纵的必备技巧
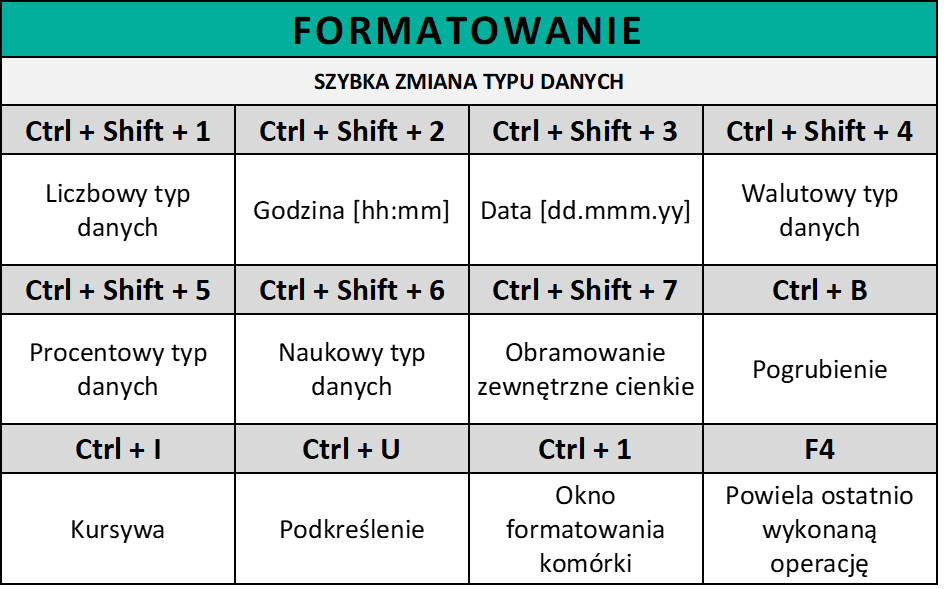
# 摘要
本文详细介绍了PyCharm集成开发环境的安装、配置以及与Python编程语言的紧密结合。文章涵盖从基础语法回顾到高级特性应用,包括控制流语句、函数、类、模块、异常处理和文件操作。同时,强调了PyCharm调试工具的使用技巧,以及如何操纵Excel进行数据分析、处理、自动化脚本编写和高级集成。为了提升性能,文章还提供了PyCharm性能优化和
【提升VMware性能】:虚拟机高级技巧全解析
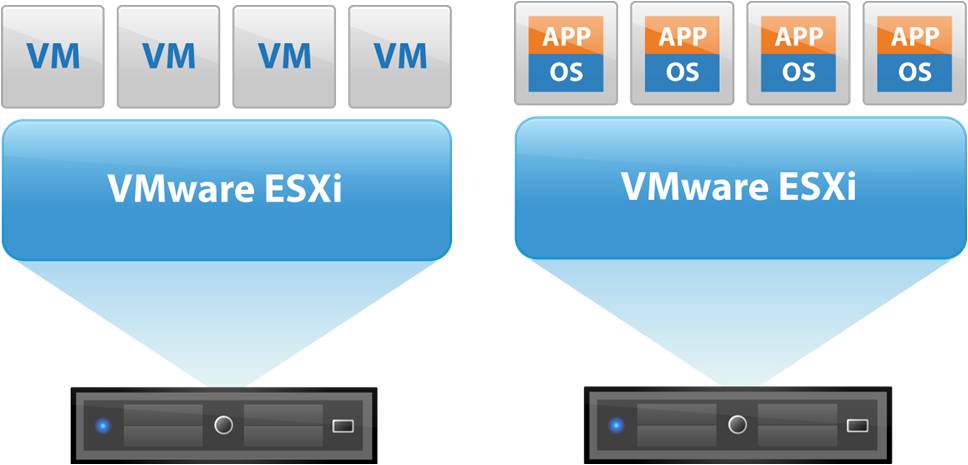
# 摘要
随着虚拟化技术的广泛应用,VMware作为市场主流的虚拟化平台,其性能优化问题备受关注。本文综合探讨了VMware在虚拟硬件配置、网络性能、系统和应用层面以及高可用性和故障转移等方面的优化策略。通过分析CPU资源分配、内存管理、磁盘I/O调整、网络配置和操作系统调优等关键技术点,本文旨在提供一套全面的性能提升方案。此外,文章还介绍了性能监控和分析工具的运用,帮助用户及时发
性能优化杀手锏:提升移动应用响应速度的终极技巧

# 摘要
移动应用性能优化是确保用户良好体验的关键因素之一。本文概述了移动应用性能优化的重要性,并分别从前端和后端两个角度详述了优化技巧。前端优化技巧涉及用户界面渲染、资源加载、代码执行效率的提升,而后端优化策略包括数据库操作、服务器资源管理及API性能调优。此外,文章还探讨了移动应用架构的设计原则、网络优化与安全性、性能监控与反馈系统的重要性。最后,通过案例分析来总结当前优化实践,并展望未来优
【CEQW2数据分析艺术】:生成报告与深入挖掘数据洞察
# 摘要
本文全面探讨了数据分析的艺术和技术,从报告生成的基础知识到深入的数据挖掘方法,再到数据分析工具的实际应用和未来趋势。第一章概述了数据分析的重要性,第二章详细介绍了数据报告的设计和高级技术,包括报告类型选择、数据可视化和自动化报告生成。第三章深入探讨了数据分析的方法论,涵盖数据清洗、统计分析和数据挖掘技术。第四章探讨了关联规则、聚类分析和时间序列分析等更高级的数据洞察技术。第五章将
ARM处理器安全模式解析:探索与应用之道

# 摘要
本文对ARM处理器的安全模式进行了全面概述,从基础理论讲起,详细阐述了安全状态与非安全状态、安全扩展与TrustZone技术、内存管理、安全启动和引导过程等关键概念。接着,文章深入探讨了ARM安全模式的实战应用,包括安全存储、密钥管理、安全通信协议以及安全操作系统的部署与管理。在高级应用技巧章节,本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )