Redis缓存实战指南:提升应用性能与响应速度
发布时间: 2024-07-28 05:35:06 阅读量: 23 订阅数: 20 
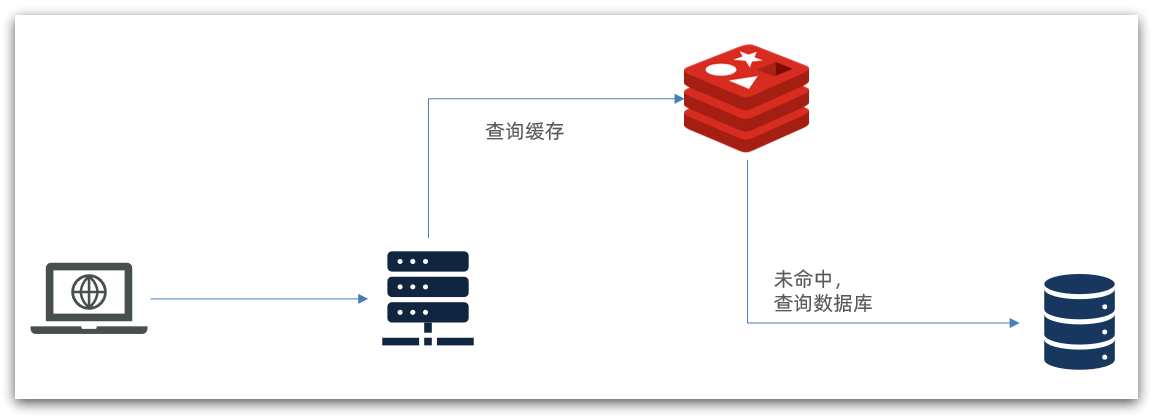
# 1. Redis缓存概述
Redis是一种开源的内存数据库,以其高性能和可扩展性而闻名。它主要用于缓存数据,以减少对数据库的访问,从而提高应用程序的性能。
Redis支持多种数据结构,包括字符串、散列、列表、集合和有序集合。这些数据结构可以用来存储各种类型的数据,例如用户会话、产品目录和实时统计信息。
Redis还提供了丰富的缓存策略和淘汰算法,以确保缓存中的数据是最新的和最常用的。它还支持复制和持久化机制,以确保数据的可靠性和可用性。
# 2. Redis缓存技术原理
### 2.1 数据结构与存储模型
Redis使用多种数据结构来存储数据,每种数据结构都有其独特的特性和适用场景。主要的数据结构包括:
- **字符串(String)**:最基本的数据类型,可以存储文本、二进制数据或数字。
- **列表(List)**:有序集合,可以存储多个字符串或其他数据类型。
- **哈希(Hash)**:键值对集合,可以存储复杂对象或结构化数据。
- **集合(Set)**:无序集合,存储唯一元素。
- **有序集合(Sorted Set)**:有序集合,元素按分数排序。
Redis采用键值对存储模型,每个键对应一个值。键可以是字符串,而值可以是上述任何数据结构。这种模型提供了快速和高效的数据访问,并且可以轻松扩展以存储大量数据。
### 2.2 缓存命中策略与淘汰算法
缓存命中策略决定了当客户端请求数据时,如何确定数据是否在缓存中。常见的命中策略包括:
- **最近最少使用(LRU)**:淘汰最近最少使用的缓存项。
- **最近最不经常使用(LFU)**:淘汰最近最不经常使用的缓存项。
- **随机淘汰**:随机淘汰缓存项。
淘汰算法决定了当缓存已满时,如何选择要淘汰的缓存项。常见的淘汰算法包括:
- **惰性淘汰**:只有当客户端请求不存在于缓存中的数据时,才会淘汰缓存项。
- **定期淘汰**:定期淘汰一定数量的缓存项,以防止缓存过大。
- **主动淘汰**:当缓存接近容量限制时,主动淘汰缓存项,以释放空间。
### 2.3 复制与持久化机制
Redis提供了复制和持久化机制,以确保数据的可靠性和可用性。
**复制**:Redis支持主从复制,其中一个主节点与多个从节点同步数据。当主节点发生故障时,从节点可以接管并继续提供服务。
**持久化**:Redis提供两种持久化机制:
- **RDB(Redis数据库文件)**:定期将整个数据集转储到硬盘。
- **AOF(追加只写文件)**:将所有写入操作记录到日志文件,并在服务器重启时重放日志。
通过复制和持久化,Redis可以确保数据在服务器故障或意外关闭的情况下不会丢失。
# 3.1 缓存设计与配置优化
#### 缓存设计原则
* **遵循最少原则:**只缓存真正需要缓存的数据,避免不必要的缓存开销。
* **考虑数据访问模式:**根据数据访问频率和模式设计缓存策略,优化命中率。
* **选择合适的缓存数据结构:**根据数据类型和访问模式选择合适的缓存数据结构,如哈希表、列表、集合等。
* **合理设置缓存过期时间:**根据数据更新频率和重要性设置合
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏深入探讨了各种数据库和数据管理技术的方方面面,从JSON数据库的ER图建模到MySQL性能优化和高可用性架构设计。它提供了深入的分析、实用指南和案例研究,帮助读者理解复杂的数据结构、关系建模和数据库管理概念。通过揭秘数据库的奥秘,专栏旨在提升数据组织、查询效率和整体系统性能,为数据库专业人士、开发人员和架构师提供宝贵的见解。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python序列化与反序列化高级技巧:精通pickle模块用法

# 1. Python序列化与反序列化概述
在信息处理和数据交换日益频繁的今天,数据持久化成为了软件开发中不可或缺的一环。序列化(Serialization)和反序列化(Deserialization)是数据持久化的重要组成部分,它们能够将复杂的数据结构或对象状态转换为可存储或可传输的格式,以及还原成原始数据结构的过程。
序列化通常用于数据存储、
【Python集合异常处理攻略】:集合在错误控制中的有效策略

# 1. Python集合的基础知识
Python集合是一种无序的、不重复的数据结构,提供了丰富的操作用于处理数据集合。集合(set)与列表(list)、元组(tuple)、字典(dict)一样,是Python中的内置数据类型之一。它擅长于去除重复元素并进行成员关系测试,是进行集合操作和数学集合运算的理想选择。
集合的基础操作包括创建集合、添加元素、删除元素、成员测试和集合之间的运
Image Processing and Computer Vision Techniques in Jupyter Notebook
# Image Processing and Computer Vision Techniques in Jupyter Notebook
## Chapter 1: Introduction to Jupyter Notebook
### 2.1 What is Jupyter Notebook
Jupyter Notebook is an interactive computing environment that supports code execution, text writing, and image display. Its main features include:
-
Pandas中的文本数据处理:字符串操作与正则表达式的高级应用

# 1. Pandas文本数据处理概览
Pandas库不仅在数据清洗、数据处理领域享有盛誉,而且在文本数据处理方面也有着独特的优势。在本章中,我们将介绍Pandas处理文本数据的核心概念和基础应用。通过Pandas,我们可以轻松地对数据集中的文本进行各种形式的操作,比如提取信息、转换格式、数据清洗等。
我们会从基础的字
Python print语句装饰器魔法:代码复用与增强的终极指南

# 1. Python print语句基础
## 1.1 print函数的基本用法
Python中的`print`函数是最基本的输出工具,几乎所有程序员都曾频繁地使用它来查看变量值或调试程序。以下是一个简单的例子来说明`print`的基本用法:
```python
print("Hello, World!")
```
这个简单的语句会输出字符串到标准输出,即你的控制台或终端。`prin
Python版本与性能优化:选择合适版本的5个关键因素

# 1. Python版本选择的重要性
Python是不断发展的编程语言,每个新版本都会带来改进和新特性。选择合适的Python版本至关重要,因为不同的项目对语言特性的需求差异较大,错误的版本选择可能会导致不必要的兼容性问题、性能瓶颈甚至项目失败。本章将深入探讨Python版本选择的重要性,为读者提供选择和评估Python版本的决策依据。
Python的版本更新速度和特性变化需要开发者们保持敏锐的洞
Python数组与数据库交互:掌握高级技术

# 1. Python数组基础及其应用
Python 中的数组,通常指的是列表(list),它是 Python 中最基本也是最灵活的数据结构之一。列表允许我们存储一系列有序的元素,这些元素可以是不同的数据类型,比如数字、字符串甚至是另一个列表。这种特性使得 Python 列表非常适合用作数组,尤其是在需要处理动态数组时。
在本章中,我们将从基础出发,逐步深入到列表的创建、操作,以及高
Python pip性能提升之道
# 1. Python pip工具概述
Python开发者几乎每天都会与pip打交道,它是Python包的安装和管理工具,使得安装第三方库变得像“pip install 包名”一样简单。本章将带你进入pip的世界,从其功能特性到安装方法,再到对常见问题的解答,我们一步步深入了解这一Python生态系统中不可或缺的工具。
首先,pip是一个全称“Pip Installs Pac
Parallelization Techniques for Matlab Autocorrelation Function: Enhancing Efficiency in Big Data Analysis
# 1. Introduction to Matlab Autocorrelation Function
The autocorrelation function is a vital analytical tool in time-domain signal processing, capable of measuring the similarity of a signal with itself at varying time lags. In Matlab, the autocorrelation function can be calculated using the `xcorr
Technical Guide to Building Enterprise-level Document Management System using kkfileview
# 1.1 kkfileview Technical Overview
kkfileview is a technology designed for file previewing and management, offering rapid and convenient document browsing capabilities. Its standout feature is the support for online previews of various file formats, such as Word, Excel, PDF, and more—allowing user
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )